GPT-5.4 Mini کی تکنیکی خصوصیات
| آئٹم | GPT-5.4 Mini (سرکاری معلومات + باہمی تصدیق سے اندازاً) |
|---|---|
| ماڈل فیملی | GPT-5.4 سیریز (لاگت مؤثر “mini” ویریئنٹ) |
| فراہم کنندہ | OpenAI |
| ان پٹ کی اقسام | متن، تصویر |
| آؤٹ پٹ کی اقسام | متن |
| کانٹیکسٹ ونڈو | 400,000 ٹوکنز |
| زیادہ سے زیادہ آؤٹ پٹ ٹوکنز | 128,000 ٹوکنز |
| علمی حدِ تاریخ | ~31 مئی 2024 (mini lineage سے وراثت میں) |
| ریزننگ سپورٹ | ہاں (مکمل GPT-5.4 کے مقابلے میں ہلکی) |
| ٹول سپورٹ | Function calling, web search, file search, agents (GPT-5 فیملی سے اخذ کردہ) |
| پوزیشننگ | تیز رفتار، لاگت مؤثر، near-frontier ماڈل |
GPT-5.4 Mini کیا ہے؟
GPT-5.4 Mini، GPT-5.4 کا ایک لاگت مؤثر اور تیز رفتار ویریئنٹ ہے، جو کم تاخیر اور زیادہ حجم والے ورک لوڈز کے لیے ڈیزائن کیا گیا ہے۔ یہ GPT-5.4 کی ریزننگ، کوڈنگ، اور ملٹی موڈل صلاحیتوں کا ایک نمایاں حصہ ایک چھوٹے اور زیادہ تیز ماڈل میں فراہم کرتا ہے، جسے پروڈکشن-اسکیل سسٹمز کے لیے بہتر بنایا گیا ہے۔
پہلے کے “mini” ماڈلز کے مقابلے میں، GPT-5.4 Mini کو ایک near-frontier small model کے طور پر پیش کیا گیا ہے، یعنی یہ لاگت اور رسپانس ٹائم کو نمایاں طور پر کم کرتے ہوئے flagship-سطح کی کارکردگی کے قریب پہنچتا ہے۔
GPT-5.4 Mini کی اہم خصوصیات
- تیز رفتار inference: کم تاخیر والی ایپلیکیشنز جیسے chatbots، copilots، اور real-time systems کے لیے بہتر بنایا گیا
- بڑی context window (400K): طویل دستاویزات، کثیر مرحلہ وار workflows، اور agent memory کی سپورٹ
- مضبوط coding اور agent support: ٹول استعمال، کثیر مرحلہ وار reasoning، اور delegated sub-agent tasks کے لیے ڈیزائن کیا گیا
- ملٹی موڈل ان پٹ: زیادہ بھرپور workflows کے لیے متن اور تصویر دونوں ان پٹس قبول کرتا ہے
- لاگت مؤثر scaling: مضبوط reasoning صلاحیت برقرار رکھتے ہوئے GPT-5.4 سے نمایاں طور پر سستا
- Agent pipeline optimization: ایسی multi-model architectures کے لیے موزوں جہاں بڑے ماڈلز منصوبہ بندی کریں اور mini ماڈلز عمل درآمد کریں
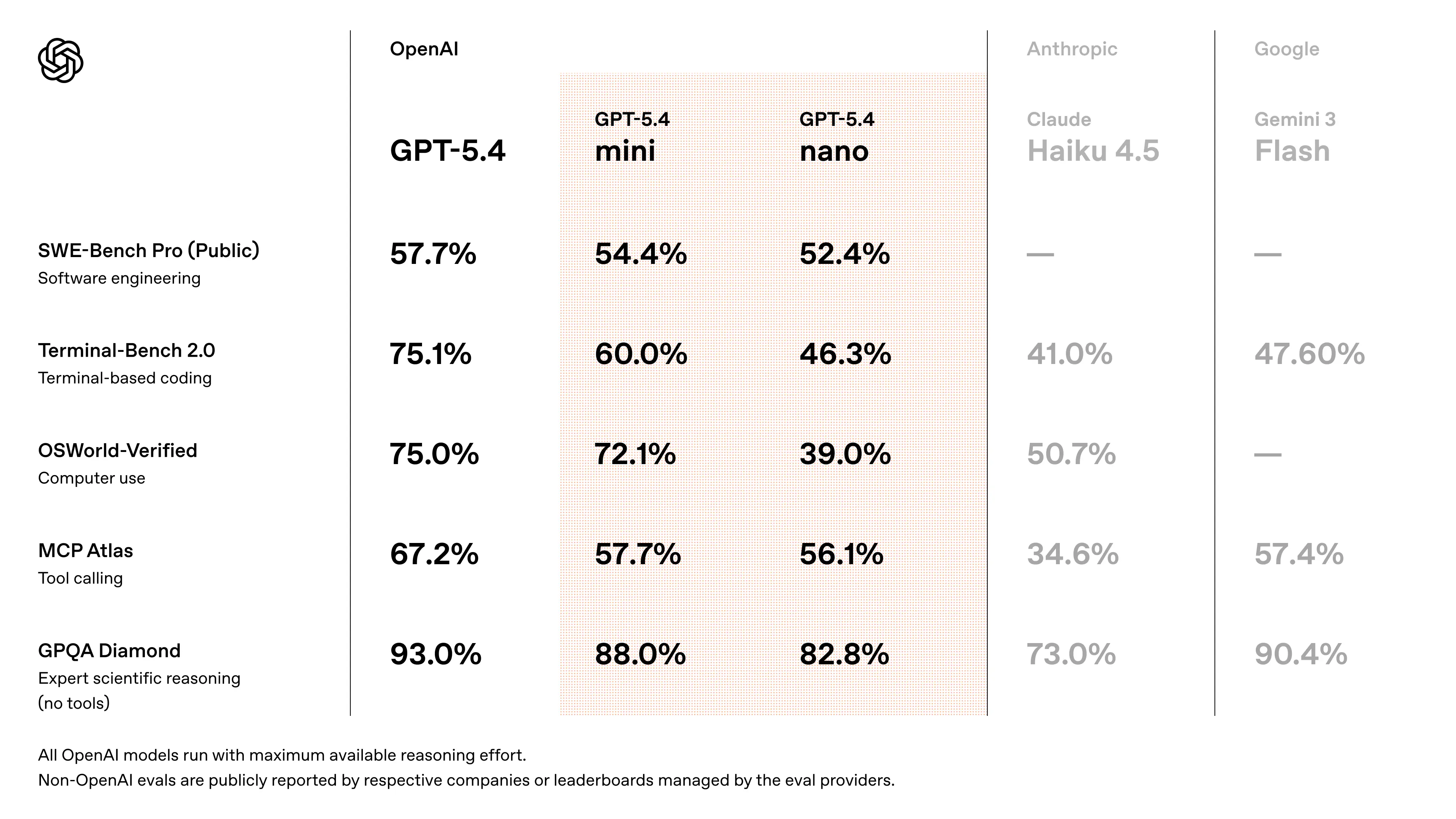
GPT-5.4 Mini کی benchmark کارکردگی
- SWE-Bench طرز کے coding tasks پر GPT-5.4 کی کارکردگی کے قریب پہنچتا ہے (~94–95% flagship performance) (ریلیز مباحث سے باہمی تصدیق شدہ اندازہ)
- GPT-5 Mini کے مقابلے میں نمایاں بہتری:
- reasoning accuracy
- tool usage reliability
- multimodal understanding
- agent workflows اور coding benchmarks میں پچھلی “mini” نسلوں سے بہتر کارکردگی کے لیے ڈیزائن کیا گیا
- speed measurements: ابتدائی API testers نے GPT-5.4 Mini پر ~180–190 tokens/sec رپورٹ کیے ہیں (جبکہ پرانے GPT-5 mini variants میں priority modes کے لحاظ سے ~55–120 t/s)۔
👉 اہم نکتہ: GPT-5.4 Mini کم لاگت اور کم تاخیر پر near-frontier کارکردگی فراہم کرتا ہے، جو اسے scalable systems کے لیے موزوں بناتا ہے۔
نمائندہ استعمال کے کیسز
- Coding assistants اور editors (IDE plugins, Copilot): تیز context parsing، codebase exploration، اور فوری completions، GPT-5.4 Mini کو in-editor suggestions کے لیے مثالی بناتے ہیں جہاں time-to-first-token اہم ہوتا ہے۔ GitHub Copilot ایک ابتدائی انضمام ہے۔
- Subagents / delegated workers: جہاں ایک master agent مختصر اور تیز کام (formatting، چھوٹے reasoning steps، grep-style searches) ایک سستے اور تیز worker کو سونپتا ہے۔ OpenAI ان کرداروں کے لیے mini/nano کو پوزیشن کرتا ہے۔
- High-volume API automation: بڑے پیمانے پر code generation، automated ticket triage، اور log summarization، جہاں فی کال لاگت اور تاخیر بنیادی رکاوٹیں ہوں۔ کمیونٹی throughput اعداد و شمار mini کے لیے نمایاں آپریشنل فوائد کی نشاندہی کرتے ہیں۔
- Tool-wrapping اور toolchains: تیز tool calls جہاں ماڈل بیرونی tools (search، grep، run tests) کو orchestrate کرتا ہے اور مختصر، قابلِ عمل outputs واپس کرتا ہے۔ GPT-5.4 family میں بہتر “computer use” صلاحیتیں شامل ہیں۔
GPT-5.4 Mini API تک رسائی کیسے حاصل کریں
مرحلہ 1: API Key کے لیے سائن اپ کریں
cometapi.com میں لاگ ان کریں۔ اگر آپ ابھی تک ہمارے صارف نہیں ہیں تو پہلے رجسٹر کریں۔ اپنے CometAPI console میں سائن ان کریں۔ انٹرفیس کی رسائی اسناد API key حاصل کریں۔ ذاتی مرکز میں API token کے حصے میں “Add Token” پر کلک کریں، token key حاصل کریں: sk-xxxxx اور submit کریں۔

مرحلہ 2: GPT-5.4 Mini API کو Requests بھیجیں
API request بھیجنے کے لیے “gpt-5.4-mini” endpoint منتخب کریں اور request body سیٹ کریں۔ request method اور request body ہماری ویب سائٹ کے API doc سے حاصل کیے جاتے ہیں۔ ہماری ویب سائٹ آپ کی سہولت کے لیے Apifox test بھی فراہم کرتی ہے۔ <YOUR_API_KEY> کو اپنے اکاؤنٹ سے حاصل کردہ اصل CometAPI key سے بدل دیں۔ base url یہ ہیں: Chat Completions اور Responses۔
اپنا سوال یا request content field میں درج کریں—یہی وہ چیز ہے جس کا ماڈل جواب دے گا۔ تیار کردہ جواب حاصل کرنے کے لیے API response کو process کریں۔
مرحلہ 3: نتائج حاصل کریں اور تصدیق کریں
تیار کردہ جواب حاصل کرنے کے لیے API response کو process کریں۔ processing کے بعد، API task status اور output data کے ساتھ جواب دیتا ہے۔