

اس کے اکتوبر کے اپ ڈیٹس میں، OpenAI نے اس کے ارد گرد رپورٹ کیا 0.15% ہفتہ وار فعال صارفین ایسی گفتگو کریں جن میں ممکنہ خودکشی کی منصوبہ بندی یا ارادے کے واضح اشارے ہوتے ہیں — ایک ایسا حصہ جسے، جب ChatGPT کے بڑے صارف کی بنیاد پر سکیل کیا جاتا ہے، اس کے مساوی ہوتا ہے۔ ہر ہفتے ایک ملین سے زیادہ لوگ سروس کے ساتھ خودکشی سے متعلق موضوعات پر گفتگو کرتے ہوئے، اس نے ایک بھرے ہوئے سوال پر توجہ مرکوز کر دی ہے: کیا زبان کے بڑے ماڈلز بامعنی اور محفوظ طریقے سے جواب دے سکتے ہیں جب لوگ ذہنی صحت کے شدید خدشات جیسے سائیکوسس، انماد، خودکشی کے ارادے اور گہرے جذباتی انحصار کو چیٹ میں لاتے ہیں؟
لہذا، OpenAI کی اکتوبر میں GPT-5 کے اپ ڈیٹس - کے طور پر پیداوار میں شامل ہوئے۔ gpt-5-oct-3 اپ ڈیٹ — بڑے لینگوئج ماڈلز (LLMs) کو محفوظ اور زیادہ کارآمد بنانے کے لیے کمپنی کے سب سے واضح، ناپے گئے دباؤ کی نمائندگی کرتا ہے جب صارفین ذہنی صحت سے متعلق خدشات لاتے ہیں۔ تبدیلیاں ایک جادوئی حل نہیں ہیں۔ وہ تکنیکی، عمل، اور تشخیصی چالوں کا ایک مجموعہ ہیں جن کا مقصد نقصان دہ یا غیر مددگار نتائج، سطحی پیشہ ورانہ وسائل کو کم کرنا، اور صارفین کو طبی دیکھ بھال کے متبادل کے طور پر ماڈل پر انحصار کرنے کی حوصلہ شکنی کرنا ہے۔ لیکن عملی طور پر نظام کتنا بہتر ہے، بالکل کیا بدلا ہے، اور باقی خطرات کیا ہیں؟
OpenAI نے gpt-5 میں کیا اپ ڈیٹ کیا اور اس سے فرق کیوں پڑتا ہے؟
OpenAI نے ChatGPT کے ڈیفالٹ GPT-5 ماڈل میں ایک اپ ڈیٹ تعینات کیا (عام طور پر مواصلات میں اس کا حوالہ دیا جاتا ہے gpt-5-oct-3) کا مقصد خاص طور پر ماڈل کے طرز عمل کو مضبوط کرنا ہے۔ حساس بات چیت - وہ جن میں سائیکوسس یا انماد کی علامات، خودکشی کی سوچ یا منصوبہ بندی، یا AI پر اس قسم کا جذباتی انحصار شامل ہے جو حقیقی دنیا کے تعلقات کو بے گھر کر سکتا ہے۔
تبدیلیوں کو 170 سے زیادہ دماغی صحت کے ماہرین کے ساتھ مشاورت اور نئے داخلی درجہ بندیوں اور ٹھوس "مطلوبہ طرز عمل" کے ارد گرد تیار کردہ خودکار تشخیص کے ذریعے مطلع کیا گیا، نفسیات کے ماہرین کی طرف سے بہتر بنانے کے بعد، GPT-5 ماڈل:
- ھدف بنائے گئے ذہنی صحت کے چیلنج سیٹوں پر، نئے GPT-5 ماڈل نے اسکور کیا۔ ~ 92٪ کمپنی کے مطلوبہ رویے کی درجہ بندی کے مطابق (مشکل ٹیسٹ سیٹس پر پہلے کے ورژن کے لیے بہت کم فیصد)۔
- خود کو نقصان پہنچانے اور خودکشی کے منظرناموں کے لیے، خودکار تشخیص تک پہنچ گئی۔ ~ 91٪ سے تعمیل 77٪ بیان کردہ مخصوص بینچ مارک میں پچھلے GPT-5 ویرینٹ پر۔ OpenAI بھی رپورٹ کرتا ہے ~ 65٪ ردعمل کی شرحوں میں کمی جو پروڈکشن ٹریفک میں کئی ذہنی صحت کے ڈومینز میں "مکمل طور پر تعمیل نہیں کرتے"۔
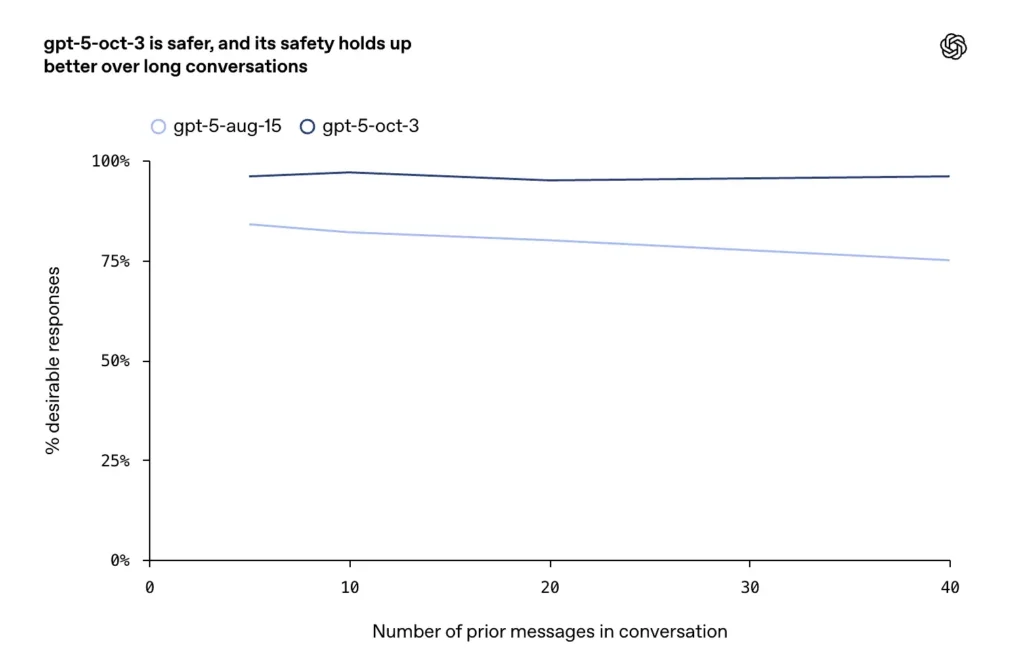
- طویل، مخالفانہ یا طویل بات چیت (چیٹ ماڈلز کے لیے ایک معروف ناکامی موڈ) پر بہتری کی اطلاع دی گئی، جہاں کمپنی کا کہنا ہے کہ اکتوبر کے اپ ڈیٹس طویل مکالمے کے موڑ میں اعلی مستقل مزاجی اور حفاظت کو برقرار رکھتے ہیں۔
اس سے فرق کیوں پڑتا ہے
OpenAI نے کہا کہ - ChatGPT کے موجودہ پیمانے کو دیکھتے ہوئے - حساس بات چیت کے بہت چھوٹے فیصد بھی لوگوں کی بہت بڑی تعداد کے مطابق ہیں۔ کمپنی نے اطلاع دی کہ، ایک عام ہفتے میں:
- کے بارے میں 0.07٪ فعال صارفین میں سے ممکنہ علامات نفسیات یا انماد سے مطابقت رکھتی ہیں۔ اور
- کے بارے میں 0.15٪ فعال صارفین کی ایسی گفتگو ہوتی ہے جس میں ممکنہ خودکشی کی منصوبہ بندی یا ارادے کے واضح اشارے شامل ہوتے ہیں۔ اور
- تقریبا 0.15٪ فعال صارفین میں سے ChatGPT سے جذباتی وابستگی کی "بلند سطح" دکھاتے ہیں۔
ان فیصدوں کو ٹھوس بنانے کے لیے: اوپن اے آئی کے سی ای او نے کہا کہ چیٹ جی پی ٹی کے پاس ~ ہے۔800 ملین ہفتہ وار فعال صارفین. ضرب لگانے سے صارف کی مطلق تعداد ملتی ہے:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
زمرے شور اور اوور لیپنگ ہیں (ایک ہی گفتگو ایک سے زیادہ زمروں میں ظاہر ہو سکتی ہے) اور یہ کہ یہ ہیں اندازوں کے مطابق طبی تشخیص کے بجائے اندرونی پتہ لگانے والے ٹیکونومیز سے ماخوذ۔
اوپن اے آئی نے ان تبدیلیوں کو کیسے نافذ کیا - پانچ قدمی بہتری کا طریقہ کار؟
OpenAI ایک کثیر جہتی، ماہر سے باخبر عمل کی وضاحت کرتا ہے۔ ذیل میں ایک کشید، تولیدی ہے۔ پانچ قدمی بہتری کا طریقہ کار جو کہ کمپنی کے انکشافات اور ماڈل سیفٹی انجینئرنگ میں عام مشق کا نقشہ بناتا ہے۔
پانچ قدمی بہتری کا طریقہ کار
- ماہر کی رہنمائی کردہ درجہ بندی اور لیبلنگ۔ نفسیاتی ماہرین، ماہر نفسیات اور بنیادی نگہداشت کے معالجین کو بلائیں تاکہ ان رویوں اور زبان کی وضاحت کی جائے جو نفسیات/انماد، خود کو نقصان پہنچانے کے ارادے، یا غیر صحت بخش جذباتی انحصار کی نشاندہی کرتے ہیں۔ لیبل والے ڈیٹا سیٹس اور فیصلہ سازی کے اصول بنائیں۔
- ٹارگٹڈ ڈیٹا اکٹھا کرنا اور تیار کردہ اشارے۔ نمائندہ گفتگو کے ٹکڑوں، ایج کیس کی مثالیں، اور مخالفانہ معلومات جمع کریں۔ کلینشین کی نگرانی کے ساتھ تیار کردہ کنٹرول رول پلے ٹرانسکرپٹس کے ساتھ اضافہ۔
- حفاظتی مقاصد کے ساتھ ماڈل ٹیوننگ/فائن ٹیوننگ۔ کیوریٹڈ ڈیٹاسیٹ پر بنیادی ماڈل کو نقصان کی شرائط کے ساتھ تربیت دیں یا ٹھیک کریں جو فریب کو تقویت دینے پر جرمانہ عائد کرتے ہیں، محفوظ جوابی ٹیمپلیٹس فراہم کرتے ہیں، اور بحران کے وسائل تک روٹنگ کو فروغ دیتے ہیں۔
- کلاسیفائر + گارڈریل پرت (رن ٹائم سیفٹی)۔ ایک تیز درجہ بندی یا نگرانی کی پرت تعینات کریں جو حقیقی وقت میں زیادہ خطرے والے موڑ کا پتہ لگاتی ہے اور یا تو ماڈل کے ڈی کوڈنگ پیرامیٹرز کو تبدیل کرتی ہے، ایک خصوصی جواب دہندہ پر سوئچ کرتی ہے، یا انسانی جائزے کی پائپ لائنوں کو بڑھاتی ہے۔ (بات چیت کے بڑھنے پر ٹوٹنے والے رویے سے بچنے کے لیے یہ بہت ضروری ہے۔)
- انسانی ماہر کی تشخیص اور مسلسل انشانکن۔ طبی ماہرین کو طبی تشخیص کے روبرکس کا استعمال کرتے ہوئے بلائنڈ ریٹ ماڈل کے جوابات حاصل کریں۔ ناپسندیدہ ردعمل کی شرح کی پیمائش؛ درجہ بندی، تربیتی ڈیٹا اور سسٹم پرامپٹس پر اعادہ کریں۔ پروڈکشن ٹیلی میٹری کو برقرار رکھیں اور بینچ مارکس کو باقاعدگی سے دوبارہ چلائیں۔
ذیل میں ایک کمپیکٹ سیڈوکوڈ/تکنیکی خاکہ ہے جو رن ٹائم کے بہاؤ کو پکڑتا ہے جو زیادہ تر حفاظتی ٹیمیں نافذ کرتی ہیں (یہ ہے مثالی اور غیر ملکیتی):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
پروڈکشن پائپ لائن عام طور پر قلیل مدتی درجہ بندی (تیز)، سست لیکن اعلیٰ معیار کے جواب دہندگان (خصوصی اشارے / ٹیونڈ چیک پوائنٹس) اور جھنڈے والے کیسز کے لیے انسانی جائزہ لیتی ہے۔ یہ خالصتاً علمی نہیں ہے: معالجین نے جائزہ لیا۔ 1,800 ماڈل کے جوابات اور درجہ بندی کے خلاف ان کی درجہ بندی کی، اور یہ کہ ان جائزوں نے مادی طور پر شکل دی کہ کس طرح پرامپٹس اور فال بیک رویے لکھے گئے۔
OpenAI کے عوام بتاتے ہیں کہ انہوں نے نتائج کا جائزہ لینے کے لیے پانچوں مراحل اور کلینشین کی درجہ بندیوں کے تغیرات کا استعمال کیا:
- ماہرین نے 1,800 سے زیادہ ماڈل کے جوابات کا جائزہ لیا۔
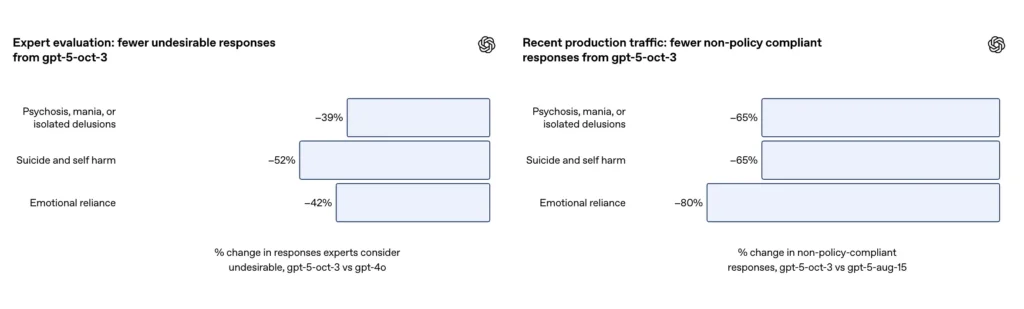
- GPT-5 نے تمام زمروں میں "غیر اطمینان بخش جوابات" کو 39-52% تک کم کیا۔
- انٹر ریٹر کی اعتباریت 71–77% تک تھی، جو موضوعی اختلافات کے باوجود مجموعی اتفاق رائے کی اعلیٰ ڈگری کی نشاندہی کرتی ہے۔
GPT-5 اب سائیکوسس یا انماد کا کیا جواب دیتا ہے؟
OpenAI نے ماڈل کو کیا کرنا سکھایا (اور نہ کرنا)
پیمائش کریں: ماڈل کی پہچان اور شدید علامات جیسے فریب اور انماد کے ردعمل کو بہتر بنائیں۔ ایسی گفتگو کے لیے جو ممکنہ گمراہ کن عقائد، فریب کاری، یا انماد کا اشارہ دیتے ہیں، OpenAI نے ماڈل کی خصوصیت کے کچھ حصوں کو دوبارہ لکھا اور زیر نگرانی تربیتی مثالیں فراہم کیں تاکہ GPT-5 بے بنیاد عقائد کی تصدیق کیے بغیر جواب دے یا ان کو بڑھائے۔ ماڈل کی حوصلہ افزائی کی جاتی ہے کہ وہ ہمدرد بنیں، غلط فہمیوں کی توثیق کرنے سے بچیں، اور جب ضروری ہو تو صارف کو عملی حفاظتی اقدامات اور پیشہ ورانہ مدد کی طرف نرمی سے ری فریم یا ری ڈائریکٹ کریں۔
تشخیص سے کیا پتہ چلتا ہے۔
OpenAI رپورٹ کرتا ہے کہ سائیکوسس/مینیا کے بارے میں چیلنجنگ بات چیت کے ایک ٹیسٹ سیٹ پر، نئے GPT-5 نے پہلے کی بنیادی خطوط کے مقابلے میں غیر مطلوبہ ردعمل کو کافی حد تک کم کر دیا ہے اور یہ کہ خودکار تشخیص ان کی درجہ بندی کی اعلی تعمیل پر اپ ڈیٹ شدہ ماڈل کو اسکور کرتی ہے۔
| میٹرک | GPT-4o | GPT-5 | بہتری |
|---|---|---|---|
| غیر تعمیل جواب کی شرح | بیس لائن | ↓ 65٪ | نمایاں بہتری |
| طبی ماہرین کی تشخیص | - | منفی ردعمل میں 39 فیصد کمی | - |
| خودکار تشخیص تعمیل کی شرح | 27٪ | 92٪ | ↑65 فیصد پوائنٹس |
| صارف کی شمولیت کی شرح | ~0.07% ہفتہ وار فعال صارفین | انتہائی کم لیکن واضح طور پر نگرانی کی گئی۔ | - |
نوٹ:
- نامناسب جوابات میں 65 فیصد کمی واقع ہوئی ہے۔
- صرف 0.07% صارفین اور 0.01% پیغامات میں ایسا مواد تھا۔
- ماہرین کے جائزوں میں، GPT-5 نے GPT-4o کے مقابلے میں 39% کم نامناسب ردعمل پیدا کیا۔
- خودکار جائزوں میں، GPT-5 نے 92% تعمیل کی شرح حاصل کی (اس کے پیشرو کے لیے 27% کے مقابلے)۔
GPT-5 کس طرح خودکشی کے خیال اور خود کو نقصان پہنچاتا ہے؟
سپورٹ اور ہدایات فراہم کرنے سے انکار کے لیے مضبوط روٹنگ
OpenAI خود کو نقصان پہنچانے اور خودکشی کے معاملات کے لیے وسیع اور واضح تربیت کی وضاحت کرتا ہے: ماڈل کو ارادے یا منصوبہ بندی کے براہ راست اور بالواسطہ اشاروں کو پہچاننے، ہمدردانہ اور کم کرنے والی زبان فراہم کرنے، موجودہ بحران کے وسائل (ہاٹ لائنز، مقامی ہنگامی ہدایات)، اور خود کو نقصان پہنچانے کے لیے ہدایات فراہم کرنے سے انکار کرنے کی تربیت دی جاتی ہے۔ اکتوبر کے اپ ڈیٹس طویل گفتگو میں زیادہ پائیدار رویے پر زور دیتے ہیں، جہاں پہلے کے ماڈل بعض اوقات غیر محفوظ یا متضاد جوابات کی طرف بڑھ جاتے تھے۔
پیمائش شدہ نتائج
چیلنجنگ خود کو نقصان پہنچانے اور خودکشی کی بات چیت کے کیوریٹڈ تشخیص کے سیٹ پر، OpenAI رپورٹ کرتا ہے کہ اپ ڈیٹ شدہ GPT-5 حاصل کیا گیا 91% تعمیل OpenAI کے مطلوبہ طرز عمل کے ساتھ مقابلے میں 77٪ پہلے کے GPT-5 ماڈل کے لیے۔ کمپنی کا یہ بھی کہنا ہے کہ مضامین کے ماہرین نے غیر مطلوبہ جوابات کو تقریباً کم کرنے کے لیے اپ ڈیٹ شدہ ماڈل کا فیصلہ کیا۔ 52% بمقابلہ GPT-4o ایک ہی مسئلہ سیٹ پر. مزید برآں، اوپن اے آئی ایک اندازے کا دعویٰ کرتا ہے۔ 65 فیصد کمی جوابات کی پیداواری ٹریفک میں جو نئے حفاظتی اقدامات کو نافذ کرنے کے بعد خود کو نقصان پہنچانے والے حالات کے لیے اپنی درجہ بندی کی "مکمل تعمیل نہیں کرتے"۔
| میٹرک | GPT-4o | GPT-5 | بہتری |
|---|---|---|---|
| نامناسب ردعمل کی شرح | بیس لائن | ↓ 65٪ | نمایاں بہتری |
| طبی ماہرین کی درجہ بندی | - | نامناسب جوابات میں 52 فیصد کمی آئی | - |
| خودکار تشخیص تعمیل کی شرح | 77٪ | 91٪ | ↑14 فیصد پوائنٹس |
| صارف کی شمولیت کی شرح | 0.15% ہفتہ وار (لاکھوں صارفین) | بہت کم لیکن سماجی لحاظ سے اہم | - |
نوٹ:
- نامناسب جوابات میں 65 فیصد کمی واقع ہوئی ہے۔
- تقریباً 0.15% صارفین اور 0.05% پیغامات میں خودکشی کے ممکنہ خطرات شامل تھے۔
- ماہرین کی درجہ بندیوں سے پتہ چلتا ہے کہ GPT-5 نے GPT-4o کے مقابلے میں نامناسب ردعمل میں 52 فیصد کمی کی ہے۔
- خودکار تشخیص میں تعمیل کی شرح بڑھ کر 91% ہوگئی (پچھلی نسل کے لیے 77% کے مقابلے)؛
- توسیع شدہ بات چیت میں، GPT-5 نے 95 فیصد سے زیادہ استحکام برقرار رکھا۔
"جذباتی انحصار" کیا ہے اور اسے کیسے حل کیا گیا؟
منسلکات بنانے والے صارفین کا چیلنج
OpenAI جذباتی انحصار کو ایسے نمونوں کے طور پر بیان کرتا ہے جہاں صارف حقیقی دنیا کے تعلقات، ذمہ داریوں، یا فلاح و بہبود کو نقصان پہنچانے کے لیے AI پر ممکنہ طور پر غیر صحت بخش انحصار ظاہر کرتا ہے۔ یہ فوری طور پر جسمانی حفاظت کی ناکامی نہیں ہے جس طرح سے خود کو نقصان پہنچانے کی ہدایات ہیں، لیکن یہ ایک طرز عمل کی حفاظت کا مسئلہ ہے جو وقت کے ساتھ ساتھ کسی شخص کی سماجی حمایت اور لچک کو ختم کر سکتا ہے۔ کمپنی نے اپنے ماڈل کی تفصیلات کے کام میں جذباتی انحصار کو ایک واضح زمرہ بنایا اور ماڈل کو حقیقی دنیا کے رابطے کی حوصلہ افزائی کرنے، لوگوں تک رسائی کو معمول پر لانے، اور ایسی زبان سے اجتناب کرنے کی تعلیم دی جو اٹیچمنٹ کی خصوصیت کو تقویت دیتی ہے۔
ان بات چیت میں، ماڈل کو تربیت دی گئی تھی:
- صارفین کو دوستوں، خاندان، یا معالج سے رابطہ کرنے کی ترغیب دیں؛
- AI کے ساتھ منسلک کو مضبوط بنانے سے بچیں؛
- وہموں یا غلط عقائد کا نرم اور عقلی انداز میں جواب دیں۔
نتائج کی اطلاع دی گئی۔
OpenAI کے ضمیمہ کے مطابق، اپ ڈیٹ نے ایک پیدا کیا۔ ~80% کمی ماڈل ردعمل کی شرح میں جو پروڈکشن ٹریفک میں جذباتی انحصار کی درجہ بندی کے تحت مکمل طور پر تعمیل نہیں کرتے ہیں۔ کیوریٹڈ تشخیصی گفتگو پر، خودکار تشخیص نے اپ ڈیٹ شدہ ماڈل کو اسکور کیا۔ 97% تعمیل پچھلے GPT-5 کے 50% کے مقابلے، جذباتی انحصار کے منظرناموں کے لیے مطلوبہ رویے کے ساتھ۔ نمبر مخصوص درجہ بندی اور ٹیسٹ سیٹ پر بڑی بہتری کی تجویز کرتے ہیں۔ تاہم، جنگلی میں جذباتی انحصار کی پیمائش فطری طور پر شور اور ثقافتی اور سیاق و سباق کے فرق کے لیے حساس ہے۔
| میٹرک | GPT-4o | GPT-5 | بہتری |
|---|---|---|---|
| غیر تعمیل جواب کی شرح | 50٪ | 97% موافق | ↓80% نامناسب جوابات |
| ماہر تشخیص | نامناسب جوابات میں 42 فیصد کمی | - | - |
| صارف کی شمولیت کی شرح | 0.15% صارفین/ہفتہ، 0.03% پیغامات | نایاب لیکن موجود ہے۔ | - |
| ماڈل سلوک | حقیقی دنیا کے تعلقات کی حوصلہ افزائی کرتا ہے؛ "نقلی سماجی رومانس" کو مسترد کرتا ہے | - | - |
نوٹ:
- نامناسب جوابات میں 80 فیصد کمی واقع ہوئی ہے۔
- تقریباً 0.15% صارفین/0.03% پیغامات نے AI پر ممکنہ جذباتی انحصار کی علامات ظاہر کیں۔
- ماہرین کے جائزے سے پتہ چلتا ہے کہ GPT-5 نے GPT-4o کے مقابلے میں 42 فیصد نامناسب ردعمل کو کم کیا ہے۔
- خودکار تشخیص کی تعمیل 50% سے 97% تک نمایاں طور پر بہتر ہوئی۔
حدود اور بقایا خطرات کیا ہیں؟
جھوٹے منفی اور جھوٹے مثبت
- جھوٹے منفی: ماڈل ٹھیک ٹھیک یا کوڈفائیڈ سگنلز کی نشاندہی کرنے میں ناکام ہو سکتا ہے کہ صارف شدید خطرے میں ہے — خاص طور پر جب لوگ ترچھے یا کوڈ میں بات چیت کرتے ہیں۔
- جھوٹی مثبت: سسٹم ایسے معاملات میں بحرانی پیغامات کو بڑھا سکتا ہے یا فراہم کر سکتا ہے جن کی ضرورت نہیں ہے، جو صارف کے اعتماد کو ختم کر سکتا ہے یا غیر ضروری الارم پیدا کر سکتا ہے۔ غلطی کی دونوں قسمیں اہمیت رکھتی ہیں کیونکہ وہ صارف کے رویے اور نگہداشت کے تصورات کی تشکیل کرتی ہیں۔ OpenAI تسلیم کرتا ہے کہ پتہ لگانا نامکمل ہے۔
آٹومیشن پر حد سے زیادہ انحصار
یہاں تک کہ بہترین ماڈل بھی کچھ صارفین کو مستقل انسانی مدد حاصل کرنے کے بجائے فوری، ہمیشہ دستیاب AI ردعمل پر انحصار کرنے کی ترغیب دے سکتا ہے۔ OpenAI واضح طور پر اس خطرے کی وجہ سے ایک حفاظتی زمرے کے طور پر جذباتی انحصار کو جھنڈا دیتا ہے۔ کمپنی کی اپ ڈیٹس صارفین کو انسانی رابطے کی طرف راغب کرنے کی کوشش کرتی ہیں، لیکن سماجی حرکیات کو صرف پیغام کے اشارے سے تبدیل کرنا مشکل ہے۔
سیاق و سباق اور ثقافتی فرق
حفاظتی جملے جو ایک ثقافت یا زبان میں مناسب نظر آتے ہیں دوسری زبان میں اہمیت سے محروم ہو سکتے ہیں۔ مکمل لوکلائزیشن اور ثقافتی طور پر آگاہی کی تشخیص ضروری ہے۔ OpenAI کے شائع شدہ نتائج ابھی تک زبان یا علاقے کے لحاظ سے مکمل خرابی فراہم نہیں کرتے ہیں۔
قانونی اور اخلاقی نمائش
جب نایاب ناکامیوں کے سنگین نتائج ہوتے ہیں، تو کمپنیوں کو قانونی اور شہرت کے خطرے کا سامنا کرنا پڑتا ہے (جیسا کہ میڈیا کوریج اور مقدمہ نے روشنی ڈالی ہے)۔ مسئلہ کے سائز اور نقصانات کو کم کرنے کے لیے اس کی کوششوں کے بارے میں OpenAI کی شفافیت ایک اہم قدم ہے، لیکن یہ ریگولیٹری اور قانونی جانچ کو بھی مدعو کرتا ہے۔
تو - کیا GPT-5 اب ذہنی صحت کے مسائل کو سنبھال سکتا ہے؟
مختصر جواب: یہ بہت سے تنگ، قابل پیمائش کاموں میں نمایاں طور پر بہتر ہے۔، اور OpenAI کے شائع شدہ میٹرکس خود کو نقصان پہنچانے، سائیکوسس/انماد، اور جذباتی-انحصار ٹیسٹ سویٹس میں ناپسندیدہ ردعمل میں معنی خیز کمی کو ظاہر کرتے ہیں۔ وہ حقیقی بہتری ہیں، جو ماہرانہ ان پٹ، واضح درجہ بندی، اور جارحانہ تشخیص اور نگرانی کے ذریعے فعال ہیں۔ کمپنی کی عوامی تعداد - اعلی تعمیل کی شرح اور کیوریٹڈ سیٹوں پر غیر تعمیل جوابات میں تیزی سے کمی - ابھی تک اس بات کا سب سے مضبوط ثبوت ہیں کہ جان بوجھ کر، کثیر الشعبہ انجینئرنگ اور کلینیکل تعاون مادی طور پر ماڈل کے رویے کو تبدیل کر سکتا ہے۔
تازہ ترین GPT-5 API تک کیسے رسائی حاصل کی جائے؟
CometAPI ایک متحد API پلیٹ فارم ہے جو سرکردہ فراہم کنندگان سے 500 سے زیادہ AI ماڈلز کو اکٹھا کرتا ہے — جیسے OpenAI کی GPT سیریز، Google کی Gemini، Anthropic's Claude، Midjourney، Suno، اور مزید — ایک واحد، ڈویلپر کے موافق انٹرفیس میں۔ مسلسل تصدیق، درخواست کی فارمیٹنگ، اور رسپانس ہینڈلنگ کی پیشکش کرکے، CometAPI ڈرامائی طور پر آپ کی ایپلی کیشنز میں AI صلاحیتوں کے انضمام کو آسان بناتا ہے۔ چاہے آپ چیٹ بوٹس، امیج جنریٹرز، میوزک کمپوزر، یا ڈیٹا سے چلنے والی اینالیٹکس پائپ لائنز بنا رہے ہوں، CometAPI آپ کو تیزی سے اعادہ کرنے، لاگت کو کنٹرول کرنے، اور وینڈر-ایگنوسٹک رہنے دیتا ہے—یہ سب کچھ AI ماحولیاتی نظام میں تازہ ترین کامیابیوں کو حاصل کرنے کے دوران۔
ڈویلپرز رسائی حاصل کر سکتے ہیں۔ GPT-5 API CometAPI کے ذریعے، جدید ترین ماڈل ورژن ہمیشہ سرکاری ویب سائٹ کے ساتھ اپ ڈیٹ کیا جاتا ہے۔ شروع کرنے کے لیے، میں ماڈل کی صلاحیتوں کو دریافت کریں۔ کھیل کے میدان اور مشورہ کریں API گائیڈ تفصیلی ہدایات کے لیے۔ رسائی کرنے سے پہلے، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ ان کیا ہے اور API کلید حاصل کر لی ہے۔ CometAPI آپ کو انضمام میں مدد کے لیے سرکاری قیمت سے کہیں کم قیمت پیش کریں۔
جانے کے لیے تیار ہیں؟→ CometAPI کے لیے آج ہی سائن اپ کریں۔ !
اگر آپ AI پر مزید ٹپس، گائیڈز اور خبریں جاننا چاہتے ہیں تو ہمیں فالو کریں۔ VK, X اور Discord!