Gemini 2.5 Flash, çıktı kalitesinden ödün vermeden hızlı yanıtlar sunmak üzere tasarlanmıştır. Metin, görseller, ses ve videoyu içeren çok kipli girdileri destekleyerek çeşitli uygulamalara uygun hale getirir. Model, Google AI Studio ve Vertex AI gibi platformlar üzerinden erişilebilir olup, geliştiricilere çeşitli sistemlere sorunsuz entegrasyon için gerekli araçları sağlar.
Temel Bilgiler (Özellikler)
Gemini 2.5 Flash, Gemini 2.5 ailesi içinde onu öne çıkaran birkaç belirgin özellik sunar:
- Hibrit Akıl Yürütme: Geliştiriciler, modelin çıktıyı üretmeden önce içsel akıl yürütmeye kaç token ayıracağını ince ayarlarla kontrol etmek için thinking_budget parametresini belirleyebilir.
- Pareto Sınırı: Optimal maliyet-performans noktasına konumlanan Flash, 2.5 modelleri arasında en iyi fiyat-zeka oranını sunar.
- Çok Kipli Destek: Metin, görseller, video ve sesi yerel olarak işler; daha zengin sohbet ve analitik yetenekler sağlar.
- 1 Milyon-Token Bağlamı: Eşsiz bağlam uzunluğu, tek bir istekte derin analiz ve uzun belge anlama olanağı tanır.
Model Sürümleri
Gemini 2.5 Flash aşağıdaki önemli sürümlerden geçmiştir:
- gemini-2.5-flash-lite-preview-09-2025: Gelişmiş araç kullanılabilirliği: Karmaşık, çok adımlı görevlerde performans iyileştirildi; SWE-Bench Verified puanlarında %5 artış (48.9%’dan 54%’e). Verimlilik artırıldı: Akıl yürütme etkinleştirildiğinde daha az token ile daha yüksek kaliteli çıktı elde edilerek gecikme ve maliyetler düşürülür.
- Preview 04-17: “Düşünme” yeteneğine sahip erken erişim sürümü, gemini-2.5-flash-preview-04-17 üzerinden kullanılabilir.
- Stable General Availability (GA): 17 Haziran 2025 itibarıyla, kararlı uç nokta gemini-2.5-flash önizlemenin yerini alarak üretim düzeyinde güvenilirlik sağlar; 20 Mayıs önizlemesine kıyasla API değişikliği yoktur.
- Preview’un Kullanımdan Kaldırılması: Önizleme uç noktalarının 15 Temmuz 2025’te kapatılması planlanmıştır; kullanıcıların bu tarihten önce GA uç noktasına geçiş yapması gerekir.
Temmuz 2025 itibarıyla, Gemini 2.5 Flash artık herkese açık ve kararlı durumdadır (gemini-2.5-flash-preview-05-20 sürümünden değişiklik yoktur). gemini-2.5-flash-preview-04-17 kullanıyorsanız, mevcut önizleme fiyatlandırması model uç noktası 15 Temmuz 2025’te kapatılana kadar devam edecektir. Genel kullanıma açık model olan "gemini-2.5-flash" sürümüne geçiş yapabilirsiniz.
Daha hızlı, daha ucuz, daha akıllı:
- Tasarım hedefleri: düşük gecikme + yüksek verim + düşük maliyet;
- Akıl yürütme, çok kipli işleme ve uzun metin görevlerinde genel hızlanma;
- Token kullanımı %20–30 azaltılarak akıl yürütme maliyetleri önemli ölçüde düşürülür.
Teknik Özellikler
Girdi Bağlam Penceresi: 1 milyon tokene kadar; kapsamlı bağlam koruması sağlar.
Çıktı Tokenları: Yanıt başına 8.192 tokene kadar üretim kapasitesi.
Desteklenen Kipler: Metin, görseller, ses ve video.
Entegrasyon Platformları: Google AI Studio ve Vertex AI üzerinden kullanılabilir.
Fiyatlandırma: Rekabetçi, token tabanlı fiyatlandırma modeli; maliyet etkin dağıtımı kolaylaştırır.
Teknik Ayrıntılar
Kaputun altında, Gemini 2.5 Flash; web, kod, görsel ve video verilerinin bir karışımı üzerinde eğitilmiş, transformer tabanlı bir büyük dil modelidir. Öne çıkan teknik özellikler:
Çok Kipli Eğitim: Birden çok kip ile hizalı olacak şekilde eğitilmiştir; Flash, metni görseller, video veya ses ile sorunsuz biçimde harmanlayabilir; bu da video özetleme veya ses altyazılama gibi görevler için faydalıdır.
Dinamik Düşünme Süreci: Modelin nihai çıktıyı üretmeden önce plan yaptığı ve karmaşık istemleri parçalara ayırdığı dahili bir akıl yürütme döngüsü uygular.
Yapılandırılabilir Düşünme Bütçeleri: thinking_budget, 0 (akıl yürütme yok) ile 24.576 token arasında ayarlanabilir; gecikme ile yanıt kalitesi arasında denge kurulmasını sağlar.
Araç Entegrasyonu: Google Search ile Temellendirme, Kod Yürütme, URL Bağlamı ve Fonksiyon Çağrısı desteklenir; doğal dil istemlerinden doğrudan gerçek dünya eylemlerini etkinleştirir.
Kıyaslama Performansı
Zorlu değerlendirmelerde, Gemini 2.5 Flash sektör lideri performans sergiler:
- LMArena Hard Prompts: Zorlu Hard Prompts kıyaslamasında yalnızca 2.5 Pro’nun ardından ikinci olmuştur; güçlü çok adımlı akıl yürütme yeteneklerini gösterir.
- 0.809 MMLU Skoru: 0.809 MMLU doğruluğuyla ortalama model performansını aşar; geniş alan bilgisi ve akıl yürütme yetkinliğini yansıtır.
- Gecikme ve Verim: 271.4 tokens/sec çözümleme hızı ve 0.29 s Time-to-First-Token ile gecikmeye duyarlı iş yükleri için idealdir.
- Fiyat-Performans Lideri: $0.26/1 M tokens seviyesinde fiyatla, temel kıyaslarda rakipleriyle eşleşirken veya onları aşarken daha uygun maliyet sunar.
Bu sonuçlar, Gemini 2.5 Flash’ın akıl yürütme, bilimsel anlayış, matematiksel problem çözme, kodlama, görsel yorumlama ve çok dilli yeteneklerdeki rekabet avantajını göstermektedir:
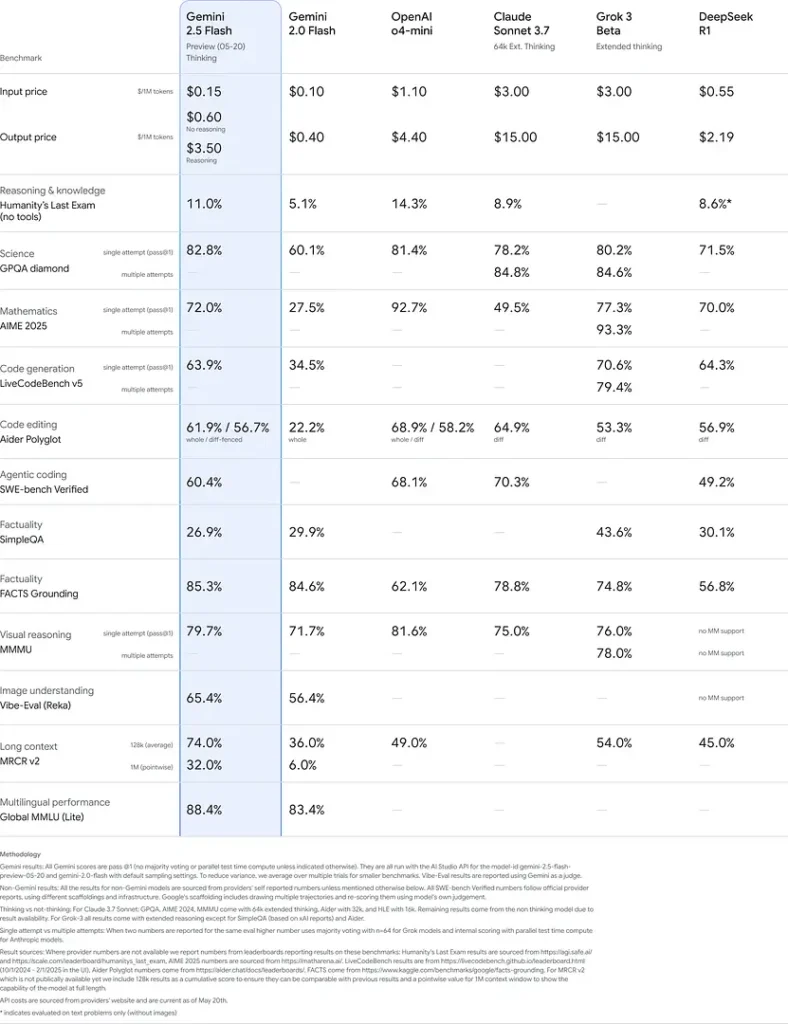
Sınırlamalar
Güçlü olmasına karşın, Gemini 2.5 Flash’ın bazı sınırlamaları vardır:
- Güvenlik Riskleri: Model “öğüt verici” bir ton sergileyebilir ve özellikle uç durum sorgularında ikna edici görünen ancak hatalı veya önyargılı çıktılar (halüsinasyonlar) üretebilir. Sıkı insan denetimi gerekli olmaya devam eder.
- Oran Sınırları: API kullanımı oran sınırlarıyla (varsayılan katmanlarda 10 RPM, 250.000 TPM, 250 RPD) kısıtlanır; bu durum toplu işleme veya yüksek hacimli uygulamaları etkileyebilir.
- Asgari Zekâ Seviyesi: Bir flash modeli için olağanüstü yetenekli olsa da, gelişmiş kodlama veya çoklu ajan koordinasyonu gibi en zorlu ajansal görevlerde 2.5 Pro kadar isabetli değildir.
- Maliyet Dengeleri: En iyi fiyat-performansı sunmasına rağmen, düşünme modunun yoğun kullanımı toplam token tüketimini artırarak derin akıl yürütme gerektiren istemlerde maliyetleri yükseltir.