

Vidu Q3 ได้เข้ามาในวงสนทนาเมื่อต้นปี 2026 ในฐานะสัญญาณที่ชัดเจนยิ่งขึ้นว่า การสร้างวิดีโอด้วย AI กำลังก้าวจากคลิปสั้นแบบเล่นสนุก ไปสู่การเล่าเรื่องที่มีโครงเรื่องจริงจังและหลายช็อต นับตั้งแต่เปิดให้ใช้งานอย่างกว้างขวาง Vidu Q3 กลายเป็นเครื่องมือหลักในเวิร์กโฟลว์ของครีเอเตอร์ โครงการวิจัยนำร่อง และการทดสอบเชิงพาณิชย์ ด้วยเหตุผลที่ดี: มันผลักขีดจำกัดด้านระยะเวลา การบูรณาการภาพและเสียง และความสอดคล้องหลายช็อตได้ไกลกว่ารุ่นก่อนๆ พร้อมมี API สำหรับนักพัฒนาเพื่อใช้งานแบบโปรแกรมมิ่ง
Vidu Q3 คืออะไร?
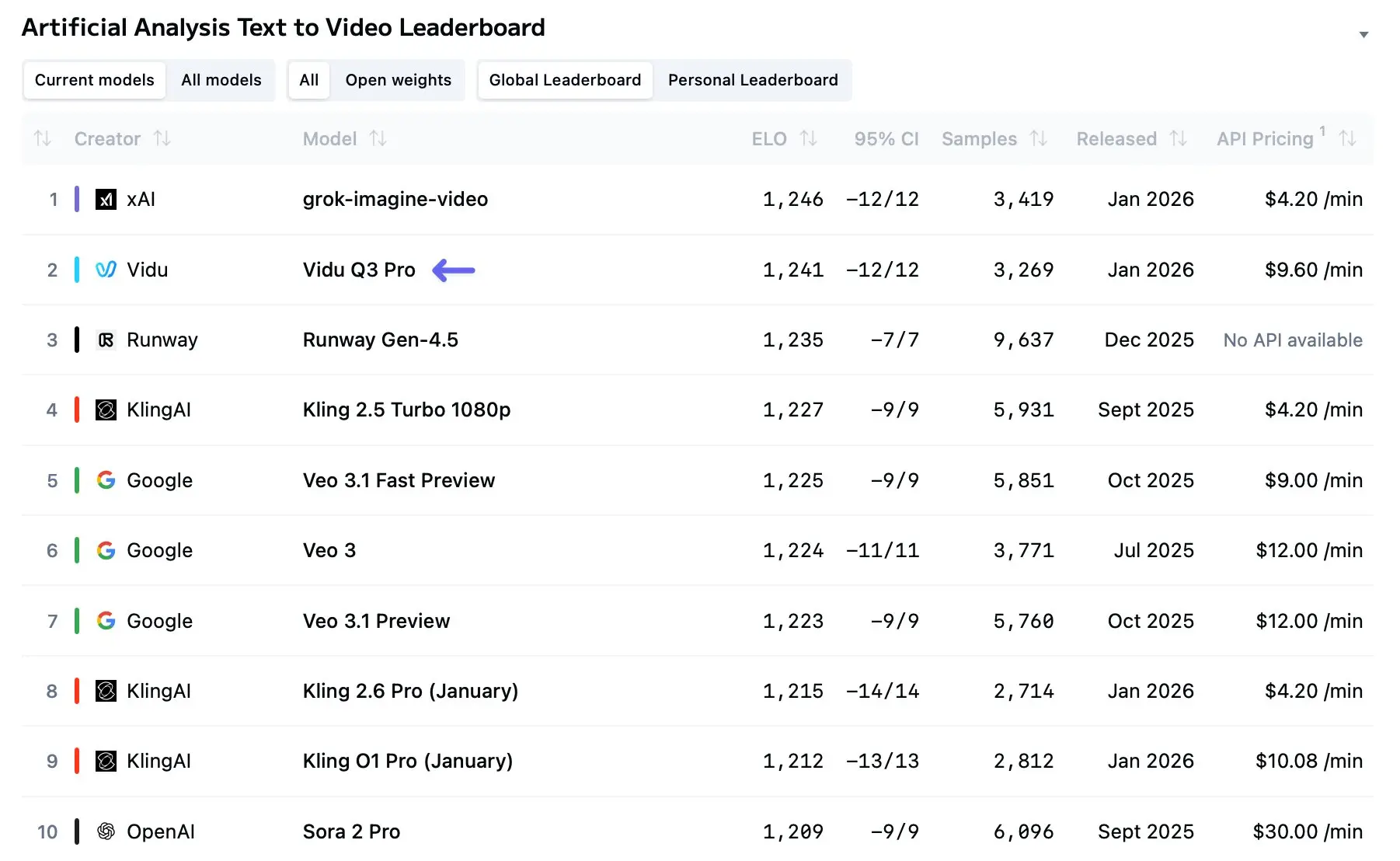
Vidu Q3 คือรุ่นเรือธงล่าสุดของสถาปัตยกรรมโมเดลวิดีโอขนาดใหญ่ (LVM) ของ ShengShu Technology ต่างจากรุ่นก่อนหน้า (Vidu 1.0 และ 1.5) ซึ่งต้องใช้เวิร์กโฟลว์แยกระหว่างการสร้างภาพกับการทำเสียงในภายหลัง Vidu Q3 เป็นเอนจินเชิงกำเนิดแบบ "all-in-one"
จุดก้าวหน้าหลักของ Vidu Q3 คือความสามารถในการสร้างภาพความละเอียดสูงและเสียงคุณภาพสูงพร้อมกัน[ ด้วยการทำความเข้าใจฟิสิกส์ของเสียงและแสงร่วมกัน โมเดลจึงขจัด “หุบเหวลึกลับ” ของเสียงที่ไม่ซิงก์ ซึ่งพบได้บ่อยในโมเดลคู่แข่ง รองรับการสร้างต่อเนื่องได้นานสูงสุดถึง 16 วินาทีที่ความละเอียด 1080p แบบเนทีฟ ทำให้เข้าระยะพร้อมใช้งานผลิตจริงสำหรับหนังสั้น โฆษณา และการเล่าเรื่องเชิงบรรยาย
Vidu Q3 ทำงานเบื้องหลังอย่างไร?
แม้รายละเอียดแกนสถาปัตยกรรมจะเป็นทรัพย์สินเฉพาะ Vidu สร้างขึ้นบนพื้นฐานของการผสานแบบไฮบริดระหว่าง U-ViT ที่ผสาน diffusion models และ transformers ซึ่งเป็นดีไซน์ที่ขึ้นชื่อเรื่องการรักษาความสอดคล้อง ความต่อเนื่องเชิงเวลา และความเป็นธรรมชาติในการสร้างวิดีโอ
สถาปัตยกรรมผสานนี้ทำให้โมเดลสามารถให้เหตุผลเกี่ยวกับการเคลื่อนไหว เสียง และบริบทของเรื่องเล่าตลอดลำดับภาพที่ยาวขึ้น
6 คุณสมบัติเด่นของ Vidu Q3
1. การสร้างคลิประยะยาว — ไปได้ไกลแค่ไหน?
หนึ่งในจุดขายของ Vidu Q3 คือระยะเวลาการสร้างต่อครั้งที่ยาวขึ้น หลายรุ่นก่อนหน้านี้มุ่งที่ไมโครคลิป ขณะที่ Q3 ตั้งใจยืดความยาวคลิปเพื่อให้เกิดโค้งเรื่องเล่าง่ายๆ และลำดับหลายช็อต โดยไม่บังคับให้ครีเอเตอร์ต้องต่อคลิปสั้นมากๆ เข้าด้วยกัน เอกสารแพลตฟอร์มและพอร์ทัลพาร์ทเนอร์ระบุว่าทำได้ถึงประมาณ ~16 วินาทีต่อการสร้างหนึ่งครั้งที่ความละเอียดเนทีฟ (รูปแบบและคุณภาพอาจต่างกันตามผู้ให้บริการและแผน API) นี่สำคัญเพราะการขยับจาก 4–8 วินาทีไปเป็น 16 วินาที เปลี่ยนวิธีวางแผนฉาก เขียนบีต และจังหวะเสียงของครีเอเตอร์
2. ความคมชัดของภาพและความสอดคล้องตามเวลา
การประเมินอิสระและเบนช์มาร์กช่วงแรกแสดงว่า Vidu Q3 ให้ภาพคมชัดและมีความเพี้ยนระดับเฟรมน้อยกว่ารุ่นผู้บริโภคก่อนหน้า การพัฒนาทางสถาปัตยกรรมและการเสริมข้อมูลช่วยลดการกะพริบและปรับปรุงความต่อเนื่องของการเคลื่อนไหวในคลิปที่ยาวไม่เกิน 10–16 วินาที อย่างไรก็ตาม โมเดลยังอาจลำบากกับฉากหนาแน่นหลายองค์ประกอบ (ฝูงชน ปฏิสัมพันธ์ทางกายภาพซับซ้อน) ที่ต้องอาศัยเหตุผลทางฟิสิกส์ที่แข็งแรง เว็บไซต์จัดอันดับและลีดเดอร์บอร์ดของโมเดลบางแห่งจัด Vidu Q3 ไว้สูงในหมวด T2V (text-to-video) แม้อันดับจะต่างกันตามเบนช์มาร์กและชุดข้อมูล
3. สร้างเสียง + วิดีโอแบบเนทีฟ
ต่างจากระบบที่สร้างภาพเงียบแล้วค่อยทำเสียงภายหลัง Vidu Q3 ผนวกการสร้างเสียงไว้ในโมเดล ผลลัพธ์คือบทสนทนาที่ซิงก์ปาก เอฟเฟกต์เสียงตรงจังหวะ และดนตรีประกอบทางเลือกที่ผลิตมาพร้อมกับเฟรม การรวมเสียงในระดับโมเดลช่วยลดข้อผิดพลาดด้านการจัดแนว (ปากไม่ตรงคำ เสียงหลุดจังหวะ) และย่นวงจรการผลิตสำหรับเดโม พรีวิว และงานสั้นจำนวนมากที่พร้อมเผยแพร่
4. การควบคุมกล้องอัจฉริยะและเรื่องเล่าหลายช็อต
ความสามารถ “สมาร์ตคาเมรา” ของ Q3 ตีความพรอมป์ต์ที่ระบุการเคลื่อนกล้อง (แพน ดอลลี แทร็กกิง) และลำดับหลายช็อต แทนที่จะออกมาเป็นมุมมองนิ่งเดียว โมเดลสามารถสร้างคัตและทรานซิชันตามแผน ทำให้คลิปอ่านได้เหมือนฉากที่มีผู้กำกับ สำหรับครีเอเตอร์ นี่เปลี่ยนผลลัพธ์จาก ‘ภาพหนึ่งใบที่ขยับ’ เป็น ‘ฉากสั้นที่มีหลายช็อต’ ซึ่งเพิ่มความน่าดูและเปิดทางให้การเล่าเรื่องด้วยภาพที่เข้มขึ้นในการสร้างครั้งเดียว
5. ความสอดคล้องหลายอ้างอิงและความคงเส้นคงวาของตัวละคร
Vidu (ในฐานะแพลตฟอร์ม) ลงทุนกับระบบ “reference to video” และความสอดคล้องหลายอ้างอิง ที่ให้ครีเอเตอร์อัปโหลดภาพอ้างอิงหลายใบเพื่อยึดเอกลักษณ์ตัวละครให้คงที่ข้ามเฟรม Q3 ขยายแนวคิดนี้เพื่อคงรูปลักษณ์ตัวละครและพร็อปให้สอดคล้องข้ามมุมกล้องและคัต — ข้อกำหนดพื้นฐานแต่จำเป็นสำหรับผลลัพธ์ที่เล่าเรื่องได้ coherently โดยเฉพาะงานอนิเมะหรือสไตล์จัดที่ต้องรักษาศิลป์ของตัวละครให้เสถียร
6. ความพร้อมสำหรับนักพัฒนา: API และเวิร์กโฟลว์
ชุดโมเดลของ Vidu—รวม Q3—พร้อมให้ใช้ผ่านเว็บ UI และ REST API แบบโปรแกรม นักพัฒนาส่งงาน text-to-video หรือ image-plus-text ไปยังปลายทาง inference รับ task ID แล้วโพลล์ผลลัพธ์ (แพตเทิร์นงาน async ปกติ) API มีพารามิเตอร์อย่างความละเอียด อัตราส่วน ระยะเวลา ความแรงการเคลื่อนไหว และสวิตช์เปิด/ปิดการสร้างเสียง ทำให้ Q3 เข้าถึงได้สำหรับงานอัตโนมัติ งานแบตช์ และการผนวกเข้ากับสายงานตัดต่อ
Vidu Q3 เทียบกับ Sora 2 และ Veo 3.1 อย่างไร?
คำตอบสั้น: Vidu Q3 เด่นในงานเล่าเรื่องแบบคลิปยาวขึ้นและการผสานเสียง/วิดีโอสำหรับฉาก 10–20 วินาที Sora 2 โดดเด่นด้านความสมจริงและฟิสิกส์ในช็อตเดี่ยว พร้อมการผสานโซเชียล ส่วน Veo 3.1 นำในด้านความเนียนระดับพิกเซล เครื่องมือความต่อเนื่องหลายเฟรม และการผนวก API สำหรับองค์กร ด้านล่างคือการไล่แยกตามปัจจัยใช้งานจริง
โมเดลไหนแข็งแรงกว่าสำหรับความสมจริงและฟิสิกส์: Sora 2 หรือ Vidu Q3?
Sora 2 (OpenAI) ถูกฝึกให้เน้นความสมเหตุสมผลทางกายภาพและการจำลองโลก — หมายเหตุสาธารณะระบุพฤติกรรมฟิสิกส์ขั้นสูง ปฏิสัมพันธ์วัตถุแม่นยำ และวิถีการเคลื่อนที่ที่สมจริง Sora 2 ยังให้เสียงที่ซิงก์และอินทิเกรตกับโซเชียลแอป (รวมแคมิโอและโมบายแอป) ทำให้แข็งแกร่งมากสำหรับฉากสมจริงที่มีความสอดคล้องทางกายภาพ หากบรีฟของคุณต้องการการชนปะทะที่ถูกต้อง ไดนามิกส์สมจริง หรือการเคลื่อนไหวมนุษย์แบบโฟโตเรียลิสติกในช็อตสั้นที่ปิดจบ Sora 2 มักจะเหนือกว่า
Vidu Q3 ตรงกันข้าม ถูกวางตัวเป็นเอ็นจินเพื่อการเล่าเรื่อง: คลิปยาวขึ้น ลำดับหลายช็อต และการควบคุมกล้องแบบผู้กำกับ นั่นไม่ใช่ว่า Vidu ทิ้งความสมจริง แต่ผลกำไรหลักอยู่ที่ความต่อเนื่องของเรื่องเล่าและเอาต์พุตเสียง-ภาพที่รวมกันมากกว่าการจำลองฟิสิกส์ล้วน สำหรับการเล่าเรื่องสั้นเชิงภาพยนตร์ (เช่น เดโมผลิตภัณฑ์ 16s ที่มีการคัตและ VO) เวิร์กโฟลว์ของ Q3 มักเร็วกว่าสะดวกกว่า
โมเดลไหนดีกว่าสำหรับความเนียนเชิงภาพยนตร์และความคมชัดสูง: Veo 3.1 vs Vidu Q3?
Veo 3.1 (Google / DeepMind / Gemini) ทำตลาดในฐานะตัวเลือกคุณภาพสูงสำหรับองค์กร ที่มีเครื่องมือควบคุมความต่อเนื่องแข็งแรง การสร้างเสียงแบบเนทีฟ และการรองรับในสแตกของ Google/Vertex/Gemini Veo 3.1 เปิดตัวความสามารถ “ingredients to video” รองรับแนวตั้ง (9:16) แบบเนทีฟ และอัปสเกลสู่ความละเอียดสูง (รวมถึง 4K ในบางโฟลว์) สำหรับโครงการที่ต้องการคุณภาพพิกเซลสูงสุด ความกลมกลืนของสีแม่นยำ และ API สำหรับองค์กร Veo 3.1 มักเป็นตัวเลือกหลัก
Vidu Q3 ถือสู้ได้ด้วยการโฟกัสที่ระยะเวลาที่ยาวขึ้น + ความสอดคล้องของเรื่องเล่าหลายช็อต และการทำผลิตภัณฑ์ที่เน้นครีเอเตอร์ (เว็บเพลย์กราวนด์ที่ไว การจัดการหลายอ้างอิง) หากความสำคัญของคุณคือการทำฉากสั้นที่มีผู้กำกับด้วยการเคลื่อนกล้องหลายรูปแบบและคิวเสียงที่บูรณาการ (และให้ความสำคัญกับความยาวมากกว่าความเนียนพิกเซลล้วน) Vidu Q3 น่าสนใจ สำหรับความโฟโตเรียลิสติกดิบๆ Veo 3.1 มักได้เปรียบ
ณ ต้นปี 2026 ขุนศึกวิดีโอ AI สามรายประกอบด้วย Sora 2 ของ OpenAI, Veo 3.1 ของ Google และ Vidu Q3 ต่อไปนี้คือการเทียบตรง:
| คุณสมบัติ | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| ระยะเวลาคลิปเดี่ยวสูงสุด | ~16 s | สูงสุด ~25 s (Pro) | 8 s (พร้อมคุณสมบัติต่อเรื่องเล่า) |
| การสร้างเสียงแบบเนทีฟ | ใช่ (บูรณาการ) | ใช่ (ทดลอง) | ใช่ (ขั้นสูง) |
| การควบคุมกล้องเชิงภาพยนตร์ | ใช่ (รับรู้ช็อต) | พรีเซ็ตจำกัด | ใช่ (ความสอดคล้องหลายช็อต) |
| เรื่องเล่าหลายช็อต | ใช่ | ใช่ | ใช่ |
| การเรนเดอร์ข้อความในเฟรม | ใช่ | แตกต่างกัน | แตกต่างกัน |
| ความละเอียด | 1080p | 1080p | 1080p / 4K ในบางกรณี |
| กรณีใช้งานหลัก | การเล่าเรื่องเชิงบรรยาย, แอนิเมชัน | คอนเซปต์/ภาพยนตร์งบสูง | Youtube Shorts / TikTok |
การวิเคราะห์:
- เทียบ Sora 2: Sora 2 ยังครองความเหนือชั้นด้านความเนียนของภาพและจินตนาการเหนือจริงระดับ “ฮอลลีวูด” อย่างไรก็ตาม Vidu Q3 เฉือนในด้านประสิทธิภาพเวิร์กโฟลว์ด้วยข้อจำกัด 16 วินาทีและการผสานเสียงที่ดีกว่า สำหรับครีเอเตอร์ที่ต้องการคลิป “ทำครั้งเดียวจบ” Q3 เร็วกว่า
- เทียบ Veo 3.1: Veo 3.1 ของ Google โดดเด่นด้านความเร็วสำหรับคลิปสั้นแนวโซเชียล (4–8 วินาที) และผนวกแน่นกับ YouTube Vidu Q3 เล็งไปไกลกว่า มุ่งที่แอนิเมเตอร์และผู้สร้างภาพยนตร์มืออาชีพที่ต้องการคัตต่อเนื่องยาวขึ้นที่ Veo ทำได้ไม่สม่ำเสมอ
Vidu Q3 เปิดโอกาสการใช้งานจริงอะไรบ้าง?
โฆษณาและมาร์เก็ตติ้งแบบสั้น
แบรนด์สามารถต้นแบบไอเดียโฆษณาแบบครบจบได้เร็วขึ้นมาก: เขียนสคริปต์ สร้างวิดีโอ 16 วินาทีพร้อม VO และ SFX ที่ซิงก์กัน ปรับคำและองค์ประกอบช็อต และผลิตเสียงพากย์หลายภาษาด้วยการเปลี่ยนพรอมป์ต์ การลดรอบเวลาสร้างเนื้อหาสำหรับ A/B Testing คือชัยชนะเชิงธุรกิจ เคสสตูดี้จากแพลตฟอร์มแสดงว่านักการตลาดใช้ Vidu Q3 กับไมโครแอดและทีเซอร์สินค้า
สตอรีบอร์ดและพรีวิชวลไลเซชันสำหรับภาพยนตร์และทีวี
ผู้กำกับและบรรณาธิการใช้คลิป AI สั้นๆ เป็นพรีวิสเพื่อบล็อกกิ้งฉาก ทดสอบการเคลื่อนกล้อง และพิตช์ทรีตเมนต์ ความสามารถลำดับหลายช็อตและสมาร์ตคาเมราของ Vidu Q3 มีประโยชน์มาก: ทีมครีเอทีฟสามารถลองบล็อกกิ้งและบทสนทนาโดยไม่ต้องเสียค่าใช้จ่ายถ่ายโลเคชัน แม้พรีวิสด้วย AI จะไม่แทนการกำกับบนกองถ่าย แต่มันย่นวัฏจักรการตัดสินใจช่วงต้นได้
อีเลิร์นนิงและวิดีโออธิบาย
ฝ่ายการศึกษาและการเรียนรู้ในองค์กรสามารถสร้างคลิปอธิบายสั้นๆ พร้อมคำบรรยายที่ซิงก์และ SFX ประกอบ สำหรับเนื้อหามาตรฐาน (เทรนนิงสินค้า ออนบอร์ดดิ้ง) สิ่งนี้ลดการพึ่งพาสตูดิโอราคาแพงและเร่งเวอร์ชันโลคัลไลซ์ ความเร็วสู่การเผยแพร่และความสามารถเสียงแบบเนทีฟทำให้ Vidu Q3 น่าสนใจอย่างยิ่งในกรณีนี้
เกม คอนเซปต์อาร์ต และโปรดักชันอินดี้
ผู้พัฒนาอินดี้และทีมเกมใช้คลิปภาพยนตร์สั้นด้วย AI สำหรับเทรลเลอร์ ม็อกอัปบทสนทนา NPC หรือสำรวจสไตล์ Vidu Q3 รองรับภาพอ้างอิงและความคงเส้นคงวาของตัวละคร ช่วยรักษาอัตลักษณ์ภาพของ IP เกมให้เสถียรในเทรลเลอร์ต้นแบบ โมเดลนี้ยังใช้ในสื่อพิตช์เพื่อระดมทุนหรือดึงดูดความสนใจจากผู้จัดจำหน่าย
การเข้าถึงและการทำโลคัลไลเซชันอย่างรวดเร็ว
เพราะเสียงถูกสร้างแบบเนทีฟ Vidu Q3 ทำให้เวอร์ชันหลายภาษาง่ายขึ้น: สร้างช็อตเดียวกันด้วยพรอมป์ต์ต่างภาษา หรือขอโทนเสียงพูดต่างกัน สิ่งนี้ช่วยเร่งการทำโลคัลไลซ์คอนเทนต์มาร์เก็ตติ้งหรือสื่อฝึกอบรม พร้อมคงความตรงปากในระดับที่เพียงพอสำหรับคอนเทนต์สั้นจำนวนมาก (อย่างไรก็ดี งานออกอากาศระดับสูงยังอาจต้องปรับแต่งโดยมนุษย์)
Vidu Q3 คือโมเดลวิดีโอ AI ที่ดีที่สุดในปี 2026 หรือไม่?
การประกาศว่ามี “ดีที่สุด” เพียงหนึ่งเดียวอาจพลาดความละเอียดอ่อน: ผู้ชนะขึ้นกับกรณีใช้งาน
- สำหรับเอาต์พุตโฟโตเรียลิสติก ยึดฟิสิกส์ และการจัดการความปลอดภัยแบบอนุรักษนิยม OpenAI’s Sora 2 มักถูกมองว่าเป็นตัวเลือกอันดับหนึ่ง เน้นความสมจริงและการกลั่นกรองที่แข็งแรง เหมาะกับโปรดักชันไฮเอนด์และองค์กรที่ระมัดระวังความเสี่ยง
- สำหรับคอนเทนต์ฟอร์แมตสั้นที่ผนวกกับแพลตฟอร์ม Veo 3.1 มีเอาต์พุตแนวตั้งแบบเนทีฟและอินทิเกรตกับแอปของ Google (YouTube Shorts, Google Photos) อย่างสะดวกเป็นพิเศษ
- สำหรับโปรโตไทป์เสียง-ภาพอย่างรวดเร็ว การควบคุมเรื่องเล่าหลายช็อต และบาลานซ์ฟีเจอร์เพื่อการเล่าเรื่องที่แข็งแรง Vidu Q3 โดดเด่น — โดยเฉพาะเมื่อความเร็วในการวนลองและเสียงที่บูรณาการสำคัญกว่าความโฟโตเรียลิสติกแบบสุดทาง เบนช์มาร์กช่วงต้นและรายงานจากผู้ให้บริการจัด Vidu Q3 ไว้สูงใน T2V และคุณสมบัติของมันทำให้เป็นตัวเลือกที่ลงตัวสำหรับนักการตลาด ครีเอเตอร์อิสระ และสตูดิโอที่กำลังต้นแบบไอเดียใหม่
ข้อจำกัดและข้อพิจารณา?
ขณะที่ Vidu Q3 เป็นก้าวกระโดด ก็ยังมีสิ่งแลกเปลี่ยน:
- ระยะเวลาคลิปยังถูกจำกัด (~16 s) ดังนั้นเรื่องที่ยาวกว่าต้องต่อคลิปหรือใช้พรอมป์ต์หลายชุด
- ต้นทุนทรัพยากรอาจเพิ่มตามการสร้างความละเอียดสูงและเสียงที่ซับซ้อน
- เครื่องมือ AI ยังต้องการ “วิจารณญาณด้านบรรณาธิการ” เพื่อขัดเกลาผลลัพธ์สู่ผลงานสำเร็จรูป
ดังนั้น: Vidu Q3 เป็นผู้ท้าชิงระดับหัวแถวในปี 2026 โดยเฉพาะสำหรับครีเอเตอร์ที่ให้ความสำคัญกับเวิร์กโฟลว์เสียงเนทีฟและการเล่าเรื่องหลายช็อต ส่วนจะเป็น “ที่หนึ่ง” หรือไม่ขึ้นกับบรีฟการผลิต ข้อกำกับดูแล และสายการเผยแพร่ของผู้ใช้
บทสรุป
Vidu Q3 โดดเด่นในปี 2026 ในฐานะโมเดลวิดีโอ AI ชั้นนำที่ผลิตคลิป เสียง-ภาพแบบบูรณาการพร้อมเล่าเรื่องได้ เชื่อมระหว่างความสร้างสรรค์และความต้องการผลิต เทียบกับ ความสอดประสานเชิงเรื่องเล่าที่แข็งแกร่งของ Sora 2 และ ความสมจริงเชิงภาพยนตร์ของ Veo 3.1 Vidu Q3 มอบชุดเครื่องมือที่สมดุล เหมาะอย่างยิ่งสำหรับนักเล่าเรื่อง คอนเทนต์ครีเอเตอร์ และเวิร์กโฟลว์เชิงพาณิชย์
เมื่อเบนช์มาร์กแสดงสมรรถนะสูงและคุณสมบัติที่ผนวกไว้ Vidu Q3 ถือเป็นจุดเปลี่ยนของวิดีโอ AI เชิงกำเนิด — ทำให้การผลิตเสียง-ภาพที่ซับซ้อนเข้าถึงได้และมีประสิทธิภาพมากขึ้น
นักพัฒนาสามารถเข้าถึง Vidu Q3, Veo 3.1 และ Sora 2 ผ่าน CometAPI โมเดลล่าสุดที่แสดงเป็นข้อมูล ณ วันที่เผยแพร่บทความ เพื่อเริ่มต้น สำรวจความสามารถของโมเดลใน Playground และดู API guide สำหรับคำแนะนำละเอียด ก่อนเข้าถึง โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับ API key แล้ว CometAPI มีราคาต่ำกว่าราคาทางการมากเพื่อช่วยให้คุณผนวกรวมได้ง่ายขึ้น
พร้อมลุยหรือยัง?→ สมัครใช้งานสำหรับการสร้างวิดีโอวันนี้ !
หากต้องการเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม ติดตามเราบน VK, X และ Discord!