

DeepSeek ได้เปิดตัว DeepSeek V3.2 ในฐานะรุ่นต่อจากสาย V3.x และมีรุ่น DeepSeek-V3.2-Speciale ควบคู่กัน ซึ่งบริษัทวางตำแหน่งให้เป็นรุ่นประสิทธิภาพสูงที่เน้นการให้เหตุผลเป็นอันดับแรกสำหรับการใช้งานแบบ agent/tool โดย V3.2 ต่อยอดจากงานทดลอง (V3.2-Exp) และเพิ่มความสามารถด้านการให้เหตุผลที่สูงขึ้น รุ่น Speciale ที่ปรับแต่งมาเพื่อประสิทธิภาพระดับ “gold-level” ในด้านคณิตศาสตร์/การแข่งขันเขียนโปรแกรม และสิ่งที่ DeepSeek อธิบายว่าเป็นระบบ “thinking + tool” แบบสองโหมดตัวแรกของโลก ที่ผสานการให้เหตุผลภายในแบบทีละขั้นตอนเข้ากับการเรียกใช้เครื่องมือภายนอกและเวิร์กโฟลว์ของเอเจนต์อย่างแน่นแฟ้น
DeepSeek V3.2 คืออะไร — และ V3.2-Speciale แตกต่างอย่างไร?
DeepSeek-V3.2 คือรุ่นทางการที่สืบทอดต่อจากสายทดลอง DeepSeek V3.2-Exp โดย DeepSeek อธิบายว่าเป็นตระกูลโมเดล “reasoning-first” ที่สร้างมาเพื่อ agents กล่าวคือ เป็นโมเดลที่ไม่ได้ปรับแต่งมาเพียงเพื่อคุณภาพการสนทนาตามธรรมชาติเท่านั้น แต่ยังมุ่งเน้นเป็นพิเศษไปที่การอนุมานหลายขั้นตอน การเรียกใช้เครื่องมือ และการให้เหตุผลแบบ chain-of-thought ที่เชื่อถือได้เมื่อทำงานในสภาพแวดล้อมที่มีเครื่องมือภายนอก (API, การรันโค้ด, data connectors)
DeepSeek-V3.2 (base) คืออะไร
- วางตำแหน่งเป็นรุ่นหลักสำหรับการใช้งานจริงที่สืบทอดต่อจากสายทดลอง V3.2-Exp; ตั้งใจให้พร้อมใช้งานอย่างกว้างขวางผ่านแอป/เว็บ/API ของ DeepSeek
- รักษาสมดุลระหว่างประสิทธิภาพการประมวลผลและความสามารถด้านการให้เหตุผลที่แข็งแกร่งสำหรับงาน agentic
DeepSeek-V3.2-Speciale คืออะไร
DeepSeek-V3.2-Speciale คือรุ่นย่อยที่ DeepSeek ทำตลาดว่าเป็น “Special Edition” ที่มีความสามารถสูงกว่า ปรับแต่งมาสำหรับการให้เหตุผลระดับการแข่งขัน คณิตศาสตร์ขั้นสูง และประสิทธิภาพของเอเจนต์ ทำตลาดในฐานะรุ่นที่มีความสามารถสูงกว่าซึ่ง “ผลักขอบเขตของความสามารถในการให้เหตุผล” ปัจจุบัน DeepSeek เปิดให้ใช้ Speciale ผ่าน API เท่านั้นพร้อมการกำหนดเส้นทางการเข้าถึงแบบชั่วคราว; benchmark ระยะแรกบ่งชี้ว่ารุ่นนี้ถูกวางตำแหน่งให้แข่งขันกับโมเดลปิดระดับสูงใน benchmark ด้านการให้เหตุผลและการเขียนโค้ด
สายพัฒนาและการตัดสินใจทางวิศวกรรมใดนำไปสู่ V3.2?
V3.2 สืบทอดมาจากสายวิวัฒนาการทางวิศวกรรมแบบต่อเนื่องที่ DeepSeek เผยแพร่ตลอดปี 2025: V3 → V3.1 (Terminus) → V3.2-Exp (ขั้นทดลอง) → V3.2 → V3.2-Speciale โดยรุ่นทดลอง V3.2-Exp ได้แนะนำ DeepSeek Sparse Attention (DSA) — กลไก sparse attention แบบละเอียดที่มุ่งลดต้นทุนหน่วยความจำและการคำนวณสำหรับ context ที่ยาวมาก ขณะเดียวกันยังคงคุณภาพของผลลัพธ์ไว้ งานวิจัย DSA และงานลดต้นทุนดังกล่าวจึงเป็นก้าวทางเทคนิคที่ปูทางไปสู่ตระกูล V3.2 อย่างเป็นทางการ
มีอะไรใหม่ใน DeepSeek 3.2 เวอร์ชันทางการ?
1) ความสามารถด้านการให้เหตุผลที่เพิ่มขึ้น — ปรับปรุงอย่างไร?
DeepSeek ทำตลาด V3.2 ว่าเป็นโมเดล “reasoning-first” ซึ่งหมายความว่าสถาปัตยกรรมและการปรับแต่งละเอียดมุ่งเน้นไปที่การทำอนุมานหลายขั้นตอนอย่างเชื่อถือได้ การคงไว้ซึ่ง chain of thought ภายใน และการรองรับการไตร่ตรองอย่างมีโครงสร้างในแบบที่เอเจนต์ต้องใช้เพื่อเรียกใช้เครื่องมือภายนอกได้อย่างถูกต้อง
ในเชิงรูปธรรม การปรับปรุงมีดังนี้:
- การฝึกและ RLHF (หรือกระบวนการ alignment ที่คล้ายกัน) ถูกปรับให้ส่งเสริมการแก้ปัญหาแบบเป็นขั้นตอนอย่างชัดเจนและสถานะขั้นกลางที่เสถียร (มีประโยชน์ต่อการให้เหตุผลทางคณิตศาสตร์ การสร้างโค้ดหลายขั้นตอน และงานตรรกะ)
- การเลือกสถาปัตยกรรมและฟังก์ชัน loss ที่ช่วยคงหน้าต่าง context ที่ยาวขึ้น และทำให้โมเดลอ้างอิงขั้นตอนการให้เหตุผลก่อนหน้าได้อย่างแม่นยำ
- โหมดการใช้งานจริง (ดู “dual-mode” ด้านล่าง) ที่ทำให้โมเดลเดียวกันทำงานได้ทั้งในโหมด “chat” ที่เร็วกว่า หรือในโหมด “thinking” ที่ไตร่ตรอง ซึ่งตั้งใจทำงานผ่านขั้นตอนขั้นกลางก่อนลงมือดำเนินการ
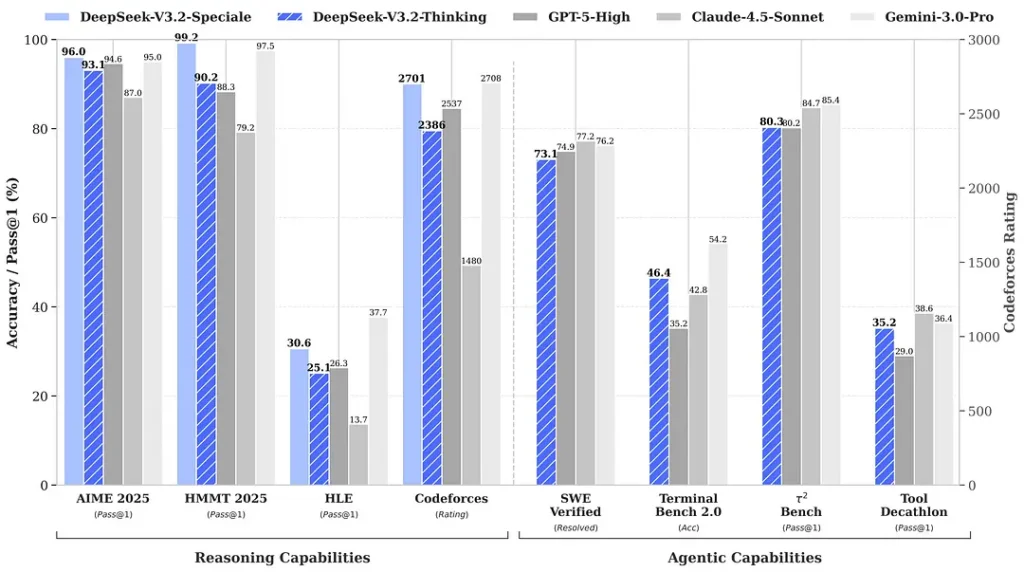
benchmark ที่อ้างถึงในช่วงเปิดตัวระบุว่ามีการเพิ่มขึ้นอย่างชัดเจนในชุดทดสอบด้านคณิตศาสตร์และการให้เหตุผล; benchmark ชุมชนอิสระในช่วงแรกก็รายงานคะแนนที่น่าประทับใจในชุดประเมินเชิงแข่งขันเช่นกัน:
2) ประสิทธิภาพก้าวกระโดดในรุ่น Special Edition — ดีขึ้นมากแค่ไหน?
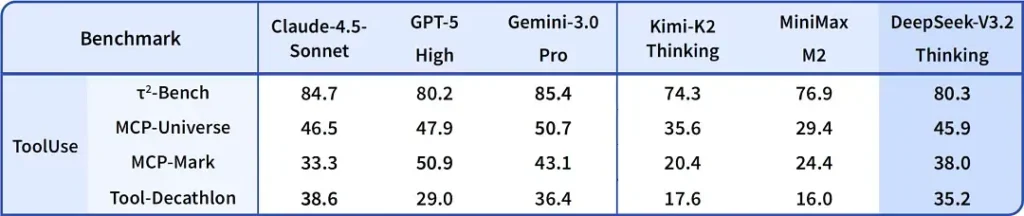
DeepSeek-V3.2-Speciale ถูกอ้างว่าส่งมอบความแม่นยำในการให้เหตุผลและการ orchestration ของเอเจนต์ที่เหนือกว่ารุ่น V3.2 มาตรฐาน ผู้ให้บริการวางกรอบให้ Speciale เป็นระดับประสิทธิภาพที่มุ่งเป้าไปยังเวิร์กโหลดการให้เหตุผลหนักและงานเอเจนต์ที่ท้าทาย; ปัจจุบันมีให้ใช้งานผ่าน API เท่านั้นและถูกนำเสนอในฐานะ endpoint ชั่วคราวที่มีความสามารถสูงกว่า (DeepSeek ระบุว่าการใช้งาน Speciale จะถูกจำกัดในช่วงแรก) รุ่น Speciale ผสานโมเดลคณิตศาสตร์ก่อนหน้าคือ DeepSeek-Math-V2; สามารถพิสูจน์ทฤษฎีบททางคณิตศาสตร์และตรวจสอบการให้เหตุผลเชิงตรรกะได้ด้วยตัวเอง; และทำผลงานโดดเด่นในหลายการแข่งขันระดับโลก:
- 🥇 IMO (International Mathematical Olympiad) เหรียญทอง
- 🥇 CMO (Chinese Mathematical Olympiad) เหรียญทอง
- 🥈 ICPC (International Computer Programming Contest) อันดับสอง (การแข่งขันของมนุษย์)
- 🥉 IOI (International Olympiad in Informatics) อันดับที่สิบ (การแข่งขันของมนุษย์)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) การใช้งานระบบ “thinking + tool” แบบสองโหมดครั้งแรก
หนึ่งในคำกล่าวอ้างที่น่าสนใจที่สุดในทางปฏิบัติของ V3.2 คือเวิร์กโฟลว์แบบ dual-mode ที่แยกออกจากกัน (และให้คุณเลือกได้) ระหว่างการทำงานเชิงสนทนาแบบรวดเร็วกับโหมด “thinking” ที่ช้ากว่าแต่ไตร่ตรองมากกว่า ซึ่งผสานเข้ากับการใช้เครื่องมืออย่างแนบแน่น
- โหมด “Chat / fast”: ออกแบบมาสำหรับแชตที่ตอบสนองต่ำและเผชิญหน้ากับผู้ใช้ ให้คำตอบกระชับและมีร่องรอยการให้เหตุผลภายในน้อยกว่า — เหมาะสำหรับการช่วยเหลือทั่วไป คำถาม-คำตอบสั้น ๆ และแอปพลิเคชันที่ไวต่อความเร็ว
- โหมด “Thinking / reasoner”: ปรับให้เหมาะกับ chain-of-thought ที่เข้มงวด การวางแผนแบบเป็นขั้นตอน และการ orchestration เครื่องมือภายนอก (API, การ query ฐานข้อมูล, การรันโค้ด) เมื่อทำงานในโหมด thinking โมเดลจะสร้างขั้นตอนขั้นกลางที่ชัดเจนมากขึ้น ซึ่งสามารถตรวจสอบได้หรือใช้ขับเคลื่อนการเรียกใช้เครื่องมืออย่างปลอดภัยและถูกต้องในระบบ agentic
รูปแบบนี้ (การออกแบบสองโหมด) มีอยู่ในสายทดลองก่อนหน้านี้ และ DeepSeek ได้นำมาผสานอย่างลึกซึ้งยิ่งขึ้นใน V3.2 และ Speciale — โดยปัจจุบัน Speciale รองรับเฉพาะโหมด thinking เท่านั้น (จึงมีการจำกัดผ่าน API) ความสามารถในการสลับระหว่างความเร็วและการไตร่ตรองมีคุณค่าต่อวิศวกรรมอย่างมาก เพราะช่วยให้นักพัฒนาสามารถเลือกจุดสมดุลที่เหมาะสมระหว่าง latency กับ reliability เมื่อสร้างเอเจนต์ที่ต้องโต้ตอบกับระบบโลกจริง
เหตุใดจึงน่าสังเกต: ระบบสมัยใหม่จำนวนมากมักให้มาอย่างใดอย่างหนึ่งระหว่างโมเดล chain-of-thought ที่แข็งแกร่ง (เพื่ออธิบายการให้เหตุผล) หรือเลเยอร์ orchestration เอเจนต์/เครื่องมือแยกต่างหาก มุมมองของ DeepSeek ชี้ให้เห็นถึงการเชื่อมโยงที่แน่นแฟ้นกว่า — โมเดลสามารถ “คิด” แล้วเรียกใช้เครื่องมืออย่างกำหนดได้แน่นอน จากนั้นใช้คำตอบจากเครื่องมือมาเป็นข้อมูลสำหรับการคิดในลำดับถัดไป — ซึ่งไร้รอยต่อมากกว่าสำหรับนักพัฒนาที่สร้าง autonomous agents
จะหา DeepSeek v3.2 ได้จากที่ไหน
คำตอบสั้น ๆ — คุณสามารถใช้ DeepSeek v3.2 ได้หลายวิธีขึ้นอยู่กับสิ่งที่คุณต้องการ:
- เว็บ/แอปทางการ (ใช้งานออนไลน์) — ลองใช้เว็บอินเทอร์เฟซหรือแอปมือถือของ DeepSeek เพื่อใช้งาน V3.2 แบบอินเทอร์แอกทีฟ
- การเข้าถึงผ่าน API — DeepSeek เปิดให้ใช้ V3.2 ผ่าน API ของตน (เอกสารประกอบมีชื่อโมเดล /
base_urlและราคา) สมัคร API key แล้วเรียกใช้ endpoint ของ v3.2 - น้ำหนักโมเดลแบบดาวน์โหลดได้/โอเพนเวต (Hugging Face) — โมเดล (รุ่น V3.2 / V3.2-Exp) ถูกเผยแพร่บน Hugging Face และสามารถดาวน์โหลดได้ (open-weight) ใช้
huggingface-hubหรือtransformersเพื่อดึงไฟล์ - CometAPI — แพลตฟอร์มรวม AI API ที่ให้บริการ endpoint แบบโฮสต์สำหรับ V3.2-Exp ราคาถูกกว่าราคาทางการ
หมายเหตุเชิงปฏิบัติเล็กน้อย:
- หากคุณต้องการ weights เพื่อรันบนเครื่องของคุณเอง ให้ไปที่หน้าโมเดลบน Hugging Face (ยอมรับเงื่อนไขใบอนุญาต / การเข้าถึงตามที่กำหนด) แล้วใช้
huggingface-cliหรือtransformersเพื่อดาวน์โหลด; โดยปกติ repo บน GitHub จะแสดงคำสั่งที่แน่นอนไว้ - หากคุณต้องการ ใช้งานจริงผ่าน API, ให้ทำตามเอกสารของแพลตฟอร์มที่คุณต้องการ เช่น เอกสาร API ของ cometapi สำหรับชื่อ endpoint และ
base_urlที่ถูกต้องของรุ่น V3.2
DeepSeek-V3.2-Speciale:* เปิดสำหรับการใช้งานวิจัยเท่านั้น รองรับบทสนทนา “Thinking Mode” แต่ไม่รองรับการเรียกใช้เครื่องมือ
- เอาต์พุตสูงสุดสามารถยาวได้ถึง 128K โทเค็น (Thinking Chain แบบยาวพิเศษ)
- ขณะนี้เปิดให้ทดสอบฟรีจนถึงวันที่ 15 ธันวาคม 2025
ข้อคิดเห็นส่งท้าย
DeepSeek-V3.2 เป็นก้าวที่มีความหมายในการเติบโตของโมเดลที่เน้นการให้เหตุผลเป็นศูนย์กลาง การผสมผสานระหว่างการให้เหตุผลหลายขั้นตอนที่ดีขึ้น รุ่นเฉพาะทางประสิทธิภาพสูง (Speciale) และการผสาน “thinking + tool” ที่พร้อมใช้งานจริงในการผลิต เป็นสิ่งที่น่าสนใจสำหรับทุกคนที่กำลังสร้างเอเจนต์ขั้นสูง ผู้ช่วยเขียนโค้ด หรือเวิร์กโฟลว์ด้านการวิจัยที่ต้องสลับระหว่างการไตร่ตรองกับการกระทำภายนอก
นักพัฒนาสามารถเข้าถึง DeepSeek V3.2 ผ่าน CometAPI ได้ หากต้องการเริ่มต้น ให้สำรวจความสามารถของโมเดลบน CometAPI ใน Playground และดู คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับ API key แล้ว CometAPI เสนอราคาที่ต่ำกว่าราคาทางการมากเพื่อช่วยให้คุณผสานรวมได้ง่ายขึ้น
พร้อมเริ่มใช้งานหรือยัง?→ สมัครใช้งาน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คู่มือ และข่าวสารเกี่ยวกับ AI เพิ่มเติม ติดตามเราได้ที่ VK, X และ Discord!