GPT-5.4 Mini کی تکنیکی خصوصیات
| آئٹم | GPT-5.4 Mini (سرکاری معلومات + کراس توثیق سے اندازہ) |
|---|---|
| ماڈل فیملی | GPT-5.4 سیریز (کم لاگت والا “mini” ویریئنٹ) |
| فراہم کنندہ | OpenAI |
| ان پٹ اقسام | متن، تصویر |
| آؤٹ پٹ اقسام | متن |
| کانٹیکسٹ ونڈو | 400,000 ٹوکنز |
| زیادہ سے زیادہ آؤٹ پٹ ٹوکنز | 128,000 ٹوکنز |
| علم کی حد | ~31 مئی، 2024 (mini لائن ایج سے موروثی) |
| منطقی استدلال کی معاونت | ہاں (ہلکا وزن بمقابلہ مکمل GPT-5.4) |
| ٹول سپورٹ | فنکشن کالنگ، ویب سرچ، فائل سرچ، ایجنٹس (GPT-5 فیملی سے اخذ شدہ) |
| پوزیشننگ | ہائی اسپیڈ، کم لاگت near‑frontier ماڈل |
GPT-5.4 Mini کیا ہے؟
GPT-5.4 Mini، GPT-5.4 کا ایک کم لاگت، ہائی اسپیڈ ویریئنٹ ہے جو تاخیر کے لیے حساس اور بڑی مقدار کے ورک لوڈز کے لیے ڈیزائن کیا گیا ہے۔ یہ GPT-5.4 کی معقولیت، کوڈنگ اور ملٹی موڈل صلاحیتوں کا بڑا حصہ ایک چھوٹے، تیز تر ماڈل میں فراہم کرتا ہے جو پروڈکشن اسکیل سسٹمز کے لیے موزوں ہے۔
پچھلے “mini” ماڈلز کے مقابلے میں، GPT-5.4 Mini کو ایک near‑frontier چھوٹا ماڈل سمجھا جاتا ہے، یعنی یہ فلیگ شپ درجے کی کارکردگی کے قریب پہنچتا ہے جبکہ لاگت اور ریسپانس ٹائم کو نمایاں طور پر گھٹا دیتا ہے۔
GPT-5.4 Mini کی کلیدی خصوصیات
- ہائی اسپیڈ انفیرینس: کم تاخیر والی ایپلیکیشنز جیسے چیٹ بوٹس، کوپائلٹس، اور ریئل ٹائم سسٹمز کے لیے بہتر بنایا گیا ہے
- بڑا کانٹیکسٹ ونڈو (400K): طویل دستاویزات، متعدد مراحل کے ورک فلو اور ایجنٹ میموری کی حمایت کرتا ہے
- مضبوط کوڈنگ اور ایجنٹ سپورٹ: ٹول کے استعمال، متعدد مراحل کے استدلال اور تفویض شدہ سب ایجنٹ ٹاسکس کے لیے ڈیزائن کیا گیا ہے
- ملٹی موڈل ان پٹ: زیادہ بھرپور ورک فلو کے لیے متن اور تصویر دونوں ان پٹس قبول کرتا ہے
- کم لاگت والی اسکیلنگ: مضبوط استدلالی صلاحیت برقرار رکھتے ہوئے GPT-5.4 کے مقابلے میں نمایاں طور پر سستا
- ایجنٹ پائپ لائن آپٹمائزیشن: ان ملٹی ماڈل آرکیٹیکچرز کے لیے موزوں جہاں بڑے ماڈلز منصوبہ بندی کرتے ہیں اور mini ماڈلز عمل درآمد کرتے ہیں
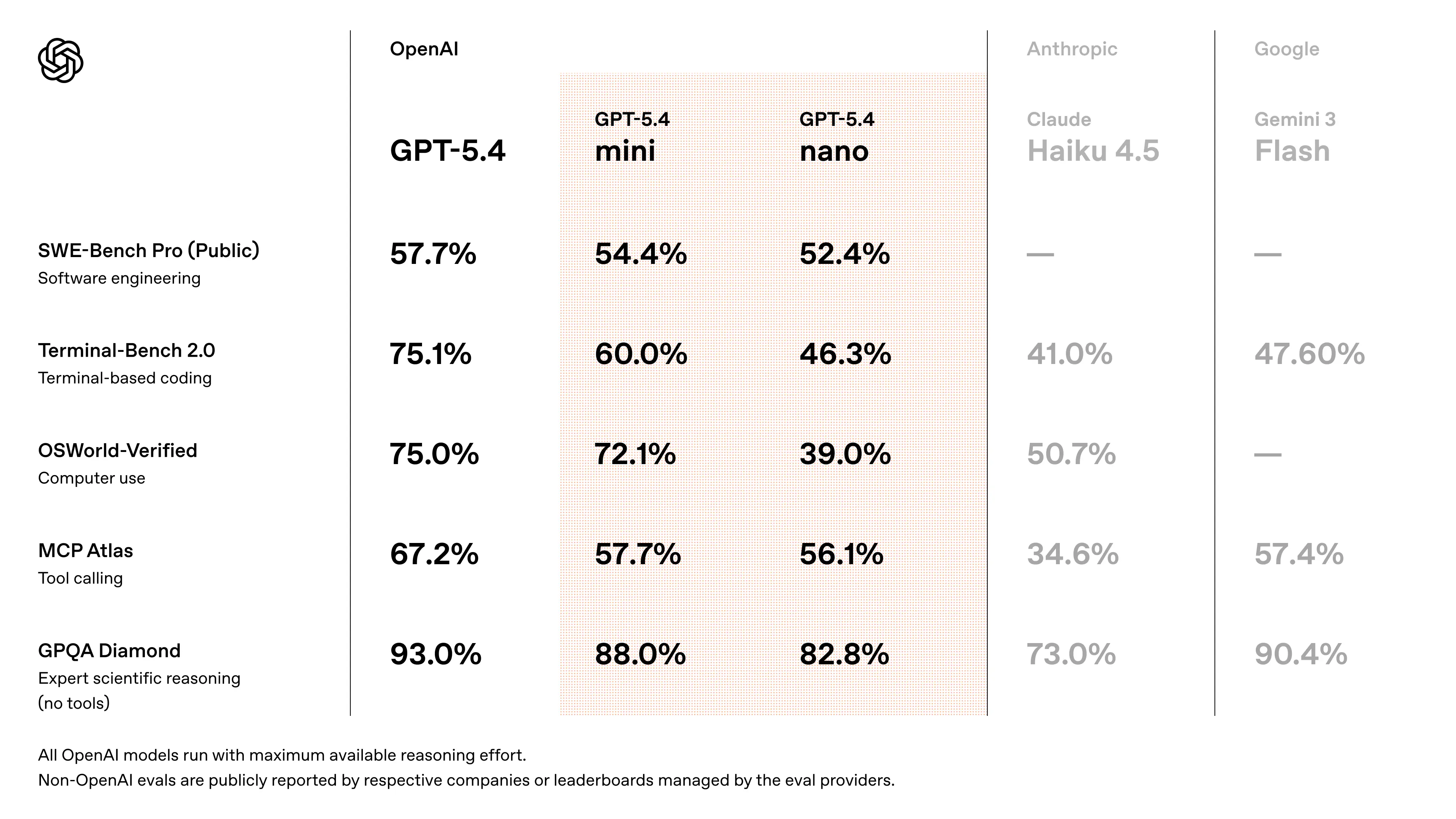
GPT-5.4 Mini کی بینچ مارک کارکردگی
- SWE-Bench طرز کے کوڈنگ ٹاسکس پر GPT-5.4 کی کارکردگی کے قریب پہنچتا ہے (~94–95% فلیگ شپ کارکردگی) (ریلیز مباحثوں سے کراس ویلیڈیٹڈ اندازہ)
- GPT-5 Mini کے مقابلے میں نمایاں بہتریاں:
- استدلال کی درستی
- ٹول کے استعمال کی بھروسہ مندی
- ملٹی موڈل سمجھ
- ایجنٹ ورک فلو اور کوڈنگ بینچ مارکس میں پچھلی “mini” جنریشنز سے بہتر کارکردگی کے لیے ڈیزائن کیا گیا ہے
- رفتار کی پیمائش: ابتدائی API ٹیسٹرز رپورٹ کرتے ہیں کہ GPT-5.4 Mini پر تقریباً ~180–190 ٹوکنز/سیکنڈ حاصل ہوئے (جبکہ پرانے GPT-5 mini ویریئنٹس کے لیے ترجیحی موڈز پر منحصر ہو کر ~55–120 t/s)
👉 کلیدی نکتہ: GPT-5.4 Mini لاگت اور تاخیر کے ایک معمولی حصے پر near‑frontier کارکردگی فراہم کرتا ہے، جس سے یہ اسکیل ایبل سسٹمز کے لیے نہایت موزوں بنتا ہے۔
نمائندہ استعمالات
- کوڈنگ اسسٹنٹس اور ایڈیٹرز (IDE پلگ اِنز، Copilot): تیز رفتار کانٹیکسٹ پارسنگ، کوڈ بیس ایکسپلوریشن، اور فوری کمپلیشنز GPT-5.4 Mini کو ان-ایڈیٹر تجاویز کے لیے مثالی بناتی ہیں جہاں پہلے ٹوکن تک وقت اہم ہوتا ہے۔ GitHub Copilot ایک ابتدائی انٹیگریشن ہے۔
- سب ایجنٹس/تفویض شدہ ورکرز: جہاں ایک ماسٹر ایجنٹ مختصر، تیز کام (فارمیٹنگ، چھوٹے استدلالی مراحل، grep-انداز تلاشیں) کسی سستے، تیز ورکر کو سونپتا ہے۔ OpenAI ان کرداروں کے لیے mini/nano کو متعین کرتا ہے۔
- ہائی والیوم API آٹومیشن: بلک کوڈ جنریشن، خودکار ٹکٹ ٹرائیاج، اور بڑے پیمانے پر لاگ سمریزیشن جہاں فی کال لاگت اور تاخیر بنیادی حدود ہوتی ہیں۔ کمیونٹی تھروپٹ نمبرز mini کے لیے نمایاں عملی فوائد ظاہر کرتے ہیں۔
- ٹول-ریپنگ اور ٹول چینز: تیز ٹول کالز جہاں ماڈل بیرونی ٹولز (search، grep، run tests) کو منظم کرتا ہے اور مختصر، قابلِ عمل آؤٹ پٹس واپس کرتا ہے۔ GPT-5.4 فیملی میں بہتر “computer use” صلاحیتیں شامل ہیں۔
GPT-5.4 Mini API تک کیسے رسائی حاصل کریں
مرحلہ 1: API Key کے لیے سائن اپ کریں
cometapi.com میں لاگ اِن کریں۔ اگر آپ ہمارے صارف نہیں ہیں تو پہلے رجسٹر کریں۔ اپنے CometAPI کنسول میں سائن اِن کریں۔ انٹرفیس کی رسائی کے لیے API key حاصل کریں۔ پرسنل سینٹر میں API ٹوکن کے سامنے “Add Token” پر کلک کریں، ٹوکن کلید حاصل کریں: sk-xxxxx اور سبمٹ کریں۔

مرحلہ 2: GPT-5.4 Mini API کو درخواستیں بھیجیں
“gpt-5.4-mini” اینڈ پوائنٹ منتخب کریں تاکہ API ریکویسٹ بھیجی جا سکے اور ریکویسٹ باڈی سیٹ کریں۔ ریکویسٹ میتھڈ اور ریکویسٹ باڈی ہماری ویب سائٹ کی API ڈاک سے حاصل کیے جا سکتے ہیں۔ آپ کی سہولت کے لیے ہماری ویب سائٹ Apifox ٹیسٹ بھی فراہم کرتی ہے۔ اپنے اکاؤنٹ کی اصل CometAPI کلید کے ساتھ <YOUR_API_KEY> کو بدلیں۔ بیس URL Chat Completions اور Responses ہے۔
اپنا سوال یا درخواست content فیلڈ میں درج کریں—اسی پر ماڈل جواب دے گا۔ تیار شدہ جواب حاصل کرنے کے لیے API ریسپانس کو پروسیس کریں۔
مرحلہ 3: نتائج حاصل کریں اور تصدیق کریں
تیار شدہ جواب حاصل کرنے کے لیے API ریسپانس کو پروسیس کریں۔ پروسیسنگ کے بعد، API ٹاسک کی اسٹیٹس اور آؤٹ پٹ ڈیٹا فراہم کرتی ہے۔