

Kimi K2 Thinking คือระบบ "คิด" ใหม่ของ Moonshot AI ในตระกูล Kimi K2: โมเดลผสมผู้เชี่ยวชาญ (MoE) ที่มีพารามิเตอร์ล้านล้านพารามิเตอร์และเบาบาง ซึ่งออกแบบมาโดยเฉพาะเพื่อ คิดขณะทำ — กล่าวคือ เพื่อแทรกการใช้เหตุผลแบบห่วงโซ่ความคิดเชิงลึกเข้ากับการเรียกใช้เครื่องมือที่เชื่อถือได้ การวางแผนระยะยาว และการตรวจสอบตนเองแบบอัตโนมัติ โปรแกรมนี้ประกอบด้วยโครงข่ายหลักแบบเบาบางขนาดใหญ่ (พารามิเตอร์ทั้งหมดประมาณ 1 ล้านรายการ เปิดใช้งานประมาณ 32 พันล้านรายการต่อโทเค็น) ไพพ์ไลน์การวัดปริมาณ INT4 แบบเนทีฟ และการออกแบบที่ปรับขนาดได้ เวลาอนุมาน การใช้เหตุผล (ใช้ "โทเค็นการคิด" มากขึ้นและใช้รอบการเรียกเครื่องมือมากขึ้น) มากกว่าการเพิ่มจำนวนพารามิเตอร์คงที่เพียงอย่างเดียว
พูดแบบง่ายๆ: K2 Thinking ถือว่าโมเดลนี้เป็นการแก้ปัญหา ตัวแทน แทนที่จะเป็นตัวสร้างภาษาแบบช็อตเดียว การเปลี่ยนแปลงนี้ — จาก "รูปแบบภาษา" ไปสู่ "รูปแบบการคิด" — คือสิ่งที่ทำให้การเปิดตัวนี้โดดเด่น และเป็นเหตุผลที่นักปฏิบัติหลายคนจึงกำหนดให้เป็นก้าวสำคัญใน AI แบบเอเจนต์โอเพนซอร์ส
“Kimi K2 Thinking” คืออะไรกันแน่?
สถาปัตยกรรมและข้อมูลจำเพาะที่สำคัญ
K2 Thinking ถูกสร้างขึ้นเป็นโมเดล MoE แบบเบาบาง (ผู้เชี่ยวชาญ 384 คน ผู้เชี่ยวชาญ 8 คนได้รับเลือกต่อโทเค็น) โดยมีประมาณ พารามิเตอร์รวม 1 ล้านล้าน และ ~32B พารามิเตอร์ที่เปิดใช้งาน ต่อการอนุมาน โดยใช้ตัวเลือกสถาปัตยกรรมแบบไฮบริด (MLA Attention, SwiGLU activations) และได้รับการฝึกฝนด้วยโปรแกรมเพิ่มประสิทธิภาพ Muon/MuonClip ของ Moonshot บนโทเค็นบัดเจ็ตขนาดใหญ่ตามที่อธิบายไว้ในรายงานทางเทคนิค รูปแบบการคิดนี้ขยายโมเดลพื้นฐานด้วยการวัดปริมาณหลังการฝึกฝน (รองรับ INT4 ดั้งเดิม), หน้าต่างบริบทขนาด 256k และวิศวกรรมเพื่อเปิดเผยและทำให้การติดตามการใช้เหตุผลภายในของโมเดลมีเสถียรภาพในระหว่างการใช้งานจริง
“การคิด” หมายความว่าอย่างไรในทางปฏิบัติ
“การคิด” ในที่นี้คือเป้าหมายทางวิศวกรรม: ช่วยให้แบบจำลองสามารถ (1) สร้างห่วงโซ่การให้เหตุผลภายในที่ยาวและมีโครงสร้าง (โทเค็นห่วงโซ่ความคิด) (2) เรียกใช้เครื่องมือภายนอก (การค้นหา, แซนด์บ็อกซ์ Python, เบราว์เซอร์, ฐานข้อมูล) เป็นส่วนหนึ่งของการให้เหตุผลนั้น (3) ประเมินและตรวจสอบข้อเรียกร้องระดับกลางด้วยตนเอง และ (4) ทำซ้ำได้หลายรอบโดยไม่ทำให้ความสอดคล้องกันลดลง เอกสารประกอบและการ์ดแบบจำลองของ Moonshot แสดงให้เห็นว่า K2 Thinking ได้รับการฝึกฝนและปรับแต่งอย่างชัดเจนให้สลับการใช้เหตุผลและการเรียกใช้ฟังก์ชัน และเพื่อรักษาพฤติกรรมของตัวแทนที่เสถียรตลอดหลายร้อยขั้นตอน
วัตถุประสงค์หลักคืออะไร
ข้อจำกัดของแบบจำลองขนาดใหญ่แบบดั้งเดิมมีดังนี้:
- กระบวนการผลิตมีการมองการณ์ไกลที่สั้น ขาดตรรกะแบบข้ามขั้นตอน
- การใช้งานเครื่องมือนั้นมีจำกัด (โดยปกติสามารถเรียกใช้เครื่องมือภายนอกได้หนึ่งหรือสองครั้งเท่านั้น)
- พวกเขาไม่สามารถแก้ไขตัวเองได้ในปัญหาที่ซับซ้อน
เป้าหมายหลักของการออกแบบ K2 Thinking คือการแก้ปัญหาทั้งสามข้อนี้ ในทางปฏิบัติ K2 Thinking สามารถดำเนินการเรียกเครื่องมือได้ 200-300 ครั้งติดต่อกันโดยไม่ต้องอาศัยการแทรกแซงจากมนุษย์ รักษาขั้นตอนการใช้เหตุผลเชิงตรรกะที่สอดคล้องกันหลายร้อยขั้นตอน และแก้ไขปัญหาที่ซับซ้อนผ่านการตรวจสอบตนเองตามบริบท
การวางตำแหน่งใหม่: รูปแบบภาษา → รูปแบบการคิด
โครงการ K2 Thinking แสดงให้เห็นถึงการเปลี่ยนแปลงเชิงกลยุทธ์ที่กว้างขึ้นในสาขานี้: ก้าวข้ามการสร้างข้อความแบบมีเงื่อนไขไปสู่ ผู้แก้ปัญหาเชิงตัวแทนวัตถุประสงค์หลักไม่ใช่เพื่อปรับปรุงความสับสนหรือการทำนายโทเค็นถัดไป แต่เพื่อสร้างแบบจำลองที่สามารถ:
- แพ็กเกจ กลยุทธ์หลายขั้นตอนของพวกเขาเอง
- ประสานงาน เครื่องมือและตัวดำเนินการภายนอก (การค้นหา การดำเนินการรหัส ฐานความรู้)
- ตรวจสอบ ผลลัพธ์กลางและแก้ไขข้อผิดพลาด;
- สนับสนุน ความสอดคล้องกันระหว่างบริบทที่ยาวนานและห่วงโซ่เครื่องมือที่ยาวนาน
การกำหนดกรอบใหม่นี้จะเปลี่ยนทั้งการประเมิน (เกณฑ์มาตรฐานเน้นที่กระบวนการและผลลัพธ์ ไม่ใช่แค่คุณภาพของข้อความเท่านั้น) และวิศวกรรม (โครงสร้างสำหรับการกำหนดเส้นทางเครื่องมือ การนับขั้นตอน การวิจารณ์ตนเอง ฯลฯ)
วิธีการทำงาน: แบบจำลองการคิดทำงานอย่างไร
ในทางปฏิบัติ K2 Thinking แสดงให้เห็นวิธีการทำงานหลายวิธีที่เป็นลักษณะเฉพาะของแนวทาง “รูปแบบการคิด”:
- ร่องรอยภายในที่คงอยู่: โมเดลนี้สร้างขั้นตอนกลางที่มีโครงสร้าง (การติดตามเหตุผล) ที่ถูกเก็บไว้ในบริบทและสามารถนำกลับมาใช้ใหม่หรือตรวจสอบในภายหลังได้
- การกำหนดเส้นทางเครื่องมือแบบไดนามิก: K2 จะตัดสินใจว่าจะเรียกใช้เครื่องมือใด (การค้นหา ตัวแปลรหัส เว็บเบราว์เซอร์) และจะเรียกใช้เมื่อใด โดยอิงตามขั้นตอนภายในแต่ละขั้นตอน
- การปรับขนาดเวลาทดสอบ: ในระหว่างการอนุมาน ระบบสามารถขยาย "ความลึกของการคิด" (โทเค็นการใช้เหตุผลภายในเพิ่มเติม) และเพิ่มจำนวนการเรียกใช้เครื่องมือเพื่อค้นหาวิธีแก้ปัญหาได้ดียิ่งขึ้น
- การตรวจสอบตนเองและการกู้คืน: โมเดลจะตรวจสอบผลลัพธ์อย่างชัดเจน ทำการทดสอบความสมเหตุสมผล และวางแผนใหม่เมื่อการตรวจสอบล้มเหลว
วิธีการเหล่านี้ผสมผสานสถาปัตยกรรมแบบจำลอง (MoE + บริบทยาว) เข้ากับวิศวกรรมระบบ (การประสานงานเครื่องมือ การตรวจสอบความปลอดภัย)
นวัตกรรมเทคโนโลยีใดบ้างที่ช่วยให้ Kimi K2 Thinking เกิดขึ้นได้?
กลไกการใช้เหตุผลของ Kimi K2 Thinking รองรับการคิดแบบสลับและการใช้เครื่องมือ วงจรการใช้เหตุผล K2 Thinking:
- การทำความเข้าใจปัญหา (การแยกวิเคราะห์และการแยกนามธรรม)
- การสร้างแผนการใช้เหตุผลหลายขั้นตอน (แผนโซ่)
- การใช้เครื่องมือภายนอก (โค้ด เบราว์เซอร์ เครื่องมือทางคณิตศาสตร์)
- การตรวจสอบและแก้ไขผลลัพธ์ (verify & revised)
- สรุปเหตุผล (สรุปเหตุผล)
ด้านล่างนี้ ฉันจะแนะนำเทคนิคสำคัญสามประการที่ทำให้การวนซ้ำเหตุผลใน xx เป็นไปได้
1) การปรับขนาดเวลาทดสอบ
มันคืออะไร: “กฎการปรับขนาด” แบบดั้งเดิมมุ่งเน้นไปที่การเพิ่มจำนวนพารามิเตอร์หรือข้อมูลระหว่างการฝึกฝน นวัตกรรมของ K2 Thinking อยู่ที่: การขยายจำนวนโทเค็น (เช่น ความลึกของความคิด) แบบไดนามิกในช่วง “ช่วงการให้เหตุผล”; การขยายจำนวนการเรียกใช้เครื่องมือ (เช่น ความกว้างของการกระทำ) พร้อมกัน วิธีการนี้เรียกว่าการปรับขนาดเวลาทดสอบ (test-time scaling) และมีสมมติฐานหลักคือ: “ห่วงโซ่การให้เหตุผลที่ยาวขึ้น + เครื่องมือแบบโต้ตอบมากขึ้น = ก้าวกระโดดเชิงคุณภาพในเชิงสติปัญญาที่แท้จริง”
ทำไมมันเรื่อง: K2 Thinking ปรับให้เหมาะสมอย่างชัดเจนสำหรับสิ่งนี้: Moonshot แสดงให้เห็นว่าการขยาย "โทเค็นการคิด" และจำนวน/ความลึกของการเรียกใช้เครื่องมือจะส่งผลให้เกิดการปรับปรุงที่วัดได้ในเกณฑ์มาตรฐานของตัวแทน ช่วยให้โมเดลทำงานได้ดีกว่าโมเดลอื่นๆ ที่มีขนาดใกล้เคียงกันหรือใหญ่กว่าในสถานการณ์ที่จับคู่ FLOP
2) การใช้เหตุผลเสริมด้วยเครื่องมือ
มันคืออะไร: K2 Thinking ถูกออกแบบมาเพื่อวิเคราะห์โครงร่างเครื่องมือโดยอัตโนมัติ ตัดสินใจโดยอัตโนมัติว่าจะเรียกใช้เครื่องมือเมื่อใด และนำผลลัพธ์ของเครื่องมือกลับเข้าสู่กระบวนการคิดอย่างต่อเนื่อง Moonshot ได้ฝึกฝนและปรับแต่งโมเดลให้สลับลำดับความคิดด้วยการเรียกใช้ฟังก์ชัน จากนั้นจึงปรับพฤติกรรมนี้ให้คงที่ตลอดหลายร้อยขั้นตอนของเครื่องมือตามลำดับ
ทำไมมันเรื่อง: การผสมผสานดังกล่าว — การแยกวิเคราะห์ที่เชื่อถือได้ + สถานะภายในที่เสถียร + เครื่องมือ API — คือสิ่งที่ช่วยให้โมเดลสามารถเรียกดูเว็บ รันโค้ด และจัดการเวิร์กโฟลว์หลายขั้นตอนเป็นส่วนหนึ่งของเซสชันเดียว
ภายในสถาปัตยกรรมภายใน โมเดลจะสร้างเส้นทางการดำเนินการ "กระบวนการคิดที่มองเห็นได้": คำเตือน → โทเค็นการให้เหตุผล → การเรียกเครื่องมือ → การสังเกต → การให้เหตุผลถัดไป → คำตอบสุดท้าย
3) ความสอดคล้องในขอบเขตยาวและการยืนยันตนเอง
มันคืออะไร: ความสอดคล้องกันในขอบเขตยาว (Long-horizon coherence) คือความสามารถของแบบจำลองในการรักษาแผนงานและสถานะภายในที่สอดคล้องกันในหลายขั้นตอนและในบริบทที่ยาวนานมาก การตรวจสอบตนเอง (Self-verification) หมายถึงแบบจำลองจะตรวจสอบผลลัพธ์ระหว่างกระบวนการอย่างเชิงรุก และรันซ้ำหรือแก้ไขขั้นตอนเมื่อการตรวจสอบล้มเหลว งานที่ยาวนานมักทำให้แบบจำลองคลาดเคลื่อนหรือเกิดอาการประสาทหลอน K2 Thinking จัดการกับปัญหานี้ด้วยเทคนิคหลากหลาย ได้แก่ ขอบเขตบริบทที่ยาวมาก (256k), กลยุทธ์การฝึกที่รักษาสถานะไว้ตลอดลำดับ CoT ที่ยาว และแบบจำลองความซื่อสัตย์/การตัดสินระดับประโยคที่ชัดเจน เพื่อตรวจจับข้อกล่าวอ้างที่ไม่มีหลักฐานสนับสนุน
ทำไมมันเรื่อง: กลไก “หน่วยความจำการใช้เหตุผลแบบวนซ้ำ” ช่วยรักษาความคงอยู่ของสถานะการใช้เหตุผล ทำให้เกิด “เสถียรภาพในการคิด” และ “การควบคุมตนเองตามบริบท” เสมือนมนุษย์ เมื่องานต่างๆ ขยายออกไปหลายขั้นตอน (เช่น โครงการวิจัย งานเขียนโค้ดหลายไฟล์ กระบวนการแก้ไขที่ยาวนาน) การรักษาความสัมพันธ์ที่สอดคล้องกันจึงเป็นสิ่งสำคัญ การตรวจสอบตนเองช่วยลดความล้มเหลวแบบเงียบๆ แทนที่จะส่งคำตอบที่น่าเชื่อถือแต่ไม่ถูกต้องกลับมา โมเดลนี้สามารถตรวจจับความไม่สอดคล้องกันและปรึกษาเครื่องมือหรือวางแผนใหม่ได้
ความสามารถ:
- ความสอดคล้องตามบริบท: รักษาความต่อเนื่องทางความหมายทั่วทั้งโทเค็นมากกว่า 10 รายการ
- การตรวจจับข้อผิดพลาดและการย้อนกลับ: ระบุและแก้ไขความเบี่ยงเบนเชิงตรรกะในกระบวนการคิดเบื้องต้น
- วงจรยืนยันตนเอง: ตรวจสอบความสมเหตุสมผลของคำตอบโดยอัตโนมัติหลังจากการใช้เหตุผลเสร็จสิ้น
- การผสานการใช้เหตุผลหลายเส้นทาง: เลือกเส้นทางที่ดีที่สุดจากห่วงโซ่ตรรกะหลาย ๆ เส้น
ความสามารถหลักทั้งสี่ของ K2 Thinking มีอะไรบ้าง?
การใช้เหตุผลเชิงลึกและมีโครงสร้าง
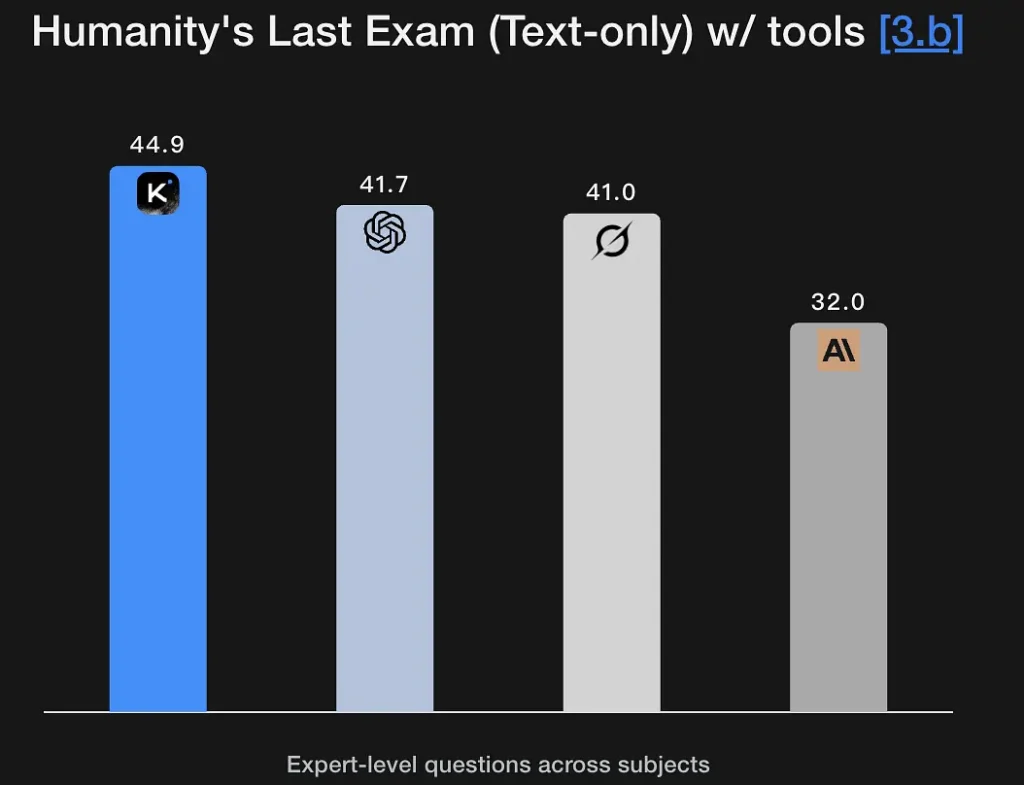
K2 Thinking ได้รับการออกแบบมาเพื่อสร้างร่องรอยการใช้เหตุผลแบบหลายขั้นตอนที่ชัดเจน และนำไปใช้เพื่อบรรลุข้อสรุปที่ชัดเจน แบบจำลองนี้แสดงคะแนนที่แข็งแกร่งในเกณฑ์มาตรฐานการใช้เหตุผลทางคณิตศาสตร์และเกณฑ์มาตรฐานที่เข้มงวด (GSM8K, AIME, เกณฑ์มาตรฐานแบบ IMO) และแสดงให้เห็นถึงความสามารถในการรักษาการใช้เหตุผลให้คงเดิมในลำดับที่ยาวนาน ซึ่งเป็นข้อกำหนดพื้นฐานสำหรับการแก้ปัญหาระดับงานวิจัย ประสิทธิภาพที่ยอดเยี่ยมในการสอบ Humanity's Last Exam (44.9%) แสดงให้เห็นถึงความสามารถในการวิเคราะห์ระดับผู้เชี่ยวชาญ แบบจำลองนี้สามารถดึงกรอบความคิดเชิงตรรกะจากคำอธิบายความหมายแบบฟัซซี และสร้างกราฟการใช้เหตุผลได้
คุณสมบัติเด่น:
- รองรับการใช้เหตุผลเชิงสัญลักษณ์: เข้าใจและดำเนินการตามโครงสร้างทางคณิตศาสตร์ ตรรกะ และการเขียนโปรแกรม
- มีความสามารถในการทดสอบสมมติฐาน: สามารถเสนอและตรวจสอบสมมติฐานได้อย่างเป็นธรรมชาติ
- สามารถดำเนินการแยกปัญหาหลายขั้นตอนได้: แบ่งวัตถุประสงค์ที่ซับซ้อนออกเป็นงานย่อยหลายงาน
การค้นหาตัวแทน
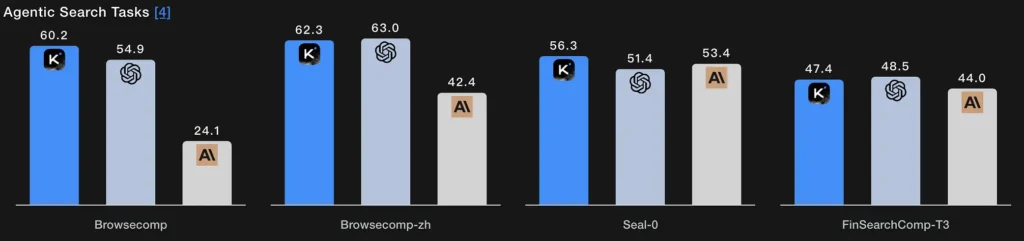
แทนที่จะใช้ขั้นตอนการดึงข้อมูลเพียงขั้นตอนเดียว การค้นหาแบบเอเจนต์จะช่วยให้โมเดลสามารถวางแผนกลยุทธ์การค้นหา (สิ่งที่ต้องการค้นหา) ดำเนินการผ่านการเรียกใช้เว็บ/เครื่องมือซ้ำๆ สังเคราะห์ผลลัพธ์ที่เข้ามา และปรับแต่งคำค้นหา คะแนนที่เปิดใช้งานเครื่องมือ BrowseComp และ Seal-0 ของ K2 Thinking แสดงให้เห็นถึงประสิทธิภาพที่แข็งแกร่งในความสามารถนี้ โมเดลนี้ได้รับการออกแบบมาโดยเฉพาะเพื่อรองรับการค้นหาเว็บแบบหลายรอบด้วยการวางแผนแบบมีสถานะ
สาระสำคัญทางเทคนิค:
- โมดูลการค้นหาและโมเดลภาษาสร้างวงจรปิด: การสร้างแบบสอบถาม → การดึงข้อมูลหน้าเว็บ → การกรองความหมาย → การผสมผสานเหตุผล
- โมเดลสามารถปรับกลยุทธ์การค้นหาได้อย่างยืดหยุ่น เช่น ค้นหาคำจำกัดความก่อน จากนั้นค้นหาข้อมูล และสุดท้ายตรวจสอบสมมติฐาน
- โดยพื้นฐานแล้ว มันคือปัญญาแบบผสมผสานของ “การค้นหาข้อมูล + ความเข้าใจ + การโต้แย้ง”
การเข้ารหัสแบบเอเจนต์
นี่คือความสามารถที่จะ เขียน ดำเนินการ ทดสอบ และทำซ้ำ ในส่วนของโค้ดซึ่งเป็นส่วนหนึ่งของวงจรการให้เหตุผล K2 Thinking นำเสนอผลลัพธ์ที่แข่งขันได้บนเกณฑ์มาตรฐานการเขียนโค้ดและการตรวจสอบโค้ดแบบเรียลไทม์ รองรับชุดเครื่องมือ Python ในการเรียกใช้เครื่องมือ และสามารถรันลูปการดีบักแบบหลายขั้นตอนได้ด้วยการเรียกใช้แซนด์บ็อกซ์ อ่านข้อผิดพลาด และซ่อมแซมโค้ดซ้ำๆ คะแนน EvalPlus/LiveCodeBench สะท้อนถึงจุดแข็งเหล่านี้ การได้คะแนน 71.3% ในการทดสอบ SWE-Bench Verified หมายความว่า K2 Thinking สามารถทำงานซ่อมแซมซอฟต์แวร์จริงได้อย่างถูกต้องมากกว่า 70%
นอกจากนี้ยังแสดงให้เห็นถึงประสิทธิภาพที่เสถียรในสภาพแวดล้อมการแข่งขัน LiveCodeBench V6 โดยแสดงให้เห็นความสามารถในการนำอัลกอริทึมไปใช้งานและเพิ่มประสิทธิภาพ

สาระสำคัญทางเทคนิค:
- ซึ่งใช้กระบวนการ “การแยกวิเคราะห์ความหมาย + การรีแฟกเตอร์ระดับ AST + การตรวจสอบอัตโนมัติ”
- การดำเนินการและการทดสอบโค้ดทำได้สำเร็จผ่านการเรียกใช้เครื่องมือในเลเยอร์การดำเนินการ
- ทำให้เกิดการพัฒนาแบบอัตโนมัติแบบวงจรปิดจากการทำความเข้าใจโค้ด → การวินิจฉัยข้อผิดพลาด → การสร้างแพตช์ → การตรวจสอบความสำเร็จ
การเขียนแบบตัวแทน
นอกเหนือจากงานร้อยแก้วเชิงสร้างสรรค์แล้ว การเขียนเชิงตัวแทน (agentic writing) คือการผลิตเอกสารที่มีโครงสร้างและมุ่งเป้าหมาย ซึ่งอาจจำเป็นต้องมีการวิจัยจากภายนอก การอ้างอิง การสร้างตาราง และการปรับปรุงแก้ไขแบบวนซ้ำ (เช่น การเขียนร่าง → ตรวจสอบข้อเท็จจริง → แก้ไข) บริบทระยะยาวและการประสานเครื่องมือของ K2 Thinking ทำให้เหมาะอย่างยิ่งสำหรับเวิร์กโฟลว์การเขียนแบบหลายขั้นตอน (สรุปงานวิจัย สรุปข้อบังคับ และเนื้อหาหลายบท) อัตราการชนะแบบปลายเปิดของแบบจำลองจากการทดสอบแบบ Arena และตัวชี้วัดการเขียนแบบยาวสนับสนุนข้อกล่าวอ้างดังกล่าว
สาระสำคัญทางเทคนิค:
- สร้างกลุ่มข้อความโดยอัตโนมัติโดยใช้การวางแผนความคิดแบบตัวแทน
- ควบคุมตรรกะของข้อความภายในโดยใช้โทเค็นการให้เหตุผล
- สามารถเรียกใช้เครื่องมือต่างๆ เช่น การค้นหา การคำนวณ และการสร้างแผนภูมิพร้อมกันเพื่อบรรลุ "การเขียนแบบหลายโหมด" ได้
คุณจะใช้ K2 Thinking ได้อย่างไรในวันนี้?
โหมดการเข้าถึง
K2 Thinking พร้อมใช้งานในรูปแบบโอเพนซอร์ส (น้ำหนักและจุดตรวจสอบของโมเดล) และผ่านจุดสิ้นสุดของแพลตฟอร์มและศูนย์กลางชุมชน (Hugging Face, แพลตฟอร์ม Moonshot) คุณสามารถโฮสต์ด้วยตนเองได้หากคุณมีการประมวลผลเพียงพอ หรือใช้ โคเมทเอพีไอAPI/UI ที่โฮสต์ไว้เพื่อการออนบอร์ดที่รวดเร็วยิ่งขึ้น นอกจากนี้ยังมีเอกสารประกอบ reasoning_content ฟิลด์ที่แสดงโทเค็นความคิดภายในให้ผู้โทรทราบเมื่อเปิดใช้งาน
เคล็ดลับการใช้งานที่เป็นประโยชน์
- เริ่มต้นด้วยบล็อกตัวต่อตัวแทน: เปิดเผยชุดเครื่องมือกำหนดแบบเล็กๆ ก่อน (การค้นหา, แซนด์บ็อกซ์ Python และฐานข้อมูลข้อเท็จจริงที่เชื่อถือได้) จัดเตรียมโครงร่างเครื่องมือที่ชัดเจนเพื่อให้โมเดลสามารถวิเคราะห์/ตรวจสอบการเรียกได้
- ปรับแต่งการคำนวณเวลาทดสอบ: สำหรับการแก้ปัญหาที่ยาก ควรเผื่อเวลาคิดให้นานขึ้น งบประมาณ และรอบการเรียกใช้เครื่องมือที่มากขึ้น วัดผลว่าคุณภาพดีขึ้นเมื่อเทียบกับความล่าช้า/ต้นทุน Moonshot สนับสนุนการปรับขนาดตามเวลาทดสอบเป็นปัจจัยหลัก
- ใช้โหมด INT4 เพื่อประสิทธิภาพด้านต้นทุน:K2 Thinking รองรับการวัดเชิงปริมาณ INT4 ซึ่งให้ความเร็วที่เพิ่มขึ้นอย่างมีนัยสำคัญ แต่ตรวจสอบพฤติกรรมกรณีขอบในงานของคุณ
- เนื้อหาการใช้เหตุผลพื้นผิวอย่างระมัดระวัง:การเปิดเผยเชนภายในอาจช่วยในการดีบัก แต่ยังเพิ่มความเสี่ยงต่อข้อผิดพลาดของโมเดลดิบอีกด้วย พิจารณาการใช้เหตุผลภายในเป็น การวินิจฉัย ไม่น่าเชื่อถือ ให้จับคู่กับการตรวจสอบอัตโนมัติ
สรุป
Kimi K2 Thinking เป็นคำตอบที่ออกแบบมาอย่างจงใจสำหรับยุคถัดไปของ AI ไม่ใช่แค่โมเดลที่ใหญ่ขึ้นเท่านั้น แต่ ตัวแทนที่คิด ดำเนินการ และตรวจสอบการผสมผสานนี้ช่วยผสานรวมการปรับขนาด MoE กลยุทธ์การประมวลผลแบบทดสอบ การอนุมานความแม่นยำต่ำแบบดั้งเดิม และการประสานเครื่องมือที่ชัดเจน เพื่อให้สามารถแก้ปัญหาได้หลายขั้นตอนอย่างต่อเนื่อง สำหรับทีมที่ต้องการแก้ปัญหาหลายขั้นตอนและมีวินัยทางวิศวกรรมในการผสานรวม แซนด์บ็อกซ์ และติดตามระบบเอเจนต์ K2 Thinking ถือเป็นก้าวสำคัญที่ใช้งานได้จริง และเป็นการทดสอบความเครียดที่สำคัญสำหรับวิธีที่อุตสาหกรรมและสังคมจะควบคุม AI ที่มุ่งเน้นการปฏิบัติและมีความสามารถมากขึ้น
นักพัฒนาสามารถเข้าถึงได้ คิมิ K2 Thinking API ผ่านทาง CometAPI รุ่นใหม่ล่าสุด ได้รับการอัปเดตอยู่เสมอจากเว็บไซต์อย่างเป็นทางการ เริ่มต้นด้วยการสำรวจความสามารถของโมเดลใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว โคเมทเอพีไอ เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยคุณบูรณาการ
พร้อมไปหรือยัง?→ ลงทะเบียน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม โปรดติดตามเราที่ VK, X และ ไม่ลงรอยกัน!