

Google اور اس کی ریسرچ بازو DeepMind نے چپکے سے (اور پھر خاصی نمایاں طور پر) Gemini روڈمیپ میں ایک اور بڑا قدم آگے بڑھایا ہے: Gemini 3.1 Pro۔ یہ ریلیز، جو صارف رُو بہ رُو سرفیسز اور CometAPI پر متعارف کرائی گئی ہے، Gemini 3 فیملی کے لیے کارکردگی اور استدلال میں اپ گریڈ کے طور پر پوزیشن کی گئی ہے — طویل شکل کے استدلال میں نمایاں بہتری، ملٹی موڈل سمجھ، اور حقیقی دُنیا کی ایپلیکیشنز کے لیے بہتر اسکیل ایبلٹی کا وعدہ کرتی ہے۔
Google کا نیا ماڈل — Gemini 3.1 Pro کیا ہے؟
Gemini 3.1 Pro، Gemini 3 فیملی میں پہلا اِنکریمنٹل اپ ڈیٹ ہے جسے “سب سے قابل” استدلالی ماڈل کے طور پر رکھا گیا ہے، جو ملٹی اسٹیپ، ملٹی موڈل اور ایجنٹک ٹاسکس کے لیے آپٹمائزڈ ہے۔ یہ ماڈل فروری 2026 کے وسط میں پبلک پری ویو میں جاری کیا گیا (پری ویو 19–20 فروری 2026 کو اعلان ہوا)، اور اسے اُن منظرناموں کے لیے واضح طور پر ہدف بنایا گیا ہے جنہیں مسلسل سلسلہ وار سوچ، ٹول کے استعمال، اور طویل کانٹیکسٹ کی سمجھ درکار ہو — مثال کے طور پر: بڑے پیمانے پر ریسرچ سنتھیسِس، ایسے انجینئرنگ ایجنٹس جو ٹولز اور سسٹمز کو کوآرڈینیٹ کریں، اور ایسے ڈاکیومنٹس کا ملٹی موڈل تجزیہ جو متن، تصاویر، آڈیو اور ویڈیو کو ملاتے ہوں۔
بالائی سطح پر، Gemini 3.1 Pro کو اس کے ڈیویلپرز یوں بیان کرتے ہیں:
- فطری طور پر ملٹی موڈل — متن، تصاویر، آڈیو اور ویڈیو کو قبول کرنے اور اُن پر استدلال کرنے کے قابل۔
- طویل کانٹیکسٹ کے لیے بنایا گیا — بہت بڑے کانٹیکسٹ ونڈوز کی سپورٹ جو مکمل کوڈ بیسز، کثیر دستاویزی ڈوسیئرز، یا طویل ٹرانسکرپٹس کے لیے موزوں ہوں۔
- قابلِ اعتماد استدلال اور ایجنٹک ورک فلو کے لیے آپٹمائزڈ، یعنی یہ منصوبہ بندی، ٹول کالنگ، اور ملٹی اسٹیپ ٹاسکس میں آؤٹ پٹس کی توثیق کے لیے ٹیون کیا گیا ہے۔
یہ اب کیوں اہم ہے: ادارے اور ڈیویلپرز “اچھی گفتگوئی معاونت” سے “اعلی داؤ پر مبنی فیصلہ سازی اور ریسرچ ایجنٹس” کی طرف بڑھ رہے ہیں (قانونی ڈرافٹنگ، R&D سنتھیسِس، ملٹی موڈل ڈاکیومنٹ کی سمجھ)۔ Gemini 3.1 Pro اسی راہ داری کے لیے خاص طور پر ڈیزائن کیا گیا ہے — ہیلوسینیشنز کم کرنے، قابلِ سراغ استدلال پیش کرنے، اور CometAPI کے ساتھ پروٹو ٹائپنگ اور پروڈکشن دونوں کے لیے انضمام کرنے کی خاطر۔
Gemini 3.1 Pro کی تکنیکی جھلکیاں اور فیچرز کیا ہیں؟
فطری ملٹی موڈیلیٹی اور انتہائی بڑے کانٹیکسٹ ونڈوز
Gemini 3.1 Pro نے Gemini سلسلے کی ملٹی موڈیلیٹی پر توجہ کو جاری رکھا ہے۔ ماڈل کارڈ اور پروڈکٹ نوٹس کے مطابق، یہ ماڈل ایک ہی پائپ لائن میں متن، تصاویر، آڈیو اور ویڈیو کو قبول کرتا ہے اور اُن پر استدلال کرتا ہے — ایسی صلاحیت جو اُن ورک فلو کو سادہ بناتی ہے جہاں ڈیٹا کی اقسام ملی جلی ہوں (مثالاً، قانونی بیانات جن میں آڈیو + ٹرانسکرپٹ + سکینز شامل ہوں)۔ خاص طور پر، یہ ماڈل 1,000,000-ٹوکن کانٹیکسٹ ونڈو سپورٹ کرتا ہے اور طویل آؤٹ پٹس پیدا کر سکتا ہے (شائع شدہ نوٹس طویل شکل کے کاموں کے لیے موزوں حدیں بتاتی ہیں)۔ یہ پیمانہ اسے ایسے استعمالات کے لیے موزوں بناتا ہے جیسے کہ مکمل کوڈ ریپوزٹریز، کثیر ابواب والی دستاویزات، یا طویل ٹرانسکرپٹس کا بغیر چنکنگ کے تجزیہ۔
“Dynamic thinking”: بہتر استدلال اور مرحلہ وار منصوبہ بندی
Google کے مطابق 3.1 Pro میں “سوچنے” کی صلاحیت بہتر ہوئی ہے — یعنی اندرونی chain-of-thought ہینڈلنگ بہتر ہوئی ہے اور ٹاسک کی پیچیدگی کے مطابق استدلالی حکمتِ عملیوں کا متحرک انتخاب ہوتا ہے۔ ماڈل کو ضرورت کے وقت واضح ملٹی اسٹیپ پلاننگ میں مشغول ہونے اور اس دوران ٹوکن مؤثریت برقرار رکھنے کے لیے ٹیون کیا گیا ہے۔ عملی طور پر، اس کا مطلب پیچیدہ، مرحلہ وار مسائل میں کم ہیلوسینیشنز اور ملٹی اسٹیپ استدلالی بینچ مارکس پر بہتر حقیقی مطابقت ہے۔
ایجنٹک ورک فلو اور ٹول کا استعمال
3.1 Pro کا ایک بڑا ڈیزائن فوکس ایجنٹک کارکردگی ہے: ٹولز کی ہم آہنگی، ویب گراؤنڈنگ یا سرچ کو کال کرنا، کوڈ اسنیپٹس لکھنا اور چلانا، اور ثانوی پاسز کے ذریعے آؤٹ پٹس کی توثیق کرنا۔ Google نے 3.1 Pro کو ایجنٹ-فرسٹ پروڈکٹس (مثلاً، Antigravity ڈیویلپمنٹ ماحول) میں ضم کیا ہے تاکہ ماڈلز ایسے کام انجام دے سکیں جن میں ایڈیٹر، ٹرمینل اور براؤزر شامل ہوں — اور اس عمل کی تصدیق کے لیے اسکرین شاٹس اور براؤزر ریکارڈنگز جیسے آرٹی فیکٹس ریکارڈ کریں۔ یہ فیچرز “مشورہ دینے” والے ماڈلز اور اُن ماڈلز کے درمیان خلا کم کرنے کا ہدف رکھتے ہیں جو حقیقتاً کثیر ٹول ورک فلوز کو قابلِ اعتماد انداز میں انجام دیتے ہیں۔
خاص سب موڈز (Deep Research، Deep Think)
Google، 3.1 Pro کو “Deep Research” کے ساتھ جوڑتا ہے اور ایک آنے والے “Deep Think” ویریئنٹ کا حوالہ دیتا ہے۔ یہ سب موڈز بالترتیب — زیادہ ریکال والی ریسرچ ٹاسکس اور زیادہ سے زیادہ استدلالی گہرائی (اضافی کمپیوٹ لاگت اور لیٹنسی کے ساتھ) — کو ہدف بناتے ہیں۔ ان کا مقصد اُن اینالسٹس، محققین، اور ڈیویلپرز کی خدمت کرنا ہے جنہیں تیز ترین اور سستے جواب کے بجائے زیادہ غور و خوض کے ساتھ اعلیٰ معیار کے آؤٹ پٹس درکار ہوں۔
بینچ مارکس پر Gemini 3.1 Pro کی کارکردگی کیسی ہے؟
Gemini 3.1 Pro نے پچھلے Gemini 3 Pro نتائج پر مضبوط اضافہ حاصل کیا ہے، اکثر ملٹی اسٹیپ استدلال اور ملٹی موڈل پیمائشوں کے وسیع سیٹ پر سبقت لیتے ہوئے — مگر مخصوص تخصصی کاموں پر کچھ مقابل حریفوں سے پیچھے بھی رہتا ہے (خصوصاً بعض ایڈوانسڈ کوڈنگ یا ماہر سطح کے سوال ناموں پر)۔ خلاصہ: تخصصی بینچ مارکس میں کچھ تنگ دائروں میں حریفوں کی برتری کے ساتھ مجموعی طور پر وسیع بہتریاں۔
بنیادی بینچ مارک دعوے اور نمایاں اعداد
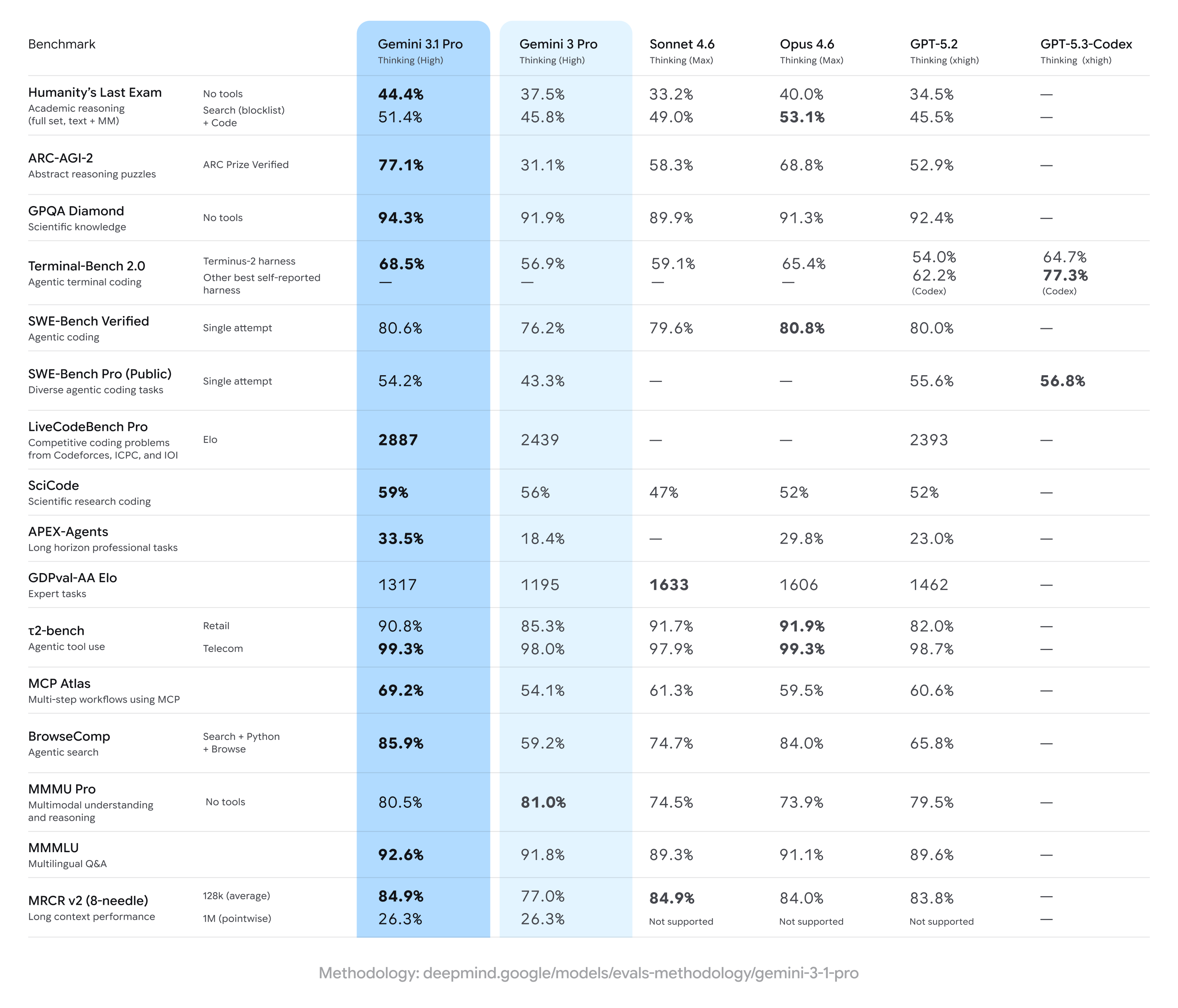
- ARC-AGI-2 (انتزاعی استدلال / ملٹی اسٹیپ سائنس پہیلیاں): Gemini 3.1 Pro کے لیے رپورٹ شدہ اضافے پچھلے Gemini 3 Pro ورژنز کے مقابلے میں نمایاں بہتری دکھاتے ہیں؛ ایک کمیونٹی ٹیسٹ سوئٹ نے مختصر، مرتکز ٹیسٹس میں سابقہ Gemini 3 Pro بیس لائن پر ARC-AGI-2 میں دو گنا سے زیادہ بہتری ظاہر کی۔ مخصوص رپورٹ شدہ اسکورز (کمیونٹی ٹیسٹس) Gemini 3.1 Pro کو بعض ARC طرز کے مجموعوں پر تقریباً 77.1% پر رکھتے ہیں (عوامی رپورٹنگ)۔
- GPQA Diamond اور گریجویٹ سطح کے سائنس بینچ مارکس: ڈیٹا رپورٹس ظاہر کرتی ہیں کہ Gemini 3.1 Pro نے GPQA Diamond (گریجویٹ سطح کا سائنس QA بینچ مارک) پر ریکارڈ بلندی حاصل کی، پہلے کے Gemini ماڈلز کو پیچھے چھوڑتے ہوئے اور آزادانہ رنز میں فیملی کے لیے ایک نیا سنگِ میل قائم کیا۔ یہ اضافہ ماڈل کی chain-of-thought اور مرحلہ وار استدلال کی ٹیوننگ کی عکاسی کرتا ہے۔
- “Humanity’s Last Exam” ٹولز فعال ہونے کے ساتھ (کثیر ٹول، گراؤنڈڈ استدلال): Anthropic کے Claude Opus 4.6 کے ساتھ ہیڈ ٹو ہیڈ موازنوں میں، Claude نے اس پیچیدہ ٹول فعال بینچ مارک پر 53.1% حاصل کیا جبکہ Gemini 3.1 Pro نے اسی ٹیسٹ راؤنڈ میں 51.4% حاصل کیے — یہ ظاہر کرتا ہے کہ اس مخصوص کثیر ٹول امتحان میں Gemini بہت قریب ہے مگر سبقت نہیں لے سکا۔
- Coding & terminal بینچ مارکس (Terminal-Bench 2.0، SWE-Bench Pro): خصوصیتی کوڈنگ بینچ مارکس میں فرق زیادہ نمایاں ہوا۔ مخصوص ہارنیسز کے ساتھ Terminal-Bench 2.0 پر، GPT-5.3-Codex ویریئنٹس نے تقریباً 77.3% اسکور کیا جبکہ Gemini 3.1 Pro نے انہی موازنوں میں تقریباً 68.5% حاصل کیے۔ SWE-Bench Pro کے عوامی نتائج میں، Gemini 3.1 Pro نے تقریباً 54.2% اسکور کیا جبکہ GPT-5.3-Codex نے 56.8% — فرق کم ہے، مگر ان رنز میں OpenAI کی Codex فیملی نے تخصصی پروگرامنگ ٹاسکس پر برتری برقرار رکھی۔
- GDPval-AA Elo (ماہر ٹاسکس ریٹنگ): ماہر ٹاسکس کے لیے Elo طرز کے مجموعی رینکنگ میں، Claude Sonnet/Opus ویریئنٹس نے زیادہ اسکور کیے (مثلاً تقریباً 1606–1633 پوائنٹس) جبکہ ایک عوامی رپورٹ نے اسی ڈیٹاسیٹ میں Gemini 3.1 Pro کو تقریباً 1317 پوائنٹس پر رکھا — جو کچھ تنگ ماہر ڈومینز میں بہتری کی گنجائش کی نشاندہی کرتا ہے۔
حقیقی دنیا کے آزمائشی نتائج اور ہینڈز آن ٹیسٹس
ہینڈز آن اینالسٹ تحریروں سے ظاہر ہوتا ہے کہ Gemini 3.1 Pro خاص طور پر ان میں بہترین ہے:
- طویل کانٹیکسٹ سمری اور کثیر دستاویزی سنتھیسِس، جہاں 1M ٹوکن ونڈو چنکنگ سے پیدا ہونے والے مسائل سے بچاتی ہے۔
- ملٹی موڈل فہم کے کام جہاں تصویر + متن گراؤنڈنگ حقیقی معلومات کے اخذ میں بہتری لاتی ہے۔
- ایجنٹک آٹومیشن (مثلاً، سادہ ٹول چینز کی ہم آہنگی) — Antigravity ٹرائلز سے ظاہر ہوتا ہے کہ ملٹی ایجنٹ ٹاسک آرکسٹریشن ممکن ہے، ایسے آرٹی فیکٹس کے ساتھ جو ہر قدم ریکارڈ کرتے ہیں۔
جہاں Gemini 3.1 Pro ابھی پیچھے ہے (اعداد کیا بتاتے ہیں)
کوئی بھی ماڈل ہر جگہ بہترین نہیں۔ آزادانہ تبصروں اور کمیونٹی ٹیسٹنگ نے مخصوص خلاجات اجاگر کیے:
- سافٹ ویئر انجینئرنگ اور کوڈ-مینٹیننس بینچ مارکس (SWE-Bench Pro وغیرہ) — Gemini 3.1 Pro کچھ حریف (Anthropic کا Claude Opus 4.6) سے اُن ٹاسکس میں پیچھے ہے جو عملی سافٹ ویئر انجینئرنگ صلاحیتوں کو آزماتے ہیں: بڑے پیمانے پر ریفیکٹرز، الجھے ہوئے کوڈ بیسز میں بگ ٹرائیج، اور خودکار پروگرام مرمت کی کچھ اقسام۔ یعنی روزمرہ انجینئرنگ مینٹیننس کے لیے، کچھ ٹیسٹ بیڈز میں تخصصی ماڈلز اب بھی برتری رکھتے ہیں۔
- لیٹنسی حساس مائیکرو ٹاسکس — چونکہ Gemini 3.1 Pro کو گہرائی کے لیے ٹیون کیا گیا ہے، اس لیے ایسے کام جو انتہائی کم لیٹنسی اور بلند تھروپٹ چاہتے ہیں (مثلاً، ہلکے وزن کے گفتگوئی UI کے لیے مائیکرو اِنفرنس) ممکن ہے کہ Gemini فیملی کے “Flash” یا دیگر آپٹمائزڈ ویریئنٹس کے ذریعے بہتر سر انجام پائیں۔
Gemini 3.1 Pro کی قیمت کیا ہے؟
آپ Gemini 3.1 Pro تک دو طریقوں سے رسائی حاصل کر سکتے ہیں — کنزیومر سبسکرپشن یا ڈیویلپر API — اور ہر ایک کی قیمت مختلف ہے۔
- Consumer (Gemini app / Google AI Pro): Gemini 3.1 Pro تک رسائی Google AI Pro سبسکرپشن میں شامل ہے، جو U.S. میں $19.99 / month ہے (Google کم قیمت “AI Plus” اور زیادہ قیمت “AI Ultra” ٹئیر بھی پیش کرتا ہے)۔ Google۔
- Developer / API (ٹوکن پر مبنی): اگر آپ Gemini/AI ڈیویلپر API کے ذریعے Gemini ماڈلز کال کرتے ہیں، تو قیمت ٹوکنز کے لحاظ سے میٹر کی جاتی ہے۔ Gemini 3.x Pro پری ویو کے لیے شائع شدہ ڈیویلپر قیمتیں تقریباً یہ ہیں: معیاری (≤200k پرامپٹس) بینڈ کے لیے $2.00 فی 1M اِن پٹ ٹوکنز اور $12.00 فی 1M آؤٹ پٹ ٹوکنز — جبکہ بہت بڑے کانٹیکسٹ کے لیے بلند ٹئیرز (مثلاً $4/$18 فی 1M) موجود ہیں۔ (تفصیل اور بیچ پرائسنگ کے لیے Gemini API پرائسنگ ٹیبل دیکھیں۔)
- اگر آپ CometAPI کے ذریعے Gemini 3.1 Pro استعمال کرتے ہیں:
| Comet قیمت (USD / M Tokens) | آفیشل قیمت (USD / M Tokens) |
|---|---|
| اِن پٹ:$1.6/M; آؤٹ پٹ:$9.6/M | اِن پٹ:$2/M; آؤٹ پٹ:$12/M |
کنزیومر سبسکرپشن پرائسنگ (Gemini app)
Gemini ایپ کے اندر اینڈ یوزر پلانز کے لیے، Google ٹئیرز اس طرح بناتا ہے کہ ماڈل ویریئنٹس اور اضافی فیچرز تک رسائی مرحلہ وار ہو: Google AI Pro اور Google AI Ultra۔ قیمتیں مارکیٹ اور کرنسی کے لحاظ سے مختلف ہوتی ہیں؛ شائع شدہ مثالیں Google AI Pro کو $19.99/month (پروموشنل ٹرائلز دستیاب) پر دکھاتی ہیں اور پروڈکٹ صفحے پر کرنسی کے لحاظ سے ٹئیرڈ قیمتیں دی گئی ہیں (ٹرائل آفرز اور قلیل مدتی کم ریٹس سمیت)۔ AI Ultra بلند رسائی (مثلاً، نئی جدتوں تک ترجیحی رسائی، ویڈیو جنریشن کے لیے زیادہ کریڈٹس) زیادہ ماہانہ قیمت کے بدلے بَندل کرتا ہے۔ یہ کنزیومر پلان قیمتیں دیگر اعلیٰ درجے کی کنزیومر AI سبسکرپشنز کے مقابلے میں مسابقتی ہیں اور افراد یا چھوٹی ٹیموں کو API انضمام کے بغیر 3.1 Pro فیچرز تک رسائی دینے کے لیے پوزیشن کی گئی ہیں۔
عملی پرومپٹ اور استعمال کے نکات (میں کیا کروں گا)
عالمی سطح پر قابلِ اعتماد اور قابلِ تکرار نتائج کے لیے یہ استعمال کریں:
- واضح اسٹیپ پلانر
پرومپٹ پیٹرن:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.یہ 3.1 Pro کی مضبوط مرحلہ وار ایکزیکیوشن سے فائدہ اٹھاتا ہے اور آپ کو چیک پوائنٹس دیتا ہے۔ - سٹرکچرڈ آؤٹ پٹ سکیما کے ساتھ
JSON مانگیں جس کے ساتھ ایک سکیما ہو اورstrict: true۔ چونکہ 3.1 Pro طویل، سکیما-مطابق آؤٹ پٹس زیادہ قابلِ اعتماد طریقے سے پیدا کرتا ہے، آپ کو بڑے واحد ریسپانس ملیں گے جنہیں آپ ڈاؤن اسٹریم پارس کر سکتے ہیں۔ - ٹول-چیک سینڈوچ
جب بیرونی ٹولز (APIs، کوڈ رنرز) کال کریں، ماڈل سے پیدا کروائیں: پلان → عین ٹول کال (کاپی/پیست فرینڈلی) → ویلیڈیشن اسٹیپس۔ پھر جاری رکھنے سے پہلے ویلیڈیشن اسٹیپس کو ماڈل سے باہر تصدیق کریں۔ - سنگل-اسٹیپ اعتماد سے خبردار
چاہے ماڈل کتنا ہی بہترین نظر آنے والا کوڈ یا کمانڈز لکھے، آزادانہ ویلیڈیشن (ٹیسٹس، لنٹرز، سینڈ باکسڈ ایکزیکیوشن) لازماً چلائیں — خصوصاً ایجنٹک/خودکار کارروائیوں کے لیے۔
Gemini 3.1 Pro کے ساتھ ہینڈز آن
ٹرائل کیس 1: طویل کانٹیکسٹ ریسرچ اسسٹنٹ (NotebookLM / Deep Research)
ہدف: ماڈل کی صلاحیت کا جائزہ لینا کہ وہ 10–50 طویل دستاویزات (مثلاً رپورٹس، وائٹ پیپرز) کو حوالہ جات اور ایکشن آئٹمز کے ساتھ کثیر صفحات پر مشتمل ایگزیکٹو سمری میں کیسے سنتھیسائز کرتا ہے۔
سیٹ اپ: مجموعی طور پر 200k–800k ٹوکنز پر مشتمل کارپس فیڈ کریں؛ ماڈل سے کہیں کہ وہ 2–4 صفحات کی سمری واضح حوالہ جات اور “اگلے اقدامات” کی سفارشات کے ساتھ تیار کرے۔ ایک قابلِ تکرار پرومپٹ ٹیمپلیٹ استعمال کریں اور وقت، ٹوکن استعمال (لاگت)، اور حقیقی درستگی کو ناپیں۔
نتائج: پچھلے ماڈلز کے مقابلے میں کم چنکنگ مسائل کے ساتھ تیز تر اینڈ ٹو اینڈ سمریزیشن، سمری میں حوالہ جاتی وفاداری زیادہ، اور بڑے پیمانے پر بہتر ربط — البتہ قابلِ ذکر ٹوکن استعمال کی قیمت پر (لہٰذا بجٹ پلان کریں)۔ بینچ مارکس اور ہینڈز آن ٹیسٹس دکھاتے ہیں کہ 1M ٹوکن ونڈو کی وجہ سے Gemini 3.1 Pro کثیر دستاویزی سنتھیسِس میں ممتاز ہے۔
ٹرائل کیس 2: ایجنٹک کوڈنگ اسسٹنٹ (Antigravity + GitHub Copilot)
ہدف: کثیر مرحلہ ڈیویلپر ٹاسکس (مثلاً، متعدد فائلوں میں ایک فیچر نافذ کرنا، ٹیسٹس چلانا، ناکام ٹیسٹس درست کرنا) کے لیے وقتِ تکمیل میں کمی ناپنا۔
سیٹ اپ: Antigravity یا GitHub Copilot کو پری ویو میں Gemini 3.1 Pro کے ساتھ منتخب کریں۔ قابلِ تکرار ٹاسکس متعین کریں (ایشو تخلیق → نفاذ → ٹیسٹس چلانا)، اقدامات اور ایجنٹ آرٹی فیکٹس لاگ کریں، اور محض انسانی بیس لائن کے ساتھ موازنہ کریں۔
نتائج: ملٹی اسٹیپ ٹاسکس کی آرکسٹریشن بہتر (آرٹی فیکٹ ریکارڈنگ، پیچ امیدواروں کی خودکار تجویز)، پچھلے Gemini 3 Pro سے ملٹی فائل استدلال بہتر، اور معمول کے فیچر ورک پر قابلِ پیمائش وقت کی بچت۔ تخصصی، نچلی سطح کے سسٹم ڈیبگنگ ٹاسکس اب بھی کوڈ-فرسٹ تخصصی ماڈلز کے حق میں ہو سکتے ہیں (کمیونٹی نتائج کچھ ٹرمینل بینچ مارکس پر بعض GPT-Codex ویریئنٹس کے مقابلے میں فرق دکھاتے ہیں)۔
ٹرائل کیس 3: ملٹی موڈل قانونی/طبی دستاویز جائزہ
ہدف: ماڈل کے ذریعے مخلوط کارپس (سکین شدہ PDFs، تصاویر، آڈیو ٹرانسکرپٹس) کو ہضم کرکے کلیدی حقائق اخذ کرنا، اور رسک میٹرکس اور ترجیحی اقدامات تیار کرنا۔
سیٹ اپ: سکین شدہ تصاویر اور OCR متن کے ساتھ ڈیٹاسیٹ فراہم کریں، ساتھ میں معاون آڈیو۔ نامیاتی اکائی اخذ میں درستگی، فالس پازیٹو ریٹ، اور ماڈل کی ماخذ آرٹی فیکٹس کے حوالے دینے کی صلاحیت ناپیں۔
نتائج: طریقہ کار کے لحاظ سے مضبوط مربوط ملٹی موڈل استدلال اور زیادہ قابلِ سراغ آؤٹ پٹس (دعویٰ کی پشت پناہی کرنے والی تصویر/صفحہ/آڈیو ٹائم اسٹیمپ کی نشان دہی کی صلاحیت)۔ طویل کانٹیکسٹ ونڈو دستی چنکنگ اور کراس ریفرنسنگ کی ضرورت کم کرتی ہے۔ تاہم، ریگولیٹڈ ڈومینز میں، آؤٹ پٹس کو ڈومین ماہرین سے ویلیڈیٹ کرائیں اور گراؤنڈنگ/توثیقی پائپ لائن استعمال کریں۔
ابتدائی تاثرات (کیا مختلف محسوس ہوا)
- زیادہ گہرا مرحلہ وار استدلال۔ وہ کام جو پہلے متعدد بار آگے پیچھے کرنے سے مکمل ہوتے تھے — مثلاً، کثیر دستاویزی سنتھیسِس، ملٹی اسٹیپ ریاضی/منطق — اب کم پاسز میں مکمل ہوتے ہیں اور زیادہ واضح سلسلہ وار استدلالی انداز کے آؤٹ پٹس کے ساتھ (بغیر داخلی ہدایتی متن ظاہر کیے)۔ یہی Google نے بطور سرخی اُجاگر کیا۔
- طویل، اعلیٰ معیار کے سٹرکچرڈ آؤٹ پٹس۔ JSON اور طویل شکل کی آٹومیشنز زیادہ مستقل مزاج اور اکثر بہت زیادہ طویل ہوتی ہیں (کچھ صارفین نے 3.0 سے کہیں بڑے آؤٹ پٹس رپورٹ کیے)۔ یہ اُن جنریٹر جابز کے لیے عمدہ ہے جہاں آپ ایک بڑا، واحد پے لوڈ چاہتے ہیں۔ بڑے آؤٹ پٹس اور اسٹریمِنگ کے ہینڈلنگ کی توقع رکھیں۔
- ٹوکنز/کانٹیکسٹ ہینڈلنگ میں زیادہ مؤثریت۔ ٹوکن مؤثریت میں بہتری اور ٹول-استعمال والے منظرناموں میں زیادہ “گراؤنڈڈ، حقیقت پسندانہ” برتاؤ۔ یہ مختصر حقیقی استفسارات میں کم ہیلوسینیشنز سے جھلکتا ہے۔
حتمی تجزیہ: کیا Gemini 3.1 Pro کو ابھی اپنانا فائدہ مند ہے؟
Gemini 3.1 Pro، Gemini فیملی میں ایک معنی خیز قدمِ ترقی کی نمائندگی کرتا ہے، جس میں استدلال، کوڈنگ اور ایجنٹک بینچ مارکس پر قابلِ مشاہدہ بہتریاں ہیں — جن کی پشت پناہی Google کے شائع شدہ ماڈل کارڈ اور آزاد ٹریکర్స్ کرتے ہیں جو منتخب لیڈر بورڈز پر بڑے جست دکھاتے ہیں۔ اُن ٹیموں کے لیے جنہیں اعلیٰ درجے کا استدلال، ایجنٹک ٹول کوآرڈینیشن، یا طویل کانٹیکسٹ ملٹی موڈل صلاحیتیں درکار ہیں، 3.1 Pro پرکشش امیدوار ہے۔
ڈیویلپرز ابھی Gemini 3.1 Pro کو CometAPI کے ذریعے ایکسس کر سکتے ہیں۔ آغاز کے لیے، Playground میں ماڈل کی صلاحیتیں دریافت کریں اور تفصیلی ہدایات کے لیے API guide دیکھیں۔ رسائی سے پہلے، براہِ کرم یقینی بنائیں کہ آپ CometAPI میں لاگ اِن ہیں اور API key حاصل کر چکے ہیں۔ CometAPI انضمام میں مدد کے لیے آفیشل قیمت کے مقابلے میں کہیں کم قیمت پیش کرتا ہے۔
Ready to Go?→ آج ہی Gemini 3.1 Pro کے لیے سائن اپ کریں!
اگر آپ AI پر مزید ٹِپس، گائیڈز اور خبروں سے باخبر رہنا چاہتے ہیں تو ہمیں VK، X اور Discord پر فالو کریں!