

17 جون کو، شنگھائی AI ایک تنگاوالا MiniMax سرکاری طور پر اوپن سورس MiniMax‑M1، دنیا کا پہلا اوپن ویٹ بڑے پیمانے پر ہائبرڈ توجہ کا اندازہ لگانے والا ماڈل۔ نئے لائٹننگ اٹینشن میکانزم کے ساتھ ایک مکسچر آف ایکسپرٹس (MoE) فن تعمیر کو ملا کر، MiniMax-M1 انفرنس اسپیڈ، الٹرا لانگ سیاق و سباق کو سنبھالنے اور پیچیدہ کام کی کارکردگی میں اہم فوائد فراہم کرتا ہے۔
پس منظر اور ارتقاء
کی بنیاد پر تعمیر MiniMax-Text-01، جس نے تربیت کے دوران 1 ملین ٹوکن سیاق و سباق حاصل کرنے کے لئے مکسچر آف ایکسپرٹس (MoE) فریم ورک پر بجلی کی توجہ متعارف کرائی اور تخمینہ کے لحاظ سے 4 ملین ٹوکن تک، MiniMax-M1 MiniMax-01 سیریز کی اگلی نسل کی نمائندگی کرتا ہے۔ پیشرو ماڈل، MiniMax-Text-01، 456 بلین کل پیرامیٹرز پر مشتمل ہے جس میں 45.9 بلین فی ٹوکن ایکٹیویٹ کیا گیا ہے، جو اعلی درجے کے LLMs کے برابر کارکردگی کا مظاہرہ کرتے ہوئے سیاق و سباق کی صلاحیتوں کو وسیع پیمانے پر بڑھاتا ہے۔
MiniMax-M1 کی اہم خصوصیات
- ہائبرڈ MoE + بجلی کی توجہ: MiniMax‑M1 ماہرین کے ڈیزائن کے ایک ویرل مرکب کو فیوز کرتا ہے—456 بلین کل پیرامیٹرز، لیکن صرف 45.9 بلین فی ٹوکن چالو — لائٹننگ اٹینشن کے ساتھ، ایک لکیری-پیچیدگی کی توجہ جو بہت طویل ترتیب کے لیے موزوں ہے۔
- الٹرا لانگ سیاق و سباق: تک کی حمایت کرتا ہے۔ 1 ملین ان پٹ ٹوکنز—DeepSeek‑R128 کی 1 K حد سے تقریباً آٹھ گنا— بڑے پیمانے پر دستاویزات کی گہرائی سے فہم کو قابل بناتا ہے۔
- اعلی کارکردگی: 100 K ٹوکنز تیار کرتے وقت، MiniMax‑M1 کی لائٹننگ اٹینشن کے لیے DeepSeek‑R25 کے استعمال کردہ کمپیوٹ کا صرف ~30–1% درکار ہوتا ہے۔
ماڈل کی مختلف حالتیں
- MiniMax‑M1‑40K: 1 M ٹوکن سیاق و سباق، 40 K ٹوکن انفرنس بجٹ
- MiniMax‑M1‑80K: 1 M ٹوکن سیاق و سباق، 80 K ٹوکن انفرنس بجٹ
TAU بینچ ٹول کے استعمال کے منظرناموں میں، 40K ویریئنٹ نے تمام اوپن ویٹ ماڈلز کو پیچھے چھوڑ دیا — بشمول Gemini 2.5 Pro — اپنی ایجنٹ کی صلاحیتوں کو ظاہر کرتے ہوئے۔
تربیت کی لاگت اور سیٹ اپ
MiniMax-M1 کو کاموں کے متنوع سیٹ میں بڑے پیمانے پر کمک سیکھنے (RL) کا استعمال کرتے ہوئے آخر سے آخر تک تربیت دی گئی تھی—جدید ریاضیاتی استدلال سے لے کر سینڈ باکس پر مبنی سافٹ ویئر انجینئرنگ ماحول تک۔ ایک نیا الگورتھم، سی آئی ایس پی او (پالیسی کی اصلاح کے لیے کلیپڈ امپورٹنس سیمپلنگ)، ٹوکن لیول اپڈیٹس کے بجائے اہمیت کے نمونے لینے کے وزن کو تراش کر تربیت کی کارکردگی کو مزید بڑھاتا ہے۔ اس نقطہ نظر نے، ماڈل کی بجلی کی توجہ کے ساتھ مل کر، 512 H800 GPUs پر مکمل RL ٹریننگ کو صرف تین ہفتوں میں $534,700 کی کل کرائے کی قیمت پر مکمل کرنے کی اجازت دی۔
دستیابی اور قیمتوں کا تعین
MiniMax-M1 کے تحت جاری کیا گیا ہے۔ اپاچی 2.0 اوپن سورس لائسنس اور اس کے ذریعے فوری طور پر قابل رسائی ہے:
- GitHub ذخیرہبشمول ماڈل وزن، تربیتی اسکرپٹ، اور تشخیصی معیارات۔
- سلیکون کلاؤڈ ہوسٹنگ، مکمل 40 M ٹوکن فنل کو فعال کرنے کے منصوبوں کے ساتھ—1 K‑ٹوکن (“M40‑80K”) اور 1 K‑token (“M80‑1K”) پیش کر رہا ہے۔
- قیمتوں کا تعین فی الحال مقرر ہے۔ ¥4 فی ملین ان پٹ کے لیے ٹوکن اور ¥16 فی ملین آؤٹ پٹ کے لیے ٹوکنز، انٹرپرائز صارفین کے لیے دستیاب والیوم ڈسکاؤنٹس کے ساتھ۔
ڈویلپرز اور تنظیمیں معیاری APIs کے ذریعے MiniMax-M1 کو مربوط کر سکتے ہیں، ڈومین کے مخصوص ڈیٹا کو ٹھیک کر سکتے ہیں، یا حساس کام کے بوجھ کے لیے آن پریمیسس تعینات کر سکتے ہیں۔
ٹاسک لیول کی کارکردگی
| ٹاسک کیٹیگری | نمایاں کریں | رشتہ دار کارکردگی |
|---|---|---|
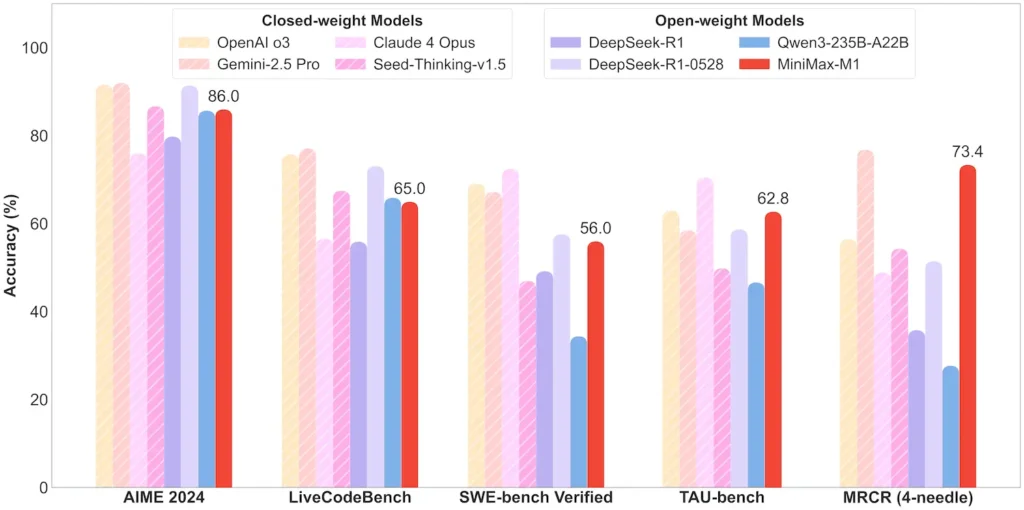
| ریاضی اور منطق | AIME 2024: 86.0% | > Qwen 3، DeepSeek‑R1؛ بند ذریعہ کے قریب |
| طویل سیاق و سباق کی سمجھ | حکمران (4 K–1 M ٹوکن): مستحکم اعلی درجے کا | GPT-4 کو 128 K ٹوکن کی لمبائی سے آگے بڑھاتا ہے۔ |
| سافٹ ویئر انجینئرنگ | SWE بینچ (حقیقی GitHub کیڑے): 56% | کھلے ماڈلز میں بہترین؛ معروف بند کرنے کے لئے 2nd |
| ایجنٹ اور ٹول کا استعمال | TAU بینچ (API تخروپن) | 62–63.5% بمقابلہ جیمنی 2.5، کلاڈ 4 |
| مکالمہ اور معاون | ملٹی چیلنج: 44.7% | Claude 4، DeepSeek‑R1 سے مماثل ہے۔ |
| حقیقت QA | سادہ QA: 18.5% | مستقبل کی بہتری کے لیے علاقہ |
نوٹ: سرکاری MiniMax انکشاف اور آزاد خبروں کی رپورٹس سے فیصد اور بینچ مارکس
تکنیکی اختراعات
- ہائبرڈ توجہ اسٹیک: بجلی کی توجہ کارکردگی اور ماڈلنگ کی طاقت کو متوازن کرنے کے لیے پرتیں (لکیری لاگت) وقفے وقفے سے سافٹ میکس اٹینشن (چودھری لیکن زیادہ اظہار خیال) کے ساتھ جڑی ہوئی ہیں۔
- اسپارس ایم او ای روٹنگ: 32 ماہر ماڈیولز؛ ہر ٹوکن کل پیرامیٹرز کا صرف 10% چالو کرتا ہے، صلاحیت کو محفوظ رکھتے ہوئے تخمینہ لاگت کو کم کرتا ہے۔
- CISPO کمک سیکھنا: ایک ناول "کلپڈ IS-ویٹ پالیسی آپٹیمائزیشن" الگورتھم جو سیکھنے کے سگنل میں نایاب لیکن اہم ٹوکنز کو برقرار رکھتا ہے، RL استحکام اور رفتار کو تیز کرتا ہے۔
MiniMax‑M1 کی اوپن ویٹ ریلیز انتہائی طویل سیاق و سباق کو کھولتی ہے، ہر ایک کے لیے اعلی کارکردگی کا تخمینہ—تحقیق اور قابل تعیناتی بڑے پیمانے پر AI کے درمیان فرق کو ختم کرتی ہے۔
شروع
CometAPI ایک متحد REST انٹرفیس فراہم کرتا ہے جو کہ سیکڑوں AI ماڈلز کو جمع کرتا ہے — بشمول ChatGPT فیملی — ایک مستقل اختتامی نقطہ کے تحت، بلٹ ان API-کی مینجمنٹ، استعمال کوٹہ، اور بلنگ ڈیش بورڈز کے ساتھ۔ متعدد وینڈر یو آر ایل اور اسناد کو جگانے کے بجائے۔
شروع کرنے کے لیے، میں ماڈلز کی صلاحیتوں کو دریافت کریں۔ کھیل کے میدان اور مشورہ کریں API گائیڈ تفصیلی ہدایات کے لیے۔ رسائی کرنے سے پہلے، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ ان کیا ہے اور API کلید حاصل کر لی ہے۔
تازہ ترین انٹیگریشن MiniMax‑M1 API جلد ہی CometAPI پر ظاہر ہو گا، اس لیے دیکھتے رہیں!جب تک ہم MiniMax‑M1 ماڈل اپ لوڈ کو حتمی شکل دے رہے ہیں، ہمارے دوسرے ماڈلز کو دیکھیں ماڈلز کا صفحہ یا میں ان کی کوشش کریں AI کھیل کا میدان. CometAPI میں MiniMax کا تازہ ترین ماڈل ہیں۔ Minimax ABAB7-Preview API اور MiniMax Video-01 API رجوع کریں:
