

ท่ามกลางภูมิทัศน์ที่ถูกครอบงำด้วยแนวคิด “ขยายขนาดไม่ว่าต้องแลกด้วยอะไร” — ซึ่งโมเดลอย่าง Flux.2 และ Hunyuan-Image-3.0 ผลักจำนวนพารามิเตอร์ไปสู่ระดับมหาศาล 30B ถึง 80B — ผู้ท้าชิงรายใหม่ได้ปรากฏตัวขึ้นเพื่อเขย่าสถานะเดิม Z-Image ที่พัฒนาโดย Tongyi Lab ของ Alibaba เปิดตัวอย่างเป็นทางการ ทำลายความคาดหมายด้วยสถาปัตยกรรมกระทัดรัด 6 พันล้านพารามิเตอร์ ที่ให้คุณภาพผลลัพธ์ท้าทายยักษ์ใหญ่ในอุตสาหกรรม พร้อมยังทำงานได้บนฮาร์ดแวร์ระดับผู้ใช้ทั่วไป
เปิดตัวช่วงปลายปี 2025, Z-Image (และรุ่นความเร็วสูง Z-Image-Turbo) ได้รับความสนใจจากชุมชน AI ทันที โดยมียอดดาวน์โหลดเกิน 500,000 ครั้ง ภายใน 24 ชั่วโมงแรก ด้วยการสร้างภาพสมจริงระดับภาพถ่ายในเพียง 8 ขั้นตอนการอนุมาน Z-Image ไม่ใช่แค่โมเดลอีกตัวหนึ่ง; มันคือแรงผลักดันให้ AI สร้างสรรค์เป็นประชาธิปไตย เปิดโอกาสให้สร้างงานคุณภาพสูงบนแล็ปท็อปที่คู่แข่งทำให้ถึงกับชะงัก
Z-Image คืออะไร?
Z-Image เป็นโมเดลฐานการสร้างภาพแบบโอเพนซอร์สรุ่นใหม่ที่พัฒนาโดยทีมวิจัย Tongyi-MAI / Alibaba Tongyi Lab เป็นโมเดลสร้างภาพขนาด 6 พันล้านพารามิเตอร์ สร้างบนสถาปัตยกรรม Scalable Single-Stream Diffusion Transformer (S3-DiT) แบบใหม่ ที่นำโทเคนข้อความ โทเคนความหมายเชิงภาพ และโทเคน VAE มาต่อรวมเป็นสตรีมเดียว เป้าหมายการออกแบบชัดเจน: มอบความสมจริงระดับสูงสุดและการยึดตามคำสั่ง พร้อมลดต้นทุนการอนุมานอย่างมากและทำให้ใช้งานได้จริงบนฮาร์ดแวร์ผู้ใช้ทั่วไป โครงการ Z-Image เผยแพร่โค้ด น้ำหนักโมเดล และเดโมออนไลน์ภายใต้ไลเซนส์ Apache-2.0.
Z-Image มีหลายเวอร์ชัน รุ่นที่ถูกพูดถึงมากที่สุดคือ Z-Image-Turbo — เวอร์ชันกลั่น (distilled) แบบไม่กี่สเต็ปที่ปรับแต่งเพื่อการนำไปใช้งาน — รวมถึง Z-Image-Base ที่ไม่ผ่านการกลั่น (เช็คพอยต์ฐาน เหมาะกับการปรับจูน) และ Z-Image-Edit (ปรับจูนตามคำสั่งสำหรับการแก้ไขภาพ).
ข้อได้เปรียบของ “Turbo”: การอนุมาน 8 ขั้นตอน
รุ่นเรือธง Z-Image-Turbo ใช้เทคนิคการกลั่นแบบก้าวหน้าเรียกว่า Decoupled-DMD (Distribution Matching Distillation) ทำให้โมเดลบีบกระบวนการสร้างจากมาตรฐาน 30–50 ขั้นตอนลงเหลือเพียง 8 ขั้นตอน
ผลลัพธ์: เวลาในการสร้างระดับเสี้ยววินาทีบน GPU เอนเทอร์ไพรส์ (H800) และแทบเรียลไทม์บนการ์ดสำหรับผู้บริโภค (RTX 4090) โดยไม่มีลักษณะ “พลาสติก” หรือ “สีจืด” ที่พบได้ในโมเดล turbo/lightning อื่นๆ
4 คุณสมบัติสำคัญของ Z-Image
Z-Image อัดแน่นด้วยคุณสมบัติที่ตอบโจทย์ทั้งนักพัฒนาเชิงเทคนิคและมือสร้างสรรค์
1. ความสมจริงแบบภาพถ่ายและสุนทรียะที่เหนือชั้น
แม้จะมีเพียง 6 พันล้านพารามิเตอร์ Z-Image ก็ผลิตภาพที่คมชัดน่าทึ่ง โดดเด่นใน:
- พื้นผิวผิวหนัง: จำลองรูขุมขน ความไม่สมบูรณ์ และแสงธรรมชาติบนบุคคล
- ฟิสิกส์ของวัสดุ: เรนเดอร์แก้ว โลหะ และพื้นผิวผ้าอย่างแม่นยำ
- แสง: จัดการแสงเชิงภาพยนตร์และแสงเชิงปริมาตรได้ดีกว่า SDXL
2. การเรนเดอร์ข้อความแบบสองภาษาโดยกำเนิด
หนึ่งในปัญหาสำคัญของการสร้างภาพด้วย AI คือการเรนเดอร์ข้อความ Z-Image แก้ปัญหานี้ด้วยการรองรับ ทั้งภาษาอังกฤษและจีน
- สามารถสร้างโปสเตอร์ โลโก้ และป้ายที่ซับซ้อนพร้อมการสะกดและลายเส้นอักษรถูกต้องทั้งสองภาษา คุณสมบัตินี้มักไม่มีในโมเดลที่เน้นตะวันตก
3. Z-Image-Edit: การแก้ไขตามคำสั่ง
ควบคู่ไปกับโมเดลฐาน ทีมงานได้ปล่อย Z-Image-Edit เวอร์ชันนี้ปรับจูนสำหรับงาน image-to-image อนุญาตให้ผู้ใช้ปรับเปลี่ยนภาพที่มีอยู่ด้วยคำสั่งภาษาธรรมชาติ (เช่น "ทำให้คนคนนั้นยิ้ม", "เปลี่ยนพื้นหลังเป็นภูเขาหิมะ") โดยยังคงความสอดคล้องด้านเอกลักษณ์และแสงระหว่างการแปลง
4. การเข้าถึงบนฮาร์ดแวร์ผู้ใช้ทั่วไป
- ประสิทธิภาพ VRAM: ทำงานได้สบายบน 6GB VRAM (ด้วยการควอนไทซ์) ถึง 16GB VRAM (ความแม่นยำเต็ม)
- การรันแบบโลคัล: รองรับการดีพลอยโลคัลผ่าน ComfyUI และ
diffusersช่วยให้ผู้ใช้ไม่ต้องพึ่งพาคลาวด์
Z-Image ทำงานอย่างไร?
ตัวแปลงดิฟฟิวชันแบบสตรีมเดียว (S3-DiT)
Z-Image แตกต่างจากดีไซน์แบบสองสตรีมคลาสสิก (แยกเอนโค้ดเดอร์/สตรีมข้อความและภาพ) โดยนำโทเคนข้อความ โทเคน VAE ของภาพ และโทเคนความหมายเชิงภาพมาต่อรวมเป็นอินพุตทรานส์ฟอร์เมอร์เดียว แนวทางแบบ สตรีมเดียว นี้ปรับการใช้พารามิเตอร์ให้คุ้มค่าและทำให้การจัดแนวข้ามโมดัลภายในแบ็กโบนทรานส์ฟอร์เมอร์ง่ายขึ้น ซึ่งผู้เขียนระบุว่าให้สมดุลประสิทธิภาพ/คุณภาพที่ดีสำหรับโมเดล 6B.
Decoupled-DMD และ DMDR (การกลั่น + RL)
เพื่อให้การสร้างแบบไม่กี่สเต็ป (8 สเต็ป) โดยไม่เสียคุณภาพ ทีมงานพัฒนาแนวทางการกลั่น Decoupled-DMD ที่แยกการเพิ่ม CFG (classifier-free guidance) ออกจากการจับคู่การแจกแจง ทำให้แต่ละส่วนถูกปรับให้เหมาะสมอย่างอิสระ จากนั้นใช้ขั้นตอนการเรียนรู้แบบเสริมแรงหลังการฝึก (DMDR) เพื่อปรับปรุงการจัดแนวเชิงความหมายและสุนทรียะ ทั้งหมดนี้สร้าง Z-Image-Turbo ที่ใช้ NFE น้อยกว่าดิฟฟิวชันโมเดลทั่วไปอย่างมากแต่ยังคงความสมจริงสูง.
การเพิ่มประสิทธิภาพทราฟฟิกการฝึกและต้นทุน
Z-Image ถูกฝึกด้วยแนวทางเพิ่มประสิทธิภาพตลอดวงจร: สายข้อมูลที่คัดเลือกอย่างดี หลักสูตรที่กระชับ และการลงมือทำที่คำนึงถึงประสิทธิภาพ ผู้เขียนรายงานว่าจบเวิร์กโฟลว์การฝึกทั้งหมดในประมาณ 314K ชั่วโมง GPU H800 (≈ USD $630K) — เมตริกวิศวกรรมที่ชัดเจนและทำซ้ำได้ ซึ่งให้ภาพของความคุ้มค่าต้นทุนเมื่อเทียบกับทางเลือกที่ใหญ่มาก (>20B)
ผลทดสอบมาตรฐานของโมเดล Z-Image
Z-Image-Turbo ติดอันดับสูงในหลายลีดเดอร์บอร์ดร่วมสมัย รวมถึงตำแหน่งโอเพนซอร์สระดับท็อปบน Artificial Analysis Text-to-Image leaderboard และผลงานที่แข็งแกร่งบนการประเมินความชอบของมนุษย์ใน Alibaba AI Arena
แต่คุณภาพในโลกจริงยังขึ้นอยู่กับการกำหนดพรอมต์ ความละเอียด ขั้นตอนขยายความละเอียด และการโพสต์โปรเซสเพิ่มเติม
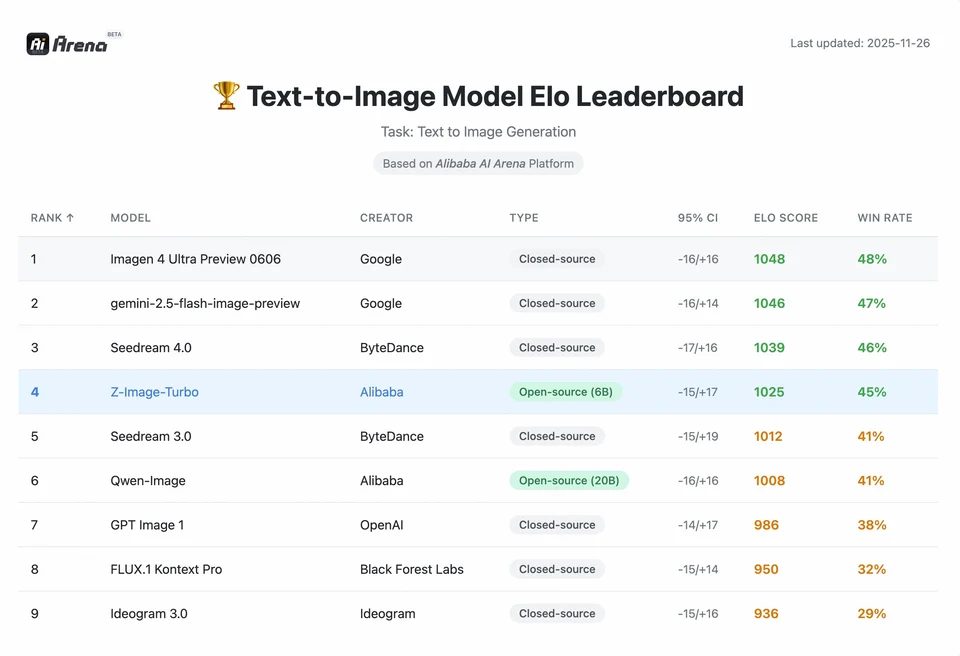
เพื่อเข้าใจขนาดของความสำเร็จของ Z-Image เราต้องดูข้อมูล ด้านล่างเป็นการวิเคราะห์เปรียบเทียบ Z-Image กับโมเดลโอเพนซอร์สและเชิงพาณิชย์ชั้นนำ
สรุปการเปรียบเทียบ Benchmark
| คุณสมบัติ / เมตริก | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| สถาปัตยกรรม | S3-DiT (สตรีมเดียว) | MM-DiT (สองสตรีม) | U-Net | Diffusion Transformer |
| จำนวนพารามิเตอร์ | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| ขั้นตอนการอนุมาน | 8 ขั้นตอน | 25 - 50 ขั้นตอน | 1 - 4 ขั้นตอน | 30 - 50 ขั้นตอน |
| VRAM ที่ต้องใช้ | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| การเรนเดอร์ข้อความ | สูง (EN + CN) | สูง (EN) | ปานกลาง (EN) | สูง (CN + EN) |
| ความเร็วการสร้าง (4090) | ~1.5 - 3.0 วินาที | ~15 - 30 วินาที | ~0.5 วินาที | ~20 วินาที |
| คะแนนความสมจริงระดับภาพถ่าย | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| ไลเซนส์ | Apache 2.0 | ไม่เชิงพาณิชย์ (Dev) | OpenRAIL | กำหนดเอง |
การวิเคราะห์ข้อมูลและมุมมองประสิทธิภาพ
- ความเร็วเทียบคุณภาพ: แม้ SDXL Turbo จะเร็วกว่า (1 สเต็ป) แต่คุณภาพลดลงมากในพรอมต์ที่ซับซ้อน Z-Image-Turbo เข้าจุดหวานที่ 8 สเต็ป ให้คุณภาพเทียบ Flux.2 แต่ เร็วกว่า 5x ถึง 10x
- การทำให้ฮาร์ดแวร์เข้าถึงได้: แม้ Flux.2 จะทรงพลัง แต่นับว่าแทบถูกจำกัดด้วยการ์ด VRAM 24GB (RTX 3090/4090) เพื่อความเร็วที่เหมาะสม Z-Image ทำให้ผู้ใช้การ์ดระดับกลาง (RTX 3060/4060) สร้างภาพคุณภาพระดับมืออาชีพที่ 1024x1024 ได้แบบโลคัล
นักพัฒนาจะเข้าถึงและใช้ Z-Image ได้อย่างไร?
มี 3 แนวทางทั่วไป:
- โฮสต์ / SaaS (เว็บ UI หรือ API): ใช้บริการเช่น z-image.ai หรือผู้ให้บริการอื่นที่ดีพลอยโมเดลและเปิดเว็บอินเทอร์เฟซหรือ API แบบเสียเงินสำหรับการสร้างภาพ วิธีนี้เร็วที่สุดสำหรับการลองใช้งานโดยไม่ต้องตั้งค่าบนเครื่อง
- Hugging Face + diffusers pipelines: ไลบรารี
diffusersของ Hugging Face มีZImagePipelineและZImageImg2ImgPipelineและรองรับเวิร์กโฟลว์มาตรฐานfrom_pretrained(...).to("cuda")นี่เป็นเส้นทางที่แนะนำสำหรับนักพัฒนา Python ที่ต้องการอินทิเกรตแบบตรงไปตรงมาและตัวอย่างที่ทำซ้ำได้. - การอนุมานแบบโลคัลจาก GitHub repo: repo ของ Tongyi-MAI มีสคริปต์อนุมานแบบ native ตัวเลือกเพิ่มประสิทธิภาพ (FlashAttention, การคอมไพล์, การย้ายภาระไป CPU) และคำแนะนำการติดตั้ง
diffusersจากซอร์สเพื่อการอินทิเกรตล่าสุด เส้นทางนี้เหมาะกับนักวิจัยและทีมที่ต้องการควบคุมเต็มรูปแบบหรือรันการฝึก/ปรับจูนแบบกำหนดเอง.
ตัวอย่าง Python แบบมินิมอลเป็นอย่างไร?
ด้านล่างเป็นสแนิปต์ Python แบบกระชับโดยใช้ diffusers ของ Hugging Face สำหรับการสร้างภาพจากข้อความด้วย Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # ใช้ bfloat16 เมื่อรองรับเพื่อประสิทธิภาพบน GPU ทันสมัย pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"บันทึกแล้ว: {output_path}")if __name__ == "__main__": generate("ภาพพอร์ตเทรตสไตล์ภาพยนตร์ของหุ่นยนต์จิตรกร แสงสตูดิโอ รายละเอียดสูงมาก")
หมายเหตุ:guidance_scale ค่าเริ่มต้นและการตั้งค่าที่แนะนำอาจแตกต่างสำหรับโมเดล Turbo; เอกสารแนะนำว่า guidance อาจตั้งไว้ต่ำหรือศูนย์สำหรับ Turbo ขึ้นกับพฤติกรรมที่ต้องการ
จะรัน image-to-image (แก้ไข) ด้วย Z-Image อย่างไร?
ZImageImg2ImgPipeline รองรับการแก้ไขภาพ ตัวอย่าง:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "แปลงสเก็ตช์นี้ให้เป็นหุบเขาแม่น้ำแฟนตาซีที่มีสีสันสดใส"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
สิ่งนี้สะท้อนรูปแบบการใช้งานทางการ และเหมาะสำหรับงานแก้ไขเชิงสร้างสรรค์และการทำ inpainting
ควรตั้งค่าพรอมต์และ guidance อย่างไร?
- ระบุโครงสร้างให้ชัดเจน: สำหรับฉากซับซ้อน ให้จัดพรอมต์เพื่อรวมองค์ประกอบฉาก วัตถุหลัก กล้อง/เลนส์ แสง อารมณ์ และองค์ประกอบข้อความ Z-Image ทำงานได้ดีเมื่อพรอมต์ละเอียด และจัดการสัญญาณเชิงตำแหน่ง/การเล่าเรื่องได้ดี.
- ปรับค่า guidance_scale อย่างระมัดระวัง: โมเดล Turbo อาจแนะนำค่า guidance ที่ต่ำ; ต้องทดลอง สำหรับหลายเวิร์กโฟลว์ Turbo
guidance_scale=0.0–1.0พร้อม seed และจำนวนสเต็ปคงที่ ให้ผลที่สม่ำเสมอ - ใช้ image-to-image สำหรับการแก้ไขที่ควบคุมได้: เมื่อคุณต้องการรักษาองค์ประกอบแต่เปลี่ยนสไตล์/สี/วัตถุ ให้เริ่มจากภาพตั้งต้นและใช้
strengthเพื่อควบคุมขนาดการเปลี่ยนแปลง
กรณีใช้งานและแนวทางปฏิบัติที่ดีที่สุด
1. การทำต้นแบบอย่างรวดเร็วและสตอรีบอร์ด
Use Case: ผู้กำกับภาพยนตร์และนักออกแบบเกมต้องการเห็นภาพฉากทันที
ทำไมต้อง Z-Image? ด้วยการสร้างภาพไม่ถึง 3 วินาที ผู้สร้างสามารถไล่ไอเดียหลายร้อยแบบในเซสชันเดียว ปรับแสงและองค์ประกอบได้แบบเรียลไทม์โดยไม่ต้องรอเรนเดอร์เป็นนาที
2. อีคอมเมิร์ซและโฆษณา
Use Case: สร้างฉากพื้นหลังสินค้า หรือภาพไลฟ์สไตล์สำหรับสินค้า
Best Practice: ใช้ Z-Image-Edit.
อัปโหลดภาพสินค้าดิบ แล้วใช้พรอมต์แบบคำสั่งเช่น "วางขวดน้ำหอมนี้บนโต๊ะไม้ในสวนที่มีแสงแดดส่อง" โมเดลจะคงความถูกต้องของสินค้าไว้ พร้อมจินตนาการพื้นหลังสมจริงระดับภาพถ่าย
3. สร้างคอนเทนต์สองภาษา
Use Case: แคมเปญการตลาดระดับโลกที่ต้องการงานสำหรับทั้งตลาดตะวันตกและเอเชีย
Best Practice: ใช้ความสามารถเรนเดอร์ข้อความ.
- พรอมต์: "ป้ายไฟนีออนที่เขียนว่า 'OPEN' และ '营业中' เรืองแสงในตรอกมืด"
- Z-Image จะเรนเดอร์ตัวอักษรทั้งอังกฤษและจีนได้ถูกต้อง ซึ่งโมเดลอื่นจำนวนมากทำไม่ได้
4. สภาพแวดล้อมทรัพยากรต่ำ
Use Case: รันการสร้างภาพด้วย AI บนอุปกรณ์ขอบเครือข่ายหรือแล็ปท็อปสำนักงานมาตรฐาน
เคล็ดลับการเพิ่มประสิทธิภาพ: ใช้เวอร์ชัน INT8 quantized ของ Z-Image ทำให้ใช้ VRAM ต่ำกว่า 6GB โดยคุณภาพลดลงเล็กน้อย เหมาะสำหรับแอปโลคัลบนแล็ปท็อปที่ไม่ใช่เกมมิง
สรุป: ใครควรใช้ Z-Image?
Z-Image ถูกออกแบบมาสำหรับองค์กรและนักพัฒนาที่ต้องการ ความสมจริงระดับสูง พร้อม ความหน่วงและต้นทุนที่ใช้งานจริง และที่ชอบ ไลเซนส์แบบเปิด รวมถึงการโฮสต์แบบออน-พริมิสหรือกำหนดเอง โดยเฉพาะเหมาะกับทีมที่ต้องการไล่ไอเดว่องไว (เครื่องมือสร้างสรรค์ ม็อกอัปสินค้า บริการเรียลไทม์) และนักวิจัย/ชุมชนที่สนใจปรับจูนโมเดลสร้างภาพที่กะทัดรัดแต่ทรงพลัง
CometAPI มีโมเดล Grok Image ที่จำกัดน้อยในทำนองเดียวกัน รวมถึงโมเดลอย่าง Nano Banana Pro, GPT- image 1.5, Sora 2(Can Sora 2 generate NSFW content? How can we try it?) เป็นต้น — โดยมีเงื่อนไขว่าคุณมีเคล็ดลับ NSFW ที่ถูกต้องเพื่อเลี่ยงข้อจำกัดและเริ่มสร้างได้อย่างอิสระ ก่อนเข้าใช้งาน โปรดตรวจสอบว่าคุณได้ล็อกอิน CometAPI และได้รับ API key แล้ว CometAPI เสนอราคา ที่ต่ำกว่าราคาอย่างเป็นทางการเพื่อช่วยคุณอินทิเกรต
พร้อมเริ่มหรือยัง?→ ทดลองสร้างฟรี !