

GLM-5، Zhipu AI کا نیا اوپن ویٹس، ایجنٹ مرکوز فاؤنڈیشن ماڈل ہے جو طویل افق کوڈنگ اور کثیر قدمی ایجنٹس کے لیے بنایا گیا ہے۔ یہ متعدد ہوسٹڈ APIs (جن میں CometAPI اور پرووائیڈر اینڈپوائنٹس شامل ہیں) کے ذریعے دستیاب ہے اور تحقیقاتی ریلیز کے طور پر کوڈ اور ویٹس کے ساتھ؛ آپ اسے معیاری OpenAI-مطابق REST کالز، اسٹریمنگ، اور SDKs کے ذریعے مربوط کر سکتے ہیں۔
Z.ai کا GLM-5 کیا ہے؟
GLM-5، Z.ai کا پانچویں نسل کا فلیگ شپ فاؤنڈیشن ماڈل ہے جو ایجینٹک انجینئرنگ کے لیے ڈیزائن کیا گیا ہے: طویل افق منصوبہ بندی، کثیر قدمی ٹول استعمال، اور بڑے پیمانے پر کوڈ/سسٹم ڈیزائن۔ فروری 2026 میں عوامی طور پر جاری کیا گیا، GLM-5 ایک Mixture-of-Experts (MoE) ماڈل ہے جس میں کل ~744 بلین پیرامیٹرز ہیں اور فی فارورڈ پاس فعال پیرامیٹر سیٹ ~40B کے دائرے میں ہے؛ آرکیٹیکچر اور تربیتی انتخاب طویل کانٹیکسٹ میں مطابقت، ٹول کالنگ، اور پروڈکشن ورک لوڈز کے لیے کم لاگت انفیرینس کو ترجیح دیتے ہیں۔ یہ ڈیزائن انتخاب GLM-5 کو توسیع شدہ ایجینٹک ورک فلو چلانے دیتے ہیں (مثال کے طور پر: براؤز → منصوبہ بنائیں → کوڈ لکھیں/جانچیں → دہرائیں) جبکہ بہت طویل ان پٹس پر سیاق و سباق محفوظ رکھتے ہیں۔
اہم تکنیکی نمایاں خصوصیات:
- MoE آرکیٹیکچر ~744B کل / ~40B فعال پیرامیٹرز کے ساتھ؛ اسکیلڈ پری ٹریننگ (~28.5T ٹوکنز رپورٹڈ) تاکہ فرنٹیئر بند ماڈلز کے ساتھ خلا کم کیا جا سکے۔
- لانگ کانٹیکسٹ سپورٹ اور آپٹیمائزیشنز (deep sparse attention, DSA) جو سادہ ڈینس اسکیلنگ کے مقابلے میں ڈپلائمنٹ لاگت کم کرتی ہیں۔
- ایجینٹک فیچرز بلٹ ان: ٹول/فنکشن کالنگ، اسٹیٹ فل سیشن سپورٹ، اور انٹیگریٹڈ آؤٹ پٹس (وینڈر UIs میں ایجنٹ ورک فلو کا حصہ ہوتے ہوئے
.docx,.xlsx,.pdfآرٹیفیکٹس بنانے کی صلاحیت)۔ - اوپن ویٹس دستیابی (ویٹس ماڈل ہبز پر شائع) اور ہوسٹڈ ایکسس آپشنز (وینڈر APIs، انفیرینس مائیکرو سروسز)۔
GLM-5 کے اہم فوائد کیا ہیں؟
ایجینٹک منصوبہ بندی اور طویل افق میموری
GLM-5 کا آرکیٹیکچر اور ٹیوننگ ورک فلوز میں مستقل کثیر قدمی استدلال اور میموری کو ترجیح دیتے ہیں — یہ فائدہ مند ہے برائے:
- خودکار ایجنٹس (CI پائپ لائنز، ٹاسک آرکسٹریٹرز)،
- بڑے کثیر فائل کوڈ جنریشن یا ریفیکٹرز، اور
- دستاویزی انٹیلیجنس جسے بڑی ہسٹری برقرار رکھنی ہوتی ہے۔
وسیع کانٹیکسٹ ونڈوز
GLM-5 بہت بڑے کانٹیکسٹ سائزز کی سپورٹ کرتا ہے (شائع شدہ ماڈل اسپیکس میں ~200k ٹوکنز کے درجے پر)، جس سے آپ ایک درخواست میں سیشن کا زیادہ حصہ برقرار رکھ سکتے ہیں اور بہت سے استعمال کیسز کے لیے جارحانہ چنکنگ یا بیرونی میموری کی ضرورت کم ہوتی ہے۔ (نیچے تقابلی چارٹ دیکھیں۔)
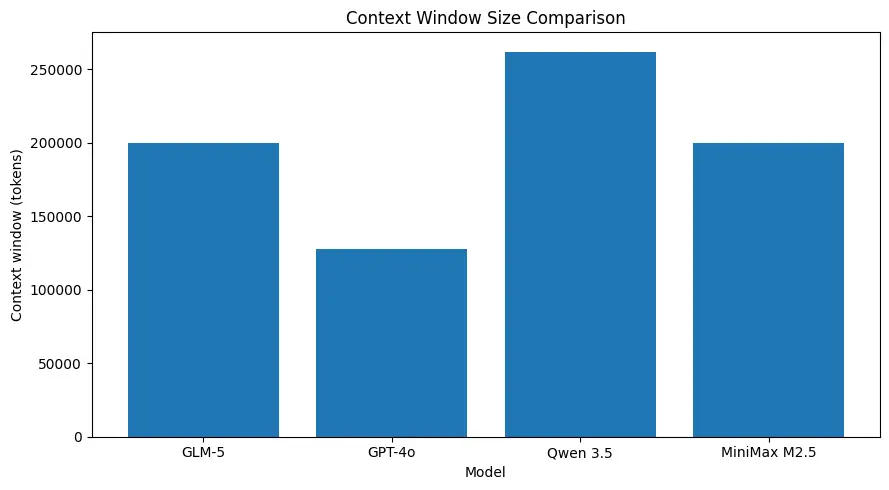
سسٹم لیول ٹاسکس کے لیے مضبوط کوڈنگ کارکردگی
GLM-5 نے سافٹ ویئر انجینئرنگ بینچ مارکس (SWE-bench اور اپلائیڈ کوڈ + ایجنٹ سوٹس) پر بہترین اوپن سورس کارکردگی رپورٹ کی ہے۔ SWE-bench-Verified پر ~77.8% رپورٹ کرتا ہے؛ کوڈنگ/ٹرمنل-اسٹائل ایجنٹ ٹیسٹس (Terminal-Bench 2.0) میں اسکورز مڈ-50s میں کلسٹر کرتے ہیں — عملی کوڈنگ صلاحیت کے شواہد جو فرنٹیئر ملکیتی ماڈلز کے قریب پہنچتی ہیں۔ یہ میٹرکس ظاہر کرتے ہیں کہ GLM-5 کوڈ جنریشن، خودکار ریفیکٹرنگ، کثیر فائل استدلال، اور CI/CD اسسٹنٹ منظرناموں جیسے کاموں کے لیے موزوں ہے۔
لاگت/کارکردگی کے تبادلے
کیونکہ GLM-5 MoE اور “سپارس” اٹنشن میں جدتیں استعمال کرتا ہے، یہ صلاحیت فی یونٹ انفیرینس لاگت کو brute-force ڈینس اسکیلنگ کے مقابلے میں کم کرنے کا ہدف رکھتا ہے۔ CometAPI ایسے مسابقتی قیمت پوائنٹس فراہم کرتا ہے جو GLM-5 کو بھاری تھرو پٹ ایجینٹک ورک لوڈز کے لیے پرکشش بناتے ہیں۔
میں CometAPI کے ذریعے GLM-5 API کیسے استعمال کروں؟
مختصر جواب: CometAPI کو ایک OpenAI-مطابق گیٹ وے سمجھیں — اپنا بیس URL اور API کی سیٹ کریں، glm-5 کو ماڈل کے طور پر منتخب کریں، پھر chat/completions اینڈ پوائنٹ کال کریں۔ CometAPI ایک OpenAI-اسٹائل REST سطح فراہم کرتا ہے (ایند پوائنٹس جیسے /v1/chat/completions) نیز SDKs اور نمونہ پروجیکٹس جو مائیگریشن کو بہت آسان بنا دیتے ہیں۔
نیچے ایک عملی، پروڈکشن-اورینٹڈ کوک بک ہے: آتھ، بنیادی چیٹ کال، اسٹریمنگ، فنکشن/ٹول کالنگ، اور لاگت/رسپانس ہینڈلنگ۔
CometAPI کے ذریعے GLM-5 تک رسائی کے بنیادی مراحل:
- CometAPI پر سائن اپ کریں، API کی حاصل کریں۔
- CometAPI کے کیٹلاگ میں GLM-5 کے لیے درست ماڈل آئی ڈی تلاش کریں (
"glm-5"لسٹنگ پر منحصر)۔ - CometAPI کے chat/completions اینڈ پوائنٹ (OpenAI-اسٹائل) پر ایک مستند POST درخواست بھیجیں۔
بنیادی تفصیلات (CometAPI پیٹرنز): پلیٹ فارم OpenAI-اسٹائل راستے سپورٹ کرتا ہے جیسے https://api.cometapi.com/v1/chat/completions، Bearer تصدیق، model پیرامیٹر، system/user پیغامات، اسٹریمنگ، اور دستاویزات میں curl/python مثالیں۔
مثال: GLM-5 کے ساتھ فاسٹ Python (requests) چیٹ کمپلیشن
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
مثال: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
اسٹریمنگ رسپانسز (عملی پیٹرن)
CometAPI OpenAI-اسٹائل اسٹریمنگ (SSE / chunked) سپورٹ کرتا ہے۔ Python میں سب سے آسان طریقہ "stream": true کی درخواست کرنا ہے اور رسپانس ڈیٹا کو وصول ہوتے ہی iterate کرنا ہے۔ یہ اس وقت اہم ہے جب آپ کو کم تاخیر کے ساتھ جزوی آؤٹ پٹ درکار ہو (ریئل ٹائم ڈیو اسسٹنٹس، اسٹریمنگ UIs بنائیں)۔
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
حوالہ: OpenAI-اسٹائل اسٹریمنگ اور CometAPI موافقت دستاویزات۔
فنکشن / ٹول کالنگ (کسی بیرونی ٹول کو کیسے کال کریں)
GLM-5 OpenAI / ایگریگیٹر کنونشنز کے مطابق فنکشن یا ٹول کالنگ پیٹرنز سپورٹ کرتا ہے (گیٹ وے ماڈل رسپانس میں ساختہ فنکشن کالز پاس کرتا ہے)۔ مثال استعمال: GLM-5 سے مقامی “run_tests” ٹول کو کال کرنے کو کہیں؛ ماڈل ایک ساختہ ہدایت واپس کرتا ہے جسے آپ پارس کر کے ایکزیکیوٹ کر سکتے ہیں۔
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
جب ماڈل function_call پے لوڈ واپس کرے، ٹول کو سرور سائیڈ پر ایکزیکیوٹ کریں، پھر ٹول نتیجہ کو "tool" رول والے پیغام کے طور پر واپس فیڈ کریں اور گفتگو جاری رکھیں۔ یہ پیٹرن محفوظ ٹول انوکیشن اور اسٹیٹ فل ایجنٹ فلو کو ممکن بناتا ہے۔ ٹھوس SDK ہیلپرز کے لیے CometAPI کی دستاویزات اور مثالیں دیکھیں۔
عملی پیرامیٹرز اور ٹیوننگ
function_call: ساختہ ٹول انوکیشن اور زیادہ محفوظ ایکزیکیوشن فلو فعال کرنے کے لیے استعمال کریں۔
temperature: سسٹم-لیول آؤٹ پٹس (کوڈ، انفرا) کے لیے 0–0.3، آئیڈییشن کے لیے زیادہ۔
max_tokens: متوقع آؤٹ پٹ لمبائی کے مطابق سیٹ کریں؛ ہوسٹڈ ہونے پر GLM-5 بہت طویل آؤٹ پٹس سپورٹ کرتا ہے (وینڈر حدود مختلف ہو سکتی ہیں)۔
top_p / nucleus sampling: غیر ممکنہ ٹیلز کو محدود کرنے کے لیے مفید۔
stream: interactive UIs کے لیے true۔
GLM-5 کا Anthropic کے Claude Opus اور دیگر فرنٹیئر ماڈلز سے موازنہ
مختصر جواب: GLM-5 ایجینٹک اور کوڈنگ بینچ مارکس میں فرنٹیئر بند ماڈلز کے ساتھ خلا کم کرتا ہے جبکہ اوپن ویٹس ڈپلائمنٹ اور اکثر بہتر فی ٹوکن لاگت فراہم کرتا ہے جب ایگریگیٹرز کے ذریعے ہوسٹ کیا جائے۔ باریک نکتہ: کچھ مطلق کوڈنگ بینچ مارکس (SWE-bench، Terminal-Bench ویریئنٹس) پر Anthropic کا Claude Opus (4.5/4.6) بہت سے شائع شدہ لیڈر بورڈز میں چند پوائنٹس سے آگے ہے — لیکن GLM-5 انتہائی مسابقتی ہے اور بہت سے دیگر اوپن ماڈلز سے بہتر کارکردگی دکھاتا ہے۔
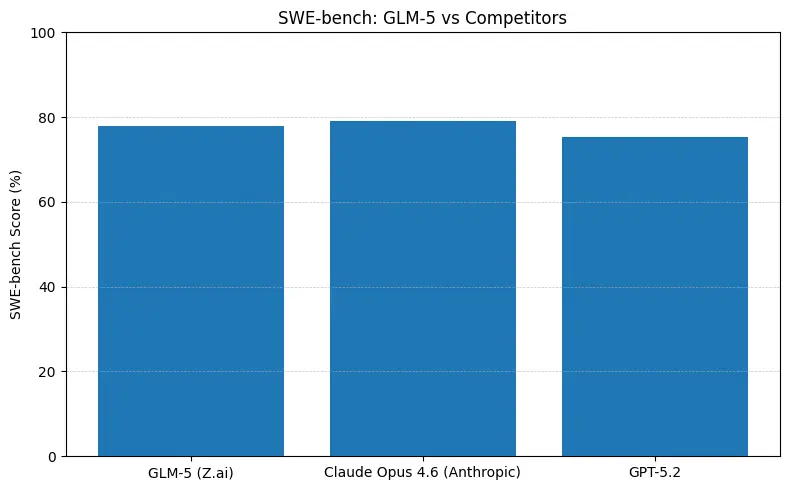
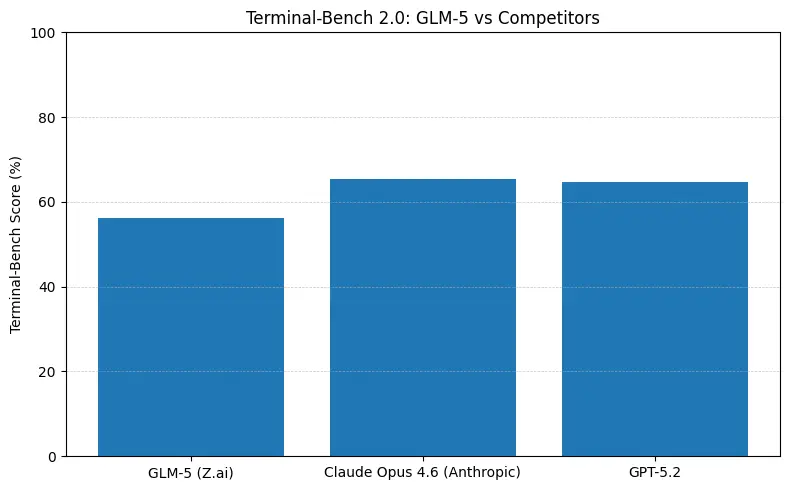
عملی طور پر ان نمبروں کا مطلب
- SWE-bench (~کوڈ درستگی / انجینئرنگ): شائع شدہ لیڈر بورڈز پر Claude Opus معمولی برتری دکھاتا ہے (≈79% بمقابلہ GLM-5 ≈77.8%)؛ بہت سے حقیقی کاموں میں یہ خلا کم دستی ایڈٹس میں ظاہر ہو گا، مگر لازمی طور پر پروٹوٹائپنگ یا اسکیلڈ ایجینٹک ورک فلو کے لیے مختلف آرکیٹیکچر انتخاب نہیں بنے گا۔
- Terminal-Bench (کمانڈ لائن ایجینٹک ٹاسکس): Opus 4.6 آگے ہے (≈65.4% بمقابلہ GLM-5 ≈56.2%) — اگر آپ کو ٹرمینل آٹومیشن میں مضبوطی اور آؤٹ-آف-ڈسٹری بیوشن شیل آپریشنز پر اعلیٰ اعتباریت چاہیے، تو Opus اکثر حاشیے پر بہتر ہوتا ہے۔
- ایجینٹک اور طویل افق: GLM-5 لانگ-ہورائزن بزنس سمولیشنز (Vending-Bench 2 بیلنس $4,432 رپورٹڈ) پر بہت اچھی کارکردگی دکھاتا ہے اور کثیر قدمی ورک فلو کے لیے مضبوط منصوبہ بندی مطابقت دکھاتا ہے۔ اگر آپ کی پروڈکٹ لانگ رننگ ایجنٹ ہے (فنانس، آپریشنز)، GLM-5 مضبوط انتخاب ہے۔
GLM-5 سے قابلِ اعتبار آؤٹ پٹس حاصل کرنے کے لیے پرامپٹس اور سسٹمز کیسے ڈیزائن کریں؟
سسٹم میسیجز اور واضح پابندیاں
GLM-5 کو ایک سخت رول اور پابندیاں دیں، خاص طور پر کوڈ یا ٹول کالنگ ٹاسکس کے لیے۔ مثال:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
ہر غیر معمولی تبدیلی کے لیے ٹیسٹس اور مختصر دلائل مانگیں۔
پیچیدہ کاموں کو تقسیم کریں
“پوری پروڈکٹ لکھیں” کے بجائے یہ کہیں:
- ڈیزائن آؤٹ لائن،
- انٹرفیس سائن ایچرز،
- امپلیمینٹیشن اور ٹیسٹس،
- آخری انٹیگریشن اسکرپٹ۔
یہ مرحلہ وار تقسیم ہیلوسی نیشن کم کرتی ہے اور ایسے متعین چیک پوائنٹس دیتی ہے جنہیں آپ ویلیڈیٹ کر سکتے ہیں۔
ڈیٹرمنسٹک کوڈ کے لیے کم temperature استعمال کریں
جب کوڈ مانگیں، temperature = 0–0.2 سیٹ کریں اور max_tokens کو محفوظ اوپری حد تک رکھیں۔ تخلیقی تحریر یا ڈیزائن برین اسٹورمنگ کے لیے temperature بڑھائیں۔
GLM-5 کو مربوط کرتے وقت بہترین طریقہ کار (CometAPI یا ڈائریکٹ ہوسٹس کے ذریعے)
پرامپٹ انجینئرنگ اور سسٹم پرامپٹس
- واضح system ہدایات استعمال کریں جو ایجنٹ رولز، ٹول رسائی پالیسیاں، اور سیفٹی پابندیوں کو متعین کریں۔ مثال: “You are a system architect: only propose changes when unit tests pass locally; list exact CLI commands to run.”
- کوڈنگ ٹاسکس کے لیے ریپوزٹری کانٹیکسٹ (فائل لسٹس، کلیدی کوڈ اسنیپٹس) فراہم کریں اور اگر دستیاب ہو تو یونٹ ٹیسٹ آؤٹ پٹس منسلک کریں۔ GLM-5 کی لانگ کانٹیکسٹ ہینڈلنگ مدد کرتی ہے — مگر ہمیشہ ضروری کانٹیکسٹ پہلے رکھیں (رول، ٹاسک) پھر سپورٹنگ آرٹیفیکٹس۔
سیشن اور اسٹیٹ مینجمنٹ
- طویل ایجنٹ گفتگو کے لیے سیشن IDs استعمال کریں اور سابقہ مراحل کی کمپیکٹڈ “میموری” (خلاصے) رکھیں تاکہ کانٹیکسٹ بوجھ بڑھنے سے بچا جا سکے۔ CometAPI اور ملتے جلتے گیٹ ویز سیشن/اسٹیٹ ہیلپرز دیتے ہیں — مگر ایپلیکیشن-لیول اسٹیٹ کمپیکشن لانگ رننگ ایجنٹس کے لیے ضروری ہے۔
- سیشن IDs استعمال کریں اور گفتگو کو قابلِ ٹریس رکھیں؛ اہم تاریخی اقدامات کا خلاصہ کریں تاکہ کانٹیکسٹ موثر رہے۔
ٹولنگ اور فنکشن کالز (سیفٹی + اعتباریت)
- ٹولز کا محدود، قابلِ آڈٹ سیٹ سامنے لائیں۔ انسانی نگرانی کے بغیر من مانی شیل ایکزیکیوشن کی اجازت نہ دیں۔ ساختہ فنکشن ڈیفینیشنز استعمال کریں اور ان کے آرگیومنٹس سرور سائیڈ ویلیڈیٹ کریں۔
- ہمیشہ ٹول کالز اور ماڈل رسپانسز لاگ کریں تاکہ ٹریس ایبلٹی اور پوسٹ مارٹم ڈی بگنگ ممکن ہو۔
لاگت کنٹرول اور بیچنگ
- ہائی والیوم ایجنٹس کے لیے، بیک گراؤنڈ پروسیسنگ کو سستے ماڈل ویریئنٹس کی طرف روٹ کریں جب معیار کے تبادلے قابل قبول ہوں (CometAPI آپ کو نام کے ذریعے ماڈلز بدلنے دیتا ہے)۔ ملتے جلتے درخواستوں کو بیچ کریں اور جہاں ممکن ہو
max_tokensکم کریں۔ ان پٹ بمقابلہ آؤٹ پٹ ٹوکن ریشو مانیٹر کریں — آؤٹ پٹ ٹوکنز اکثر زیادہ مہنگے ہوتے ہیں۔ - لاگت کے لیے ان پٹ کمپریشن اور جواب کی لمبائی محدود رکھیں؛ بار بار کے کاموں کو بیچ کریں۔
لیٹنسی اور تھرو پٹ انجینئرنگ
- interactive سیشنز کے لیے اسٹریمنگ استعمال کریں۔ بیک گراؤنڈ ایجنٹ جابز کے لیے، async رن ٹائمز، ورکَر کیوز، اور ریٹ-لیمٹرز ترجیح دیں۔ اگر آپ خود ہوسٹ کرتے ہیں (اوپن ویٹس)، اپنی ایکسیلیریٹر ٹاپولوجی کو MoE آرکیٹیکچر کے مطابق ٹیون کریں — FPGA / Ascend / خصوصی سلکان جیسے آپشنز لاگت میں فائدہ دے سکتے ہیں۔
آخری نوٹس
GLM-5 ایجینٹک انجینئرنگ کی طرف ایک عملی، اوپن ویٹس قدم کی نمائندگی کرتا ہے: بڑے کانٹیکسٹ ونڈوز، منصوبہ بندی کی صلاحیتیں، اور مضبوط کوڈ کارکردگی اسے ڈویلپر ٹولز، ایجنٹ آرکسٹریشن، اور سسٹم لیول آٹومیشن کے لیے پرکشش بناتی ہیں۔ فوری انٹیگریشن کے لیے CometAPI استعمال کریں یا مینیجڈ ہوسٹنگ کے لیے کلاؤڈ ماڈل گارڈن؛ ہمیشہ اپنے ورک لوڈ پر ویلیڈیٹ کریں اور لاگت و ہیلوسی نیشن کنٹرولز کے لیے مضبوط انسٹرومنٹیشن رکھیں۔
ڈویلپرز اب GLM-5 کو CometAPI کے ذریعے ایکسس کر سکتے ہیں۔ آغاز کے لیے، ماڈل کی صلاحیتیں Playground میں ایکسپلور کریں اور تفصیلی ہدایات کے لیے API guide سے رجوع کریں۔ رسائی سے پہلے، براہ کرم یقینی بنائیں کہ آپ CometAPI میں لاگ ان ہیں اور API کی حاصل کر لی ہے۔ CometAPI سرکاری قیمت کے مقابلے میں بہت کم قیمت پیش کرتا ہے تاکہ آپ انٹیگریٹ کر سکیں۔
Ready to Go?→ آج ہی M2.5 کے لیے سائن اپ کریں !
اگر آپ AI پر مزید ٹپس، گائیڈز اور خبریں جاننا چاہتے ہیں تو ہمیں VK، X اور Discord پر فالو کریں!