

เมื่อวันที่ 19–20 พฤศจิกายน 2025 OpenAI เปิดตัวการอัปเกรดสองรายการที่เกี่ยวข้องกันแต่แตกต่างกัน: GPT-5.1-Codex-Max โมเดลการเขียนโค้ดเชิงตัวแทนใหม่สำหรับ Codex ที่เน้นการเขียนโค้ดระยะยาว ประสิทธิภาพการใช้โทเคน และ “การย่อ (compaction)” เพื่อคงเซสชันหลายหน้าต่าง; และ GPT-5.1 Pro โมเดล ChatGPT ระดับ Pro รุ่นปรับปรุงที่ปรับจูนเพื่อให้คำตอบชัดเจนและมีความสามารถมากขึ้นสำหรับงานมืออาชีพที่ซับซ้อน
GPT-5.1-Codex-Max คืออะไร และกำลังพยายามแก้ปัญหาอะไร?
GPT-5.1-Codex-Max เป็นโมเดล Codex แบบเฉพาะทางจาก OpenAI ที่ปรับจูนสำหรับเวิร์กโฟลว์การเขียนโค้ดซึ่งต้องการการให้เหตุผลและการดำเนินการอย่างต่อเนื่องในระยะยาว โมเดลทั่วไปมักสะดุดกับบริบทที่ยาวมาก — เช่น การรีแฟคเตอร์หลายไฟล์ ลูปเอเจนต์ที่ซับซ้อน หรืองาน CI/CD ที่ต่อเนื่อง — Codex-Max ได้รับการออกแบบให้ย่อและจัดการสถานะเซสชันโดยอัตโนมัติข้ามหน้าต่างบริบทหลายบาน ทำให้สามารถทำงานต่อได้อย่างสอดคล้องเมื่อโปรเจ็กต์เดียวขยายไปถึงหลายพัน (หรือมากกว่า) โทเคน OpenAI วางตำแหน่ง Codex-Max เป็นก้าวถัดไปในการทำให้เอเจนต์ที่ทำโค้ดได้มีประโยชน์จริงสำหรับงานวิศวกรรมระยะยาว
GPT-5.1-Codex-Max คืออะไร และกำลังพยายามแก้ปัญหาอะไร?
GPT-5.1-Codex-Max เป็นโมเดล Codex แบบเฉพาะทางจาก OpenAI ที่ปรับจูนสำหรับเวิร์กโฟลว์การเขียนโค้ดซึ่งต้องการการให้เหตุผลและการดำเนินการอย่างต่อเนื่องในระยะยาว โมเดลทั่วไปมักสะดุดกับบริบทที่ยาวมาก — เช่น การรีแฟคเตอร์หลายไฟล์ ลูปเอเจนต์ที่ซับซ้อน หรืองาน CI/CD ที่ต่อเนื่อง — Codex-Max ได้รับการออกแบบให้ย่อและจัดการสถานะเซสชันโดยอัตโนมัติข้ามหน้าต่างบริบทหลายบาน ทำให้สามารถทำงานต่อได้อย่างสอดคล้องเมื่อโปรเจ็กต์เดียวขยายไปถึงหลายพัน (หรือมากกว่า) โทเคน
OpenAI อธิบายว่าโมเดลนี้ “เร็วขึ้น ฉลาดขึ้น และใช้โทเคนได้มีประสิทธิภาพมากขึ้นในทุกช่วงของวงจรพัฒนา” และตั้งใจให้แทนที่ GPT-5.1-Codex เป็นโมเดลเริ่มต้นในพื้นผิวของ Codex อย่างชัดเจน
ภาพรวมคุณลักษณะ
- การย่อเพื่อความต่อเนื่องแบบหลายหน้าต่าง: ตัดทอนและคงไว้ซึ่งบริบทสำคัญเพื่อทำงานอย่างสอดคล้องเหนือโทเคนนับล้านและหลายชั่วโมง 0
- ประสิทธิภาพการใช้โทเคนดีขึ้นเมื่อเทียบกับ GPT-5.1-Codex: ใช้โทเคน “การคิด” น้อยลงได้ถึง ~30% สำหรับความพยายามด้านเหตุผลที่ใกล้เคียงกันในบางเกณฑ์ทดสอบโค้ด
- ความทนทานของเอเจนต์ระยะยาว: พบภายในว่าสามารถคงลูปเอเจนต์ได้หลายชั่วโมง/หลายวัน (OpenAI บันทึกการรันภายในมากกว่า 24 ชั่วโมง)
- การผสานรวมกับแพลตฟอร์ม: พร้อมใช้งานแล้วใน Codex CLI ส่วนขยาย IDE คลาวด์ และเครื่องมือตรวจทบทวนโค้ด; การเข้าถึง API จะตามมา
- รองรับสภาพแวดล้อม Windows: OpenAI ระบุโดยเฉพาะว่า Windows รองรับเป็นครั้งแรกในเวิร์กโฟลว์ Codex ขยายการเข้าถึงนักพัฒนาในโลกจริง
เทียบกับผลิตภัณฑ์คู่แข่งอย่างไร (เช่น GitHub Copilot, AI เขียนโค้ดอื่น ๆ)?
GPT-5.1-Codex-Max ถูกนำเสนอว่าเป็นผู้ร่วมงานที่มีความเป็นอิสระและมุมมองระยะยาวมากกว่า เมื่อเทียบกับเครื่องมือเติมคำตอบแบบรายคำขอ ขณะที่ Copilot และผู้ช่วยที่คล้ายกันโดดเด่นในงานเติมคำระยะสั้นภายในเอดิเตอร์ จุดแข็งของ Codex-Max อยู่ที่การจัดการงานหลายขั้นตอน รักษาสถานะให้สอดคล้องข้ามเซสชัน และจัดการเวิร์กโฟลว์ที่ต้องการการวางแผน การทดสอบ และการทำซ้ำ อย่างไรก็ตาม แนวทางที่ดีที่สุดสำหรับทีมส่วนใหญ่คือแบบผสม: ใช้ Codex-Max สำหรับงานอัตโนมัติที่ซับซ้อนและงานเอเจนต์ที่ต้องทำต่อเนื่อง และใช้ผู้ช่วยที่เบากว่าสำหรับการเติมระดับบรรทัด
GPT-5.1-Codex-Max ทำงานอย่างไร?
“การย่อ (compaction)” คืออะไร และทำให้งานระยะยาวเป็นไปได้อย่างไร?
ความก้าวหน้าทางเทคนิคหลักคือการย่อ (compaction)—กลไกภายในที่ตัดทอนประวัติของเซสชันขณะคงชิ้นส่วนบริบทที่สำคัญไว้ เพื่อให้โมเดลสามารถทำงานต่ออย่างสอดคล้องข้ามหลายหน้าต่างบริบท ในทางปฏิบัติ หมายความว่าเมื่อเซสชันของ Codex เข้าใกล้ขีดจำกัดบริบท จะมีการย่อ (สรุป/คงค่าของโทเคนที่เก่าหรือต่ำค่า) เพื่อให้เอเจนต์มีหน้าต่างใหม่และสามารถวนทำงานซ้ำได้จนกว่างานจะเสร็จ OpenAI รายงานการรันภายในที่โมเดลทำงานต่อเนื่องได้นานกว่า 24 ชั่วโมง
การให้เหตุผลแบบปรับตัวและประสิทธิภาพการใช้โทเคน
GPT-5.1-Codex-Max ใช้กลยุทธ์การให้เหตุผลที่ปรับปรุงขึ้น ทำให้ใช้โทเคนได้มีประสิทธิภาพมากขึ้น: ในเกณฑ์ภายในที่ OpenAI รายงาน โมเดล Max ทำผลงานเทียบเท่าหรือดีกว่า GPT-5.1-Codex ขณะใช้โทเคน “การคิด” น้อยลงอย่างมีนัยสำคัญ—OpenAI ระบุประมาณน้อยลง 30% ของโทเคนการคิดบน SWE-bench Verified เมื่อรันด้วยความพยายามด้านเหตุผลเท่ากัน โมเดลยังมีโหมดความพยายามด้านเหตุผล “Extra High (xhigh)” สำหรับงานที่ไม่ไวต่อความหน่วง ช่วยให้ใช้การให้เหตุผลภายในมากขึ้นเพื่อให้ผลลัพธ์คุณภาพสูงขึ้น
การผสานเข้ากับระบบและเครื่องมือเชิงตัวแทน
Codex-Max ถูกแจกจ่ายภายในเวิร์กโฟลว์ของ Codex (CLI ส่วนขยาย IDE คลาวด์ และพื้นผิวการรีวิวโค้ด) เพื่อให้สามารถโต้ตอบกับทูลเชนของนักพัฒนาจริงได้ การผสานรวมระยะแรกประกอบด้วย Codex CLI และเอเจนต์ใน IDE (VS Code, JetBrains เป็นต้น) โดยการเข้าถึง API มีแผนตามมา เป้าหมายการออกแบบไม่ใช่แค่การสังเคราะห์โค้ดที่ฉลาดขึ้น แต่เป็น AI ที่สามารถรันเวิร์กโฟลว์หลายขั้นตอน: เปิดไฟล์ รันเทสต์ แก้ความล้มเหลว รีแฟคเตอร์ และรันใหม่
GPT-5.1-Codex-Max ทำงานได้ดีแค่ไหนในเกณฑ์ทดสอบและงานจริง?
การให้เหตุผลอย่างต่อเนื่องและงานระยะยาว
การประเมินชี้ให้เห็นถึงการปรับปรุงที่วัดได้ในด้านการให้เหตุผลอย่างต่อเนื่องและงานระยะยาว:
- OpenAI การประเมินภายใน: Codex-Max สามารถทำงานกับงานได้นาน “มากกว่า 24 ชั่วโมง” ในการทดลองภายใน และการผสาน Codex เข้ากับทูลของนักพัฒนาเพิ่มตัวชี้วัดประสิทธิผลด้านวิศวกรรมภายใน (เช่น การใช้งานและอัตราการส่ง pull request) สิ่งเหล่านี้เป็นข้ออ้างภายในของ OpenAI และบ่งชี้ถึงการปรับปรุงระดับงานในด้านประสิทธิภาพการทำงานจริง
- การประเมินอิสระ (METR): รายงานอิสระของ METR วัดค่า observed 50% time horizon (สถิติที่แสดงเวลามัธยฐานที่โมเดลสามารถคงความสอดคล้องของงานระยะยาวได้) สำหรับ GPT-5.1-Codex-Max ประมาณ 2 ชั่วโมง 40 นาที (โดยมีช่วงความเชื่อมั่นกว้าง) เพิ่มขึ้นจาก GPT-5 ที่ 2 ชั่วโมง 17 นาทีในการวัดเทียบเคียง — เป็นการปรับปรุงในแนวโน้มที่มีความหมายต่อความสอดคล้องระยะยาวในการใช้งานจริง ระเบียบวิธีและ CI ของ METR เน้นความแปรปรวน แต่ผลลัพธ์สนับสนุนแนวเรื่องที่ว่า Codex-Max ปรับปรุงความสามารถเชิงปฏิบัติในงานระยะยาว
เกณฑ์ทดสอบโค้ด
OpenAI รายงานผลลัพธ์ที่ดีขึ้นบนการประเมินเชิงแนวหน้าด้านโค้ด โดยเฉพาะ SWE-bench Verified ที่ GPT-5.1-Codex-Max ทำได้ดีกว่า GPT-5.1-Codex พร้อมประสิทธิภาพการใช้โทเคนที่ดีกว่า บริษัทเน้นว่าด้วยความพยายามด้านเหตุผล “medium” เท่ากัน โมเดล Max ให้ผลดีกว่าพร้อมใช้โทเคนการคิดน้อยลงประมาณ 30%; สำหรับผู้ใช้ที่อนุญาตให้ใช้การให้เหตุผลภายในนานขึ้น โหมด xhigh สามารถยกระดับคำตอบได้เพิ่มเติมแลกกับความหน่วง
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
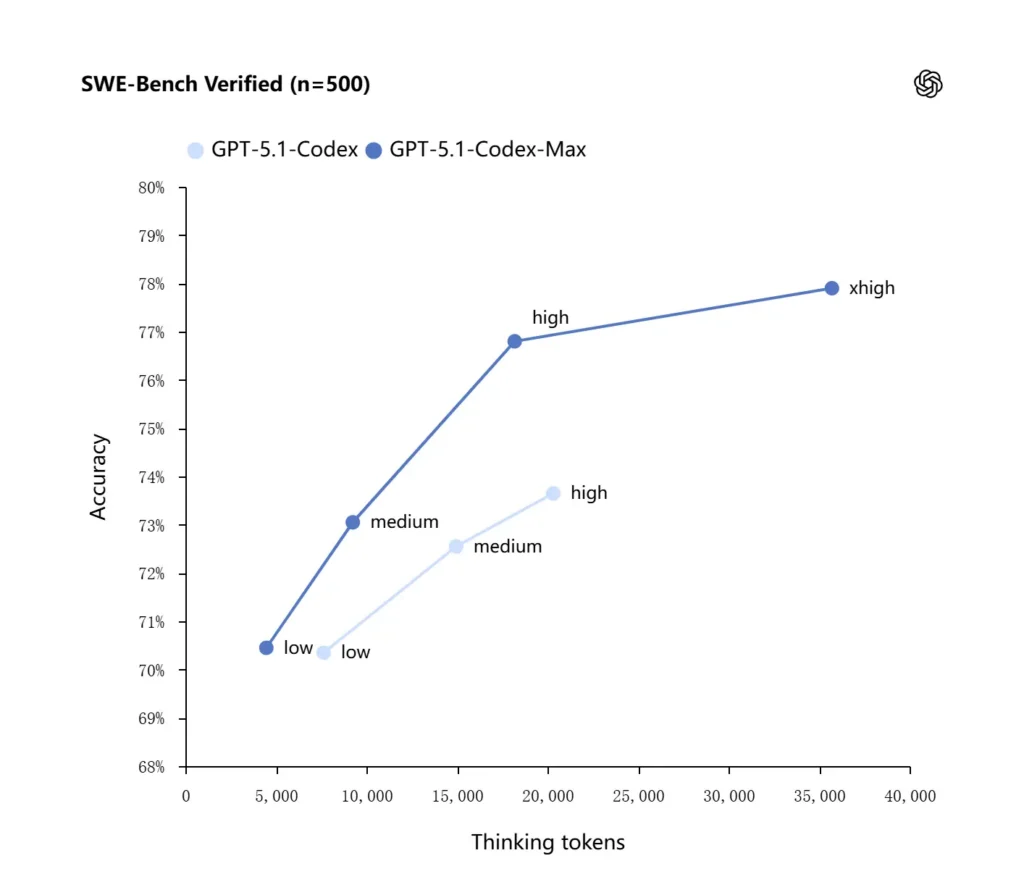
GPT-5.1-Codex-Max เปรียบเทียบกับ GPT-5.1-Codex อย่างไร?
ความแตกต่างด้านสมรรถนะและวัตถุประสงค์
- ขอบเขต: GPT-5.1-Codex เป็นเวอร์ชันการเขียนโค้ดสมรรถนะสูงของตระกูล GPT-5.1; Codex-Max เป็นผู้สืบทอดเชิงตัวแทน ระยะยาวอย่างชัดเจน ซึ่งตั้งใจให้เป็นค่าเริ่มต้นที่แนะนำสำหรับสภาพแวดล้อม Codex และที่คล้ายกัน
- ประสิทธิภาพการใช้โทเคน: Codex-Max แสดงให้เห็นการประหยัดโทเคนอย่างมีนัยสำคัญ (ข้ออ้างของ OpenAI ว่า “น้อยลง ~30%” สำหรับโทเคนการคิด) บน SWE-bench และในการใช้งานภายใน
- การจัดการบริบท: Codex-Max นำเสนอการย่อและการจัดการหลายหน้าต่างโดยเนื้อแท้เพื่อคงงานที่เกินหน้าต่างบริบทเดียว; Codex เดิมไม่มีความสามารถนี้ในระดับเดียวกัน
- ความพร้อมของเครื่องมือ: Codex-Max ส่งมาพร้อมเป็นโมเดลเริ่มต้นทั่ว CLI, IDE และพื้นผิวรีวิวโค้ด สะท้อนการย้ายเวิร์กโฟลว์ของนักพัฒนาผลิตจริง
ควรใช้โมเดลใดเมื่อใด?
- ใช้ GPT-5.1-Codex สำหรับผู้ช่วยการเขียนโค้ดแบบโต้ตอบ การแก้ไขด่วน รีแฟคเตอร์ขนาดเล็ก และกรณีที่ต้องการความหน่วงต่ำซึ่งบริบทที่เกี่ยวข้องทั้งหมดพอดีในหน้าต่างเดียวได้ง่าย
- ใช้ GPT-5.1-Codex-Max สำหรับการรีแฟคเตอร์หลายไฟล์ งานเอเจนต์อัตโนมัติที่ต้องวนหลายรอบ เวิร์กโฟลว์แบบ CI/CD หรือเมื่อคุณต้องการให้โมเดลถือมุมมองระดับโปรเจ็กต์ข้ามการโต้ตอบหลายครั้ง
รูปแบบพรอมป์ที่ใช้งานได้จริง และตัวอย่างเพื่อผลลัพธ์ที่ดีที่สุด?
รูปแบบการเขียนพรอมป์ที่ได้ผลดี
- ระบุเป้าหมายและข้อจำกัดให้ชัดเจน: “Refactor X, preserve public API, keep function names, and ensure tests A,B,C pass.”
- ให้บริบทที่จำเป็นขั้นต่ำและทำซ้ำได้: ลิงก์ไปที่เทสต์ที่ล้มเหลว รวม stack trace และส่วนนำของไฟล์ที่เกี่ยวข้องแทนที่จะเทดทั้ง repository Codex-Max จะย่อประวัติเมื่อจำเป็น
- ใช้คำสั่งแบบทีละขั้นสำหรับงานซับซ้อน: แตกงานใหญ่เป็นลำดับของงานย่อย แล้วให้ Codex-Max วนทำตามนั้น (เช่น “1) run tests 2) fix top 3 failing tests 3) run linter 4) summarize changes”)
- ขอคำอธิบายและ diff: ขอทั้งแพตช์และเหตุผลสั้น ๆ เพื่อให้ผู้ตรวจทวนสามารถประเมินความปลอดภัยและเจตนาได้เร็ว
เทมเพลตพรอมป์ตัวอย่าง
งานรีแฟคเตอร์
“Refactor the
payment/module to extract payment processing intopayment/processor.py. Keep public function signatures stable for existing callers. Create unit tests forprocess_payment()that cover success, network failure, and invalid card. Run the test suite and return failing tests and a patch in unified diff format.”
แก้บั๊ก + ทดสอบ
“A test
tests/test_user_auth.py::test_token_refreshfails with traceback . Investigate root cause, propose a fix with minimal changes, and add a unit test to prevent regression. Apply patch and run tests.”
การสร้าง PR แบบวนรอบ
“Implement feature X: add endpoint
POST /api/exportwhich streams export results and is authenticated. Create the endpoint, add docs, create tests, and open a PR with summary and checklist of manual items.”
สำหรับส่วนใหญ่ เริ่มด้วยความพยายามระดับ medium; สลับไปที่ xhigh เมื่อคุณต้องการให้โมเดลใช้เหตุผลเชิงลึกข้ามหลายไฟล์และการวนเทสต์หลายรอบ
เข้าถึง GPT-5.1-Codex-Max ได้อย่างไร
ใช้ได้ที่ไหนวันนี้
OpenAI ได้ผสาน GPT-5.1-Codex-Max เข้าในเครื่องมือ Codex แล้ววันนี้: Codex CLI ส่วนขยาย IDE คลาวด์ และเวิร์กโฟลว์รีวิวโค้ดใช้ Codex-Max เป็นค่าเริ่มต้น (คุณสามารถเลือก Codex-Mini ได้) การเข้าถึง API อยู่ระหว่างการเตรียมเปิดให้บริการ; GitHub Copilot มีพรีวิวสาธารณะที่รวมโมเดลตระกูล GPT-5.1 และ Codex
นักพัฒนาสามารถเข้าถึง GPT-5.1-Codex-Max และ GPT-5.1-Codex API ผ่าน CometAPI เพื่อเริ่มต้น สำรวจความสามารถของโมเดลใน CometAPI ที่ Playground และดู API guide สำหรับคำแนะนำโดยละเอียด ก่อนเข้าถึง โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับคีย์ API แล้ว CometAPI เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการอย่างมากเพื่อช่วยให้คุณผสานรวมได้
พร้อมเริ่มใช้งานหรือยัง?→ สมัครใช้งาน CometAPI วันนี้ !
หากต้องการคำแนะนำ เคล็ดลับ และข่าวสารเกี่ยวกับ AI ติดตามเราได้ทาง VK, X และ Discord!
เริ่มต้นอย่างรวดเร็ว (ทีละขั้นตอนที่ใช้งานได้จริง)
- ตรวจสอบการเข้าถึง: ยืนยันว่าแผนผลิตภัณฑ์ ChatGPT/Codex ของคุณ (Plus, Pro, Business, Edu, Enterprise) หรือแผน API นักพัฒนารองรับโมเดลตระกูล GPT-5.1/Codex
- ติดตั้ง Codex CLI หรือส่วนขยาย IDE: หากต้องการรันงานโค้ดบนเครื่อง ให้ติดตั้ง Codex CLI หรือส่วนขยาย Codex IDE สำหรับ VS Code / JetBrains / Xcode ตามที่เกี่ยวข้อง เครื่องมือจะตั้งค่าเริ่มต้นเป็น GPT-5.1-Codex-Max ในสภาพแวดล้อมที่รองรับ
- เลือกระดับความพยายามด้านเหตุผล: เริ่มต้นด้วยระดับ medium สำหรับงานส่วนใหญ่ สำหรับการดีบักเชิงลึก รีแฟคเตอร์ที่ซับซ้อน หรือเมื่อคุณต้องการให้โมเดลคิดมากขึ้นและไม่กังวลเรื่องความหน่วง ให้สลับไปที่โหมด high หรือ xhigh สำหรับงานแก้ไขเล็ก ๆ เร็ว ๆ low ก็เหมาะสม
- ให้บริบทของ repository: ให้จุดเริ่มต้นที่ชัดเจนแก่โมเดล — URL ของ repo หรือชุดไฟล์พร้อมคำสั้น ๆ (เช่น “refactor the payment module to use async I/O and add unit tests, keep function-level contracts”). Codex-Max จะย่อประวัติเมื่อเข้าใกล้ขีดจำกัดบริบทและทำงานต่อ
- วนด้วยเทสต์: หลังจากโมเดลสร้างแพตช์แล้ว ให้รันชุดเทสต์และส่งกลับความล้มเหลวเป็นส่วนหนึ่งของเซสชันต่อเนื่อง การย่อและความต่อเนื่องหลายหน้าต่างช่วยให้ Codex-Max คงบริบทของเทสต์ที่ล้มเหลวสำคัญและวนแก้ไขได้
สรุป:
GPT-5.1-Codex-Max เป็นก้าวสำคัญสู่ผู้ช่วยการเขียนโค้ดเชิงตัวแทนที่สามารถคงงานวิศวกรรมที่ซับซ้อนและยาวนานได้ด้วยประสิทธิภาพและการให้เหตุผลที่ดีขึ้น ความก้าวหน้าทางเทคนิค (การย่อ โหมดความพยายามด้านเหตุผล การฝึกสภาพแวดล้อม Windows) ทำให้เหมาะอย่างยิ่งสำหรับองค์กรวิศวกรรมสมัยใหม่ — หากทีมจับคู่โมเดลกับการควบคุมเชิงปฏิบัติการแบบอนุรักษ์นิยม นโยบาย human-in-the-loop ที่ชัดเจน และการมอนิเตอร์ที่เข้มแข็ง สำหรับทีมที่ยอมรับใช้อย่างระมัดระวัง Codex-Max มีศักยภาพในการเปลี่ยนวิธีการออกแบบ ทดสอบ และดูแลรักษาซอฟต์แวร์ — เปลี่ยนงานวิศวกรรมที่ซ้ำซ้อนให้เป็นความร่วมมือที่มีมูลค่าสูงระหว่างมนุษย์และโมเดล