

On November 19–20, 2025 OpenAI نے دو باہم متعلق مگر الگ اپ گریڈز جاری کیے: GPT-5.1-Codex-Max، Codex کے لیے ایک نیا agentic coding model، جو long-horizon coding، token efficiency، اور “compaction” پر زور دیتا ہے تاکہ multi-window sessions کو برقرار رکھا جا سکے؛ اور GPT-5.1 Pro، ChatGPT کا ایک updated Pro-tier model، جسے complex اور professional کام میں زیادہ واضح اور زیادہ قابل جواب دینے کے لیے tuned کیا گیا ہے۔
GPT-5.1-Codex-Max کیا ہے اور یہ کس مسئلے کو حل کرنے کی کوشش کر رہا ہے؟
GPT-5.1-Codex-Max، OpenAI کا ایک specialized Codex model ہے جسے ایسے coding workflows کے لیے tuned کیا گیا ہے جنہیں مسلسل، long-horizon reasoning اور execution درکار ہو۔ جہاں عام models بہت طویل contexts سے الجھ سکتے ہیں — مثال کے طور پر multi-file refactors، complex agent loops، یا persistent CI/CD tasks — وہاں Codex-Max کو اس طرح ڈیزائن کیا گیا ہے کہ یہ multiple context windows کے درمیان session state کو خودکار طور پر compact اور manage کرے، تاکہ جب ایک ہی project ہزاروں بلکہ اس سے بھی زیادہ tokens پر پھیل جائے تو یہ مربوط انداز میں کام جاری رکھ سکے۔ OpenAI کے مطابق Codex-Max اس سمت میں اگلا قدم ہے کہ code-capable agents کو extended engineering work کے لیے واقعی مفید بنایا جا سکے۔
GPT-5.1-Codex-Max کیا ہے اور یہ کس مسئلے کو حل کرنے کی کوشش کر رہا ہے؟
GPT-5.1-Codex-Max، OpenAI کا ایک specialized Codex model ہے جسے ایسے coding workflows کے لیے tuned کیا گیا ہے جنہیں مسلسل، long-horizon reasoning اور execution درکار ہو۔ جہاں عام models بہت طویل contexts سے الجھ سکتے ہیں — مثال کے طور پر multi-file refactors، complex agent loops، یا persistent CI/CD tasks — وہاں Codex-Max کو اس طرح ڈیزائن کیا گیا ہے کہ یہ multiple context windows کے درمیان session state کو خودکار طور پر compact اور manage کرے، تاکہ جب ایک ہی project ہزاروں بلکہ اس سے بھی زیادہ tokens پر پھیل جائے تو یہ مربوط انداز میں کام جاری رکھ سکے۔
OpenAI نے اسے “development cycle کے ہر مرحلے پر زیادہ تیز، زیادہ ذہین، اور زیادہ token-efficient” قرار دیا ہے، اور واضح طور پر کہا ہے کہ Codex surfaces میں اسے GPT-5.1-Codex کے default model کے طور پر replace کرنے کا ارادہ ہے۔
Feature snapshot
- Multi-window continuity کے لیے compaction: critical context کو prune اور preserve کرتا ہے تاکہ millions of tokens اور گھنٹوں تک مربوط انداز میں کام جاری رکھا جا سکے۔ 0
- GPT-5.1-Codex کے مقابلے میں بہتر token efficiency: بعض code benchmarks پر اسی نوعیت کی reasoning effort کے لیے ~30% تک کم thinking tokens۔
- Long-horizon agentic durability: اندرونی مشاہدات کے مطابق multi-hour/multi-day agent loops کو برقرار رکھ سکتا ہے (OpenAI نے >24-hour internal runs دستاویزی طور پر بیان کیے ہیں)۔
- Platform integrations: آج Codex CLI، IDE extensions، cloud، اور code review tools میں دستیاب ہے؛ API access بعد میں آئے گا۔
- Windows environment support: OpenAI نے خاص طور پر نوٹ کیا ہے کہ Codex workflows میں پہلی بار Windows supported ہے، جس سے حقیقی دنیا میں developers کی پہنچ وسیع ہوتی ہے۔
یہ competing products کے مقابلے میں کیسا ہے (مثلاً GitHub Copilot، دیگر coding AIs)؟
GPT-5.1-Codex-Max کو per-request completion tools کے مقابلے میں زیادہ autonomous، long-horizon collaborator کے طور پر پیش کیا جا رہا ہے۔ جہاں Copilot اور اسی نوعیت کے assistants editor کے اندر near-term completions میں مہارت رکھتے ہیں، وہاں Codex-Max کی طاقت multi-step tasks کو orchestrate کرنے، sessions کے درمیان coherent state برقرار رکھنے، اور ایسے workflows کو سنبھالنے میں ہے جنہیں planning، testing، اور iteration درکار ہو۔ البتہ اکثر teams کے لیے بہترین طریقہ hybrid ہوگا: complex automation اور sustained agent tasks کے لیے Codex-Max استعمال کریں، اور line-level completions کے لیے lighter-weight assistants۔
GPT-5.1-Codex-Max کیسے کام کرتا ہے؟
“Compaction” کیا ہے اور یہ long-running work کو کیسے ممکن بناتا ہے؟
ایک مرکزی technical advance compaction ہے—یہ ایک internal mechanism ہے جو session history کو prune کرتا ہے مگر context کے اہم حصوں کو محفوظ رکھتا ہے تاکہ model multiple context windows میں مربوط انداز میں کام جاری رکھ سکے۔ عملی طور پر اس کا مطلب یہ ہے کہ context limit کے قریب پہنچنے والی Codex sessions کو compact کر دیا جائے گا (پرانے یا کم اہم tokens کو summarize/preserve کیا جائے گا) تاکہ agent کے پاس ایک fresh window ہو اور وہ task مکمل ہونے تک بار بار iteration جاری رکھ سکے۔ OpenAI نے ایسی internal runs رپورٹ کی ہیں جن میں model نے 24 گھنٹوں سے زیادہ مسلسل tasks پر کام کیا۔
Adaptive reasoning اور token efficiency
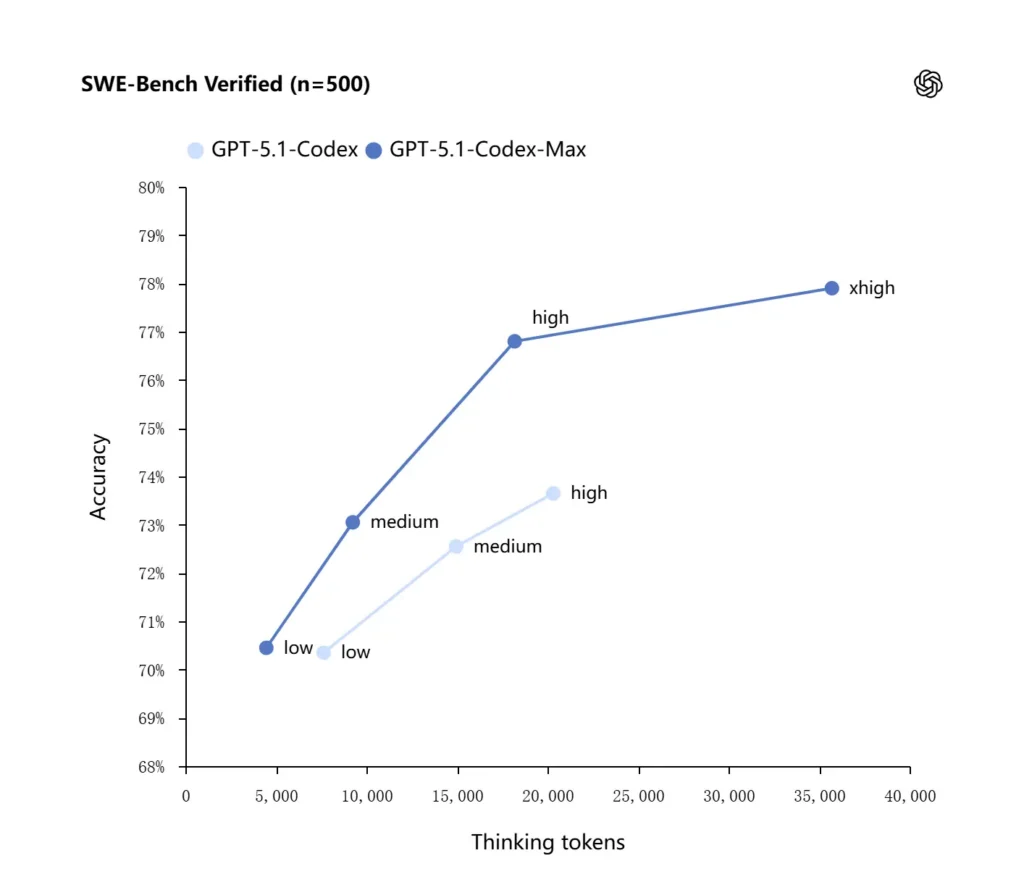
GPT-5.1-Codex-Max بہتر reasoning strategies استعمال کرتا ہے جو اسے زیادہ token-efficient بناتی ہیں: OpenAI کے رپورٹ کردہ internal benchmarks میں، Max model، GPT-5.1-Codex کے مقابلے میں مماثل یا بہتر performance حاصل کرتا ہے جبکہ نمایاں طور پر کم “thinking” tokens استعمال کرتا ہے—OpenAI کے مطابق SWE-bench Verified پر equal reasoning effort کے ساتھ چلانے پر تقریباً 30% کم thinking tokens درکار ہوتے ہیں۔ Model ایک “Extra High (xhigh)” reasoning effort mode بھی متعارف کراتا ہے جو non-latency-sensitive tasks کے لیے ہے، اور اسے زیادہ internal reasoning خرچ کر کے higher-quality outputs دینے دیتا ہے۔
System integrations اور agentic tooling
Codex-Max کو Codex workflows (CLI، IDE extensions، cloud، اور code review surfaces) کے اندر distribute کیا جا رہا ہے تاکہ یہ حقیقی developer toolchains کے ساتھ interact کر سکے۔ ابتدائی integrations میں Codex CLI اور IDE agents (VS Code، JetBrains وغیرہ) شامل ہیں، جبکہ API access بعد میں آنے کا منصوبہ ہے۔ Design goal صرف زیادہ ذہین code synthesis نہیں بلکہ ایسا AI ہے جو multi-step workflows چلا سکے: files کھولے، tests چلائے، failures درست کرے، refactor کرے، اور دوبارہ run کرے۔
GPT-5.1-Codex-Max benchmarks اور حقیقی کام میں کیسا perform کرتا ہے؟
Sustained reasoning اور long-horizon tasks
Evaluations sustained reasoning اور long-horizon tasks میں قابلِ پیمائش بہتری کی طرف اشارہ کرتی ہیں:
- OpenAI internal evaluations: Codex-Max internal experiments میں “24 گھنٹوں سے زیادہ” tasks پر کام کر سکتا ہے، اور developer tooling کے ساتھ Codex کے integration نے internal engineering productivity metrics (مثلاً usage اور pull request throughput) میں اضافہ کیا۔ یہ OpenAI کے اپنے داخلی دعوے ہیں اور حقیقی دنیا کی productivity میں task-level improvements کی نشاندہی کرتے ہیں۔
- Independent evaluations (METR): METR کی independent report نے GPT-5.1-Codex-Max کے لیے observed 50% time horizon (ایک statistic جو ظاہر کرتی ہے کہ model median طور پر کتنی دیر تک کسی long task کو مربوط انداز میں برقرار رکھ سکتا ہے) تقریباً 2 گھنٹے 40 منٹ ناپا، جو comparable measurements میں GPT-5 کے 2 گھنٹے 17 منٹ سے زیادہ ہے — sustained coherence میں ایک بامعنی اور trend کے مطابق بہتری۔ METR کی methodology اور CI variability کو نمایاں کرتے ہیں، مگر نتیجہ اس narrative کی تائید کرتا ہے کہ Codex-Max عملی long-horizon performance کو بہتر بناتا ہے۔
Code Benchmarks
OpenAI frontier coding evaluations میں بہتر نتائج رپورٹ کرتا ہے، خاص طور پر SWE-bench Verified پر جہاں GPT-5.1-Codex-Max بہتر token efficiency کے ساتھ GPT-5.1-Codex سے آگے ہے۔ کمپنی اس بات کو نمایاں کرتی ہے کہ ایک ہی “medium” reasoning effort پر Max model بہتر نتائج دیتا ہے جبکہ تقریباً 30% کم thinking tokens استعمال کرتا ہے؛ اور جو users زیادہ طویل internal reasoning کی اجازت دیتے ہیں، ان کے لیے xhigh mode latency کی قیمت پر answers کو مزید بہتر بنا سکتا ہے۔
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
GPT-5.1-Codex-Max کا GPT-5.1-Codex سے موازنہ کیسے بنتا ہے؟
Performance اور purpose میں فرق
- Scope: GPT-5.1-Codex، GPT-5.1 family کا ایک high-performance coding variant تھا؛ جبکہ Codex-Max واضح طور پر ایک agentic، long-horizon successor ہے جسے Codex اور Codex جیسے environments کے لیے recommended default بنانا مقصود ہے۔
- Token efficiency: Codex-Max، SWE-bench اور internal usage میں token efficiency میں نمایاں gains دکھاتا ہے (OpenAI کا ~30% کم thinking tokens کا دعویٰ)۔
- Context management: Codex-Max compaction اور native multi-window handling متعارف کراتا ہے تاکہ ایسے tasks برقرار رہ سکیں جو ایک single context window سے بڑھ جائیں؛ Codex اسی scale پر یہ capability native طور پر فراہم نہیں کرتا تھا۔
- Tooling readiness: Codex-Max CLI، IDE، اور code review surfaces میں default Codex model کے طور پر ship ہوتا ہے، جو production developer workflows کے لیے migration کی علامت ہے۔
کس model کو کب استعمال کرنا چاہیے؟
- GPT-5.1-Codex استعمال کریں interactive coding assistance، quick edits، small refactors، اور lower-latency use cases کے لیے جہاں پورا relevant context آسانی سے ایک single window میں سما جائے۔
- GPT-5.1-Codex-Max استعمال کریں multi-file refactors، automated agentic tasks جنہیں کئی iteration cycles درکار ہوں، CI/CD جیسے workflows، یا جب آپ کو model سے بہت سی interactions کے دوران project-level perspective برقرار رکھوانا ہو۔
Practical prompt patterns، اور بہتر نتائج کے لیے مثالیں؟
وہ prompting patterns جو اچھا کام کرتے ہیں
- Goals اور constraints واضح رکھیں: “Refactor X، public API برقرار رکھیں، function names قائم رہیں، اور tests A,B,C pass ہونے چاہییں۔”
- Minimal reproducible context فراہم کریں: failing test کا link دیں، stack traces شامل کریں، اور متعلقہ file snippets فراہم کریں، پوری repositories نہ انڈیلیں۔ Codex-Max ضرورت کے مطابق history compact کر لے گا۔
- Complex tasks کے لیے stepwise instructions استعمال کریں: بڑے کاموں کو ذیلی tasks کی ترتیب میں تقسیم کریں، اور Codex-Max کو ان پر iterate کرنے دیں (مثلاً “1) run tests 2) top 3 failing tests ٹھیک کریں 3) run linter 4) changes summarize کریں”)۔
- Explanations اور diffs طلب کریں: patch کے ساتھ ایک مختصر rationale بھی مانگیں تاکہ human reviewers جلدی سے safety اور intent کا اندازہ لگا سکیں۔
Example prompt templates
Refactor task
“
payment/module کو refactor کریں تاکہ payment processing کوpayment/processor.pyمیں extract کیا جا سکے۔ Existing callers کے لیے public function signatures کو stable رکھیں۔process_payment()کے لیے unit tests بنائیں جو success، network failure، اور invalid card کو cover کریں۔ Test suite چلائیں اور failing tests اور patch کو unified diff format میں واپس کریں۔”
Bugfix + test
“ایک test
tests/test_user_auth.py::test_token_refreshtraceback کے ساتھ fail ہو رہا ہے۔ Root cause کی تحقیق کریں، minimal changes کے ساتھ ایک fix تجویز کریں، اور regression روکنے کے لیے ایک unit test شامل کریں۔ Patch apply کریں اور tests چلائیں۔”
Iterative PR generation
“Feature X implement کریں: endpoint
POST /api/exportشامل کریں جو export results کو stream کرے اور authenticated ہو۔ Endpoint بنائیں، docs شامل کریں، tests بنائیں، اور summary اور manual items کی checklist کے ساتھ ایک PR کھولیں۔”
ان میں سے زیادہ تر کے لیے medium effort سے آغاز کریں؛ جب آپ کو model سے بہت سی files اور multiple test iterations میں deep reasoning درکار ہو تو xhigh پر جائیں۔
GPT-5.1-Codex-Max تک رسائی کیسے حاصل کریں
یہ آج کہاں دستیاب ہے
OpenAI نے GPT-5.1-Codex-Max کو آج Codex tooling میں integrate کر دیا ہے: Codex CLI، IDE extensions، cloud، اور code-review flows میں Codex-Max default کے طور پر استعمال ہوتا ہے (آپ Codex-Mini منتخب کر سکتے ہیں)۔ API availability بعد میں تیار کی جائے گی؛ GitHub Copilot کے public previews میں GPT-5.1 اور Codex series models شامل ہیں۔
Developers، CometAPI کے ذریعے GPT-5.1-Codex-Max اور GPT-5.1-Codex API تک رسائی حاصل کر سکتے ہیں۔ آغاز کے لیے، CometAPI کی model capabilities کو Playground میں دیکھیں اور تفصیلی ہدایات کے لیے API guide سے رجوع کریں۔ رسائی سے پہلے، براہ کرم یقینی بنائیں کہ آپ CometAPI میں log in کر چکے ہیں اور API key حاصل کر چکے ہیں۔ CometAPI integration میں مدد کے لیے official price کے مقابلے میں کہیں کم قیمت پیش کرتا ہے۔
Ready to Go?→ آج ہی CometAPI کے لیے sign up کریں !
اگر آپ AI سے متعلق مزید tips، guides اور news جاننا چاہتے ہیں تو ہمیں VK، X اور Discord پر follow کریں!
Quick start (practical step-by-step)
- یقینی بنائیں کہ آپ کو access حاصل ہے: تصدیق کریں کہ آپ کا ChatGPT/Codex product plan (Plus, Pro, Business, Edu, Enterprise) یا آپ کا developer API plan GPT-5.1/Codex family models کو support کرتا ہے۔
- Codex CLI یا IDE extension install کریں: اگر آپ code tasks کو locally چلانا چاہتے ہیں تو Codex CLI یا VS Code / JetBrains / Xcode کے لیے Codex IDE extension install کریں، حسبِ ضرورت۔ Supported setups میں tooling خودکار طور پر GPT-5.1-Codex-Max استعمال کرے گا۔
- Reasoning effort منتخب کریں: زیادہ تر tasks کے لیے medium effort سے شروع کریں۔ Deep debugging، complex refactors، یا جب آپ چاہتے ہوں کہ model زیادہ سوچے اور response latency اہم نہ ہو، تو high یا xhigh modes پر switch کریں۔ Quick small fixes کے لیے low مناسب ہے۔
- Repository context فراہم کریں: model کو ایک واضح starting point دیں — ایک repo URL یا files کا ایک مجموعہ اور ایک مختصر instruction (مثلاً “payment module کو async I/O کے استعمال کے لیے refactor کریں اور unit tests شامل کریں، function-level contracts برقرار رکھیں”)۔ Context limits کے قریب پہنچنے پر Codex-Max history compact کرے گا اور کام جاری رکھے گا۔
- Tests کے ساتھ iterate کریں: model کے patches دینے کے بعد test suites چلائیں اور failures کو ongoing session کے حصے کے طور پر واپس feed کریں۔ Compaction اور multi-window continuity، Codex-Max کو اہم failing test context برقرار رکھنے اور iteration جاری رکھنے دیتی ہیں۔
نتیجہ:
GPT-5.1-Codex-Max agentic coding assistants کی سمت ایک نمایاں قدم ہے، جو بہتر efficiency اور reasoning کے ساتھ complex، طویل دورانیے کے engineering tasks کو برقرار رکھ سکتے ہیں۔ Technical advances (compaction، reasoning effort modes، Windows environment training) اسے modern engineering organizations کے لیے غیر معمولی طور پر موزوں بناتی ہیں — بشرطیکہ teams اسے conservative operational controls، واضح human-in-the-loop policies، اور مضبوط monitoring کے ساتھ استعمال کریں۔ جو teams اسے احتیاط سے اپنائیں گی، ان کے لیے Codex-Max اس بات کو بدلنے کی صلاحیت رکھتا ہے کہ software کیسے design، test، اور maintain کیا جاتا ہے — repetitive engineering grunt work کو انسانوں اور models کے درمیان زیادہ high-value collaboration میں بدلتے ہوئے۔