

اوپن اے آئی نے ایک تحقیقی پیش نظارہ شائع کیا۔ gpt-oss-safeguard, ایک کھلے وزن کا اندازہ ماڈل فیملی جو ڈویلپرز کو نافذ کرنے دینے کے لیے تیار کیا گیا ہے۔ ان کے اپنے تخمینہ کے وقت حفاظتی پالیسیاں۔ ایک فکسڈ کلاسیفائر یا بلیک باکس اعتدال پسند انجن بھیجنے کے بجائے، نئے ماڈل اس کے لیے ٹھیک ہیں ڈویلپر کی فراہم کردہ پالیسی سے وجہ، ان کے استدلال کی وضاحت کرتے ہوئے ایک سلسلہ آف تھاٹ (CoT) کا اخراج کریں، اور ساختی درجہ بندی کے نتائج پیدا کریں۔ ایک تحقیقی پیش نظارہ کے طور پر اعلان کیا گیا، gpt-oss-safeguard کو استدلال کے ماڈل کے جوڑے کے طور پر پیش کیا گیا ہے۔gpt-oss-safeguard-120b اور gpt-oss-safeguard-20b— gpt-oss فیملی سے اچھی طرح سے تیار کیا گیا ہے اور واضح طور پر اندازہ کے دوران حفاظتی درجہ بندی اور پالیسی کے نفاذ کے کاموں کو انجام دینے کے لیے ڈیزائن کیا گیا ہے۔
gpt-oss-safeguard کیا ہے؟
gpt-oss-safeguard کھلے وزن والے، صرف متن کے استدلال کے ماڈلز کا ایک جوڑا ہے جسے gpt-oss فیملی سے بعد از تربیت دی گئی ہے۔ قدرتی زبان میں لکھی گئی پالیسی کی تشریح کریں اور اس پالیسی کے مطابق متن کو لیبل کریں۔. امتیازی خصوصیت یہ ہے کہ پالیسی ہے۔ قیاس کے وقت فراہم کی جاتی ہے۔ (پالیسی کے طور پر-ان پٹ)، جامد درجہ بندی کے وزن میں پکایا نہیں جاتا۔ ماڈلز بنیادی طور پر حفاظتی درجہ بندی کے کاموں کے لیے ڈیزائن کیے گئے ہیں—جیسے، کثیر پالیسی اعتدال، متعدد ریگولیٹری نظاموں میں مواد کی درجہ بندی، یا پالیسی کی تعمیل کی جانچ۔
کیوں یہ فرق پڑتا ہے
روایتی اعتدال کے نظام عام طور پر (a) مقررہ قاعدہ سیٹوں پر انحصار کرتے ہیں جو لیبل شدہ مثالوں پر تربیت یافتہ درجہ بندی کرنے والوں کے لیے میپ کیے جاتے ہیں، یا (b) مطلوبہ الفاظ کی کھوج کے لیے heuristics/regexes۔ gpt-oss-safeguard تمثیل کو تبدیل کرنے کی کوشش کرتا ہے: جب بھی پالیسی تبدیل ہوتی ہے تو درجہ بندی کرنے والوں کو دوبارہ تربیت دینے کے بجائے، آپ پالیسی کا متن فراہم کرتے ہیں (مثال کے طور پر، آپ کی کمپنی کی قابل قبول استعمال کی پالیسی، پلیٹ فارم TOS، یا ایک ریگولیٹر کی رہنما خطوط)، اور ماڈل کی وجوہات اس بارے میں کہ آیا مواد کا دیا ہوا حصہ اس پالیسی کی خلاف ورزی کرتا ہے۔ یہ چستی (دوبارہ تربیت کے بغیر پالیسی میں تبدیلی) اور تشریحی صلاحیت (ماڈل اس کے استدلال کے سلسلے کو ظاہر کرتا ہے) کا وعدہ کرتا ہے۔
یہ اس کا بنیادی فلسفہ ہے - "حافظ کو استدلال سے بدلنا، اور اندازہ کو وضاحت سے۔"
یہ مواد کی حفاظت میں ایک نئے مرحلے کی نمائندگی کرتا ہے، "غیر فعال طور پر سیکھنے کے قواعد" سے "فعال طور پر اصولوں کو سمجھنے" کی طرف۔
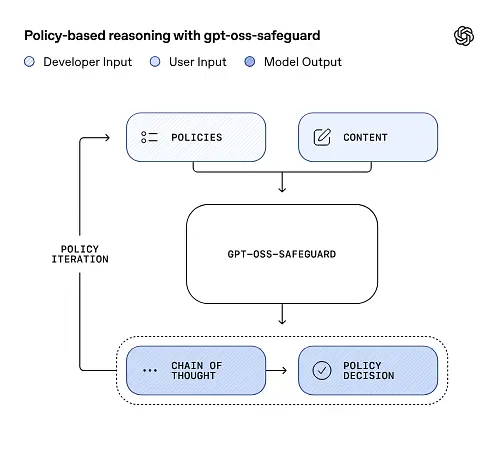
gpt-oss-safeguard ڈویلپرز کی طرف سے بیان کردہ سیکورٹی پالیسیوں کو براہ راست پڑھ سکتا ہے اور ان پالیسیوں پر عمل کر سکتا ہے تاکہ اندازہ لگانے کے دوران فیصلہ کیا جا سکے۔
gpt-oss-safeguard کیسے کام کرتا ہے؟
پالیسی کے طور پر ان پٹ استدلال
تخمینہ کے وقت، آپ دو چیزیں فراہم کرتے ہیں: پالیسی متن اور امیدوار کا مواد لیبل لگایا جائے. ماڈل پالیسی کو بنیادی ہدایات کے طور پر دیکھتا ہے اور پھر یہ تعین کرنے کے لیے مرحلہ وار استدلال کرتا ہے کہ آیا مواد کی اجازت، نامنظور، یا اضافی اعتدال کے اقدامات کی ضرورت ہے۔ اندازے کے مطابق ماڈل:
- ایک منظم آؤٹ پٹ تیار کرتا ہے جس میں ایک نتیجہ (لیبل، زمرہ، اعتماد) اور انسانی پڑھنے کے قابل استدلال کا سراغ شامل ہوتا ہے جس میں بتایا جاتا ہے کہ اس نتیجے پر کیوں پہنچا۔
- درجہ بندی کی جانے والی پالیسی اور مواد کو ہضم کرتا ہے،
- پالیسی کی شقوں کے ذریعے اندرونی طور پر وجوہات کی بناء پر سوچے سمجھے اقدامات کا استعمال کرتے ہوئے، اور
مثال کے طور پر:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
یہ جواب دے گا:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
چین آف تھاٹ (CoT) اور ساختی نتائج
gpt-oss-safeguard ہر تخمینہ کے حصے کے طور پر ایک مکمل CoT ٹریس خارج کر سکتا ہے۔ CoT کا مقصد قابل معائنہ ہونا ہے — تعمیل کرنے والی ٹیمیں پڑھ سکتی ہیں کہ ماڈل کسی نتیجے پر کیوں پہنچا، اور انجینئرز ٹریس کا استعمال پالیسی کے ابہام یا ماڈل کی ناکامی کے طریقوں کی تشخیص کے لیے کر سکتے ہیں۔ ماڈل بھی سپورٹ کرتا ہے۔ ساختی نتائج—مثال کے طور پر، ایک JSON جس میں فیصلہ، خلاف ورزی کی گئی پالیسی سیکشنز، سیوریٹی سکور، اور تجویز کردہ اصلاحی اقدامات شامل ہیں—اسے اعتدال کی پائپ لائنوں میں ضم کرنے کے لیے سیدھا بنایا گیا ہے۔
ٹیون ایبل "استدلال کی کوشش" کی سطحیں۔
تاخیر، لاگت اور مکملیت کو متوازن کرنے کے لیے ماڈل قابل استدلال کوششوں کی حمایت کرتے ہیں: کم / درمیانے / اعلی. اعلیٰ کوشش سوچ کی زنجیر کی گہرائی کو بڑھاتی ہے اور عام طور پر زیادہ مضبوط، لیکن سست اور مہنگی، قیاسات پیدا کرتی ہے۔ اس سے ڈویلپرز کو کام کے بوجھ کو ٹرائیج کرنے کی اجازت ملتی ہے — معمول کے مواد کے لیے کم کوشش اور ایج کیسز یا زیادہ رسک والے مواد کے لیے زیادہ کوشش۔
ماڈل ڈھانچہ کیا ہے اور کون سے ورژن موجود ہیں؟
ماڈل خاندان اور نسب
gpt-oss-safeguard ہیں بعد از تربیت اوپن اے آئی کے پہلے کی مختلف قسمیں gpt-oss کھلے ماڈل. حفاظتی خاندان میں فی الحال دو جاری کردہ سائز شامل ہیں:
- gpt-oss-safeguard-120b — ایک 120-بلین پیرامیٹر ماڈل جس کا مقصد اعلی درستگی کے استدلال کے کاموں کے لیے ہے جو اب بھی ایک 80GB GPU پر بہتر رن ٹائم میں چلتا ہے۔
- gpt-oss-safeguard-20b - ایک 20-بلین پیرامیٹر ماڈل جو کم لاگت کے تخمینہ اور کنارے یا آن پریم ماحول کے لیے موزوں ہے (کچھ کنفیگریشنز میں 16GB VRAM ڈیوائسز پر چل سکتا ہے)۔
آرکیٹیکچر نوٹس اور رن ٹائم خصوصیات (کیا توقع کی جائے)
- فعال پیرامیٹرز فی ٹوکن: بنیادی gpt-oss فن تعمیر میں ایسی تکنیکوں کا استعمال کیا گیا ہے جو فی ٹوکن چالو کردہ پیرامیٹرز کی تعداد کو کم کرتی ہیں (والدین gpt-oss میں گھنے اور ویرل توجہ کا مرکب / ماہرین کے طرز کے ڈیزائن کا مرکب)۔
- عملی طور پر، 120B کلاس سنگل بڑے ایکسلریٹر پر فٹ بیٹھتی ہے اور 20B کلاس کو 16GB VRAM سیٹ اپ پر آپٹمائزڈ رن ٹائمز پر کام کرنے کے لیے ڈیزائن کیا گیا ہے۔
حفاظتی ماڈل تھے۔ اضافی حیاتیاتی یا سائبرسیکیوریٹی ڈیٹا کے ساتھ تربیت یافتہ نہیں ہے۔، اور یہ کہ gpt-oss کی رہائی کے لئے انجام دیئے گئے بدترین غلط استعمال کے منظرناموں کا تجزیہ حفاظتی مختلف حالتوں پر تقریبا لاگو ہوتا ہے۔ ماڈلز حتمی صارفین کے لیے مواد کی تیاری کے بجائے درجہ بندی کے لیے بنائے گئے ہیں۔
gpt-oss-safeguard کے مقاصد کیا ہیں؟
اہداف
- پالیسی لچک: ڈویلپرز کو قدرتی زبان میں کسی بھی پالیسی کی وضاحت کرنے دیں اور ماڈل کو اپنی مرضی کے مطابق لیبل جمع کیے بغیر اسے لاگو کرنے دیں۔
- وضاحت: استدلال کو بے نقاب کریں تاکہ فیصلوں کا آڈٹ کیا جاسکے اور پالیسیوں کو دہرایا جاسکے۔
- رسائی: کھلے وزن کا متبادل فراہم کریں تاکہ تنظیمیں مقامی طور پر حفاظتی استدلال چلا سکیں اور ماڈل انٹرنل کا معائنہ کر سکیں۔
کلاسک درجہ بندی کے ساتھ موازنہ
پیشہ بمقابلہ روایتی درجہ بندی کرنے والے
- پالیسی میں تبدیلیوں کے لیے دوبارہ تربیت نہیں: اگر آپ کی اعتدال پسندی کی پالیسی تبدیل ہوتی ہے تو، لیبل جمع کرنے اور درجہ بندی کرنے والے کو دوبارہ تربیت دینے کے بجائے پالیسی دستاویز کو اپ ڈیٹ کریں۔
- بہتر استدلال: CoT کے نتائج ٹھیک ٹھیک پالیسی تعاملات کو ظاہر کر سکتے ہیں اور انسانی جائزہ لینے والوں کے لیے مفید بیانیہ جواز فراہم کر سکتے ہیں۔
- حسب ضرورت: ایک ماڈل قیاس کے دوران بیک وقت بہت سی مختلف پالیسیوں کا اطلاق کر سکتا ہے۔
کنس بمقابلہ روایتی درجہ بندی کرنے والے
- کچھ کاموں کے لیے کارکردگی کی حد: اوپن اے آئی کی تشخیص نوٹ کرتی ہے۔ دسیوں ہزار لیبل والی مثالوں پر تربیت یافتہ اعلیٰ معیار کے درجہ بندی کرنے والے gpt-oss-safeguard کو پیچھے چھوڑ سکتے ہیں۔ خصوصی درجہ بندی کے کاموں پر۔ جب مقصد خام درجہ بندی کی درستگی ہے اور آپ نے ڈیٹا کا لیبل لگا دیا ہے، تو اس تقسیم پر تربیت یافتہ ایک وقف درجہ بندی بہتر ہو سکتا ہے۔
- تاخیر اور لاگت: CoT کے ساتھ استدلال ہلکے وزن کی درجہ بندی کرنے والے کے مقابلے میں کمپیوٹ کے لحاظ سے بہت زیادہ اور سست ہے۔ یہ خالصتاً حفاظت پر مبنی پائپ لائنوں کو بڑے پیمانے پر مہنگا بنا سکتا ہے۔
مختصر میں: gpt-oss-safeguard جہاں بہترین استعمال ہوتا ہے۔ پالیسی کی چستی اور آڈٹ ایبلٹی ترجیحات ہیں یا جب لیبل لگا ڈیٹا قلیل ہے — اور ہائبرڈ پائپ لائنز میں ایک تکمیلی جزو کے طور پر، ضروری نہیں کہ اسکیل آپٹمائزڈ کلاسیفائر کے لیے ڈراپ ان متبادل کے طور پر ہو۔
OpenAI کی تشخیص میں gpt-oss-safeguard نے کس طرح کارکردگی کا مظاہرہ کیا؟
OpenAI نے 10 صفحات پر مشتمل تکنیکی رپورٹ میں بنیادی نتائج شائع کیے ہیں جس میں اندرونی اور بیرونی تشخیصات کا خلاصہ کیا گیا ہے۔ اہم ٹیک وے (منتخب کردہ، بوجھ برداشت کرنے والے میٹرکس):
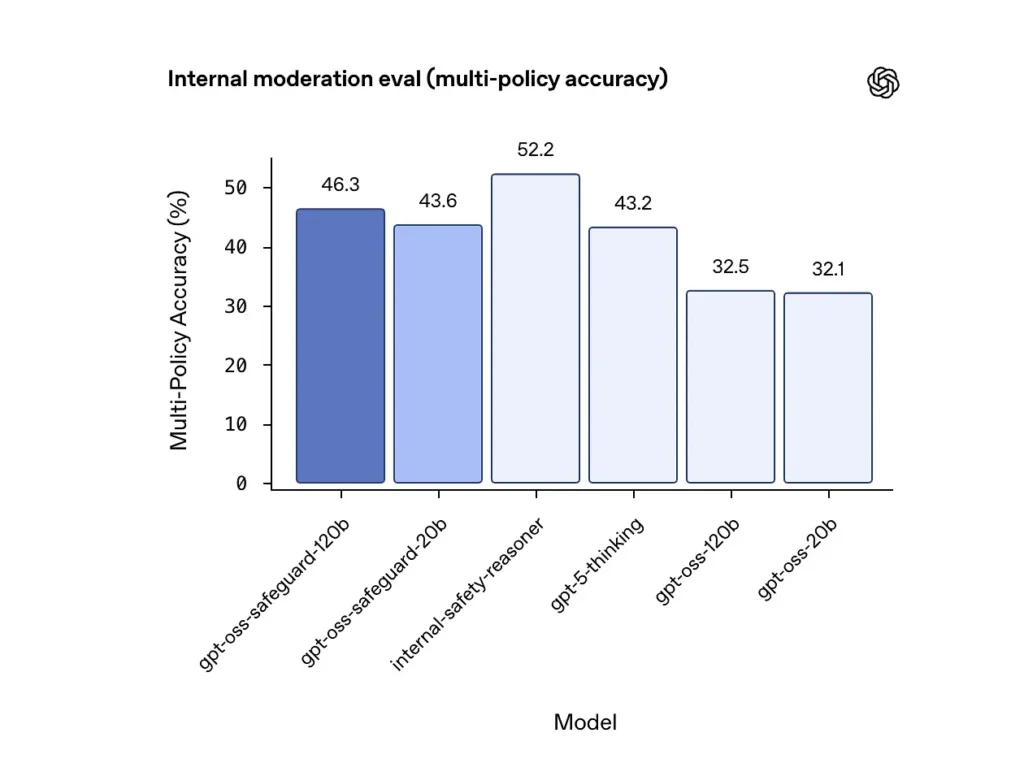
کثیر پالیسی کی درستگی (اندرونی تشخیص)
OpenAI نے ماڈل دے کر کثیر پالیسی کی درستگی کا اندازہ کیا۔ ایک سے زیادہ پالیسیاں بیک وقت اور کسی پیشین گوئی کو درست شمار کرنا صرف اس صورت میں جب وہ گولڈن لیبلز سے مماثل ہو تمام پالیسیاں نتائج:
- gpt-oss-safeguard-120b: 46.3٪ کثیر پالیسی کی درستگی
- gpt-oss-safeguard-20b: 43.6٪
- موازنہ کے لیے: gpt-5-سوچ: 43.2٪؛ gpt-oss-120b: 32.5٪؛ gpt-oss-20b: 32.1٪
اوپن اے آئی کے اندرونی "سیفٹی ریزنر" نے اسی ٹیسٹ میں 52.2 فیصد اسکور کیا۔ یہ اعداد دکھاتے ہیں کہ حفاظتی ماڈلز اپنے gpt-oss بیس ماڈلز کو ملٹی پالیسی ٹاسک پر کافی حد تک بہتر کارکردگی کا مظاہرہ کرتے ہیں، اور انہوں نے اندرونی ملٹی پالیسی میٹرک میں بڑے gpt-5-سوچنے والی بیس لائن سے بھی تجاوز کیا ہے۔
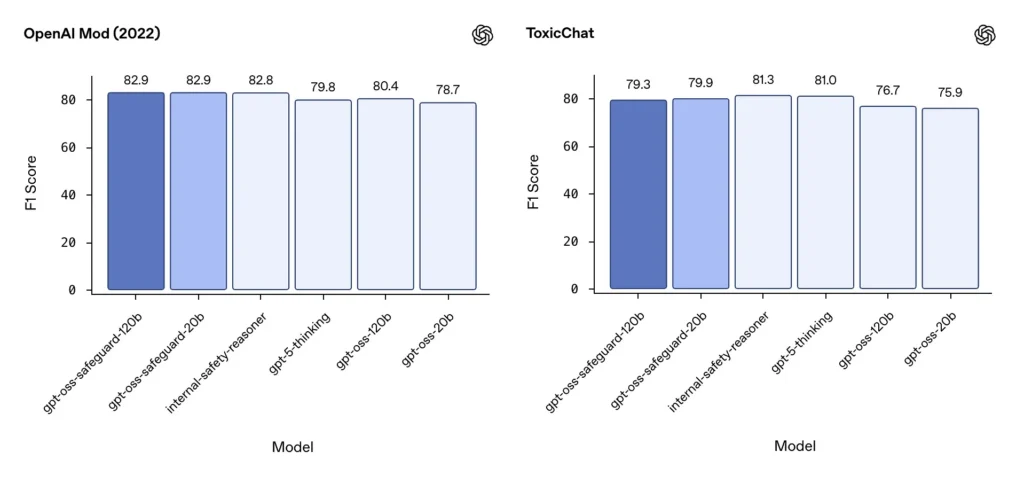
اعتدال F1 (بیرونی بینچ مارکس)
OpenAI کے 2022 ماڈریشن ڈیٹاسیٹ اور عوامی ToxicChat بینچ مارک پر، gpt-oss-safeguard ماڈلز نے ٹھوس F1 سکور حاصل کیے:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9٪, gpt-oss-safeguard-20b = 82.9٪
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3٪, gpt-oss-safeguard-20b = 79.9٪
یہ اسکور کچھ بینچ مارکس پر خصوصی اوپن اے آئی کے اندرونی سسٹمز کے قریب یا تھوڑا پیچھے gpt-oss-safeguard رکھتے ہیں، اور عام طور پر unfine-tuned gpt-oss ہم منصبوں سے آگے ہیں۔
حدود کا مشاہدہ کیا۔
OpenAI دو عملی حدود کو جھنڈا دیتا ہے:
- بڑے، ٹاسک کے مخصوص لیبل والے ڈیٹاسیٹس پر تربیت یافتہ کلاسیفائر اب بھی حفاظتی ماڈلز کو پیچھے چھوڑ سکتے ہیں جب درجہ بندی کی درستگی واحد مقصد ہے۔
- حساب اور تاخیر کے اخراجات: CoT استدلال قیاس کے وقت اور حساب کی کھپت کو بڑھاتا ہے، جو پلیٹ فارم کی سطح کی ٹریفک تک اسکیلنگ کو پیچیدہ بناتا ہے جب تک کہ ٹرائیج کلاسیفائر اور غیر مطابقت پذیر پائپ لائنز کے ساتھ جوڑا نہ بنایا جائے۔
کثیر لسانی برابری۔
gpt-oss-safeguard MMMLU طرز کے ٹیسٹوں میں بہت سی زبانوں میں بنیادی gpt-oss ماڈلز کے ساتھ برابری کے ساتھ کارکردگی کا مظاہرہ کرتا ہے، جس سے یہ ظاہر ہوتا ہے کہ حفاظتی تحفظ کی عمدہ قسمیں وسیع استدلال کی صلاحیت کو برقرار رکھتی ہیں۔
ٹیمیں gpt-oss-safeguard تک کیسے رسائی اور تعینات کر سکتی ہیں؟
OpenAI اپاچی 2.0 کے تحت وزن فراہم کرتا ہے اور ڈاؤن لوڈ کے لیے ماڈلز کو لنک کرتا ہے (ہگنگ فیس)۔ کیونکہ gpt-oss-safeguard ایک کھلے وزن کا ماڈل ہے، مقامی اور خود سے منظم تعیناتی (رازداری اور حسب ضرورت کے لیے تجویز کردہ)
- ماڈل وزن ڈاؤن لوڈ کریں۔ (OpenAI / Hugging Face سے) اور اپنے سرورز یا کلاؤڈ VMs پر ان کی میزبانی کریں۔ اپاچی 2.0 ترمیم اور تجارتی استعمال کی اجازت دیتا ہے۔
- رن ٹائم: معیاری انفرنس رن ٹائم استعمال کریں جو بڑے ٹرانسفارمر ماڈلز کو سپورٹ کرتے ہیں (ONNX رن ٹائم، ٹرائٹن، یا آپٹمائزڈ وینڈر رن ٹائمز)۔ اولاما اور ایل ایم اسٹوڈیو جیسے کمیونٹی رن ٹائمز پہلے ہی gpt-oss فیملیز کے لیے سپورٹ شامل کر رہے ہیں۔
- ہارڈ ویئر: 120B کو عام طور پر ہائی میموری والے GPUs کی ضرورت ہوتی ہے (مثال کے طور پر، 80GB A100/H100 یا ملٹی-GPU شارڈنگ)، جبکہ 20B کو زیادہ سستا چلایا جا سکتا ہے اور اس کے پاس 16GB VRAM سیٹ اپ کے لیے آپٹمائز کردہ اختیارات ہیں۔ چوٹی تھرو پٹ اور کثیر پالیسی کی تشخیص کے اخراجات کے لیے منصوبہ بندی کی صلاحیت۔
منظم اور تھرڈ پارٹی رن ٹائمز
اگر آپ کا اپنا ہارڈویئر چلانا ناقابل عمل ہے، CometAPI gpt-oss ماڈلز کے لیے تیزی سے سپورٹ شامل کر رہا ہے۔ یہ پلیٹ فارم آسانی سے اسکیلنگ فراہم کر سکتے ہیں لیکن تھرڈ پارٹی ڈیٹا ایکسپوژر ٹریڈ آفس کو دوبارہ متعارف کراتے ہیں۔ منظم رن ٹائمز کو منتخب کرنے سے پہلے رازداری، SLAs، اور رسائی کنٹرولز کا جائزہ لیں۔
gpt-oss-safeguard کے ساتھ موثر اعتدال کی حکمت عملی
1) ایک ہائبرڈ پائپ لائن استعمال کریں (ٹریج → وجہ → فیصلہ)
- ٹرائیج پرت: چھوٹے، تیز درجہ بندی کرنے والے (یا قواعد) معمولی معاملات کو فلٹر کرتے ہیں۔ یہ مہنگے حفاظتی ماڈل پر بوجھ کو کم کرتا ہے۔
- حفاظتی پرت: مبہم، زیادہ خطرے والے، یا ملٹی پالیسی چیکس کے لیے gpt-oss-safeguard چلائیں جہاں پالیسی کی اہمیت ہے۔
- انسانی فیصلہ: سی او ٹی کو شفافیت کے ثبوت کے طور پر محفوظ کرتے ہوئے ایج کیسز اور اپیلوں کو بڑھانا۔ یہ ہائبرڈ ڈیزائن تھرو پٹ اور درستگی کو متوازن رکھتا ہے۔
2) پالیسی انجینئرنگ (پرامپٹ انجینئرنگ نہیں)
- پالیسیوں کو سافٹ ویئر کے نمونے سمجھیں: ان کا ورژن بنائیں، ڈیٹا سیٹس کے خلاف ان کی جانچ کریں، اور انہیں واضح اور درجہ بندی کے مطابق رکھیں۔
- مثالوں اور جوابی مثالوں کے ساتھ پالیسیاں لکھیں۔ جب ممکن ہو، غیر واضح ہدایات شامل کریں (مثال کے طور پر، "اگر صارف کا ارادہ واضح طور پر تحقیقی اور تاریخی ہے، X کے طور پر لیبل کریں؛ اگر ارادہ آپریشنل اور حقیقی وقت ہے، Y کے طور پر لیبل کریں")۔
3) استدلال کی کوشش کو متحرک طور پر ترتیب دیں۔
- استعمال کم کوشش بلک پروسیسنگ کے لئے اور اعلی کوشش جھنڈے والے مواد، اپیلوں، یا زیادہ اثر والے عمودی (قانونی، طبی، مالیات) کے لیے۔
- قیمت/معیاری میٹھی جگہ تلاش کرنے کے لیے انسانی جائزے کے تاثرات کے ساتھ تھریشولڈز کو ٹیون کریں۔
4) CoT کی توثیق کریں اور خیالی استدلال پر نظر رکھیں
CoT قیمتی ہے، لیکن یہ دھوکہ دہی کا باعث بن سکتا ہے: ٹریس ایک ماڈل سے تیار کردہ عقلیت ہے، زمینی سچائی نہیں۔ CoT آؤٹ پٹس کا معمول کے مطابق آڈٹ کریں۔ فریب شدہ حوالہ جات یا غیر مماثل استدلال کے لیے آلہ کا پتہ لگانے والے۔ اوپن اے آئی ایک مشاہدہ شدہ چیلنج کے طور پر خیال کی زنجیروں کو فراموش کرتا ہے اور تخفیف کی حکمت عملی تجویز کرتا ہے۔
5) سسٹم کے آپریشن سے ڈیٹاسیٹس بنائیں
ماڈل کے فیصلوں اور انسانی تصحیحوں کو لاگ ان کریں تاکہ لیبل والے ڈیٹا سیٹس کو تخلیق کیا جا سکے جو ٹریج کی درجہ بندی کرنے والوں کو بہتر بنا سکتے ہیں یا پالیسی کو دوبارہ لکھنے کو مطلع کر سکتے ہیں۔ وقت گزرنے کے ساتھ، ایک چھوٹا، اعلیٰ معیار کا لیبل لگا ڈیٹاسیٹ اور ایک موثر درجہ بندی اکثر معمول کے مواد کے لیے مکمل CoT تخمینہ پر انحصار کو کم کر دیتا ہے۔
6) حساب اور اخراجات کی نگرانی؛ متضاد بہاؤ کو استعمال کریں۔
صارفین کو درپیش کم لیٹنسی ایپلی کیشنز کے لیے، ہم وقت سازی کے ساتھ اعلی کوشش CoT کو انجام دینے کے بجائے ایک مختصر مدت کے قدامت پسند UX (جیسے، عارضی طور پر زیر التواء مواد کو چھپائیں) کے ساتھ غیر مطابقت پذیر حفاظتی چیکس پر غور کریں۔ OpenAI نوٹ کرتا ہے کہ سیفٹی ریزنر پروڈکشن سروسز کے لیے تاخیر کا انتظام کرنے کے لیے اندرونی طور پر غیر مطابقت پذیر بہاؤ کا استعمال کرتا ہے۔
7) رازداری اور تعیناتی کے مقام پر غور کریں۔
چونکہ وزن کھلے ہیں، آپ سخت ڈیٹا گورننس کی تعمیل کرنے یا تیسری پارٹی کے APIs کی نمائش کو کم کرنے کے لیے مکمل طور پر آن پریمیسس چلا سکتے ہیں جو کہ ریگولیٹڈ صنعتوں کے لیے قیمتی ہے۔
نتیجہ:
gpt-oss-safeguard ایک عملی، شفاف اور لچکدار ٹول ہے۔ پالیسی پر مبنی حفاظتی استدلال. جب آپ کو ضرورت ہو تو یہ چمکتا ہے۔ قابل سماعت فیصلے واضح پالیسیوں سے منسلک ہیں۔، جب آپ کی پالیسیاں کثرت سے تبدیل ہوتی ہیں، یا جب آپ احاطے میں حفاظتی چیک رکھنا چاہتے ہیں۔ یہ ہے نوٹ ایک چاندی کی گولی جو خود بخود خصوصی، اعلیٰ حجم کے درجہ بندی کرنے والوں کی جگہ لے لے گی — اوپن اے آئی کے اپنے تجزیے ظاہر کرتے ہیں کہ بڑے لیبل والے کارپورا پر تربیت یافتہ سرشار درجہ بندی تنگ کاموں کے لیے خام درستگی پر ان ماڈلز کو پیچھے چھوڑ سکتے ہیں۔ اس کے بجائے، gpt-oss-safeguard کو ایک اسٹریٹجک جزو کے طور پر دیکھیں: ایک تہہ دار حفاظتی فن تعمیر کے مرکز میں قابل وضاحت استدلال انجن (تیز رفتار → قابل وضاحت استدلال → انسانی نگرانی)۔
شروع
CometAPI ایک متحد API پلیٹ فارم ہے جو سرکردہ فراہم کنندگان سے 500 سے زیادہ AI ماڈلز کو اکٹھا کرتا ہے — جیسے OpenAI کی GPT سیریز، Google کی Gemini، Anthropic's Claude، Midjourney، Suno، اور مزید — ایک واحد، ڈویلپر کے موافق انٹرفیس میں۔ مسلسل تصدیق، درخواست کی فارمیٹنگ، اور رسپانس ہینڈلنگ کی پیشکش کرکے، CometAPI ڈرامائی طور پر آپ کی ایپلی کیشنز میں AI صلاحیتوں کے انضمام کو آسان بناتا ہے۔ چاہے آپ چیٹ بوٹس، امیج جنریٹرز، میوزک کمپوزر، یا ڈیٹا سے چلنے والی اینالیٹکس پائپ لائنز بنا رہے ہوں، CometAPI آپ کو تیزی سے اعادہ کرنے، لاگت کو کنٹرول کرنے، اور وینڈر-ایگنوسٹک رہنے دیتا ہے—یہ سب کچھ AI ماحولیاتی نظام میں تازہ ترین کامیابیوں کو حاصل کرنے کے دوران۔
تازہ ترین انٹیگریشن gpt-oss-safeguard جلد ہی CometAPI پر ظاہر ہو گا، اس لیے دیکھتے رہیں!جب ہم gpt-oss-safeguard ماڈل اپ لوڈ کو حتمی شکل دیتے ہیں، ڈویلپرز رسائی حاصل کر سکتے ہیں GPT-OSS-20B API اور GPT-OSS-120B API CometAPI کے ذریعے، جدید ترین ماڈل ورژن ہمیشہ سرکاری ویب سائٹ کے ساتھ اپ ڈیٹ کیا جاتا ہے۔ شروع کرنے کے لیے، میں ماڈل کی صلاحیتوں کو دریافت کریں۔ کھیل کے میدان اور مشورہ کریں API گائیڈ تفصیلی ہدایات کے لیے۔ رسائی کرنے سے پہلے، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ ان کیا ہے اور API کلید حاصل کر لی ہے۔ CometAPI آپ کو انضمام میں مدد کے لیے سرکاری قیمت سے کہیں کم قیمت پیش کریں۔
جانے کے لیے تیار ہیں؟→ CometAPI کے لیے آج ہی سائن اپ کریں۔ !
اگر آپ AI پر مزید ٹپس، گائیڈز اور خبریں جاننا چاہتے ہیں تو ہمیں فالو کریں۔ VK, X اور Discord!