

xAI sessizce piyasaya sürüldü Grok 4.1 (17–18 Kasım 2025) — Grok 4'e öncelik veren odaklanmış bir yükseltme duygusal zeka, yaratıcı ifade ve azalmış halüsinasyon Önceki Grok sürümlerinin keskin mantığı korunurken, iki modda (Düşünen/Düşünmeyen) geliyor, Kasım ayı başlarında sessizce kullanıma sunuldu, LMArena'da en iyi liderlik tablosu sonuçlarını gösteriyor ve grok.com, Grok uygulamaları ve API aracılığıyla edinilebiliyor.
Grok 4.1 nedir?
Grok 4.1, Grok 4'ün kademeli, üretim odaklı halefidir: aynı büyük ölçekli takviyeli öğrenme temeli üzerine inşa edilmiş, ancak stil, kişilik, uyum ve gerçek dünya güvenilirliğini hedefleyen yoğun eğitim sonrası optimizasyonlarla ince ayar yapılmış ve yeniden eğitilmiş bir aile üyesidir. Pragmatik ve "kullanılabilir" bir adım olarak konumlandırılıyor: Kör insan tercih testlerinde daha akıllı, duygusal olarak daha zeki, yaratıcı yazmada daha iyi ve önceki yüksek performanslı hukuk lisans programlarını (LLM) rahatsız eden türden kendine güvenen ama yanlış "halüsinasyonlara" ölçülebilir derecede daha az eğilimli.
Grok 4.1 aşağıdaki dört boyutta niteliksel değişiklikler sağlar:
- Yaratıcılık: Yazma, hikaye anlatma ve sosyal bağlamlarda daha güçlü bir dil stili ve hayal gücü gösterir;
- Duygusal Zeka: Tonu ve duygusal değişimleri tanır, daha insani duygusal mantıkla yanıt verir ve rahatlatıcı ve anlayışlı tepkiler üretir;
- Kişilik Tutarlılığı: Uzun konuşmalarda tutarlı bir ton ve kişilik sergiler, artık önceki modellerin tutarsız davranışlarını sergilemez;
- İşbirlikçi: Çok yönlü diyaloglarda veya görev iş birliğinde tutarlılığı ve hedef farkındalığını korur.
xAI özelliklerini tek bir cümleyle özetliyor: "Daha algılayıcı, daha empatik ve daha tutarlı bir insan gibi."
Grok 4.1 kaputun altında nasıl çalışıyor?
Grok 4.1, Grok 4 ailesinde kullanılan aynı önceden eğitilmiş omurga artı odaklanan katmanlı bir eğitim sonrası boru hattı olarak en iyi şekilde anlaşılabilir ödül modellemesi, stil uyumu ve aracı değerlendiriciler.
Eğitim ve uyum aşamaları nelerdir?
Grok 4.1, modern öncü LLM'lerin tipik özelliği olan çok aşamalı bir boru hattı üzerinde çalışır ve 4.1 için iki önemli değişiklikle uyarlanmıştır:
- Ön antrenman + ara antrenman: Web verileri üzerinde büyük bir korpus ön eğitimi + alan bilgisini ve çok modlu yetenekleri artırmak için hedefli ara eğitim.
- Gözetimli ince ayar (SFT): İstenilen davranışlara yönelik insan gösterileri (cevaplar, reddetme stratejileri).
- Ödül modellemesi (yeni uygulama): xAI, ödül modellerini yalnızca insan tercihi etiketlerine göre değil, aynı zamanda sınır aracı akıl yürütme modelleri Ödül notlandırıcıları olarak — yüksek yetenekli, model tabanlı değerlendiricilerin aday çıktılarını büyük ölçekte puanlamasına olanak tanır. Bu, doğrulanamayan niteliklerin optimizasyonunu mümkün kılar. stil, kişilik uyumu, empati ve yardımseverlik imkansız derecede büyük bir insan etiketleme bütçesi gerektirmeden.
- Politika optimizasyonu (RLHF / RL model ödüllerinden): Öğrenilen ödül sinyallerini kullanarak dağıtılan politikayı (tüketicilerin etkileşim kurduğu model) üretmek için standart politika optimizasyonu.
Ödül modelleme yaklaşımında yenilikler neler?
Geleneksel RLHF'de, insan tercih etiketlerini (A/B) toplar, bu etiketleri tahmin etmek için bir ödül modeli eğitir ve ardından temel modeli, öğrenilen ödüle göre RL (veya reddetme örneklemesi) ile optimize edersiniz. Ancak xAI'nın öne çıkardığı iki pratik yenilik şunlardır:
- Temsilci ödül modelleri: xAI, salt insan yargıçlar yerine, daha incelikli özellikleri (ton, duygusal nüans, yaratıcılık) değerlendirmek için puanlayıcı olarak yetenekli "etkisel" akıl yürütme modelleri kullandı. Puanlayıcılar, binlerce ikili karşılaştırmayı hızla çalıştırarak mühendislerin daha hızlı yineleme yapmasını sağlayabilir. Bu, stil ve duygusal zekâda önemli gelişmelerin mekanizmasıdır.
- Doğrulanamayan sinyaller için eğitim sonrası hizalama: Belirleyici bir ölçümle ölçemeyeceğiniz nitelikler için (örneğin, "sıcaklık" veya "tutarlı kişilik"), modelin öğrenmesi için özel ödül hedefleri ve ölçeklenebilir müfredatlar sundular. stil Temel olgusal doğruluktan ödün vermeden çıktıların.
"Düşünme" ile "düşünmeme" arasındaki fark teknik olarak nasıl işliyor?
- Grok 4.1 Thinking (kod adı
quasarflux) — Nihai cevabı üretmeden önce açık muhakeme adımlarını (düşünme belirteçlerini) ortaya koyar; LMArena'da karmaşık görevler ve daha yüksek Elo için optimize edilmiştir. Ekstra belirteçler çıkarım süresi gerektirir, ancak çok adımlı muhakeme görevlerine, hata ayıklamaya ve açıklanabilirliğe yardımcı olur. - Grok 4.1 Düşünmeyen (kod adı
tensor) Açık ara belirteçleri atlayarak tek ve anında bir nihai yanıt sağlar. Bu, aynı gelişmiş politika ağırlıklarından yararlanmaya devam ederken gecikmeyi ve belirteç maliyetini azaltır. Düşünmeyen mod, son derece düşük gecikme süresi ve yine de yüksek yeteneklere sahip olacak şekilde optimize edilmiştir.
Duygu ve stilin hizalama optimizasyonu
Basit "doğruluk" sinyallerinin ötesinde, Grok 4.1, duygu, ton ve kişilerarası tarz için hedefli uyum optimizasyonu içerir. Bu, eğitim sürecinin, uyumsuz tonu (örneğin, empatinin uygun olduğu durumlarda gereksiz yere sert davranmak) açıkça cezalandıran ödül veya kayıp bileşenlerini ve istenen stil veya duygu profiline uyan ödül yanıtlarını içerdiği anlamına gelir. Yapay zeka, Grok 4.1'de ilk olarak "Kişilik Uyumu" optimizasyon hedefini ortaya koydu.
Modelin tutarlı ve istikrarlı bir kimlik duygusunu korumasına yardımcı olmayı amaçlamaktadır. Grok 4 ile karşılaştırıldığında, 4.1 eğitim hedeflerine şunları ekler:
- Duygusal ifade boyutu için pozitif ödüller (duygusal uyum ödülü);
- Kişilik tutarlılığı ölçütü.
Grok 4.1 nasıl değerlendirildi ve performansı nasıldı?
Kör insanlarda yapılan tercih testleri neyi gösterdi?
Sessiz bir dağıtım sırasında, Grok 4.1 canlı trafikte önceki üretim modeline kıyasla %64.78 oranında tercih edildi; bu, vahşi doğada daha iyi konuşma sonuçlarına işaret eden güçlü bir insan tercihi sinyalidir.
Grok 4.1 liderlik tablolarında zirveye yerleşiyor mu?
xAI, Grok 4.1'in Düşünme mod oturur LMArena'nın Metin Arenası'nda 1 numara, bildirilen Elo ile 1483ve akıl yürütme gerektirmeyen (hızlı) modu 1465 Elo ile 2. sırada yer alıyor — hem doğruluk hem de sunum açısından güçlü genel liderlik sıralamaları (stil kontrolü rol oynuyor).
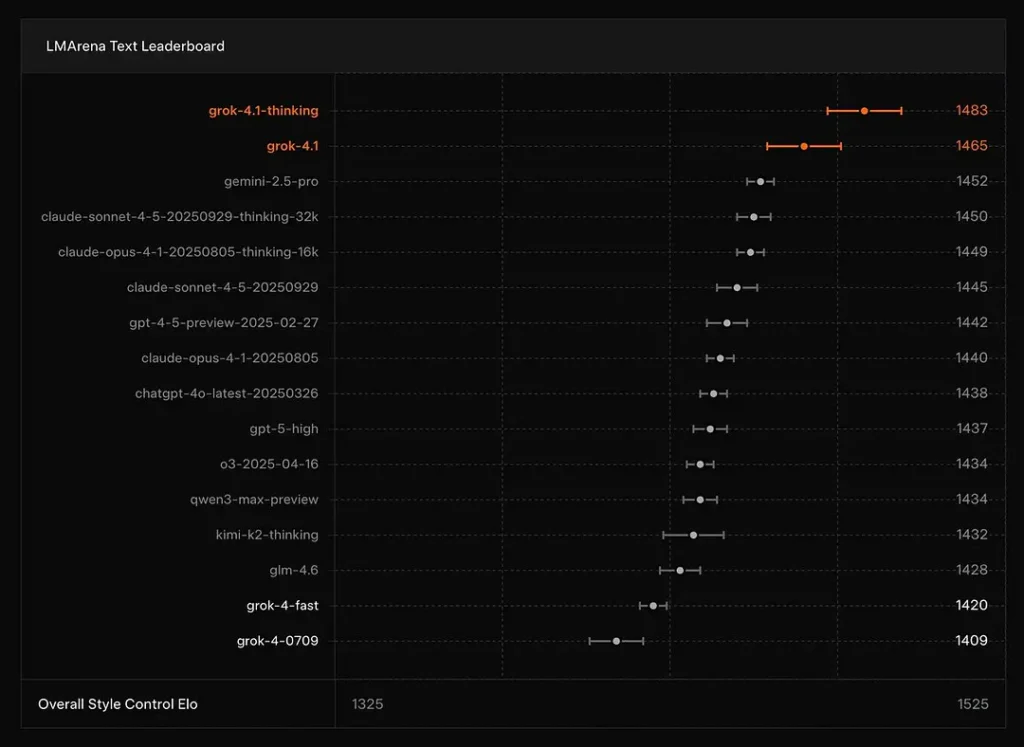
Sonuç: Grok 4.1, metin anlama, oluşturma ve genel kalite açısından ana akım GPT-4.5 ve Claude serisi modellerini geride bırakarak, yalnızca GPT-5 Gelişmiş Önizleme sürümünden sonra ikinci sırada yer almaktadır.
Duygusal zeka
xAI, 45 zorlu rol yapma senaryosunu kapsayan duygusal zeka için özel bir test olan EQ-Bench3'ü çalıştırdı ve Grok 4.1'in empati, hız ve kişilerarası içgörüde güçlü kazanımlar gösterdiğini bildirdi. Grok 4.1, üzüntü, empati ve rahatlık bağlamlarını anlamada en yüksek puanı aldı.

Yaratıcı yazarlık aslında daha yaratıcı mıdır?
Grok 4.1 şu şekilde değerlendirildi: Yaratıcı Yazarlık v3 (3 yinelemede 32 komut ve değerlendirme ölçütü + Elo puanlaması). xAI, 4.1'in yazım tarzının, ses tutarlılığının ve anlatım yaratıcılığının önemli ölçüde arttığını ve yaratıcı görevler için son liderlik tablolarının en üst sıralarına yerleştiğini belirtiyor (örnek komutlar sürümde yer almaktadır). Bağımsız raporlar da bu bulguları yansıttı: İncelemeciler, belirgin şekilde daha "ayırt edici bir ses" ve daha iyi uzun biçim tutarlılığı gözlemlediler. Yazım kalitesi açısından Grok 4.1, GPT-5 serisi modellerinden sonra ikinci sırada yer alıyor ve Claude, Gemini ve Kimi'nin tüm ürün serilerini geride bırakıyor.

Azalmış halüsinasyon / dürüstlük
xAI, halüsinasyon oranlarında önemli bir azalma olduğunu iddia ediyor: (duyuruda ve sosyal paylaşımlarda) Grok 4.1'in ~ olduğunu bildirdilerHalüsinasyon görme olasılığı 3 kat daha az Üretim trafiği analizleri ve FActScore tarzı değerlendirmelere (örneğin, biyografi/biyografi soru setleri, ne kadar düşükse o kadar iyidir) atıfta bulunan önceki Grok modelleriyle karşılaştırıldığında, özellikle harici arama araçlarının mevcut olduğu "akıl yürütmeyen modda", gerçeklerin tutarlılığı daha istikrarlıdır.

Grok 4.1 neden diğer modelleri "eziyor" — bu bir abartma mı?
"Crushes" pazarlama amaçlı bir ifadedir, ancak bu iddianın arkasında nesnel iddialar vardır:
- Skor Tabloları: Grok 4.1, xAI'nin her sürümünde metin oluşturma (1483 Elo for Thinking modu) ve güçlü yaratıcılık ve EQ-kulübesi performansları açısından herkese açık LMArena liderlik tablolarında üst sıralarda yer alıyor. Bunlar, topluluk genelinde kullanılan, rekabet açısından kıyaslanabilir metriklerdir.
- Gerçek trafik tercihi kazanır: xAI, canlı trafikte sessiz bir lansmanda kör karşılaştırmalarda insan tercihi kazanımları (önceki üretim modeline kıyasla yaklaşık %65 tercih) bildiriyor. Bu, yalnızca kağıt üzerindeki kıyaslamaları değil, gerçek kullanıcı iyileştirmelerini de yansıtıyor.
- Pratik yeni yetenek: Model derecelendiricilerin, doğrulanabilir olmayan sinyaller üzerindeki RL'nin ve daha katı giriş filtrelerinin birleşimi, rakiplerin tarihsel olarak düşük performans gösterdiği konuşma, empati ve yaratıcı görevlerde kullanıcı deneyimini doğrudan iyileştiren pragmatik bir mühendislik adımıdır.
Yani, "ezilmeler" "birden fazla kamu ve iç değerlendirmede liderlik" demenin renkli bir yolu olsa da, xAI'nin bu sonuca dayanarak yayınladığı temel kamu metrikleri
Grok 4.1'e nasıl erişilir?
Tüketici / uygulama erişimi
xAI, Grok 4.1'i periyodik olarak ücretsiz veya promosyon penceresi olarak "Otomatik" modda erişilebilir hale getirdi, ancak premium seviyeler (SuperGrok, SuperGrok Heavy) ve daha yüksek kotalara sahip API erişimi ücretli teklifler olarak mevcut ve devam ediyor.
Grok 4.1 tüm kullanıcılara açıktır on grok.com, **X (eski adıyla Twitter)**ve iOS ve Android Grok uygulamaları, Otomatik modda hemen kullanıma sunulurken, model seçicide açıkça “Grok 4.1” olarak seçilebiliyor.
API erişimi ve geliştirici planları
Grok 4.1 uç noktalarına xAI API üzerinden erişilebilir. Bu makalenin yayınlanma tarihi itibarıyla, resmi GPT 4.1 API'si henüz yayınlanmamıştır.
Kuyrukluyıldız API'si en son model dinamiklerini takip etme sözü veriyor Grok 4.1 APIResmi sürümle aynı anda yayınlanacak. Lütfen sabırsızlıkla bekleyin ve CometAPI'yi takip etmeye devam edin. Beklerken, Grok'un diğer modellerine de göz atabilirsiniz: Grok-kod-hızlı-1 ve Grok 4, Oyun Alanı'ndaki yeteneklerini keşfedin ve 'yi çağırmak için ayrıntılı talimatlar için API kılavuzuna başvurun. Erişimden önce, lütfen CometAPI'ye giriş yaptığınızdan ve API anahtarını aldığınızdan emin olun.
Grok 4.1'i üretimde kullanmaya yönelik pratik ipuçları
Halüsinasyon riskini nasıl azaltabiliriz?
- Canlı aramayı etkinleştir veya bilgi arama sorguları için doğrulanmış bir araç zinciri.
- Doğrulama adımlarını sağlayın: modelden gerçek iddialar için kaynakları ve kanıtları geri getirmesini isteyin;
responseatıfları denetlemek için meta veriler (eğer varsa). - Deterministik kontrolleri çalıştırın (doğrulama LLM'leri, yapılandırılmış veri doğrulayıcıları) yüksek riskli çıktılar için bir son işleme adımı olarak.
Ton ve stil nasıl kontrol edilir?
- Ses tonunu düzeltmek için açık sistem komutlarını kullanın (“Siz resmi ve anlayışlısınız.”).
- Uygulamalar arasında tutarlı bir ses için denetlenen komutları ve küçük yerel şablonları kullanın.
- Mümkün olduğunda xAI'nin stil kontrol seçeneğinden ve ödül odaklı direksiyon düğmelerinden yararlanın.
Son karar: Grok 4.1 kökten bir değişiklik mi?
Grok 4.1 değil yepyeni bir mimari; daha ziyade, sofistike ve düşünceli bir eğitim sonrası / hizalama Sohbette insanların gerçekten önemsediği şeylere odaklanan sürüm: kişilik, duygusal zeka, yaratıcılık ve daha az olgusal hataLiderlik tablolarında ölçülebilir kazanımlar, büyük ölçekli gerçek trafik tercihleri ve geliştirilmiş güvenlik araçları. Yüksek kaliteli sohbet, yaratıcı iş birliği veya ton duyarlı yardıma dayanan uygulamalar için Grok 4.1, önemli bir ilerlemedir ve birçok topluluk ölçütünde, piyasaya sürüldüğü tarihte en iyi performansı göstermiştir.
CometAPI, geliştiricilere tek ve tutarlı bir arayüz aracılığıyla birden fazla tedarikçiden (metin LLM'leri, görüntü/video oluşturucular, yerleştirmeler ve daha fazlası) yüzlerce yapay zeka modeline birleşik, OpenAI tarzı REST erişimi sağlayan ticari bir API toplama platformudur. OpenAI, Anthropic, Google, Meta veya daha küçük özel model sağlayıcıları için ayrı SDK'lar veya özel uç noktalar bağlamak yerine, CometAPI, model dizelerini ve birkaç parametreyi değiştirerek farklı modelleri çağırmanıza olanak tanır.
Denemeye hazır mısınız?→ Bugün CometAPI'ye kaydolun !
Yapay zeka hakkında daha fazla ipucu, kılavuz ve haber öğrenmek istiyorsanız bizi takip edin VK, X ve Katılın!