Gemini 2.5 Flash تیز رفتار جوابات فراہم کرنے کے لیے تیار کیا گیا ہے، بغیر آؤٹ پٹ کے معیار پر سمجھوتہ کیے۔ یہ ملٹی موڈل ان پٹس کو سپورٹ کرتا ہے، جن میں متن، تصاویر، آڈیو اور ویڈیو شامل ہیں، جس سے یہ مختلف ایپلیکیشنز کے لیے موزوں بنتا ہے۔ یہ ماڈل Google AI Studio اور Vertex AI جیسے پلیٹ فارمز کے ذریعے دستیاب ہے، جو ڈویلپرز کو مختلف سسٹمز میں ہموار انضمام کے لیے ضروری ٹولز فراہم کرتے ہیں۔
بنیادی معلومات (خصوصیات)
Gemini 2.5 Flash نے Gemini 2.5 فیملی کے اندر اسے ممتاز کرنے والی کئی نمایاں خصوصیات متعارف کرائی ہیں:
- ہائبرڈ استدلال: ڈویلپرز آؤٹ پٹ سے پہلے ماڈل کے داخلی استدلال کے لیے وقف کیے جانے والے ٹوکنز کی تعداد کو باریکی سے قابو کرنے کے لیے thinking_budget پیرامیٹر سیٹ کر سکتے ہیں۔
- Pareto Frontier: لاگت-کارکردگی کے مثالی نقطے پر تعینات، Flash 2.5 ماڈلز میں بہترین قیمت بمقابلہ ذہانت کا تناسب پیش کرتا ہے۔
- ملٹی موڈل سپورٹ: متن، تصاویر، ویڈیو اور آڈیو کو مقامی طور پر پروسیس کرتا ہے، جس سے گفتگو اور تجزیاتی صلاحیتیں مزید بھرپور ہوتی ہیں۔
- 1 ملین-ٹوکن کانٹیکسٹ: بے مثال کانٹیکسٹ لمبائی ایک ہی درخواست میں گہرا تجزیہ اور طویل دستاویز کی سمجھ بوجھ ممکن بناتی ہے۔
ماڈل ورژننگ
Gemini 2.5 Flash نے درج ذیل کلیدی ورژنز سے گزر کر ارتقا کیا ہے:
- gemini-2.5-flash-lite-preview-09-2025: ٹول کی استعمال پذیری میں بہتری: پیچیدہ، کثیر مرحلہ جاتی کاموں پر کارکردگی بہتر، SWE-Bench Verified اسکورز میں 5% اضافہ (48.9% سے 54%)۔ افادیت میں بہتری: reasoning فعال کرنے پر کم ٹوکنز کے ساتھ اعلیٰ معیار آؤٹ پٹ، جس سے لیٹنسی اور لاگت کم ہوتی ہے۔
- Preview 04-17: “thinking” صلاحیت کے ساتھ ارلی ایکسس ریلیز، gemini-2.5-flash-preview-04-17 کے ذریعے دستیاب۔
- Stable General Availability (GA): 17 جون، 2025 سے مستحکم اینڈ پوائنٹ gemini-2.5-flash نے پریویو کی جگہ لے لی، مئی 20 پریویو سے کوئی API تبدیلی کے بغیر پروڈکشن گریڈ قابلِ اعتمادیت یقینی بناتے ہوئے۔
- Deprecation of Preview: پریویو اینڈ پوائنٹس 15 جولائی، 2025 کو بند کرنے کے لیے شیڈول تھے؛ صارفین کو اس تاریخ سے پہلے GA اینڈ پوائنٹ پر مائیگریٹ کرنا ہوگا۔
جولائی 2025 تک، Gemini 2.5 Flash اب عوامی طور پر دستیاب اور مستحکم ہے (gemini-2.5-flash-preview-05-20 سے کوئی تبدیلی نہیں)۔ اگر آپ gemini-2.5-flash-preview-04-17 استعمال کر رہے ہیں، تو موجودہ پریویو قیمتیں ماڈل اینڈ پوائنٹ کی مقررہ ریٹائرمنٹ یعنی 15 جولائی، 2025 تک برقرار رہیں گی، جب اسے بند کر دیا جائے گا۔ آپ عام طور پر دستیاب ماڈل "gemini-2.5-flash" پر مائیگریٹ کر سکتے ہیں۔
زیادہ تیز، زیادہ سستا، زیادہ ذہین:
- ڈیزائن کے مقاصد: کم لیٹنسی + بلند تھروپٹ + کم لاگت؛
- استدلال، ملٹی موڈل پروسیسنگ، اور طویل متن کے کاموں میں مجموعی رفتار میں اضافہ؛
- ٹوکن کے استعمال میں 20–30% کمی، جس سے استدلال کی لاگت میں نمایاں کمی آتی ہے۔
تکنیکی خصوصیات
Input Context Window: زیادہ سے زیادہ 1 ملین ٹوکنز، جس سے وسیع کانٹیکسٹ برقرار رکھا جا سکتا ہے۔
Output Tokens: فی جواب زیادہ سے زیادہ 8,192 ٹوکنز جنریٹ کرنے کی صلاحیت۔
Modalities Supported: متن، تصاویر، آڈیو، اور ویڈیو۔
Integration Platforms: Google AI Studio اور Vertex AI کے ذریعے دستیاب۔
Pricing: مسابقتی ٹوکن پر مبنی قیمت گذاری ماڈل، کم لاگت تعیناتی میں معاون۔
تکنیکی تفصیلات
اندرونی طور پر، Gemini 2.5 Flash ایک ٹرانسفارمر پر مبنی بڑا لسانی ماڈل ہے جو ویب، کوڈ، امیج اور ویڈیو ڈیٹا کے امتزاج پر تربیت یافتہ ہے۔ کلیدی تکنیکی خصوصیات میں شامل ہیں:
ملٹی موڈل ٹریننگ: متعدد موڈیلٹیز کو ہم آہنگ کرنے کے لیے تربیت یافتہ، Flash متن کو تصاویر، ویڈیو یا آڈیو کے ساتھ بے رکاوٹ ملاتا ہے، جیسے ویڈیو سمریزیشن یا آڈیو کیپشننگ جیسے کاموں کے لیے موزوں۔
ڈائنامک تھنکنگ پروسیس: ایک داخلی استدلالی لوپ نافذ کرتا ہے جہاں ماڈل آخری آؤٹ پٹ سے پہلے پیچیدہ پرامپٹس کی منصوبہ بندی اور تقسیم کرتا ہے۔
قابلِ تشکیل Thinking Budgets: thinking_budget کو 0 (بلا استدلال) سے لے کر 24,576 ٹوکنز تک سیٹ کیا جا سکتا ہے، جس سے لیٹنسی اور جواب کے معیار کے درمیان توازن ممکن ہوتا ہے۔
Tool Integration: Grounding with Google Search، Code Execution، URL Context اور Function Calling کو سپورٹ کرتا ہے، جو قدرتی زبان کے پرامپٹس سے براہِ راست حقیقی دنیا کے ایکشنز کو ممکن بناتا ہے۔
بینچ مارک کارکردگی
سخت جانچ میں، Gemini 2.5 Flash نے انڈسٹری کی صفِ اوّل کی کارکردگی دکھائی:
- LMArena Hard Prompts: مشکل Hard Prompts بینچ مارک پر صرف 2.5 Pro کے بعد دوسرا اسکور، جس سے مضبوط کثیر مرحلہ جاتی استدلالی صلاحیتیں ظاہر ہوتی ہیں۔
- MMLU اسکور 0.809: اوسط ماڈل کارکردگی سے بہتر، 0.809 MMLU درستگی، جو وسیع ڈومین علم اور استدلال کی قوت کی عکاس ہے۔
- Latency اور Throughput: 271.4 tokens/sec ڈی کوڈنگ رفتار اور 0.29 s Time-to-First-Token حاصل کرتا ہے، جو لیٹنسی حساس ورک لوڈز کے لیے موزوں ہے۔
- Price-to-Performance Leader: \$0.26/1 M tokens پر، Flash بہت سے حریفوں سے کم لاگت کے ساتھ کلیدی بینچ مارکس پر برابری یا برتری دکھاتا ہے۔
یہ نتائج استدلال، سائنسی فہم، ریاضیاتی مسئلہ حل، کوڈنگ، بصری تعبیر، اور کثیر لسانی قابلیتوں میں Gemini 2.5 Flash کی مسابقتی برتری کی نشان دہی کرتے ہیں:
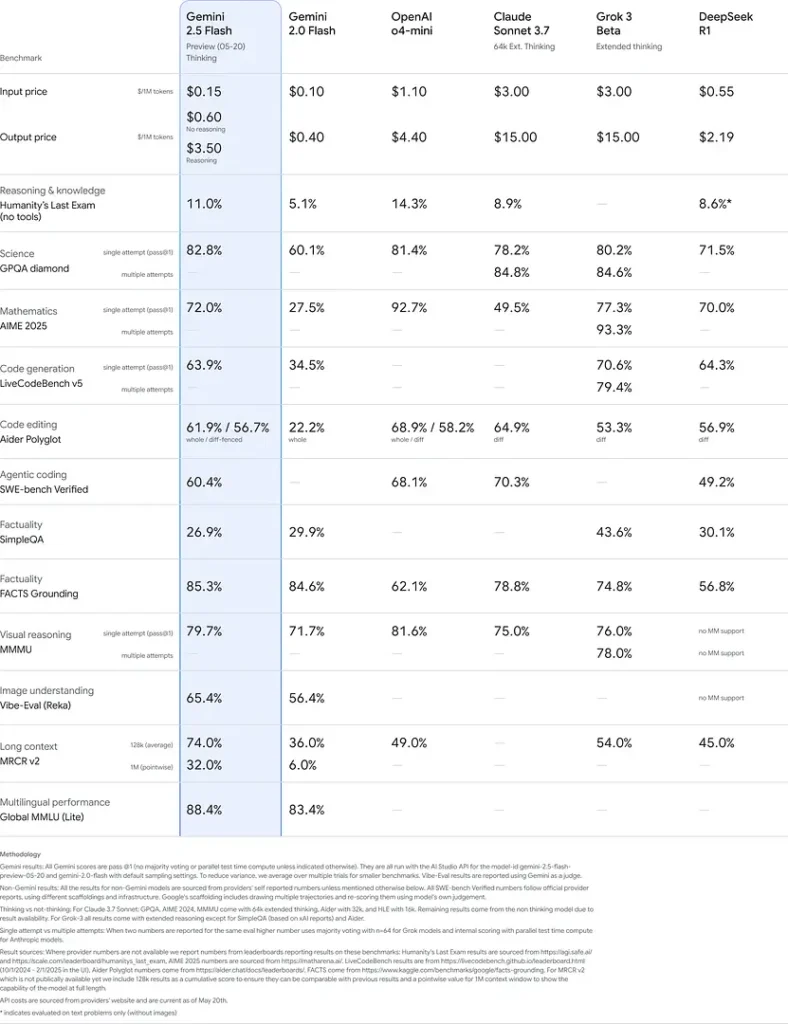
محدودیتیں
طاقتور ہونے کے باوجود، Gemini 2.5 Flash میں کچھ حدود موجود ہیں:
- سیفٹی رسکس: ماڈل میں بعض اوقات “preachy” لہجہ آ سکتا ہے اور خصوصاً کنارے کے کیسز پر قابلِ یقین مگر غلط یا جانب دار آؤٹ پٹس (ہیلوسینیشنز) پیدا ہو سکتی ہیں۔ سخت انسانی نگرانی ضروری رہتی ہے۔
- Rate Limits: API کے استعمال پر ریٹ لمٹس (10 RPM، 250,000 TPM، 250 RPD ڈیفالٹ ٹئیرز پر) لاگو ہیں، جو بیچ پروسیسنگ یا زیادہ حجم والی ایپلیکیشنز پر اثر انداز ہو سکتے ہیں۔
- Intelligence Floor: اگرچہ flash ماڈل کے طور پر غیر معمولی طور پر قابل ہے، پھر بھی انتہائی مطالبہ انگیز ایجنٹک کاموں جیسے ایڈوانسڈ کوڈنگ یا ملٹی ایجنٹ کوآرڈی نیشن پر 2.5 Pro سے کم درست ہے۔
- لاگت کے ٹریڈ آفز: اگرچہ بہترین price-performance پیش کرتا ہے، مگر thinking موڈ کے وسیع استعمال سے مجموعی ٹوکن کھپت بڑھتی ہے، جس سے گہرے استدلال والے پرامپٹس کی لاگت میں اضافہ ہوتا ہے۔