
.webp&w=3840&q=75)
GLM-5.1 เป็นจุดเปลี่ยนสำคัญในภูมิทัศน์ของ AI เมื่อบริษัท AI จีนเร่งทำให้เชิงพาณิชย์ควบคู่กับการเปิดซอร์สขีดความสามารถแนวหน้า โมเดลนี้ลดช่องว่างกับผู้นำเชิงกรรมสิทธิ์อย่าง GPT-5.4 ของ OpenAI, Claude Opus 4.6 ของ Anthropic และ Gemini 3.1 Pro ของ Google—โดยเฉพาะในงานวิศวกรรมซอฟต์แวร์โลกจริง ถูกฝึกบนสถาปัตยกรรม MoE พารามิเตอร์ 744B แบบเดียวกับ GLM-5 แต่ปรับแต่งอย่างหนักสำหรับเวิร์กโฟลว์เชิงเอเจนต์ โดดเด่นในจุดที่ LLM ส่วนใหญ่สะดุด: งานยาว คลุมเครือ วนซ้ำ ที่ต้องอาศัยการวางแผน ทดลอง ดีบัก และแก้ไขตนเองตลอดการเรียกใช้เครื่องมือหลายพันครั้ง
ตอนนี้ CometAPI ผสาน GLM-5.1 และ GLM-5 แล้ว และนักพัฒนาสามารถดูโมเดลชั้นนำจากตะวันตกอื่นๆ และเข้าถึงได้ในราคา API ที่ต่ำมาก (ซึ่งเป็นข้อได้เปรียบของ CometAPI เมื่อเทียบกับคู่แข่งรายอื่น)
GLM-5.1 คืออะไร?
GLM-5.1 คือโมเดลภาษาหลักรุ่นเรือธงล่าสุดของ Z.ai และเป็นความเคลื่อนไหวล่าสุดสู่การทำงานเชิงเอเจนต์ระยะยาว ในคำอธิบายของ Z.ai มันถูกออกแบบมาสำหรับงานที่ต้องการการดำเนินการอย่างต่อเนื่อง ไม่ใช่คำตอบแบบครั้งเดียว และถูกวางตำแหน่งให้เป็นโมเดลที่สามารถวางแผน ดำเนินการ ปรับปรุง และส่งมอบได้ภายในการรันยาวครั้งเดียว โน้ตการเปิดตัวระบุว่า GLM-5.1 ถูกสร้างด้วยการปรับจูนแบบกำกับหลายรอบ การเรียนรู้แบบเสริมแรง และกรอบประเมินคุณภาพกระบวนการ และว่ามันเพิ่มเสถียรภาพ ความสม่ำเสมอ และการใช้เครื่องมือในการทำงานระยะยาว
การวางตำแหน่งนี้สำคัญเพราะ GLM-5.1 ไม่ได้ถูกขายเป็นเพียง “อีกโมเดลแชตหนึ่ง” แต่มุ่งไปที่เวิร์กโฟลว์วิศวกรรมที่โมเดลต้องยึดเป้าหมายไว้ในใจ จัดการขั้นตอนกลาง และกู้คืนจากความผิดพลาดโดยไม่หลุดแกน จึงถูกวางให้เป็นโมเดลสำหรับการวางแผนอัตโนมัติ การดำเนินงานอย่างต่อเนื่อง แก้บั๊ก และวนกลยุทธ์ ซึ่งเป็นเรื่องราวผลิตภัณฑ์ที่ต่างจากผู้ช่วยทั่วไปหรือโคไพลอตโค้ดบริบทสั้น
รายละเอียดเชิงปฏิบัติที่เป็นประโยชน์: GLM-5.1 รองรับเฉพาะข้อความ รองรับใน GLM Coding Plan และใช้กับเอเจนต์โค้ดยอดนิยมอย่าง Claude Code และ OpenClaw ได้ จึงเหมาะเป็นพิเศษสำหรับทีมที่ต้องการให้โมเดลฝังอยู่ในเวิร์กโฟลว์นักพัฒนาที่มีอยู่แทนที่จะมาแทนที่มัน
สเปคเทคนิครวม (สืบทอดและปรับปรุงจาก GLM-5):
- สถาปัตยกรรม: Mixture-of-Experts (MoE) รวม 744 พันล้านพารามิเตอร์ และมีประมาณ 40 พันล้านพารามิเตอร์ทำงานต่ออินเฟอเรนซ์
- หน้าต่างบริบท: 203K–204.8K tokens (รองรับเอาต์พุตสูงสุด 131K tokens)
- การปรับปรุงสำคัญ: DeepSeek Sparse Attention (DSA) เพื่อรองรับบริบทยาวอย่างมีประสิทธิภาพและลดต้นทุนดีพลอย; โครงสร้างพื้นฐานการเรียนรู้แบบเสริมแรงแบบอะซิงโครนัสขั้นสูง (ผ่านเฟรมเวิร์ก “slime” ของ Z.ai) เพื่อการฝึกหลังที่มีประสิทธิผลยิ่งขึ้น
- ความพร้อมใช้งาน: น้ำหนักเปิด (สัญญาอนุญาต MIT บน Hugging Face ผ่าน zai-org/GLM-5.1), เข้าถึงผ่าน API บนแพลตฟอร์มของ Z.ai และตัวรวมอย่าง CometAPI และถูกรวมในเครื่องมือ GLM Coding Plan (รองรับ Claude Code / OpenClaw)
ต่างจาก GLM รุ่นก่อนที่เน้นสติปัญญาทั่วไปหรือ “vibe coding” ระยะสั้น GLM-5.1 มุ่งโจทย์เป็นเอเจนต์อัตโนมัติระดับพร้อมผลิตจริง สามารถวางแผน ดำเนินการ ทำเบนช์มาร์ก ดีบัก และวนทำโปรเจกต์วิศวกรรมที่ซับซ้อนได้เองเป็นชั่วโมงโดยไม่ต้องมีมนุษย์แทรกแซง—ขีดความสามารถที่วางตำแหน่งให้เป็นคู่แข่งตรงกับเอเจนต์โค้ดเฉพาะทางจาก Anthropic และ OpenAI
การเปิดตัวมาพร้อมกับการขึ้นราคา API ราว ~10% (input tokens ~$0.54/M, output ~$4.40/M) แต่ยังถูกกว่าทางเลือกอย่าง Claude Opus 4.6 ของ Anthropic อย่างมีนัย (แพงกว่าประมาณ 250–470%)
ผลลัพธ์เบนช์มาร์กของ GLM-5.1
Z.ai วาง GLM-5.1 ว่าเป็นโมเดลโอเพนซอร์สที่แข็งแกร่งที่สุดในโลกและติดท็อป 3 ทั่วโลกในงาน agentic coding ข้อมูลประสิทธิภาพมาจากการประเมินทางการบน SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 และสถานการณ์ระยะยาวแบบกำหนดเอง
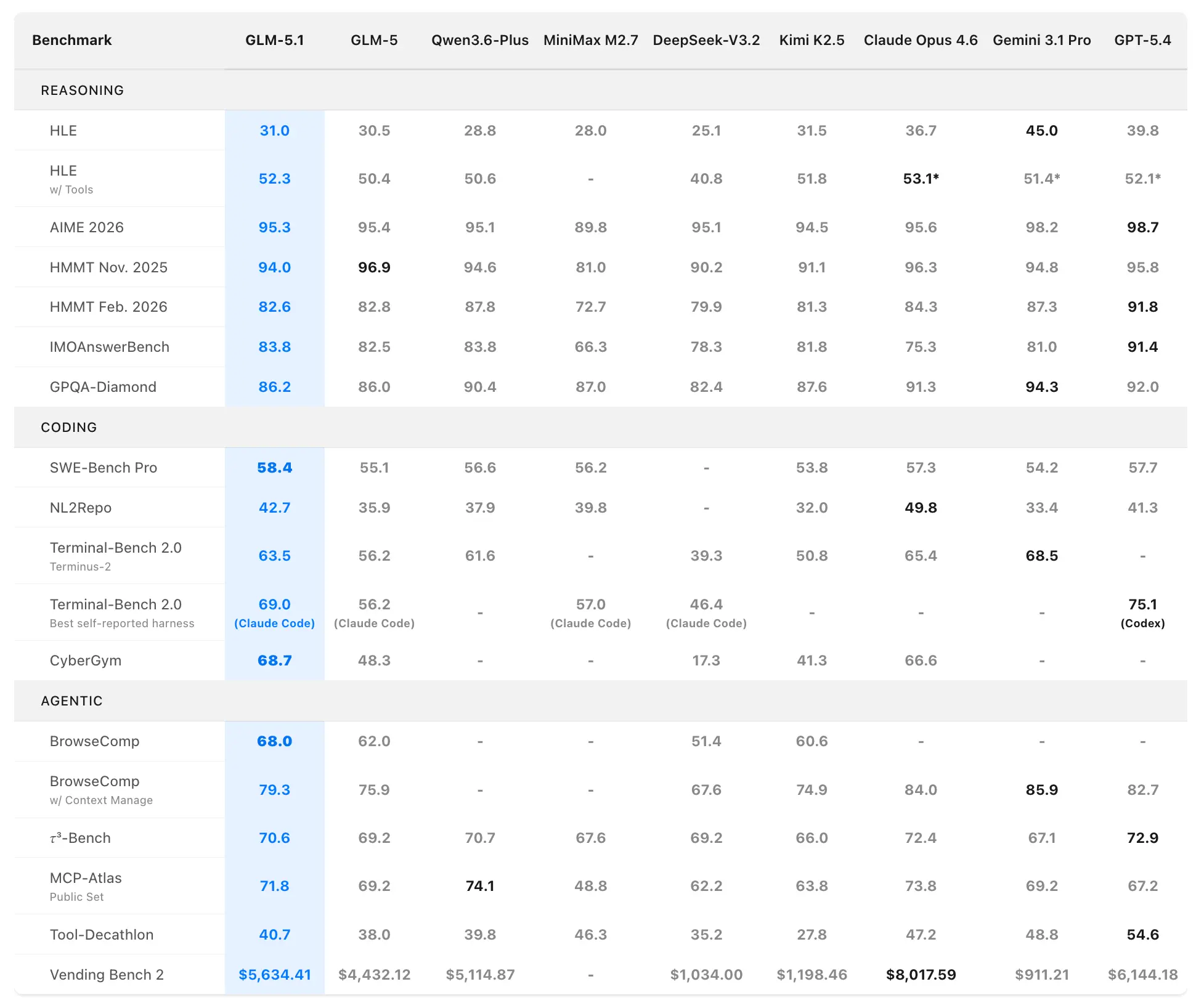
เบนช์มาร์กด้านโค้ดและเชิงเอเจนต์
SWE-Bench Pro (งานวิศวกรรมซอฟต์แวร์สมจริงที่ต้องนำทางรีโป แก้โค้ด และยืนยันการทำงาน):
- GLM-5.1: 58.4 (สถิติใหม่)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 เป็นโมเดลภายในประเทศ (จีน) และโอเพนซอร์สตัวแรกที่ติดอันดับหนึ่งบนเบนช์มาร์กเข้มข้นนี้ ซึ่งสะท้อนเวิร์กโฟลว์นักพัฒนามืออาชีพอย่างใกล้เคียง
NL2Repo (จากภาษาธรรมชาติสู่การสร้างรีโปทั้งชุด):
- GLM-5.1: 42.7 (เหนือ GLM-5 ที่ 35.9 อย่างกว้าง)
- โมเดลคู่แข่งอยู่ในช่วง 32.0–49.8 (ผู้นำเฉพาะขึ้นกับฮาร์เนส)
Terminal-Bench 2.0 (งานเทอร์มินัลและระบบโลกจริง):
- ฮาร์เนส Terminus-2: GLM-5.1 63.5 (เทียบกับ GLM-5 ที่ 56.2)
- ตัวที่รายงานตนเองดีที่สุด (Claude Code): สูงสุด 69.0
ในการประเมินฮาร์เนสโค้ดอีกชุด (สไตล์ Claude Code) GLM-5.1 ทำได้ 45.3—เท่ากับ 94.6% ของ Claude Opus 4.6 ที่ 47.9 และดีกว่า GLM-5 ที่ 35.4 อยู่ 28%
จัดอันดับภาพรวม: #1 โอเพนซอร์ส, #1 โมเดลจีน, #3 ทั่วโลก เมื่อรวม SWE-Bench Pro + NL2Repo + Terminal-Bench
ประสิทธิภาพงานระยะยาว: ตัวแยกความต่างที่แท้จริง
เบนช์มาร์กมาตรฐานวัดแบบครั้งเดียวหรือช่วงสั้น GLM-5.1 โดดเด่นในรันอัตโนมัติที่ยาวขึ้น:
- VectorDBBench Optimization (600+ รอบ, 6,000+ การเรียกใช้เครื่องมือ): เริ่มจากสเกเลตัน Rust, GLM-5.1 ออกแบบใหม่แบบวนซ้ำทั้ง indexing, compression, routing และ pruning บรรลุ 21.5k QPS (สูงกว่าเพดานเดิม 50 รอบที่ 3,547 QPS ของ Claude Opus 4.6 ถึง 6×) พร้อมคงค่า recall ≥95% บน SIFT-1M แสดง “ความก้าวหน้าแบบขั้นบันได” ด้วยความก้าวหน้าครั้งใหญ่ทุก 100–200 รอบ
- KernelBench Level 3 (ปรับแต่งโมเดล ML เต็มรูปแบบ, 1,000+ รอบ): อัตราเร่งเฉลี่ยเชิงเรขาคณิต 3.6× ผ่าน 50 โจทย์ซับซ้อน (เหนือกว่า torch.compile max-autotune ที่ 1.49×) GLM-5.1 ยังคงดีขึ้นต่อเนื่องหลัง GLM-5 ชะลอตัว; มีเพียง Claude Opus 4.6 ที่เฉือนด้วย 4.2×
- Linux Desktop Web App Build (8+ ชั่วโมง, เปิดโจทย์): ให้เพียงพรอมป์ตภาษาธรรมชาติและไม่มีโค้ดตั้งต้น GLM-5.1 สร้างสภาพแวดล้อมเดสก์ท็อปสไตล์ Linux ที่ใช้งานได้จริง—พร้อมทาสก์บาร์ หน้าต่าง ปฏิสัมพันธ์ และความเรียบร้อย—ในขณะที่รุ่นก่อนหน้าสร้างได้เพียงโครงพื้นฐาน
ผลลัพธ์เหล่านี้ยืนยันความสามารถของ GLM-5.1 ในการรักษาโครงเรื่อง ประเมินตนเอง ปรับกลยุทธ์ และหลุดพ้นกับดักเชิงท้องถิ่นในงานระยะยาวมากๆ—ความสามารถที่ Z.ai ออกแบบมาโดยเฉพาะสำหรับระบบเอเจนต์ในโลกจริง
GLM-5.1 ต่างจาก GLM-5 อย่างไร?
GLM-5 และ GLM-5.1 เกี่ยวพันกันอย่างใกล้ชิด แต่ถูกวางตำแหน่งต่างกัน GLM-5 คือโมเดลฐานก่อนหน้าของ Z.AI สำหรับ Agentic Engineering ออกแบบมาสำหรับวิศวกรรมระบบที่ซับซ้อนและงานเอเจนต์ระยะไกล ด้วยสมรรถนะโค้ดและความสามารถเชิงเอเจนต์ระดับ SOTA แบบน้ำหนักเปิด และประสิทธิภาพการโค้ดที่เข้าใกล้ Claude Opus 4.5 ในสถานการณ์เขียนโค้ดจริง ทำได้ 77.8 บน SWE-bench Verified และ 56.2 บน Terminal Bench 2.0
ในทางตรงกันข้าม GLM-5.1 ถูกวางเป็นก้าวต่อไปสู่ งานระยะยาว และการดำเนินการต่อเนื่องที่เชื่อถือได้มากขึ้น เพิ่มเสถียรภาพ ความสม่ำเสมอ และการใช้เครื่องมือในการทำงานยาว และมีการจัดแนวโดยรวมใกล้กับ Claude Opus 4.6 มากขึ้น กล่าวอีกนัย GLM-5 คือโมเดลฐานเชิงวิศวกรรมรุ่นก่อน ขณะที่ GLM-5.1 คือรุ่นเรือธงที่เน้นความทนทานเชิงงานมากกว่า
ยังมีความต่างเชิงสถาปัตยกรรมและการฝึกในเจเนอเรชัน GLM-5 ที่อธิบายการก้าวกระโดด GLM-5 ขยายจาก 355B parameters (32B activated) เป็น 744B parameters (40B activated) เพิ่มข้อมูลพรีเทรนจาก 23T เป็น 28.5T เสริมเฟรมเวิร์กการเรียนรู้แบบเสริมแรงอะซิงโครนัส และบูรณาการ DeepSeek Sparse Attention เพื่อคงคุณภาพข้อความยาวพร้อมเพิ่มประสิทธิภาพ รายละเอียดเหล่านี้ผูกกับ GLM-5 แต่เป็นฐานที่ GLM-5.1 ดูเหมือนจะต่อยอด
GLM-5.1 เทียบกับโมเดลแนวหน้ารายอื่น
GLM-5.1 โดดเด่นในฐานะ คู่แข่งโอเพนซอร์สที่แข็งแกร่งที่สุด ขณะเดียวกันก็ให้สัดส่วนราคา/ประสิทธิภาพที่น่าดึงดูด
ตารางเปรียบเทียบ: เบนช์มาร์กหลักด้านโค้ดและเอเจนต์ (เมษายน 2026)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Long-Horizon Sustained? | Open-Source? | Approx. API Price (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | Yes (600+ iter, 8 hrs) | Yes | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limited | Yes | Lower (pre-hike) |
| GPT-5.4 | 57.7 | — | — | — | Strong | No | Higher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Strongest | No | ~250–470% more expensive |
| Gemini 3.1 Pro | 54.2 | — | — | — | Good | No | Higher |
บทสรุป: GLM-5.1 ชนะด้านการเข้าถึงแบบโอเพนซอร์ส ต้นทุน และตัวชี้วัดโค้ดระยะยาวเฉพาะบางมิติ ต่อกรกับผู้นำปิดซอร์สในสถานการณ์เอเจนต์ ขณะทำให้ความสามารถแนวหน้าถูกเปิดกว้าง
สถานการณ์การใช้งานของ GLM-5.1
1) วิศวกรรมซอฟต์แวร์อัตโนมัติ
GLM-5.1 น่าดึงดูดที่สุดเมื่อภารกิจเหมือนสปรินต์วิศวกรรมจริง: อ่านโค้ดเบส วางแผนการเปลี่ยนแปลง ลงมือทำ ทดสอบ แก้รีเกรสชัน และวนจนผลลัพธ์นิ่ง โน้ตการปล่อยเน้นชัดถึงการวางแผนอัตโนมัติ การดำเนินการต่อเนื่อง แก้บั๊ก และวนกลยุทธ์ ทำให้โมเดลนี้เหมือนถูกสร้างมาสำหรับเอเจนต์โค้ดและสายพานส่งมอบซอฟต์แวร์
2) เวิร์กโฟลว์เอเจนต์รันนาน
หากกรณีใช้งานของคุณต้องเรียกใช้เครื่องมือมาก มีเวิร์กโฟลว์หลายขั้นตอนยาว หรือการแก้ไขตนเองซ้ำๆ การออกแบบของ GLM-5.1 ตรงโจทย์ เอกสารเน้นการเรียกใช้เครื่องมือ เอาต์พุตแบบมีโครงสร้าง การผสาน MCP และการสตรีมเครื่องมือ ซึ่งล้วนเป็นประโยชน์เมื่อโมเดลไม่ได้แค่ตอบ แต่ทำงานอยู่ภายในระบบที่ใหญ่กว่า
3) งานความรู้ในองค์กรและการทำรายงาน
GLM-5.1 ยังถูกวางสำหรับงานเพิ่มผลิตภาพในสำนักงาน เช่นเวิร์กโฟลว์ PowerPoint, Word, PDF และ Excel Z.ai ระบุว่ามันปรับปรุงการจัดระเบียบเนื้อหาที่ซับซ้อน การออกแบบเลย์เอาต์ เอาต์พุตเชิงโครงสร้าง และความเรียบร้อยเชิงภาพ จึงเหมาะสำหรับการสร้างรายงาน สื่อการสอน สรุปงานวิจัย และงานเอกสารหนักอื่นๆ
4) การทำต้นแบบ Front-end และอาร์ติแฟกต์
Z.ai ระบุว่า GLM-5.1 เหมาะกับการสร้างเว็บไซต์ หน้าอินเทอร์แอคทีฟ และการทำต้นแบบฝั่งหน้าบ้าน ด้วยโครงที่น้อยเทมเพลตและคุณภาพการทำงานเสร็จที่ดีขึ้น สื่อถึงความเหมาะกับทีมผลิตภัณฑ์ที่ต้องการสะพานจากบรีฟสู่ต้นแบบอย่างรวดเร็ว โดยต้นแบบต้องใช้งานได้จริงไม่ใช่แค่สวย
5) บทสนทนาที่ซับซ้อนและการทำตามคำสั่ง
แม้ไฮไลต์จะเป็นด้านโค้ด GLM-5.1 ยังอธิบายว่าดีขึ้นใน Q&A แบบเปิด ข้อกำหนดซับซ้อน และปฏิสัมพันธ์หลายรอบ ทำให้มีประโยชน์สำหรับเวิร์กโฟลว์ผู้ช่วยที่โมเดลต้องตามเงื่อนไข ปรับผลลัพธ์ และรักษาบริบทตลอดบทสนทนาที่ยาวขึ้น
บทสรุป: เหตุใด GLM-5.1 จึงสำคัญในปี 2026
GLM-5.1 ไม่ใช่แค่รุ่นเพิ่มทีละน้อย—มันส่งสัญญาณการมาถึงของ AI เชิงเอเจนต์แบบโอเพนซอร์สที่พร้อมจริง โดยโดดเด่นในเบนช์มาร์กวิศวกรรมโลกจริงที่ยากที่สุด ขณะยังคงราคาเอื้อมถึงและเปิด Z.ai ยกระดับมาตรฐานทั้งอุตสาหกรรม ไม่ว่าคุณจะเป็นนักพัฒนาเดี่ยว ทีมองค์กร หรือ นักวิจัย GLM-5.1 มอบความเป็นอิสระที่ไร้คู่แข่งสำหรับงานโค้ดระยะยาวในต้นทุนที่ต่ำกว่าคู่แข่งปิดซอร์สมาก
พร้อมลองหรือยัง? ตรวจสอบโมเดล GLM-5.1 บน CometAPI, ที่เก็บบน Hugging Face หรือ GLM Coding Plan เพื่อเข้าถึงได้ทันที