

مصنوعی ذہانت کے تیزی سے ارتقا پذیر منظر نامے میں، 2025 نے بڑے لینگویج ماڈلز (LLMs) میں نمایاں پیش رفت دیکھی ہے۔ سب سے آگے علی بابا کے Qwen2.5، DeepSeek کے V3 اور R1 ماڈلز، اور OpenAI کے ChatGPT ہیں۔ ان میں سے ہر ایک ماڈل میز پر انوکھی صلاحیتیں اور اختراعات لاتا ہے۔ یہ مضمون Qwen2.5 کے ارد گرد ہونے والی تازہ ترین پیش رفتوں پر روشنی ڈالتا ہے، اس کی خصوصیات اور کارکردگی کا DeepSeek اور ChatGPT کے ساتھ موازنہ کرتا ہے تاکہ یہ تعین کیا جا سکے کہ فی الحال کون سا ماڈل AI کی دوڑ میں آگے ہے۔
Qwen2.5 کیا ہے؟
جائزہ
Qwen 2.5 علی بابا کلاؤڈ کا تازہ ترین گھنے، ڈیکوڈر کے لیے صرف بڑی زبان کا ماڈل ہے، جو 0.5B سے 72B پیرامیٹرز تک کے متعدد سائز میں دستیاب ہے۔ یہ ہدایات کی پیروی کرنے، ساختی نتائج (مثال کے طور پر، JSON، میزیں)، کوڈنگ، اور ریاضی کے مسائل کو حل کرنے کے لیے موزوں ہے۔ 29 سے زیادہ زبانوں کے لیے تعاون اور 128K ٹوکنز کے سیاق و سباق کی لمبائی کے ساتھ، Qwen2.5 کو کثیر لسانی اور ڈومین کے لیے مخصوص ایپلی کیشنز کے لیے ڈیزائن کیا گیا ہے۔
اہم خصوصیات
- بہزبانی سپورٹ: 29 سے زیادہ زبانوں کو سپورٹ کرتا ہے، عالمی صارف کی بنیاد کو پورا کرتا ہے۔
- توسیعی سیاق و سباق کی لمبائی: 128K ٹوکن تک ہینڈل کرتا ہے، طویل دستاویزات اور بات چیت کی پروسیسنگ کو فعال کرتا ہے۔
- خصوصی متغیرات: پروگرامنگ کے کاموں کے لیے Qwen2.5-Coder اور ریاضی کے مسائل حل کرنے کے لیے Qwen2.5-Math جیسے ماڈلز شامل ہیں۔
- رسائی: ہیگنگ فیس، گٹ ہب، اور ایک نئے شروع کردہ ویب انٹرفیس جیسے پلیٹ فارمز کے ذریعے دستیاب ہے۔ chat.qwenlm.ai.
مقامی طور پر Qwen 2.5 کا استعمال کیسے کریں؟
ذیل کے لیے ایک قدم بہ قدم گائیڈ ہے۔ 7 بی چیٹ چوکی بڑے سائز صرف GPU کی ضروریات میں مختلف ہوتے ہیں۔
1. ہارڈ ویئر کی شرائط
| ماڈل | 8 بٹ کے لیے vRAM | 4 بٹ (QLoRA) کے لیے vRAM | ڈسک کا سائز |
|---|---|---|---|
| Qwen 2.5‑7B | 14 جی بی | 10 جی بی | 13 جی بی |
| Qwen 2.5‑14B | 26 جی بی | 18 جی بی | 25 جی بی |
ایک واحد RTX 4090 (24 GB) مکمل 7 بٹ درستگی پر 16 B تخمینہ کے لیے کافی ہے۔ دو ایسے کارڈز یا CPU آف لوڈ پلس کوانٹائزیشن 14 B کو سنبھال سکتے ہیں۔
2. تنصیب
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. فوری تخمینہ اسکرپٹ
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
۔ trust_remote_code=True جھنڈا درکار ہے کیونکہ کیوین اپنی مرضی کے مطابق بھیجتا ہے۔ روٹری پوزیشن ایمبیڈنگ لپیٹ
4. LoRA کے ساتھ فائن ٹیوننگ
پیرامیٹر سے موثر LoRA اڈاپٹر کی بدولت آپ Qwen کو ~50 K ڈومین پیئرز پر خصوصی تربیت دے سکتے ہیں (کہیں، میڈیکل) ایک 24 GB GPU پر چار گھنٹے سے کم وقت میں:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
نتیجے میں اڈاپٹر فائل (~ 120 MB) کو دوبارہ ضم کیا جا سکتا ہے یا مطالبہ پر لوڈ کیا جا سکتا ہے۔
اختیاری: Qwen 2.5 کو بطور API چلائیں۔
CometAPI کئی سرکردہ AI ماڈلز کے APIs کے لیے ایک مرکزی مرکز کے طور پر کام کرتا ہے، جس سے متعدد API فراہم کنندگان کے ساتھ الگ الگ مشغول ہونے کی ضرورت ختم ہوتی ہے۔ CometAPI Qwen API کو مربوط کرنے میں آپ کی مدد کے لیے سرکاری قیمت سے کہیں کم قیمت پیش کرتا ہے، اور آپ کو رجسٹر کرنے اور لاگ ان کرنے کے بعد اپنے اکاؤنٹ میں $1 ملیں گے! CometAPI کو رجسٹر کرنے اور تجربہ کرنے میں خوش آمدید۔ Qwen 2.5 کو ایپلی کیشنز میں شامل کرنے کے لیے تیار کرنے والوں کے لیے:
مرحلہ 1: ضروری لائبریریاں انسٹال کریں۔:
bash
pip install requests
مرحلہ 2: API کلید حاصل کریں۔
- پر تشریف لے جائیں CometAPI.
- اپنے CometAPI اکاؤنٹ سے سائن ان کریں۔
- منتخب کریں ڈیش بورڈ.
- "API کلید حاصل کریں" پر کلک کریں اور اپنی کلید بنانے کے لیے اشارے پر عمل کریں۔
3 مرحلہ: API کالز کو لاگو کریں۔
Qwen 2.5.Replace کے لیے درخواستیں کرنے کے لیے API اسناد کا استعمال کریں۔ آپ کے اکاؤنٹ سے اپنی اصل CometAPI کلید کے ساتھ۔
مثال کے طور پر، ازگر میں:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
یہ انضمام مختلف ایپلی کیشنز میں Qwen 2.5 کی صلاحیتوں کو بغیر کسی رکاوٹ کے شامل کرنے کی اجازت دیتا ہے، فعالیت اور صارف کے تجربے کو بڑھاتا ہے۔ “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” API کی درخواست بھیجنے اور درخواست کا باڈی سیٹ کرنے کے لیے اینڈ پوائنٹ۔ درخواست کا طریقہ اور درخواست کا باڈی ہماری ویب سائٹ API دستاویز سے حاصل کی گئی ہے۔ ہماری ویب سائٹ آپ کی سہولت کے لیے Apifox ٹیسٹ بھی فراہم کرتی ہے۔
ملاحظہ کیجیے Qwen 2.5 Max API انضمام کی تفصیلات کے لیے۔CometAPI نے تازہ ترین اپ ڈیٹ کیا ہے۔ QwQ-32B APIComet API میں ماڈل کی مزید معلومات کے لیے براہ کرم دیکھیں API دستاویز.
بہترین طریقے اور تجاویز
| منظر نامے | سفارش |
|---|---|
| طویل دستاویز سوال و جواب | ≤16 K ٹوکنز میں حصئوں کا حصہ بنائیں اور تاخیر کو کم کرنے کے لیے 100 K سیاق و سباق کے بجائے بازیافت کے بڑھے ہوئے اشارے استعمال کریں۔ |
| سٹرکچرڈ آؤٹ پٹ | سسٹم میسج کو اس کے ساتھ لگائیں: You are an AI that strictly outputs JSON. Qwen 2.5 کی الائنمنٹ ٹریننگ محدود نسل میں بہترین ہے۔ |
| کوڈ کی تکمیل۔ | سیٹ کریں temperature=0.0 اور top_p=1.0 عزم کو زیادہ سے زیادہ کرنے کے لیے، پھر ایک سے زیادہ بیم کا نمونہ (num_return_sequences=4درجہ بندی کے لیے۔ |
| سیفٹی فلٹرنگ | Alibaba کے اوپن سورس "Qwen-Guardrails" regex بنڈل یا OpenAI کا ٹیکسٹ-ماڈریشن-004 کو پہلے پاس کے طور پر استعمال کریں۔ |
Qwen 2.5 کی معلوم حدود
- فوری انجیکشن حساسیت۔ بیرونی آڈٹ Qwen 18‑VL پر 2.5% کی جیل بریک کامیابی کی شرح دکھاتے ہیں — ایک یاد دہانی کہ سراسر ماڈل سائز مخالف ہدایات کے خلاف حفاظتی ٹیکوں نہیں کرتا ہے۔
- غیر لاطینی OCR شور۔ جب بصارت کی زبان کے کاموں کے لیے ٹھیک بنایا جاتا ہے، تو ماڈل کی آخر سے آخر تک پائپ لائن بعض اوقات روایتی بمقابلہ آسان چینی گلفوں کو الجھا دیتی ہے، جس کے لیے ڈومین کے لیے مخصوص اصلاحی تہوں کی ضرورت ہوتی ہے۔
- GPU میموری کلف 128 K پر۔ FlashAttention‑2 RAM کو آف سیٹ کرتا ہے، لیکن 72 K ٹوکنز میں 128 B گھنے فارورڈ پاس اب بھی >120 GB vRAM کا مطالبہ کرتا ہے۔ پریکٹیشنرز کو ونڈو-اٹینڈ یا KV-کیچ کرنا چاہیے۔
روڈ میپ اور کمیونٹی ایکو سسٹم
کیوین ٹیم نے اشارہ دیا ہے۔ Qwen 3.0، ایک ہائبرڈ روٹنگ بیک بون (Dense + MoE) کو نشانہ بنانا اور متحد اسپیچ-وژن-ٹیکسٹ پری ٹریننگ۔ دریں اثنا، ماحولیاتی نظام پہلے سے ہی میزبانی کرتا ہے:
- Q- ایجنٹ - پالیسی کے طور پر Qwen 2.5-14B کا استعمال کرتے ہوئے ایک ReAct-سٹائل چین-آف-تھٹ ایجنٹ۔
- چینی مالیاتی الپاکا - Qwen2.5‑7B پر ایک LoRA 1 M ریگولیٹری فائلنگ کے ساتھ تربیت یافتہ ہے۔
- انٹرپریٹر پلگ ان کھولیں۔ - VS کوڈ میں مقامی Qwen چیک پوائنٹ کے لیے GPT-4 کو تبدیل کرتا ہے۔
چیک پوائنٹس، اڈاپٹرز اور ایویلیویشن ہارنیسز کی مسلسل اپ ڈیٹ فہرست کے لیے ہگنگ فیس "Qwen2.5 کلیکشن" کا صفحہ دیکھیں۔
تقابلی تجزیہ: Qwen2.5 بمقابلہ DeepSeek اور ChatGPT
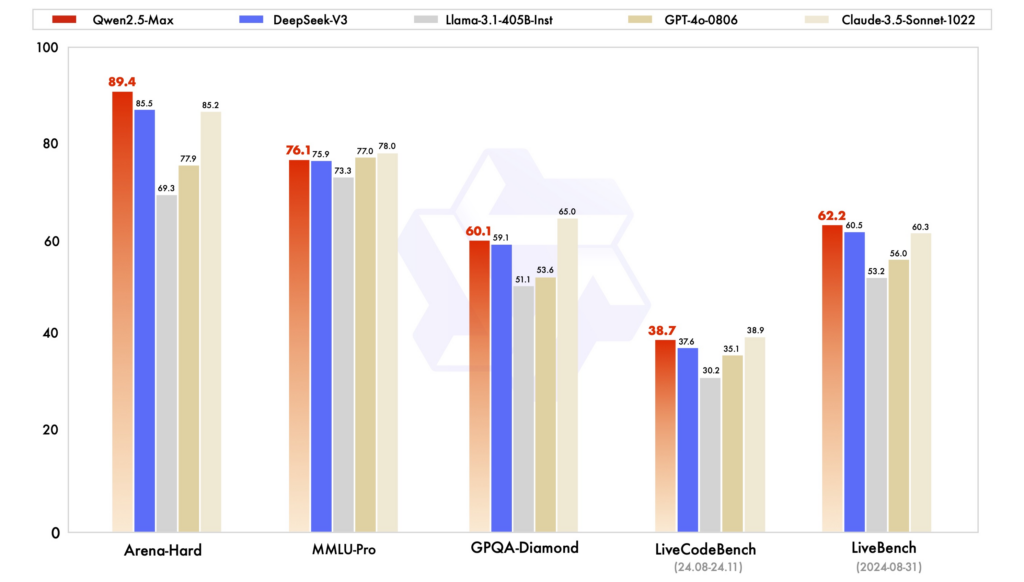
کارکردگی کے معیارات: مختلف جائزوں میں، Qwen2.5 نے ان کاموں میں مضبوط کارکردگی کا مظاہرہ کیا ہے جن میں استدلال، کوڈنگ، اور کثیر لسانی سمجھ کی ضرورت ہوتی ہے۔ DeepSeek-V3، اپنے MoE فن تعمیر کے ساتھ، کم کمپیوٹیشنل وسائل کے ساتھ اعلی کارکردگی پیش کرتے ہوئے، کارکردگی اور اسکیل ایبلٹی میں بہترین ہے۔ ChatGPT ایک مضبوط ماڈل بنی ہوئی ہے، خاص طور پر عام مقصد کی زبان کے کاموں میں۔
کارکردگی اور لاگت: ڈیپ سیک کے ماڈل اپنی لاگت سے موثر تربیت اور تخمینہ کے لیے قابل ذکر ہیں، صرف ضروری پیرامیٹرز کو فی ٹوکن فعال کرنے کے لیے MoE فن تعمیر کا فائدہ اٹھاتے ہیں۔ Qwen2.5، گھنے ہونے کے باوجود، مخصوص کاموں کے لیے کارکردگی کو بہتر بنانے کے لیے خصوصی متغیرات پیش کرتا ہے۔ ChatGPT کی تربیت میں کافی کمپیوٹیشنل وسائل شامل تھے، جو اس کے آپریشنل اخراجات کی عکاسی کرتے ہیں۔
رسائی اور اوپن سورس کی دستیابی: Qwen2.5 اور DeepSeek نے اوپن سورس کے اصولوں کو مختلف ڈگریوں تک قبول کیا ہے، جس کے ماڈل GitHub اور Hugging Face جیسے پلیٹ فارمز پر دستیاب ہیں۔ Qwen2.5 کا ایک ویب انٹرفیس کا حالیہ آغاز اس کی رسائی کو بڑھاتا ہے۔ چیٹ جی پی ٹی، اگرچہ اوپن سورس نہیں ہے، اوپن اے آئی کے پلیٹ فارم اور انضمام کے ذریعے وسیع پیمانے پر قابل رسائی ہے۔
نتیجہ
Qwen 2.5 کے درمیان ایک میٹھی جگہ پر بیٹھا ہے۔ بند ویٹ پریمیم خدمات اور مکمل طور پر کھلے شوق کے ماڈل. اجازت دینے والے لائسنسنگ، کثیر لسانی طاقت، طویل سیاق و سباق کی اہلیت اور پیرامیٹر اسکیلز کی ایک وسیع رینج کا امتزاج اسے تحقیق اور پیداوار دونوں کے لیے ایک زبردست بنیاد بناتا ہے۔
جیسا کہ اوپن سورس LLM زمین کی تزئین کی دوڑیں آگے ہیں، Qwen پروجیکٹ یہ ظاہر کرتا ہے کہ شفافیت اور کارکردگی ایک ساتھ رہ سکتی ہے۔. ڈویلپرز، ڈیٹا سائنسدانوں اور پالیسی سازوں کے لیے یکساں طور پر، Qwen 2.5 میں مہارت حاصل کرنا ایک زیادہ تکثیری، اختراعی دوستانہ AI مستقبل میں سرمایہ کاری ہے۔