

3 مارچ 2026 کو، Google نے Gemini 3.1 Flash-Lite متعارف کرایا، جو Gemini 3 فیملی کا نیا ترین رکن ہے۔ اسے خاص طور پر ڈویلپر اور انٹرپرائز ورک لوڈز کے لیے ایک ہائی تھروپُٹ، کم لیٹنسی، کم لاگت انجن کے طور پر ڈیزائن کیا گیا ہے۔ Google، Flash-Lite کو Gemini 3 لائن میں “سب سے تیز اور سب سے زیادہ لاگت مؤثر” ماڈل کے طور پر پیش کرتا ہے: یہ ایک ہلکا پھلکا ویریئنٹ ہے جس کا مقصد اسٹریمنگ تعاملات، بڑے پیمانے پر بیک گراؤنڈ پروسیسنگ، اور ہائی فریکوئنسی پروڈکشن ٹاسکس (مثلاً ترجمہ، استخراج، UI جنریشن، اور بڑی مقدار کی درجہ بندی) کو اپنے Pro متبادلات کی نسبت کہیں کم قیمت پر فراہم کرنا ہے۔
ذیل میں ہم بتاتے ہیں کہ Flash-Lite کیا ہے۔
Gemini 3.1 Flash-Lite کیا ہے
Gemini 3.1 Flash-Lite، Google کی Gemini 3 فیملی کا ایک رکن ہے جو جان بوجھ کر اعلیٰ ترین استدلال کی گہرائی کے کچھ حصے کو رفتار اور لاگت کی افادیت کے لیے تبدیل کرتا ہے۔ یہ Gemini سلسلے میں نیٹو ملٹی موڈل ہے (متن، تصاویر اور دیگر موڈیلٹیز کو بطور ان پٹ قبول کرنے کے قابل)، لیکن اسے خاص طور پر زیادہ سے زیادہ ٹوکنز فی سیکنڈ تھروپُٹ اور فی ٹوکن بلنگ میں خاطر خواہ کمی فراہم کرنے کے لیے ٹیون اور ڈپلائے کیا گیا ہے—ایسی ورک لوڈز کے لیے جو زیادہ سے زیادہ ادراکی گہرائی کے بجائے تیز اور بار بار انفرنس کی متقاضی ہوں۔ بتایا گیا ہے کہ یہ ماڈل 3.1 Pro آرکیٹیکچر سے ماخوذ ہے مگر تھروپُٹ، لیٹنسی اور لاگت کے لیے آپٹمائز کیا گیا ہے۔
کلیدی ڈیزائن سمجھوتے
"Lite" کا لاحقہ ماڈل کی انجینئرنگ ترجیحات کی نشان دہی کرتا ہے:
- بھاری استدلال پر تھروپُٹ: Flash-Lite جان بوجھ کر فی ٹوکن کمپیوٹ کو کم کرتا ہے تاکہ Time-to-First-Token (TTFT) اور مسلسل آؤٹ پٹ اسپیڈ تیز ہو۔ یہ اُن پائپ لائنز کے لیے موزوں ہے جہاں ہر درخواست کو تیزی سے اور بڑے پیمانے پر سرو کرنا ہو (مثلاً سیفٹی فلٹرز، ریئل ٹائم اسسٹنٹس، ہائی وولیوم جنریشن)۔
- زیادہ مقدار کے لیے لاگت کی افادیت: فی ٹوکن کمپیوٹ کم کرنے سے ماڈل کو فی ملین ٹوکن کم قیمت پر پیش کیا جا سکتا ہے، جو بڑے پیمانے کی ایپلیکیشنز (مثلاً ماہانہ لاکھوں سے اربوں ٹوکنز) میں حاشیائی لاگت کم کرتا ہے۔ Google کی پری ویو پرائسنگ Pro ٹائر کے مقابلے میں نمایاں فرق دکھاتی ہے۔
- عملی کاموں کے لیے معیار کی ٹیوننگ: ابتدائی اسکورنگ خلاصوں کے مطابق، Flash-Lite معیاری کلاسیفیکیشن، کثیر لسانی اور کئی ملٹی موڈل کاموں پر مضبوط نتائج برقرار رکھتا ہے، لیکن جہاں گہرائی اہم ہو—انتہائی پیچیدہ ملٹی اسٹیپ ریزننگ یا کوڈ جنریشن—ان بینچ مارکس پر Pro کو پیچھے چھوڑنے کے لیے پوزیشن نہیں کیا گیا۔
یہ ورک لوڈز قابلِ اعتماد آؤٹ پٹ اور ہائی تھروپُٹ کی متقاضی ہوتی ہیں، مگر انہیں ہمیشہ فلیگ شپ ماڈلز کی پیچیدہ ملٹی اسٹیپ ریزننگ صلاحیت درکار نہیں ہوتی۔
Gemini 3.1 Flash-Lite کی اہم خصوصیات
1. کم تاخیر اور پہلے ٹوکن تک تیز وقت
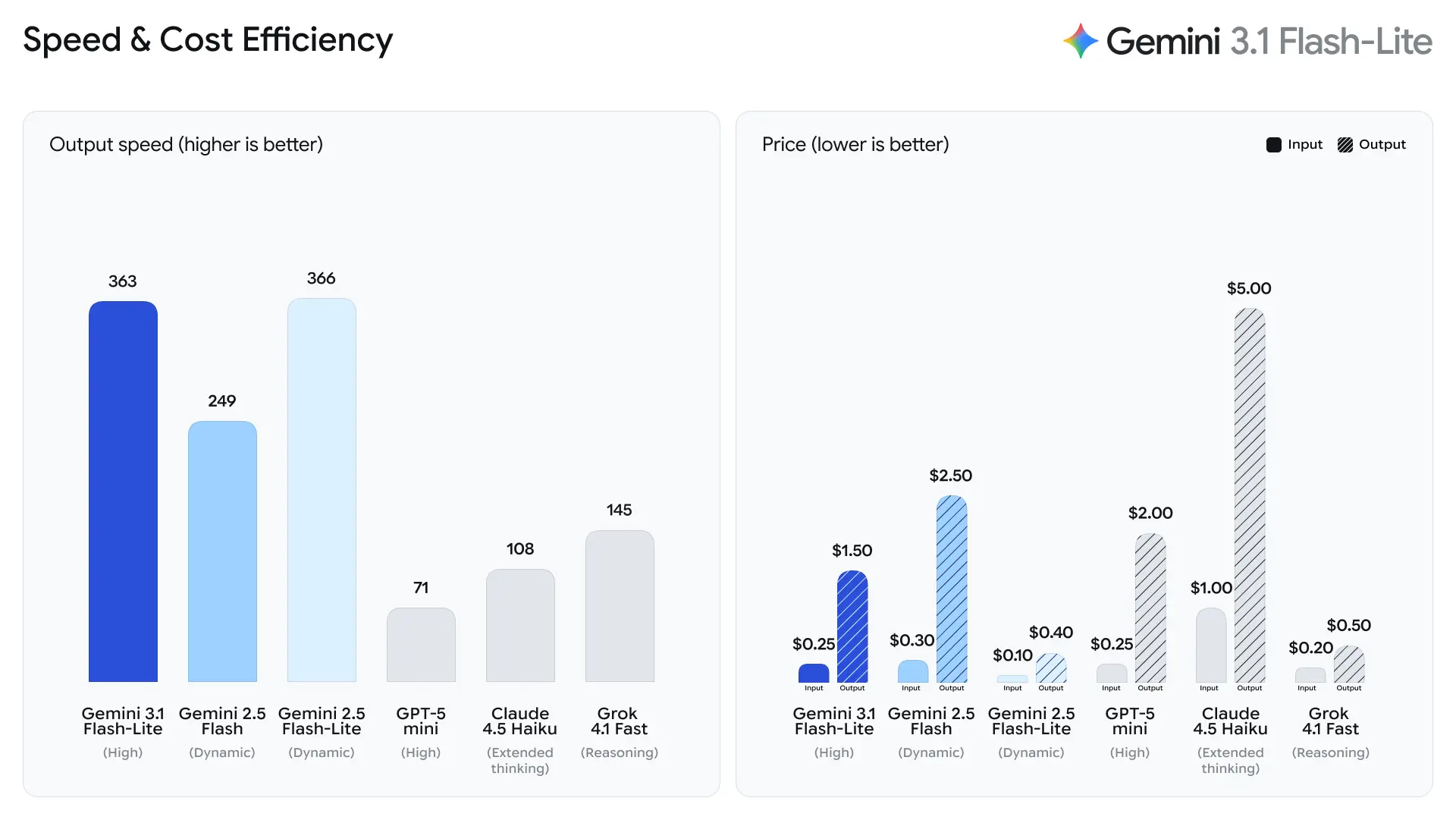
Google نے Flash-Lite کے لیے بنیادی میٹرک کے طور پر time-to-first-answer token پر زور دیا ہے۔ کمپنی کے مطابق، Gemini 2.5 Flash کے مقابلے میں ~2.5× تیز time-to-first-token اور آؤٹ پٹ جنریشن میں 45% زیادہ رفتار—ایسے بہتریاں جو براہِ راست اختتامی صارف کے محسوس کردہ ریسپانس اور بیک اینڈ سسٹمز کے تھروپُٹ اخراجات پر اثر انداز ہوتی ہیں۔ یہ فوائد Flash-Lite کو انٹرایکٹو فیچرز (مثلاً ایپس میں ایمبیڈڈ چیٹ بوٹس) اور ہائی-QPS پائپ لائنز کے لیے موزوں بناتے ہیں جہاں مائیکرو سیکنڈز بھی معنی رکھتے ہیں۔
یہ بہتری درج ذیل ریئل ٹائم ایپلیکیشنز کو نمایاں طور پر بہتر بناتی ہے:
- conversational AI
- AI-powered search assistants
- interactive chatbots
- live translation services
کم لیٹنسی انتظار کے وقت کو کم کر کے اور زیادہ رواں تعامل کو ممکن بنا کر صارف کے تجربے کو بہتر بناتی ہے۔
2. اخراجات کے لحاظ سے مؤثر ٹوکن پرائسنگ
AI انفرنس کے اخراجات اکثر فی ٹوکن حساب کیے جاتے ہیں، جس سے بڑے پیمانے کی ڈپلائمنٹ کے لیے قیمت ایک اہم عامل بن جاتی ہے۔
Gemini 3.1 Flash-Lite ایک نہایت مسابقتی پرائسنگ اسٹرکچر متعارف کراتا ہے:
| Token Type | Price |
|---|---|
| Input tokens | $0.25 per 1M tokens |
| Output tokens | $1.50 per 1M tokens |
یہ سابقہ Flash ماڈلز کے مقابلے میں کمی کی نمائندگی کرتا ہے، جس سے یہ ماڈل اُن اداروں کے لیے پرکشش بنتا ہے جو بڑے ورک لوڈز چلاتے ہیں۔
موازنہ کے لیے:
| Model | Input Price | Output Price |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
یہ پرائسنگ حکمتِ عملی ڈویلپرز کو یہ اجازت دیتی ہے کہ وہ بڑے پیمانے پر AI چلائیں بغیر آپریشنل اخراجات میں ڈرامائی اضافہ کیے۔
اگر آپ مزید بہتر قیمت کی تلاش میں ہیں تو Gemini Flash-Lite CometAPI پر 20% ڈسکاؤنٹ پیش کرتا ہے۔
3. “سوچ کی سطحیں” (قابلِ کنٹرول انفرنس گہرائی)
Gemini 3.1 Flash-Lite میں “thinking levels” کی صلاحیت شامل ہے—ایک ڈویلپر کنفیگر ایبل نوب جو ماڈل کو معمولی کاموں کے لیے تیز، سطحی پروسیسنگ اور مشکل کاموں کے لیے گہری ریزننگ کو ترجیح دینے کی ہدایت دیتا ہے۔ عملی طور پر یہ اس لیے اہم ہے کہ یہ ہر درخواست کے لحاظ سے لاگت/لیٹنسی کے متحرک سمجھوتے ممکن بناتا ہے، بغیر ماڈلز تبدیل کیے۔
ڈویلپرز ماڈل کی ریزننگ گہرائی کو ٹاسک کی پیچیدگی کے مطابق کنفیگر کر سکتے ہیں۔Thinking levels: چار سطحوں کی حمایت کرتا ہے: Minimal، Low، Medium، اور High۔
یہ متحرک طریقہ کار ایپلیکیشنز کو وسائل کے استعمال کو آپٹمائز کرنے دیتا ہے جبکہ جہاں ضروری ہو معیار برقرار رہتا ہے۔ عملی حکمتِ عملی تقریباً یوں ہے:
- Minimal/Low: اُن کاموں کے لیے موزوں جو ہائی کنکرنسی مگر منطقی طور پر سادہ ہوں، جیسے ترجمہ، کلاسیفیکیشن، اور جذباتی تجزیہ—جہاں زیادہ سے زیادہ رفتار اور کم سے کم لاگت کو ترجیح ہو۔
- Medium: زیادہ تر پروڈکشن کاموں کے لیے موزوں، جہاں معیار اور افادیت کے درمیان توازن درکار ہو۔
- High: اُن کاموں کے لیے موزوں جنہیں گہری ریزننگ درکار ہو، جیسے یوزر انٹرفیس بنانا، سمیولیشنز تیار کرنا، اور پیچیدہ ہدایات پر عمل درآمد۔
4. ہلکے نقشِ قدم کے ساتھ ملٹی موڈل صلاحیت
اگرچہ Flash-Lite کو رفتار اور لاگت کے لیے آپٹمائز کیا گیا ہے، یہ Gemini 3 لائن کی ملٹی موڈل بنیادیں برقرار رکھتا ہے: یہ ضرورت پڑنے پر کلاسیفیکیشن یا ہلکی ملٹی موڈل ریزننگ کے لیے امیج ان پٹس قبول کر سکتا ہے—لیکن ڈویلپرز کو توقع رکھنی چاہیے کہ اس کا معاشی ڈیزائن بہت بڑی امیج-ہیوی ورک فلو کے بجائے مختصر، محدود ملٹی موڈل آپریشنز کو ترجیح دے گا۔ دیگر Gemini ماڈلز کی طرح، Gemini 3.1 Flash-Lite ملٹی موڈل ان پٹس کو سپورٹ کرتا ہے، جس سے ڈویلپرز مختلف اقسام کے ڈیٹا کو پراسیس کر سکتے ہیں۔
سپورٹڈ ان پٹس میں شامل ہیں:
- Text
- Images
- Video
- Audio
- PDFs
متعدد اقسام کی معلومات کا تجزیہ کرنے کی ماڈل کی صلاحیت نئے استعمالات کو ممکن بناتی ہے، جیسے:
- automated document processing
- visual data extraction
- multimedia summarization
اس سے پہلے کے Gemini ماڈلز نے بصری اور علمی بینچ مارکس میں مضبوط ملٹی موڈل ریزننگ صلاحیتیں بھی دکھائی ہیں۔
کارکردگی بینچ مارکس — حقیقی اعداد اور ان کا مطلب
Google کے اعلان اور پروڈکٹ دستاویزات خریداروں کو یہ سمجھنے میں مدد دینے کے لیے کئی بینچ مارک ڈیٹا پوائنٹس پیش کرتے ہیں کہ ایکو سسٹم میں Flash-Lite کہاں فٹ بیٹھتا ہے۔
ڈویلپرز کے لیے رفتار کے میٹرکس
- Gemini 2.5 Flash کے مقابلے میں 2.5× تیز Time to First Answer Token (Google کا بیان کردہ داخلی موازنہ)۔
- Gemini 2.5 Flash کے مقابلے میں 45% تیز آؤٹ پٹ جنریشن۔
یہ انجینئرنگ کارکردگی میٹرکس ہیں، انسانی معیار والے میٹرکس نہیں؛ یہ رن ٹائم مائیکرو آرکیٹیکچر، بیچنگ، اور انفرنس اسٹیک آپٹمائزیشنز میں اُن بہتریوں کی عکاسی کرتے ہیں جو مختصر جوابات کے لیے لیٹنسی کم کرتی ہیں۔ پہلے ٹوکن تک تیز وقت انٹرایکٹو ایپلیکیشنز میں محسوس شدہ وقفہ کم کرتا ہے اور فی سرور مجموعی تھروپُٹ بڑھاتا ہے، جو اسی QPS پر کل کمپیوٹ لاگت کم کر سکتا ہے۔
Tokens-per-second (t/s) اور تھروپُٹ
Artificial Analysis کے ٹیسٹ ڈیٹا کے مطابق، 3.1 Flash-Lite نے 388.8 ٹوکنز فی سیکنڈ کا آؤٹ پٹ اسپیڈ حاصل کیا (اسی قیمت کی حد کے ماڈلز کا میڈین صرف 96.7 ٹوکنز/سیکنڈ ہے)۔ یہ رفتار اپنی کلاس کے ماڈلز میں سرِفہرست ہے۔
تاہم، Artificial Analysis نے ایک مسئلہ بھی اجاگر کیا: 3.1 Flash-Lite کا پہلے ٹوکن کی لیٹنسی (TTFT) 5.18 سیکنڈ ہے، جو اسی قیمت کی حد کے انفرنس ماڈلز کے لیے نسبتاً زیادہ ہے (میڈین 1.82 سیکنڈ ہے)۔ اضافی طور پر، ماڈل نے جانچ کے عمل کے دوران 53 ملین ٹوکنز جنریٹ کیے، جو اوسط 20 ملین کے مقابلے میں نسبتاً زیادہ ہے۔ اس کا مطلب یہ ہے کہ اگر آپ کا سیناریو پہلے ٹوکن کی لیٹنسی کے حوالے سے بہت حساس ہے یا آؤٹ پٹ کی اختصار پر سخت تقاضے ہیں، تو آپ کو سوچ کی سطح اور پرامپٹس کو آپٹمائز کرنے کی ضرورت پڑ سکتی ہے۔
ریزننگ اور معلوماتی درستی کے بینچ مارک اسکورز
Google نے کراس ماڈل موازنہ شامل کیے جن میں Gemini 3.1 Flash-Lite کو مجموعی ریزننگ/فیکچوئل ٹاسکس پر ہم عمروں اور سابقہ Gemini ویریئنٹس کے مقابلے میں مضبوط دکھایا گیا ہے:
- Arena.ai Elo اسکور: Gemini 3.1 Flash-Lite نے مبینہ طور پر Arena لیڈر بورڈ پر 1432 کا Elo حاصل کیا—ایک مرکب ہیڈ-ٹو-ہیڈ رینکنگ جو براہِ راست موازنوں میں نسبتاً مسابقتی کارکردگی دکھاتی ہے۔
- GPQA Diamond: 86.9% (سوال-جواب کی مضبوطی کا پیمانہ)۔
- MMMU Pro: 76.8% (ایک ملٹی موڈل/ملٹی ٹاسک میٹرک جسے کچھ لیبز اندرونی/بیرونی طور پر استعمال کرتی ہیں)۔
- LiveCodeBench (Coding Ability): 72.0%
- CharXiv Reasoning (Graphical Reasoning): 73.2%
- Video-MMMU (Video Comprehension): 84.8%
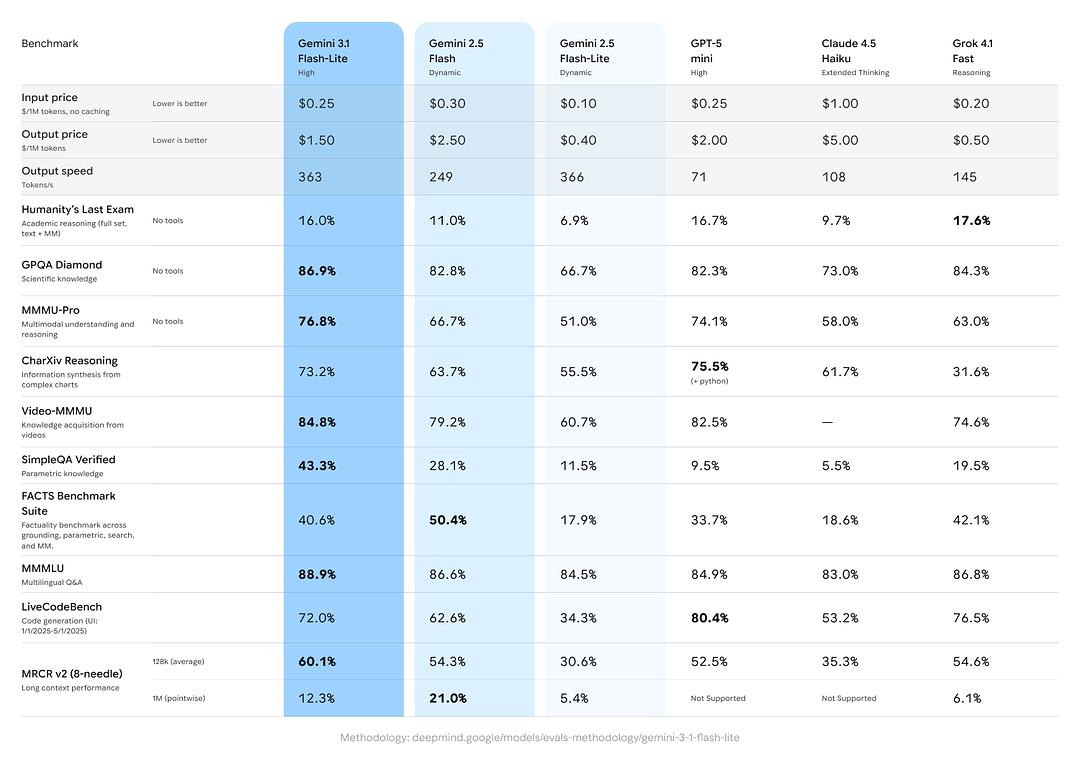
Gemini 3.1 Flash-Lite، بہتر رفتار/لاگت فراہم کرتے ہوئے ان میں سے کئی میٹرکس پر قدیم Gemini 2.5 Flash کو پیچھے چھوڑتا ہے۔
وہ استعمالات جو Gemini 3.1 Flash-Lite کے لیے موزوں ہیں
Gemini 3.1 Flash-Lite کو عملی ورک لوڈز کے ایک واضح سیٹ کے گرد ڈیزائن کیا گیا ہے جہاں ہائی تھروپُٹ اور فی ٹوکن کم لاگت فیصلہ کُن ہو:
ہائی فریکوئنسی مکالماتی ایجنٹس اور اسٹریمنگ UI
ریئل ٹائم چیٹ بوٹس، لائیو ٹرانسکرپشن + ترجمہ اسٹریمز، اور تعاوناتی UIs جو ماڈل کے جنریٹ کرنے کے ساتھ جزوی جوابات دکھاتے ہیں—Flash-Lite کے اسٹریمنگ ٹوکن آؤٹ پٹ اور کم time-to-first-token سے فائدہ اٹھاتے ہیں۔
بلک ڈیٹا پروسیسنگ (RAG، ٹرانسفارمیشن پائپ لائنز)
بڑی دستاویزات کا ادخال: اینٹیٹی استخراج، میٹاڈیٹا ٹیگنگ، کلاسیفیکیشن، اور ترجمہ کے کام جو لاکھوں دستاویزات پر انجام دیے جائیں—Gemini 3.1 Flash-Lite انفرنس لاگت کم کرتا ہے جبکہ ٹیمپلیٹڈ یا رول ڈریون آؤٹ پٹس کے لیے قابل قبول درستی فراہم کرتا ہے۔
ایج طرز یا بیک گراؤنڈ کمپیوٹ
ایسے ورک لوڈز جو آنے والے ٹیلی میٹری یا غیر ساختہ ڈیٹا کو مسلسل پروسیس کرتے ہیں (مثلاً کانٹینٹ ماڈریشن کلاسیفیکیشن پائپ لائنز، خودکار رپورٹ جنریشن) موزوں ہیں کیونکہ Gemini 3.1 Flash-Lite فی یونٹ لاگت کم سے کم رکھتا ہے۔
ڈویلپر ٹولنگ اور بیچ کوڈ کمپلیشن
ملٹی فائل اسکیفولڈنگ، بڑے پیمانے کی کوڈ لنٹنگ، اور ٹمپلیٹ جنریشن جیسے فیچرز کے لیے، Gemini 3.1 Flash-Lite کی رفتار کے فوائد اُس ڈویلپر ایکسپیرینس ٹولنگ میں لیٹنسی اور لاگت کم کرتے ہیں جہاں زیادہ سے زیادہ ریزننگ گہرائی ضروری نہیں۔
Gemini کے دیگر ماڈلز اور حریفوں کے مقابلے میں Gemini 3.1 Flash-Lite کا موازنہ
Gemini فیملی کے اندر
- Gemini 3.1 Pro: پیچیدہ ریزننگ اور ملٹی اسٹیپ پلاننگ پر سب سے زیادہ صلاحیت؛ فی ٹوکن واضح طور پر مہنگا اور سست، لیکن گہرے اور باریک کاموں کے لیے بہتر۔
- Gemini 3.1 Flash (non-Lite): خام تھروپُٹ اور صلاحیت کے درمیان درمیانی راہ کو ہدف بناتا ہے—Flash-Lite تھروپُٹ کے لیے کمپیوٹ اسٹیک میں مزید نیچے تک آپٹمائز کیا گیا ہے۔
مسابقتی “تیز” ماڈلز کے مقابلے میں
Gemini 3.1 Flash-Lite متعدد تھروپُٹ اور معیار میٹرکس پر کئی تیز/منی ماڈلز کے برابر یا بہتر کارکردگی دکھاتا ہے—تاہم آزاد تجزیہ کار خبردار کرتے ہیں کہ براہِ راست ہیڈ-ٹو-ہیڈ موازنہ جات تشخیصی طریقہ کار اور ڈیٹاسیٹ کے انتخاب کے لیے حساس ہوتے ہیں۔ توقع رکھیں کہ Gemini 3.1 Flash-Lite تھروپُٹ اور لاگت میں نہایت مسابقتی ہوگا جبکہ اعلیٰ ترین ریزننگ میٹرکس پر وسطی درجے کے قریب رہے گا۔
نتیجہ — AI اسٹیک میں Flash-Lite کہاں فٹ بیٹھتا ہے
Gemini 3.1 Flash-Lite ایک دانستہ طور پر انجینئرڈ پیشکش ہے: Gemini 3 فیملی کا ایک مؤثر، تھروپُٹ پر مرکوز رکن جو ٹیموں کو فی مثال کمپیوٹ کے کچھ حصے کو لیٹنسی اور لاگت میں ڈرامائی بہتری کے بدلے تبدیل کرنے دیتا ہے۔ اُن کاروباروں اور ڈویلپرز کے لیے جو ہائی وولیوم پائپ لائنز—ترجمہ، بیچ پروسیسنگ، اسٹریمنگ UIs، اور معتدل پیچیدگی کے ایجنٹک ٹاسکس—بناتے ہیں، Flash-Lite ایک معقول بیس لائن انجن ثابت ہوتا ہے۔ جن اداروں کو بالکل اعلیٰ ترین ریزننگ کی درستی درکار ہے، اُن کے لیے Pro ماڈلز بدستور مناسب انتخاب ہیں۔
اگر آپ کا ورک لوڈ متعدد مختصر، دہرائے جانے والے انفرنسز پر مشتمل ہے یا آپ کو بڑے پیمانے پر تیز اسٹریمنگ آؤٹ پٹ چاہیے، تو Flash-Lite آزمانے کے قابل ہے۔ اگر آپ کا ورک لوڈ گہری ملٹی ہاپ ریزننگ پر منحصر ہے، تو ایک ہائبرڈ طریقہ اپنائیں: تھروپُٹ ٹریفک کو Flash-Lite پر رُوٹ کریں اور اعلیٰ قدر، پیچیدہ سوالات کو Pro ماڈلز تک بڑھا دیں۔
ڈویلپرز ابھی Gemini 3.1 Flash Lite کو CometAPI کے ذریعے ایکسس کر سکتے ہیں۔ آغاز کے لیے، Playground میں ماڈل کی صلاحیتیں دریافت کریں اور تفصیلی ہدایات کے لیے API guide سے رجوع کریں۔ ایکسس سے پہلے، برائے مہربانی یقینی بنائیں کہ آپ CometAPI میں لاگ ان ہو چکے ہیں اور API key حاصل کر چکے ہیں۔ CometAPI انضمام میں مدد کے لیے سرکاری قیمت سے کہیں کم قیمت پیش کرتا ہے۔
آغاز کے لیے تیار ہیں؟→ Sign up fo Gemini 3.1 Flash lite today !
اگر آپ AI پر مزید ٹِپس، گائیڈز اور خبریں جاننا چاہتے ہیں تو ہمیں VK، X اور Discord پر فالو کریں!