

17 Haziran'da Şanghay AI tek boynuzlu atı MiniMax resmi olarak açık kaynaklı hale getirildi MiniMax‑M1Dünyanın ilk açık ağırlık büyük ölçekli hibrit dikkat çıkarım modeli. Bir Uzman Karışımı (MoE) mimarisini yeni Lightning Dikkat mekanizmasıyla birleştirerek MiniMax‑M1, çıkarım hızında, ultra uzun bağlam işlemede ve karmaşık görev performansında önemli kazanımlar sağlar.
Arka Plan ve Evrim
Temelin üzerine inşa etmek MiniMax-Metin-01Eğitim sırasında 1 milyon belirteç bağlamı ve çıkarımda 4 milyon belirtece kadar elde etmek için bir Uzmanlar Karışımı (MoE) çerçevesine yıldırım dikkati getiren MiniMax-M1, MiniMax-01 serisinin bir sonraki neslini temsil eder. Önceki model olan MiniMax-Text-01, belirteç başına 456 milyar etkinleştirilmiş toplam 45.9 milyar parametre içeriyordu ve bağlam yeteneklerini büyük ölçüde genişletirken en üst düzey LLM'lerle eşit performans gösteriyordu.
MiniMax‑M1'in Temel Özellikleri
- Hibrit MoE + Lightning Dikkat: MiniMax‑M1, toplam 456 milyar parametre, ancak token başına yalnızca 45.9 milyar etkinleştirilen seyrek bir Uzman Karışımı tasarımını, çok uzun diziler için optimize edilmiş doğrusal karmaşıklıkta bir dikkat olan Lightning Attention ile birleştirir.
- Ultra Uzun Bağlam: Kadar destekler 1 milyon Giriş belirteçleri (DeepSeek‑R128'in 1 K sınırının yaklaşık sekiz katı) büyük belgelerin derinlemesine anlaşılmasını sağlar.
- Üstün Verimlilik: 100 K token üretirken, MiniMax‑M1'in Lightning Attention'ı DeepSeek‑R25 tarafından kullanılan hesaplamanın yalnızca %30-1'unu gerektirir.
Model Varyantları
- MiniMax‑M1‑40K: 1 M token bağlamı, 40 K token çıkarım bütçesi
- MiniMax‑M1‑80K: 1 M token bağlamı, 80 K token çıkarım bütçesi
TAU-tezgah aracı kullanım senaryolarında, 40K varyantı Gemini 2.5 Pro dahil olmak üzere tüm açık ağırlıklı modellerden daha iyi performans göstererek ajan yeteneklerini kanıtladı.
Eğitim Maliyeti ve Kurulum
MiniMax-M1, gelişmiş matematiksel akıl yürütmeden sanal alan tabanlı yazılım mühendisliği ortamlarına kadar çeşitli görevler boyunca büyük ölçekli takviyeli öğrenme (RL) kullanılarak uçtan uca eğitildi. Yeni bir algoritma, CISPO (Politika Optimizasyonu için Kesilmiş Önem Örneklemesi), jeton düzeyindeki güncellemeler yerine önem örnekleme ağırlıklarını keserek eğitim verimliliğini daha da artırır. Bu yaklaşım, modelin yıldırım dikkatiyle birleştirildiğinde, 512 H800 GPU'da tam RL eğitiminin yalnızca üç haftada, toplam kira bedeli $534,700'e tamamlanmasına olanak sağladı.
Müsaitlik ve Fiyatlandırma
MiniMax-M1, Apache 2.0 açık kaynaklı lisansa sahiptir ve şu şekilde hemen erişilebilir:
- GitHub deposuModel ağırlıkları, eğitim betikleri ve değerlendirme ölçütleri dahil olmak üzere.
- SilikonBulut barındırma, iki çeşit sunuyor—40 K-token (“M1-40K”) ve 80 K-token (“M1-80K”)—ve tam 1 M token hunisini etkinleştirmeyi planlıyor.
- Fiyatlandırma şu anda şu şekilde belirlendi: Milyon başına 4 ¥ giriş ve için belirteçler Milyon başına 16 ¥ çıktı için tokenler, kurumsal müşteriler için hacim indirimleri mevcuttur.
Geliştiriciler ve kuruluşlar, MiniMax-M1'i standart API'ler aracılığıyla entegre edebilir, etki alanına özgü veriler üzerinde ince ayar yapabilir veya hassas iş yükleri için şirket içinde dağıtabilir.
Görev Düzeyinde Performans
| Görev Kategorisi | İlginizi Çekebilir | Göreceli performans |
|---|---|---|
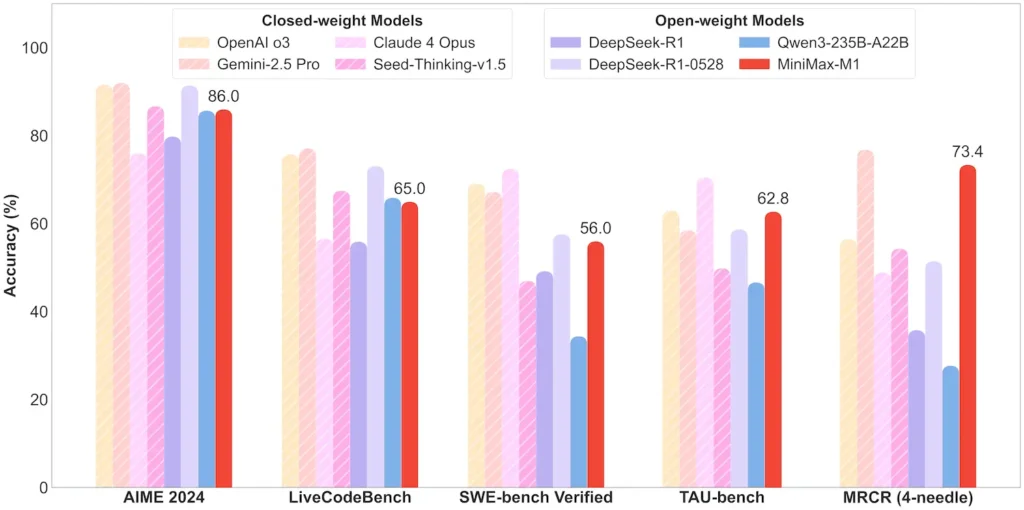
| Matematik ve Mantık | AIME 2024: %86.0 | > Qwen 3, DeepSeek‑R1; kapalı kaynaklıya yakın |
| Uzun Bağlam Anlayışı | Cetvel (4 K–1 M token): Kararlı üst düzey | 4 K token uzunluğunun ötesinde GPT‑128'ten daha iyi performans gösterir |
| Yazılım Mühendisliği | SWE-bench (gerçek GitHub hataları): %56 | Açık modeller arasında en iyisi; kapalı modellere göre 2. sırada |
| Ajan ve Araç Kullanımı | TAU-tezgahı (API simülasyonu) | %62–63.5, Gemini 2.5, Claude 4'e karşı |
| Diyalog ve Asistan | Çoklu Meydan Okuma: %44.7 | Claude 4, DeepSeek‑R1 ile eşleşir |
| Gerçek QA | BasitQA: %18.5 | Gelecekte iyileştirilecek alan |
Not: Yüzdeler ve kıyaslamalar resmi MiniMax açıklamalarından ve bağımsız haber raporlarından alınmıştır
Teknik Yenilikler
- Hibrit Dikkat Yığını: Yıldırım Dikkati Verimlilik ve modelleme gücünü dengelemek için periyodik Softmax Attention (kuadratik ama daha anlamlı) ile iç içe geçmiş katmanlar (doğrusal maliyet).
- Seyrek MoE Yönlendirmesi: 32 uzman modülü; her token toplam parametrelerin yalnızca yaklaşık %10'unu etkinleştirir, böylece kapasiteyi korurken çıkarım maliyetini azaltır.
- CISPO Güçlendirmeli Öğrenme:Öğrenme sinyalindeki nadir ancak önemli tokenleri koruyan, RL kararlılığını ve hızını artıran yeni bir “Kırpılmış IS-ağırlık Politikası Optimizasyonu” algoritması.
MiniMax‑M1'in açık ağırlık sürümü, herkes için ultra uzun bağlamlı, yüksek verimli çıkarımların kilidini açarak araştırma ile konuşlandırılabilir büyük ölçekli yapay zeka arasındaki boşluğu kapatıyor.
Başlamak
CometAPI, ChatGPT ailesi dahil yüzlerce AI modelini tutarlı bir uç nokta altında toplayan birleşik bir REST arayüzü sağlar; yerleşik API anahtarı yönetimi, kullanım kotaları ve faturalama panoları ile. Birden fazla satıcı URL'sini ve kimlik bilgilerini bir arada yürütmek yerine.
Başlamak için, modellerin yeteneklerini keşfedin Oyun Alanı ve danışın API kılavuzu Ayrıntılı talimatlar için. Erişimden önce, lütfen CometAPI'ye giriş yaptığınızdan ve API anahtarını edindiğinizden emin olun.
En son MiniMax‑M1 API entegrasyonu yakında CometAPI'de görünecek, bu yüzden bizi izlemeye devam edin! MiniMax‑M1 Model yüklemesini tamamlarken, diğer modellerimizi keşfedin Modeller sayfası veya bunları deneyin yapay zeka oyun alanı. MiniMax'ın CometAPI'deki en son Modeli Minimax ABAB7-Önizleme API'si ve MiniMax Video-01 API ,bakınız:
