

Gemini Embedding 2 คือโมเดลฝังความหมาย (embedding) แบบ multimodal โดยกำเนิด ตัวแรกของ Google ที่แมปข้อความ รูปภาพ เสียง วิดีโอ และ PDF เข้าสู่พื้นที่เวกเตอร์เชิงความหมายมิติ 3,072 หน่วยเดียว (พร้อมตัวเลือกปรับขนาดเอาต์พุตได้) นำเสนอ Matryoshka Representation Learning เพื่อให้ได้ embedding แบบซ้อน/ตัดทอน ประสิทธิภาพหลายภาษาที่ดีขึ้น (100+ ภาษา) และการควบคุมที่ปรับให้เหมาะกับงานเฉพาะ (เช่น task:search, task:code)
Gemini Embedding 2 คืออะไร?
Gemini Embedding 2 คือโมเดล embedding แบบรวมจาก Google ที่แมปอินพุตหลายโมดาลิตี — ข้อความ รูปภาพ เสียง วิดีโอ และเอกสาร — เข้าสู่พื้นที่เวกเตอร์เชิงความหมายเดียว แต่ละ embedding โดยค่าเริ่มต้นเป็นเวกเตอร์จำนวนจริงแบบลอยตัวความยาว 3,072 มิติที่แทนความหมายเชิงความหมายของอินพุต เพื่อให้รายการที่มีความหมายใกล้เคียงกัน (ไม่ขึ้นกับโมดาลิตี) อยู่ใกล้กันในพื้นที่เวกเตอร์ ความสามารถเด่น ได้แก่:
- รองรับภาษาและรูปแบบกว้าง: โมเดลเดียวที่รับข้อความ รูปภาพ เสียง วิดีโอ และเอกสาร และวางไว้ในพื้นที่เวกเตอร์เชิงความหมายเดียว Gemini Embedding 2 มีรายงานว่าสามารถจับเจตนาเชิงความหมายได้ครอบคลุม 100+ ภาษา และรับรูปแบบไฟล์ทั่วไป (PNG/JPEG, MP4/MOV, MP3/WAV, PDF) พร้อมขีดจำกัดต่อคำขอที่ระบุไว้อย่างชัดเจน (เช่น สูงสุดไม่กี่รูปภาพต่อคำขอ หรือเสียง/วิดีโอความยาวหลายสิบวินาที—ดู “วิธีใช้งาน” ด้านล่าง)
- มัลติโมดาลิตี้อย่างแท้จริง: โมเดลเดียวที่รับข้อความ รูปภาพ เสียง วิดีโอ และเอกสาร และวางไว้ในพื้นที่เวกเตอร์เชิงความหมายเดียว เพื่อให้สามารถเปรียบเทียบหรือค้นหาข้ามโมดาลิตี (เช่น ข้อความ → รูปภาพ, เสียง → ข้อความ)
- มิติโดยค่าเริ่มต้นขนาดใหญ่พร้อมการตัดทอนได้อย่างยืดหยุ่น: โมเดลส่งออกเวกเตอร์ความยาว 3072 มิติ โดยค่าเริ่มต้น แต่ใช้ Matryoshka Representation Learning (MRL) เพื่อรวบรวมสาระสำคัญเชิงความหมายไว้ในมิติแรกๆ ทำให้สามารถตัดทอนเหลือ 1536, 768 (หรือต่ำกว่านั้น) โดยคุณภาพการค้นคืนลดลงเพียงเล็กน้อย ช่วยลดต้นทุนการจัดเก็บและการประมวลผล
เหตุผลที่สำคัญ: ในอดีต embedding มักเป็นแบบข้อความเท่านั้นหรือจำเป็นต้องมี encoder แยกต่อโมดาลิตีพร้อมเลเยอร์จัดแนวข้ามโมดาลิตีที่ซับซ้อน Gemini Embedding 2 ขจัดอุปสรรคดังกล่าวด้วยการรองรับหลายรูปแบบโดยกำเนิด—ทำให้คำค้นเป็นข้อความสามารถค้นหารูปภาพหรือคลิปสั้นๆ ตามความคล้ายคลึงเชิงความหมายได้โดยไม่ต้องถอดเสียงหรือแมปด้วยมือก่อน ช่วยให้ RAG (retrieval-augmented generation), การค้นหาเชิงความหมาย และท่อการค้นคืนแบบมัลติโมดาลง่ายขึ้น
คุณสมบัติและความสามารถหลัก (มีอะไรใหม่)
1. มัลติโมดาลโดยกำเนิดจริง (พื้นที่ embedding เดียว)
โมเดลเดียวที่รับข้อความ รูปภาพ เสียง วิดีโอ และเอกสาร และวางไว้ในพื้นที่เวกเตอร์เชิงความหมายเดียว Gemini Embedding 2 แมปข้อความ รูปภาพ เสียง วิดีโอ และเอกสารเข้าสู่พื้นที่ embedding เดียวกัน ทำให้การค้นคืนข้ามโมดาลิตี (ข้อความ→รูปภาพ, เสียง→ข้อความ) ใช้งานได้โดยตรงโดยไม่ต้องจัดแนวข้ามโมเดล ลดความซับซ้อนของไปป์ไลน์และทำให้สแต็ก RAG (Retrieval-Augmented Generation) ง่ายขึ้น
2. เวกเตอร์ค่าเริ่มต้น 3,072 มิติพร้อมการปรับขนาดเอาต์พุต
Gemini Embedding 2 ส่งออกเวกเตอร์ความยาว 3072 มิติ โดยค่าเริ่มต้น แต่ใช้ Matryoshka Representation Learning (MRL) เพื่อรวบรวมเนื้อหาสำคัญเชิงความหมายไว้ในมิติแรกๆ จึงสามารถตัดทอนเหลือ 1536, 768 (หรือต่ำกว่านั้น) โดยมีการลดคุณภาพการค้นคืนเพียงเล็กน้อย ช่วยลดต้นทุนพื้นที่เก็บและการคำนวณ
3. Matryoshka Representation Learning (MRL)
MRL สร้าง embedding แบบ “ซ้อนชั้น”—เหมือนตุ๊กตารัสเซีย—ทำให้ส่วนตัดทอนที่มีมิติน้อยยังคงรักษาความหมายระดับสูงไว้ได้ ช่วยให้ระบบเลือกจุดทำงาน (สมดุลพื้นที่จัดเก็บ/ความแม่นยำ) โดยไม่ต้องคงหลายโมเดล embedding แยกกัน บทวิเคราะห์และเอกสารช่วงแรกอธิบายเทคนิคนี้ว่าเป็นนวัตกรรมหลักเพื่อความยืดหยุ่น
4. ตัวบอกใบ้งาน / วัตถุประสงค์ embedding แบบปรับแต่ง
API รองรับตัวบอกใบ้ task (เช่น task:search, task:code retrieval, task:semantic-similarity) เพื่อให้โมเดลปรับปรุงรูปทรงเรขาคณิตของ embedding ให้เหมาะกับความสัมพันธ์ปลายทางเฉพาะ คล้ายการปรับตามงานในระบบ embedding รุ่นก่อนแต่ขยายสู่ข้อมูลแบบมัลติโมดาล
5. ความกว้างของภาษาและโมดาลิตี
มีรายงานว่าสามารถจับเจตนาเชิงความหมายได้ครอบคลุม 100+ ภาษา และรับรูปแบบไฟล์ทั่วไป (PNG/JPEG, MP4/MOV, MP3/WAV, PDF) พร้อมขีดจำกัดต่อคำขอที่ชัดเจน (เช่น สูงสุดไม่กี่รูปภาพต่อคำขอ หรือเสียง/วิดีโอความยาวหลายสิบวินาที—ดู “วิธีใช้งาน” ด้านล่าง)
ตัวชี้วัดประสิทธิภาพ
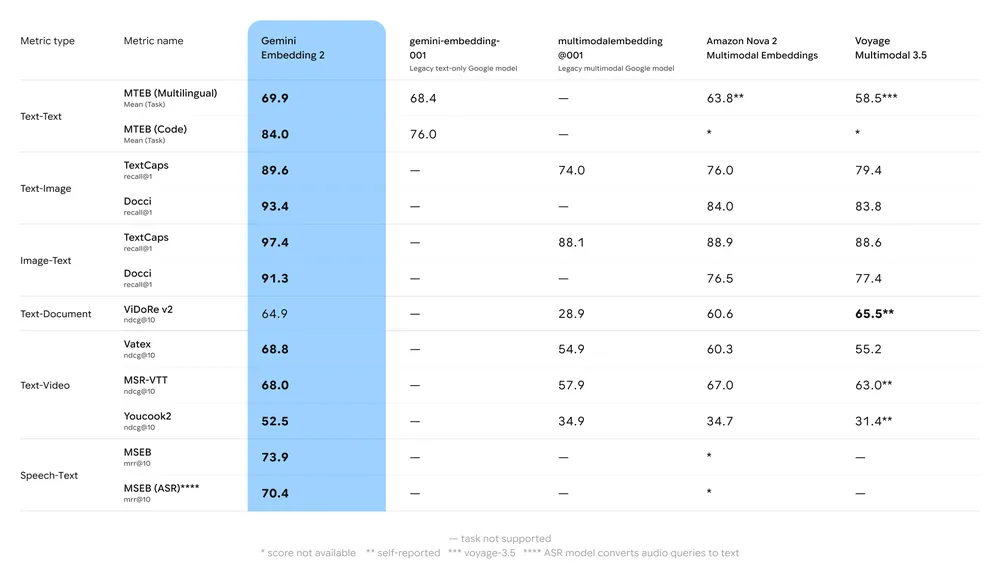
สรุปตัวชี้วัดสำคัญ:
- MTEB (Massive Text Embedding Benchmark): มีรายงานว่าทำอันดับได้ดีบนกระดานผู้นำ MTEB แบบหลายภาษาสำหรับงานภาษาอังกฤษและงานหลายภาษา; การวิเคราะห์ชี้ให้เห็นถึงการยกระดับอย่างมีนัยสำคัญเมื่อเทียบกับโมเดล embedding รุ่นก่อนของ Gemini และตัวเลือกเชิงพาณิชย์อื่นๆ หลายตัว
- การค้นคืนแบบมัลติโมดาล: ทำได้ดีกว่าหรือทัดเทียม embedding แบบโมดาลเดียวชั้นนำเมื่อใช้สำหรับความคล้ายคลึงข้ามโมดาลิตี (เช่น การค้นคืนข้อความ→รูปภาพ) อันเป็นผลจากการฝึกแบบมัลติโมดาลโดยกำเนิด
- เวลาแฝงและอัตราส่งผ่าน: การสร้าง embedding โฮสต์บนคลาวด์ แต่กรณีที่ไวต่อเวลาแฝงอาจเลือกใช้เวกเตอร์แบบตัดทอนหรือโมเดล embedding น้ำหนักเบาทางเลือกสำหรับงาน on-edge
Gemini Embedding 2 เทียบกับ gemini-embedding-001 และ text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| Modalities supported | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| Default embedding dim. | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| Native audio/video support | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| Typical use cases | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
ข้อมูลเชิงเทคนิคและขีดจำกัด
ขนาด embedding ค่าเริ่มต้นและแบบปรับได้
- ค่าเริ่มต้น: 3,072 มิติ
- ปรับได้: พารามิเตอร์
output_dimensionalityช่วยให้ขอเอาต์พุตที่มีมิติน้อยลงเพื่อประหยัดพื้นที่จัดเก็บ/CPU กรณีใช้งานที่มีคลังเวกเตอร์ขนาดใหญ่มากมักลดมิติเหลือ 512–1,024 เพื่อเหตุผลด้านต้นทุน โดยยอมรับความแม่นยำที่ลดลงบ้าง
โมดาลิตีที่รองรับและขีดจำกัดต่อคำขอ
- รูปภาพ: PNG, JPEG — สูงสุด 6 รูปภาพต่อคำขอ (ตามรายงานผู้ให้บริการ)
- วิดีโอ: MP4, MOV — ผู้ให้บริการรายงานว่าสูงสุดประมาณ 128 วินาทีต่อวิดีโอสำหรับการฝังในคำขอเดียว
- เสียง: MP3, WAV — ผู้ให้บริการรายงานว่าสูงสุดประมาณ 80 วินาทีต่ออินพุตเสียง
- เอกสาร: PDF — สูงสุด 6 หน้า/คำขอ (ตามรายงานผู้ให้บริการ)
- ขีดจำกัดโทเค็นสำหรับข้อความ: โมเดลรองรับอินพุตโทเค็นจำนวนมาก; มีขีดจำกัดโทเค็นต่อคำขอในทางปฏิบัติ (ตรวจสอบเอกสาร API และโควตา Vertex AI)
ความพร้อมใช้งานและการเข้าถึง
- Public preview: Gemini Embedding 2 เปิดตัวเป็น public preview และพร้อมใช้งานผ่าน Gemini API และ Google Cloud’s Vertex AI สำหรับการทดลองใช้งานทันที
คำถามที่พบบ่อย (FAQ)
Q1: โมเดล Gemini Embedding 2 รองรับโมดาลิตีใดบ้าง?
A: ข้อความ รูปภาพ (PNG/JPEG), วิดีโอ (MP4/MOV), เสียง (MP3/WAV) และเอกสาร PDF — ทั้งหมดถูกแมปเข้าสู่พื้นที่เวกเตอร์เชิงความหมายเดียวกัน
Q2: ขนาดเวกเตอร์เริ่มต้นของ Gemini Embedding 2 คือเท่าไร?
A: เริ่มต้นที่ 3,072 มิติ คุณสามารถขอเอาต์พุตที่มีมิติน้อยลงผ่าน API ได้
Q3: Gemini Embedding 2 พร้อมใช้งานแล้วหรือไม่?
A: พร้อมแล้ว — เปิดตัวเป็น public preview และใช้งานผ่าน Gemini API และ Vertex AI (ตรวจสอบรหัสโมเดล gemini-embedding-2-preview และบันทึกการเปลี่ยนแปลงล่าสุด)
Q4: เมื่อเทียบกับ embedding จากผู้ให้บริการรายอื่นเป็นอย่างไร?
A: การทดสอบโดยผู้ให้บริการอิสระรายงานว่า Gemini Embedding 2 อยู่ในกลุ่มโมเดลเชิงพาณิชย์ชั้นนำสำหรับข้อความหลายภาษา และแสดงประสิทธิภาพระดับ state-of-the-art สำหรับงานมัลติโมดาลบางรายการ อันดับที่แน่นอนขึ้นกับงานและชุดข้อมูล; ควรทดสอบกับข้อมูลของคุณเอง
Q5: จำเป็นต้องถอดเสียง (transcribe) เสียงก่อนใช้ Gemini Embedding 2 หรือไม่?
A: ไม่จำเป็น — Gemini Embedding 2 รับเสียงโดยตรงและสร้าง embedding ได้โดยไม่ต้องถอดเสียงก่อน ช่วยให้ค้นคืนความหมายจากเสียงแบบ end-to-end
Q6: จะลดต้นทุนพื้นที่จัดเก็บสำหรับเวกเตอร์ 3,072 มิติได้อย่างไร?
A: ตัวเลือกได้แก่ การขอ output_dimensionality ที่ต่ำลง การใช้ float16/quantization/PQ และการเก็บตัวแทนแบบบีบอัดในฐานข้อมูลเวกเตอร์ของคุณ โพสต์จากผู้ให้บริการมีเวิร์กโฟลว์และแนวปฏิบัติที่ดีที่สุด
ต่อไปคืออะไร — ควรนำไปใช้ตอนนี้หรือไม่?
Gemini Embedding 2 เป็นก้าวสำคัญในการรวมการค้นคืนแบบมัลติโมดาลและทำให้ง่ายขึ้นสำหรับสถาปัตยกรรมที่ก่อนหน้านี้ต้องใช้ตัวค้นคืนแยกสำหรับข้อความ ภาพ และเสียง ประเด็นตัดสินใจสำคัญสำหรับการนำไปใช้:
- ควรนำไปใช้เร็วขึ้น หากผลิตภัณฑ์ของคุณต้องการการค้นคืนข้ามโมดาลิตีที่แข็งแกร่ง (ข้อความ↔รูปภาพ/วิดีโอ/เสียง) หรือหากการดูแลตัวค้นคืนแบบโมดาลเดียวหลายตัวมีต้นทุนและความซับซ้อนสูง
- ทดสอบนำร่องตอนนี้ หากต้องการประเมินการตัดทอนแบบ MRL และวัดต้นทุนเทียบคุณภาพ (คงการปรับใช้แบบผสม: 1536 เป็นหลัก, 3072 สำหรับการจัดอันดับซ้ำ)
- รอก่อนหาก งานของคุณไวต่อราคามากและต้องการเพียงการค้นคืนข้อความ — โมเดลข้อความเท่านั้นระดับท็อป (เช่น OpenAI text-embedding-3-large) ยังคงแข่งขันได้และบางครั้งมีต้นทุนต่ำกว่า ขึ้นกับไปป์ไลน์และสัญญาของคุณ
นักพัฒนาสามารถเข้าถึง Gemini Embedding 2 และ OpenAI text-embedding-3 API ผ่าน CometAPI ได้แล้ว เริ่มต้นโดยสำรวจความสามารถของโมเดลใน Playground และดูรายละเอียดใน คู่มือ API ก่อนการเข้าถึง โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับคีย์ API แล้ว CometAPI มีราคาโดยรวมต่ำกว่าราคาทางการเพื่อช่วยให้คุณผสานระบบได้ง่ายขึ้น
พร้อมเริ่มต้นหรือยัง?→ Sign up for cometapi today!
หากต้องการเคล็ดลับ คู่มือ และข่าวสารด้าน AI เพิ่มเติม ติดตามเราได้ที่ VK, X และ Discord!