

DeepSeek نے DeepSeek V3.2 کو اپنی V3.x لائن کے جانشین کے طور پر جاری کیا ہے، اور اس کے ساتھ DeepSeek-V3.2-Speciale نامی ایک اضافی ویریئنٹ بھی متعارف کرایا ہے جسے کمپنی ایجنٹ/ٹول استعمال کے لیے ایک اعلیٰ کارکردگی، reasoning-first ایڈیشن کے طور پر پیش کرتی ہے۔ V3.2 تجرباتی کام (V3.2-Exp) پر مبنی ہے اور زیادہ بہتر استدلالی صلاحیت، “gold-level” ریاضی/مسابقتی پروگرامنگ کارکردگی کے لیے بہتر بنایا گیا Speciale ایڈیشن، اور وہ چیز متعارف کراتا ہے جسے DeepSeek ایک اپنی نوعیت کے پہلے dual-mode “thinking + tool” سسٹم کے طور پر بیان کرتا ہے، جو داخلی step-by-step reasoning کو بیرونی ٹول invocation اور agent workflows کے ساتھ مضبوطی سے یکجا کرتا ہے۔
DeepSeek V3.2 کیا ہے — اور V3.2-Speciale میں کیا فرق ہے؟
DeepSeek-V3.2، DeepSeek کی تجرباتی V3.2-Exp برانچ کا باضابطہ جانشین ہے۔ DeepSeek کے مطابق یہ ایک “reasoning-first” ماڈل فیملی ہے جو agents کے لیے بنائی گئی ہے، یعنی ایسے ماڈلز جو صرف فطری مکالماتی معیار کے لیے نہیں بلکہ خاص طور پر multi-step inference، tool invocation، اور قابلِ اعتماد chain-of-thought طرز کے استدلال کے لیے tune کیے گئے ہیں، خاص طور پر ان ماحول میں جہاں بیرونی tools (APIs، code execution، data connectors) موجود ہوں۔
DeepSeek-V3.2 (base) کیا ہے
- V3.2-Exp تجرباتی لائن کے مرکزی production جانشین کے طور پر پوزیشن کیا گیا ہے؛ DeepSeek کی app/web/API کے ذریعے وسیع دستیابی کے لیے تیار کیا گیا ہے۔
- compute efficiency اور agentic tasks کے لیے مضبوط reasoning کے درمیان توازن برقرار رکھتا ہے۔
DeepSeek-V3.2-Speciale کیا ہے
DeepSeek-V3.2-Speciale ایک ایسا ویریئنٹ ہے جسے DeepSeek ایک زیادہ صلاحیت والے “Special Edition” کے طور پر مارکیٹ کرتی ہے، جو contest-level reasoning، advanced mathematics، اور agent performance کے لیے tune کیا گیا ہے۔ اسے ایک زیادہ صلاحیت والے ویریئنٹ کے طور پر پیش کیا گیا ہے جو “reasoning capabilities کی حدود کو آگے بڑھاتا ہے”۔ DeepSeek فی الحال Speciale کو ایک API-only ماڈل کے طور پر عارضی access routing کے ساتھ فراہم کرتا ہے؛ ابتدائی benchmarks سے اشارہ ملتا ہے کہ اسے reasoning اور coding benchmarks میں اعلیٰ درجے کے closed models کے مقابلے کے لیے پوزیشن کیا گیا ہے۔
V3.2 تک پہنچنے والی lineage اور engineering choices کیا تھیں؟
V3.2، 2025 کے دوران DeepSeek کی عوامی طور پر بیان کردہ تدریجی engineering lineage سے وراثت لیتا ہے: V3 → V3.1 (Terminus) → V3.2-Exp (ایک تجرباتی مرحلہ) → V3.2 → V3.2-Speciale۔ تجرباتی V3.2-Exp نے DeepSeek Sparse Attention (DSA) متعارف کرایا — ایک fine-grained sparse attention mechanism جس کا مقصد بہت لمبے context lengths کے لیے memory اور compute costs کو کم کرنا تھا جبکہ output quality برقرار رہے۔ DSA تحقیق اور cost-reduction پر کام، باضابطہ V3.2 فیملی کے لیے ایک تکنیکی stepping stone ثابت ہوئے۔
باضابطہ DeepSeek 3.2 میں نیا کیا ہے؟
1) بہتر reasoning ability — reasoning کیسے بہتر ہوئی؟
DeepSeek، V3.2 کو “reasoning-first” کے طور پر پیش کرتا ہے۔ اس کا مطلب یہ ہے کہ architecture اور fine-tuning کی توجہ اس بات پر ہے کہ ماڈل قابلِ اعتماد انداز میں multi-step inference انجام دے، داخلی chains of thought برقرار رکھے، اور ان structured deliberation کی اقسام کی حمایت کرے جن کی agents کو بیرونی tools درست طور پر استعمال کرنے کے لیے ضرورت ہوتی ہے۔
واضح طور پر، بہتریوں میں شامل ہیں:
- Training اور RLHF (یا اسی طرح کے alignment procedures) کو اس انداز میں tune کیا گیا ہے کہ explicit stepwise problem solving اور stable intermediate states کی حوصلہ افزائی ہو (جو math reasoning، multi-step code generation، اور logic tasks کے لیے مفید ہیں)۔
- Architectural اور loss-function choices جو طویل context windows کو محفوظ رکھتی ہیں اور ماڈل کو پہلے کے reasoning steps کو درستگی کے ساتھ refer کرنے دیتی ہیں۔
- عملی modes (نیچے “dual-mode” دیکھیں) جو اسی ماڈل کو یا تو تیز “chat” طرز mode میں یا ایک deliberative “thinking” mode میں کام کرنے دیتے ہیں جہاں یہ عمل سے پہلے جان بوجھ کر intermediate steps پر کام کرتا ہے۔
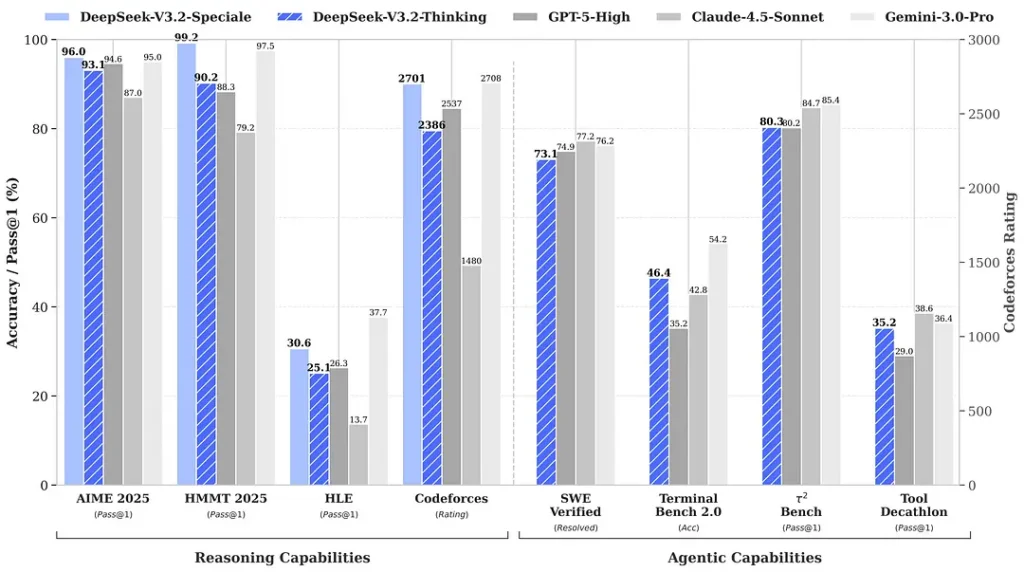
ریلیز کے آس پاس پیش کیے گئے benchmarks کے مطابق math اور reasoning suites میں نمایاں gains کا دعویٰ کیا گیا؛ ابتدائی آزاد community benchmarks نے بھی competitive evaluation sets پر متاثر کن scores رپورٹ کیے ہیں:
2) Special Edition میں breakthrough performance — کتنا بہتر؟
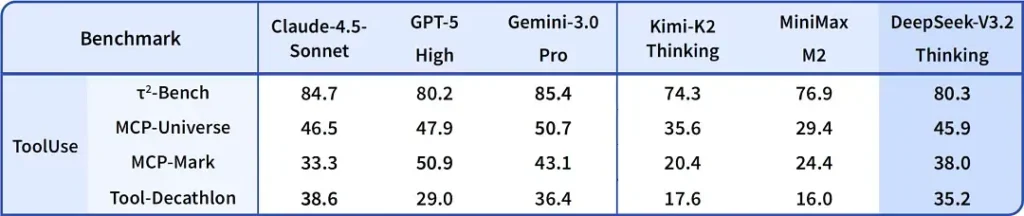
DeepSeek-V3.2-Speciale کے بارے میں دعویٰ ہے کہ یہ standard V3.2 کے مقابلے میں reasoning accuracy اور agent orchestration میں ایک واضح بہتری فراہم کرتا ہے۔ provider، Speciale کو performance tier کے طور پر پیش کرتا ہے جو heavy reasoning workloads اور challenging agent tasks کے لیے ہدف بنایا گیا ہے؛ یہ فی الحال API-only ہے اور عارضی، زیادہ صلاحیت والے endpoint کے طور پر پیش کیا جا رہا ہے (DeepSeek نے اشارہ دیا ہے کہ Speciale کی دستیابی ابتدا میں محدود ہوگی)۔ Speciale ورژن پچھلے mathematical model DeepSeek-Math-V2 کو integrate کرتا ہے؛ یہ خود ریاضیاتی قضیوں کو ثابت کر سکتا ہے اور منطقی reasoning کی تصدیق کر سکتا ہے؛ اس نے متعدد عالمی معیار کے مقابلوں میں نمایاں نتائج حاصل کیے ہیں:
- 🥇 IMO (International Mathematical Olympiad) Gold Medal
- 🥇 CMO (Chinese Mathematical Olympiad) Gold Medal
- 🥈 ICPC (International Computer Programming Contest) Second Place (Human Contest)
- 🥉 IOI (International Olympiad in Informatics) Tenth Place (Human Contest)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) dual-mode “thinking + tool” system کا پہلی بار نفاذ
V3.2 کے بارے میں سب سے زیادہ عملی طور پر دلچسپ دعوؤں میں سے ایک dual-mode workflow ہے جو تیز conversational operation اور ایک سست، deliberative “thinking” mode کو الگ کرتا ہے (اور آپ کو ان کے درمیان انتخاب کی اجازت دیتا ہے)، جبکہ اسے tool use کے ساتھ مضبوطی سے integrate بھی کرتا ہے۔
- “Chat / fast” mode: کم latency، user-facing chat کے لیے ڈیزائن کیا گیا ہے، مختصر جوابات اور کم internal reasoning traces کے ساتھ — casual help، مختصر Q&A، اور speed-sensitive applications کے لیے موزوں۔
- “Thinking / reasoner” mode: سخت chain-of-thought، stepwise planning، اور بیرونی tools (APIs، database queries، code execution) کی orchestration کے لیے بہتر بنایا گیا ہے۔ thinking mode میں کام کرتے وقت ماڈل زیادہ explicit intermediate steps پیدا کرتا ہے، جنہیں inspect کیا جا سکتا ہے یا agentic systems میں محفوظ، درست tool calls چلانے کے لیے استعمال کیا جا سکتا ہے۔
یہ pattern (دو modes والا design) پہلے کی experimental branches میں موجود تھا، اور DeepSeek نے اسے V3.2 اور Speciale میں مزید گہرائی سے integrate کیا ہے — Speciale فی الحال صرف thinking mode کو support کرتا ہے (اسی لیے اس کی API gating ہے)۔ رفتار اور deliberation کے درمیان switch کرنے کی صلاحیت engineering کے لیے قیمتی ہے کیونکہ اس سے developers کو latency اور reliability کے درمیان درست trade-off منتخب کرنے کا موقع ملتا ہے جب وہ ایسے agents بناتے ہیں جنہیں حقیقی دنیا کے systems کے ساتھ تعامل کرنا ہو۔
یہ کیوں نمایاں ہے: بہت سے جدید systems یا تو ایک مضبوط chain-of-thought model پیش کرتے ہیں (reasoning کی وضاحت کے لیے) یا ایک الگ agent/tool orchestration layer۔ DeepSeek کی framing ایک زیادہ tight coupling کی طرف اشارہ کرتی ہے — ماڈل “سوچ” سکتا ہے اور پھر deterministically tools call کر سکتا ہے، tool responses کو اگلی thinking میں استعمال کرتے ہوئے — جو autonomous agents بنانے والے developers کے لیے زیادہ seamless ہے۔
DeepSeek v3.2 کہاں سے حاصل کریں
مختصر جواب — آپ اپنی ضرورت کے مطابق کئی طریقوں سے DeepSeek v3.2 حاصل کر سکتے ہیں:
- Official web/app (آن لائن استعمال کریں) — V3.2 کو interactive طور پر استعمال کرنے کے لیے DeepSeek web interface یا mobile app آزمائیں۔
- API access — DeepSeek اپنی API کے ذریعے V3.2 فراہم کرتا ہے (docs میں model names / base_url اور pricing شامل ہیں)۔ API key کے لیے sign up کریں اور v3.2 endpoint کو call کریں۔
- Downloadable/open weights (Hugging Face) — ماڈل (V3.2 / V3.2-Exp variants) Hugging Face پر شائع کیا گیا ہے اور download کیا جا سکتا ہے (open-weight)۔ فائلیں حاصل کرنے کے لیے
huggingface-hubیاtransformersاستعمال کریں۔ - CometAPI — ایک AI API aggregation platform جو V3.2-Exp کے hosted endpoints فراہم کرتا ہے۔ اس کی قیمت official price سے کم ہے۔
چند عملی نوٹس:
- اگر آپ weights کو locally چلانا چاہتے ہیں، تو Hugging Face model page پر جائیں (وہاں موجود کسی بھی license / access conditions کو قبول کریں) اور download کے لیے
huggingface-cliیاtransformersاستعمال کریں؛ GitHub repo عموماً درست commands بھی دکھاتا ہے۔ - اگر آپ API کے ذریعے production usage چاہتے ہیں، تو اپنی مطلوبہ platform جیسے cometapi API docs کو endpoint names اور V3.2 variant کے لیے درست
base_urlکے ساتھ follow کریں۔
DeepSeek-V3.2-Speciale:* صرف research use کے لیے کھلا ہے، “Thinking Mode” dialogue کو support کرتا ہے، لیکن tool calls کو support نہیں کرتا۔
- Maximum output 128K tokens تک ہو سکتا ہے (ultra-long Thinking Chain)۔
- فی الحال 15 دسمبر 2025 تک مفت test کے لیے دستیاب ہے۔
آخری خیالات
DeepSeek-V3.2، reasoning-centric models کی پختگی میں ایک معنی خیز قدم کی نمائندگی کرتا ہے۔ بہتر multi-step reasoning، specialized high-performance editions (Speciale)، اور productionized “thinking + tool” integration کا امتزاج ان تمام لوگوں کے لیے قابلِ توجہ ہے جو advanced agents، coding assistants، یا research workflows بنا رہے ہیں جنہیں deliberation کو بیرونی actions کے ساتھ interleave کرنا ہوتا ہے۔
Developers، CometAPI کے ذریعے DeepSeek V3.2 تک رسائی حاصل کر سکتے ہیں۔ آغاز کے لیے، Playground میں CometAPI کی model capabilities دیکھیں اور تفصیلی ہدایات کے لیے API guide کا مطالعہ کریں۔ رسائی سے پہلے، براہِ کرم یہ یقینی بنائیں کہ آپ CometAPI میں log in کر چکے ہیں اور API key حاصل کر لی ہے۔ CometAPI integration میں مدد کے لیے official price سے کہیں کم قیمت پیش کرتا ہے۔
Ready to Go?→ آج ہی CometAPI کے لیے سائن اپ کریں !
اگر آپ AI سے متعلق مزید tips، guides اور news جاننا چاہتے ہیں تو ہمیں VK، X اور Discord پر follow کریں!