

DeepSeek ได้เปิดตัวแล้ว Deep Seek V3.2 เป็นผู้สืบทอดสาย V3.x และรุ่นที่มาพร้อมกับ DeepSeek-V3.2-พิเศษ รุ่นที่บริษัทจัดให้เป็นรุ่นที่เน้นการใช้เหตุผลประสิทธิภาพสูงสำหรับการใช้งานตัวแทน/เครื่องมือ V3.2 ต่อยอดจากงานทดลอง (V3.2-Exp) และนำเสนอความสามารถในการใช้เหตุผลขั้นสูง รุ่น Speciale ที่ปรับให้เหมาะสมสำหรับประสิทธิภาพการเขียนโปรแกรมเชิงคณิตศาสตร์/การแข่งขันระดับ "gold-level" และสิ่งที่ DeepSeek อธิบายว่าเป็นระบบ "การคิด + เครื่องมือ" แบบสองโหมดแรก ที่ผสานรวมการใช้เหตุผลแบบทีละขั้นตอนภายในเข้ากับการเรียกใช้เครื่องมือภายนอกและเวิร์กโฟลว์ของตัวแทนอย่างแนบแน่น
DeepSeek V3.2 คืออะไร และ V3.2-Speciale แตกต่างกันอย่างไร
DeepSeek-V3.2 คือเวอร์ชันอย่างเป็นทางการของ DeepSeek เวอร์ชันทดลอง V3.2-Exp ซึ่ง DeepSeek อธิบายว่าเป็น ครอบครัวโมเดล “การใช้เหตุผลก่อน” สร้างขึ้นสำหรับตัวแทนกล่าวคือ โมเดลที่ปรับแต่งไม่เพียงแต่สำหรับคุณภาพการสนทนาตามธรรมชาติเท่านั้น แต่ยังโดยเฉพาะสำหรับการอนุมานหลายขั้นตอน การเรียกใช้เครื่องมือ และการใช้เหตุผลแบบห่วงโซ่แห่งความคิดที่เชื่อถือได้ เมื่อใช้งานในสภาพแวดล้อมที่มีเครื่องมือภายนอก (API, การดำเนินการรหัส, ตัวเชื่อมต่อข้อมูล)
DeepSeek-V3.2 คืออะไร (พื้นฐาน)
- วางตำแหน่งเป็นผู้สืบทอดการผลิตหลักต่อจากสายผลิตภัณฑ์ทดลอง V3.2-Exp มุ่งหมายให้พร้อมใช้งานอย่างแพร่หลายผ่านแอป/เว็บ/API ของ DeepSeek
- รักษาสมดุลระหว่างประสิทธิภาพในการคำนวณและการใช้เหตุผลที่มั่นคงสำหรับงานของตัวแทน
DeepSeek-V3.2-Speciale คืออะไร
DeepSeek-V3.2-พิเศษ เป็นตัวแปรที่ DeepSeek ทำตลาดในฐานะ "Special Edition" ที่มีความสามารถสูงกว่า ซึ่งปรับแต่งมาเพื่อการใช้เหตุผลระดับการแข่งขัน คณิตศาสตร์ขั้นสูง และประสิทธิภาพของเอเจนต์ ตัวแปรนี้ทำตลาดในฐานะตัวแปรที่มีความสามารถสูงกว่าที่ "ก้าวข้ามขีดจำกัดของความสามารถในการใช้เหตุผล" ปัจจุบัน DeepSeek เปิดเผย Speciale ว่าเป็นโมเดลที่ใช้ API เท่านั้น พร้อมการกำหนดเส้นทางการเข้าถึงชั่วคราว ผลการทดสอบประสิทธิภาพในช่วงแรกชี้ให้เห็นว่า Speciale อยู่ในสถานะที่สามารถแข่งขันกับโมเดลปิดระดับไฮเอนด์ในด้านการใช้เหตุผลและการเขียนโค้ดได้
ทางเลือกด้านสายเลือดและวิศวกรรมใดบ้างที่นำไปสู่ V3.2?
V3.2 สืบทอดสายงานวิศวกรรมแบบวนซ้ำ DeepSeek ที่เผยแพร่ในปี 2025: V3 → V3.1 (Terminus) → V3.2-Exp (ขั้นตอนการทดลอง) → V3.2 → V3.2-Speciale V3.2-Exp เวอร์ชันทดลองได้เปิดตัว DeepSeek Sparse Attention (DSA) — กลไกการใส่ใจแบบเบาบางที่ละเอียด มุ่งเป้าไปที่การลดค่าใช้จ่ายด้านหน่วยความจำและการประมวลผลสำหรับบริบทที่มีความยาวมาก ขณะเดียวกันก็รักษาคุณภาพของผลลัพธ์ไว้ งานวิจัย DSA และงานลดต้นทุนดังกล่าวถือเป็นก้าวสำคัญทางเทคนิคสำหรับตระกูล V3.2 อย่างเป็นทางการ
มีอะไรใหม่ใน DeepSeek 3.2 อย่างเป็นทางการ?
1) ความสามารถในการใช้เหตุผลที่เพิ่มขึ้น — การใช้เหตุผลได้รับการปรับปรุงอย่างไร?
DeepSeek ทำตลาด V3.2 เป็น “การใช้เหตุผลก่อน” นั่นหมายถึงสถาปัตยกรรมและการปรับแต่งมุ่งเน้นไปที่การดำเนินการอนุมานหลายขั้นตอนอย่างน่าเชื่อถือ การรักษาห่วงโซ่ความคิดภายใน และการสนับสนุนตัวแทนการพิจารณาแบบมีโครงสร้างประเภทต่างๆ ที่จำเป็นในการใช้เครื่องมือภายนอกอย่างถูกต้อง
โดยการปรับปรุงที่เป็นรูปธรรมมีดังนี้:
- การฝึกอบรมและ RLHF (หรือขั้นตอนการจัดตำแหน่งที่คล้ายคลึงกัน) ได้รับการปรับแต่งเพื่อส่งเสริมการแก้ปัญหาแบบขั้นตอนที่ชัดเจนและสถานะกลางที่เสถียร (มีประโยชน์สำหรับการใช้เหตุผลทางคณิตศาสตร์ การสร้างโค้ดหลายขั้นตอน และงานตรรกะ)
- ตัวเลือกด้านสถาปัตยกรรมและการสูญเสียฟังก์ชันที่รักษาหน้าต่างบริบทที่ยาวขึ้นและอนุญาตให้โมเดลอ้างอิงขั้นตอนการใช้เหตุผลก่อนหน้านี้ด้วยความซื่อสัตย์
- โหมดปฏิบัติจริง (ดู "โหมดคู่" ด้านล่าง) ที่ให้โมเดลเดียวกันทำงานในโหมด "แชท" ที่เร็วกว่าหรือในโหมด "คิด" แบบไตร่ตรอง โดยจะทำงานผ่านขั้นตอนกลางโดยตั้งใจก่อนดำเนินการ
เกณฑ์มาตรฐานที่อ้างถึงรอบการเปิดตัวอ้างว่ามีการปรับปรุงอย่างเห็นได้ชัดในชุดการคำนวณทางคณิตศาสตร์และการใช้เหตุผล เกณฑ์มาตรฐานชุมชนอิสระในช่วงแรกยังรายงานคะแนนที่น่าประทับใจในชุดการประเมินการแข่งขันอีกด้วย
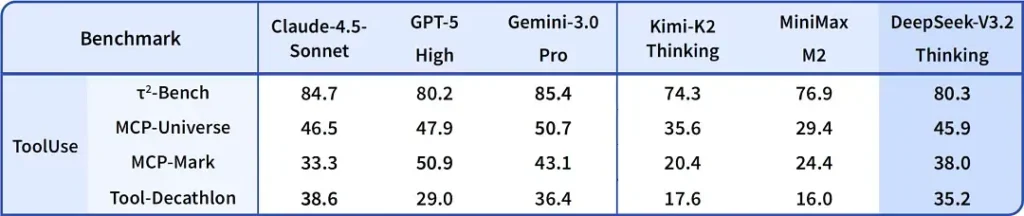
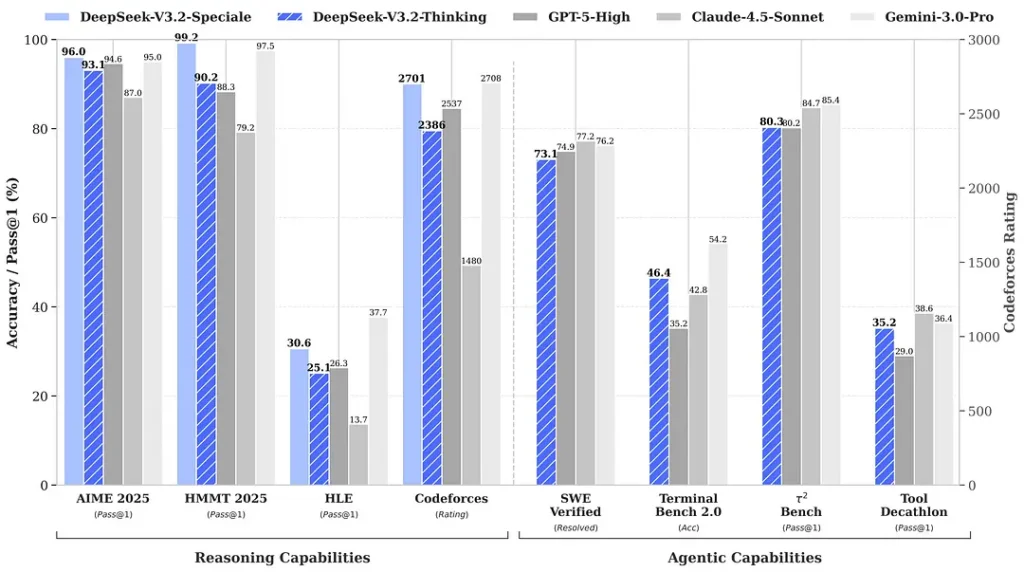
2) ประสิทธิภาพที่ก้าวล้ำในรุ่น Special Edition — ดีขึ้นมากแค่ไหน?
DeepSeek-V3.2-พิเศษ ได้รับการกล่าวอ้างว่าสามารถยกระดับความแม่นยำในการให้เหตุผลและการประสานงานของเอเจนต์ได้เมื่อเทียบกับ V3.2 มาตรฐาน ผู้ให้บริการได้กำหนดกรอบ Speciale ให้เป็นระดับประสิทธิภาพที่มุ่งเป้าไปที่เวิร์กโหลดการใช้เหตุผลจำนวนมากและงานเอเจนต์ที่ท้าทาย ปัจจุบันรองรับเฉพาะ API และนำเสนอเป็นอุปกรณ์ปลายทางชั่วคราวที่มีความสามารถสูงกว่า (DeepSeek ระบุว่าความพร้อมใช้งานของ Speciale จะมีจำกัดในเบื้องต้น) เวอร์ชัน Speciale ได้ผสานรวมแบบจำลองทางคณิตศาสตร์ DeepSeek-Math-V2 รุ่นก่อนหน้าเข้าด้วยกัน สามารถพิสูจน์ทฤษฎีบททางคณิตศาสตร์และตรวจสอบการใช้เหตุผลเชิงตรรกะได้ด้วยตัวเอง และประสบความสำเร็จอย่างโดดเด่นในการแข่งขันระดับโลกหลายรายการ:
- 🥇 เหรียญทอง IMO (โอลิมปิกคณิตศาสตร์นานาชาติ)
- 🥇 เหรียญทอง CMO (โอลิมปิกคณิตศาสตร์จีน)
- 🥈 รางวัลรองชนะเลิศอันดับ 2 จากการแข่งขันการเขียนโปรแกรมคอมพิวเตอร์นานาชาติ (ICPC) (Human Contest)
- 🥉 IOI (โอลิมปิกนานาชาติ สาขาวิทยาการคอมพิวเตอร์) อันดับที่ 10 (การแข่งขันมนุษย์)
| มาตรฐาน | GPT-5 สูง | เจมินี่-3.0 โปร | คิมิ-เค2 คิด | DeepSeek-V3.2 การคิด | DeepSeek-V3.2 พิเศษ |
|---|---|---|---|---|---|
| เอไอเอ็ม 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT กุมภาพันธ์ 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT พ.ย. 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| โค้ดฟอร์ซ | 2537 (29k) | 2708 (22k) | - | 2386 (42k) | 2701 (77k) |
| จีพีคิวเอ ไดมอนด์ | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| เอช.แอล | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) การนำระบบ “คิด + เครื่องมือ” แบบสองโหมดมาใช้เป็นครั้งแรก
หนึ่งในข้อเรียกร้องที่น่าสนใจที่สุดใน V3.2 คือ เวิร์กโฟลว์แบบสองโหมด ซึ่งแยก (และให้คุณเลือกได้ระหว่าง) การดำเนินการสนทนาแบบรวดเร็วและโหมด "การคิด" แบบไตร่ตรองที่ช้ากว่าซึ่งบูรณาการอย่างแนบแน่นกับการใช้เครื่องมือ
- โหมด “แชท / รวดเร็ว”: ออกแบบมาสำหรับการสนทนาที่ผู้ใช้ต้องเผชิญซึ่งมีความล่าช้าต่ำพร้อมคำตอบที่กระชับและการติดตามการใช้เหตุผลภายในน้อยลง เหมาะสำหรับการขอความช่วยเหลือทั่วไป คำถามและคำตอบสั้นๆ และแอปพลิเคชันที่เน้นเรื่องความเร็ว
- โหมด “คิด / ใช้เหตุผล”: ปรับให้เหมาะสมสำหรับลำดับความคิดที่เข้มงวด การวางแผนแบบเป็นขั้นตอน และการประสานเครื่องมือภายนอก (API, คิวรีฐานข้อมูล, การรันโค้ด) เมื่อใช้งานในโหมดคิด โมเดลจะสร้างขั้นตอนกลางที่ชัดเจนยิ่งขึ้น ซึ่งสามารถตรวจสอบหรือใช้เพื่อขับเคลื่อนการเรียกใช้เครื่องมือที่ปลอดภัยและถูกต้องในระบบเอเจนต์ได้
รูปแบบนี้ (การออกแบบสองโหมด) เคยปรากฏในสาขาทดลองก่อนหน้านี้ และ DeepSeek ได้ผสานรวมรูปแบบนี้เข้ากับ V3.2 และ Speciale ได้อย่างลึกซึ้งยิ่งขึ้น — ปัจจุบัน Speciale รองรับเฉพาะโหมดคิด (ดังนั้นจึงมี API gating) ความสามารถในการสลับระหว่างความเร็วและการไตร่ตรองนั้นมีประโยชน์ต่อวิศวกรรม เพราะช่วยให้นักพัฒนาสามารถเลือกจุดสมดุลระหว่างความหน่วงเวลาและความน่าเชื่อถือได้อย่างเหมาะสม เมื่อสร้างเอเจนต์ที่ต้องโต้ตอบกับระบบจริง
เพราะเหตุใดจึงน่าสังเกต: ระบบสมัยใหม่หลายระบบมีโมเดลลำดับความคิดที่แข็งแกร่ง (เพื่ออธิบายเหตุผล) หรือเลเยอร์การประสานตัวแทน/เครื่องมือแยกต่างหาก การวางกรอบของ DeepSeek แสดงให้เห็นถึงการเชื่อมโยงที่แน่นหนายิ่งขึ้น — โมเดลสามารถ "คิด" แล้วเรียกใช้เครื่องมือได้อย่างแม่นยำ โดยใช้การตอบสนองของเครื่องมือเพื่อแจ้งแนวคิดที่ตามมา — ซึ่งราบรื่นกว่าสำหรับนักพัฒนาที่สร้างตัวแทนอัตโนมัติ
ที่จะได้รับ ดีพซีค วี3.2
คำตอบสั้นๆ — คุณสามารถรับ DeepSeek v3.2 ได้หลายวิธี ขึ้นอยู่กับความต้องการของคุณ:
- เว็บ/แอปอย่างเป็นทางการ (ใช้ทางออนไลน์) — ลองใช้เว็บอินเทอร์เฟซหรือแอปมือถือ DeepSeek เพื่อใช้งาน V3.2 แบบโต้ตอบ
- การเข้าถึง API — DeepSeek เปิดเผย V3.2 ผ่าน API ของพวกเขา (เอกสารประกอบด้วยชื่อโมเดล / base_url และราคา) ลงทะเบียนเพื่อรับคีย์ API และเรียกใช้จุดสิ้นสุด v3.2
- น้ำหนักที่ดาวน์โหลดได้/เปิดได้ (กอดหน้า) — โมเดล (V3.2 / V3.2-Exp variants) ได้รับการเผยแพร่บน Hugging Face และสามารถดาวน์โหลดได้ (open-weight) ใช้งาน
huggingface-hubortransformersเพื่อดึงไฟล์ - โคเมทเอพีไอ — แพลตฟอร์มรวบรวม AI API ให้บริการโฮสต์ปลายทาง V3.2-Exp ราคาถูกกว่าราคาอย่างเป็นทางการ
ข้อควรทราบเชิงปฏิบัติสองสามข้อ:
- ถ้าคุณต้องการ น้ำหนักที่ต้องวิ่งในพื้นที่ไปที่หน้าโมเดล Hugging Face (ยอมรับเงื่อนไขใบอนุญาต/การเข้าถึงใดๆ ที่นั่น) และใช้
huggingface-cliortransformersในการดาวน์โหลด; ที่เก็บ GitHub มักจะแสดงคำสั่งที่แน่นอน - ถ้าคุณต้องการ การใช้งานการผลิตผ่าน APIทำตามแพลตฟอร์มที่คุณต้องการ เช่น เอกสาร API ของ cometapi สำหรับชื่อจุดสิ้นสุดและสิ่งที่ถูกต้อง
base_urlสำหรับรุ่น V3.2
DeepSeek-V3.2-พิเศษ:
- เปิดให้ใช้เพื่อการวิจัยเท่านั้น รองรับการสนทนา "โหมดการคิด" แต่ไม่รองรับการเรียกใช้เครื่องมือ
- เอาท์พุตสูงสุดสามารถเข้าถึงโทเค็น 128K (Thinking Chain ที่ยาวเป็นพิเศษ)
- ขณะนี้เปิดให้ทดลองใช้ฟรีถึงวันที่ 15 ธันวาคม 2025
ความคิดสุดท้าย
DeepSeek-V3.2 ถือเป็นก้าวสำคัญในการพัฒนาโมเดลที่เน้นการใช้เหตุผลให้สมบูรณ์แบบยิ่งขึ้น การผสมผสานระหว่างการใช้เหตุผลแบบหลายขั้นตอนที่ได้รับการปรับปรุง รุ่นประสิทธิภาพสูงเฉพาะทาง (Speciale) และการผสานรวม "การคิด + เครื่องมือ" ในรูปแบบการผลิต ถือเป็นสิ่งที่น่าจับตามองสำหรับทุกคนที่กำลังสร้างเอเจนต์ขั้นสูง ผู้ช่วยเขียนโค้ด หรือเวิร์กโฟลว์การวิจัยที่ต้องสลับการพิจารณากับการดำเนินการจากภายนอก
นักพัฒนาสามารถเข้าถึง DeepSeek V3.2 ผ่าน CometAPI เริ่มต้นด้วยการสำรวจความสามารถของโมเดล CometAPI ใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว ด้วยetAPI เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยคุณบูรณาการ
พร้อมไปหรือยัง?→ ลงทะเบียน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม โปรดติดตามเราที่ VK, X และ ไม่ลงรอยกัน!