
.webp&w=3840&q=75)
GLM-5.1 مصنوعی ذہانت کے منظرنامے میں ایک فیصلہ کن تبدیلی کی نمائندگی کرتا ہے۔ چینی AI کمپنیاں کھلے ماخذ کے ذریعے سرحدی صلاحیتیں جاری کرتے ہوئے کاروباری کاری کو تیز کر رہی ہیں، ایسے میں یہ ماڈل OpenAI کے GPT-5.4، Anthropic کے Claude Opus 4.6، اور Google کے Gemini 3.1 Pro جیسے ملکیتی قائدین کے ساتھ فاصلہ کم کرتا ہے—خصوصاً حقیقی دنیا کی سافٹ ویئر انجینئرنگ میں۔ GLM-5 جیسی ہی 744B-پیرامیٹر MoE معماری پر تربیت یافتہ لیکن ایجنٹک ورک فلو کے لیے بھاری طور پر بہتر بنایا گیا، یہ وہاں ممتاز ہے جہاں زیادہ تر LLM کمزور پڑتے ہیں: طویل، مبہم، تکراری کام جو ہزاروں ٹول کالز کے ساتھ منصوبہ بندی، آزمائش، ڈیبگنگ اور خود اصلاح کا تقاضا کرتے ہیں۔
اب، CometAPI نے GLM-5.1 اور GLM-5 کو ضم کر دیا ہے، اور ڈویلپرز دیگر ممتاز مغربی ماڈلز بھی دیکھ سکتے ہیں اور انہیں نہایت کم API قیمت پر حاصل کر سکتے ہیں (جو CometAPI کا دیگر حریفوں کے مقابلے میں ایک فائدہ بھی ہے)۔
GLM-5.1 کیا ہے؟
GLM-5.1 Z.ai کا نیا ترین فلیگ شپ لینگویج ماڈل ہے اور کمپنی کی طویل افق، ایجنٹ انداز سافٹ ویئر کام کی تازہ کوشش ہے۔ Z.ai کے مطابق، اسے ایسے کاموں کے لیے ڈیزائن کیا گیا ہے جنہیں ایک وقتی جواب کے بجائے مسلسل نفاذ درکار ہو، اور اسے اس طرح پوزیشن کیا گیا ہے کہ یہ ایک ہی طویل رن کے اندر منصوبہ بنا سکے، نفاذ کرے، درست کرے، اور ڈیلیور کرے۔ Z.ai کے ریلیز نوٹس کے مطابق GLM-5.1 کو ملٹی ٹرن سپروائزڈ فائن ٹیوننگ، ری انفورسمنٹ لرننگ، اور پروسس کوالٹی ایویلیوایشن فریم ورک کے ساتھ تیار کیا گیا ہے، اور یہ طویل دورانیہ والے کاموں میں استحکام، مطابقت، اور ٹول کے استعمال کو بہتر بناتا ہے۔
یہ پوزیشننگ اس لیے اہم ہے کہ GLM-5.1 کو صرف “ایک اور چیٹ ماڈل” کے طور پر نہیں بیچا جا رہا۔ اس کا ہدف انجینئرنگ ورک فلو ہیں جہاں ماڈلز کو ہدف ذہن میں رکھنا ہو، درمیانی مراحل سنبھالنا ہوں، اور دھاگہ کھوئے بغیر غلطیوں سے سنبھلنا ہو—اسے خودمختار منصوبہ بندی، مسلسل نفاذ، بگ فکسنگ، اور حکمتِ عملی کی تکرار کے لیے ایک ماڈل کے طور پر پیش کیا گیا ہے، جو ایک عام اسسٹنٹ یا مختصر سیاق والے کوڈنگ کوپائلٹ سے بالکل مختلف پروڈکٹ کہانی ہے۔
ایک عملی نکتہ: GLM-5.1 صرف متن پر مبنی ہے، یہ GLM Coding Plan میں سپورٹڈ ہے اور Claude Code اور OpenClaw جیسے مقبول کوڈنگ ایجنٹس میں استعمال ہو سکتا ہے، جس سے یہ ان ٹیموں کے لیے خاص طور پر موزوں بنتا ہے جو ماڈل کو موجودہ ڈویلپر ورک فلو کے اندر بٹھانا چاہتی ہیں نہ کہ اسے بدلنا۔
بنیادی تکنیکی خصوصیات (GLM-5 سے موروثی اور نکھاری گئی):
- Architecture: Mixture-of-Experts (MoE) جس میں کل 744 بلین پیرامیٹرز اور فی انفیرینس تقریباً 40 بلین فعال پیرامیٹرز ہیں۔
- Context Window: 203K–204.8K ٹوکنز (زیادہ سے زیادہ 131K آؤٹ پٹ ٹوکنز کی سپورٹ کے ساتھ)۔
- Key Enhancements: طویل سیاق کی مؤثر ہینڈلنگ اور کم تعیناتی لاگت کے لیے DeepSeek Sparse Attention (DSA)؛ نفاذ کے بعد تربیت کے لیے Z.ai کے “slime” فریم ورک کے ذریعے جدید غیر ہم وقت ساز ری انفورسمنٹ لرننگ انفراسٹرکچر۔
- Availability: اوپن ویٹس (MIT لائسنس کے تحت Hugging Face پر zai-org/GLM-5.1)، Z.ai کے پلیٹ فارم اور CometAPI جیسے ایگریگیٹرز کے ذریعے API رسائی، اور GLM Coding Plan ٹولز میں انٹیگریٹڈ (Claude Code / OpenClaw کے ساتھ ہم آہنگ)۔
سابقہ GLM ماڈلز کے برعکس جو عمومی ذہانت یا مختصر “وائب کوڈنگ” پر مرکوز تھے، GLM-5.1 کا ہدف پروڈکشن گریڈ خودکار ایجنٹس ہیں۔ یہ انسانی مداخلت کے بغیر گھنٹوں تک پیچیدہ انجینئرنگ پروجیکٹس کی منصوبہ بندی، نفاذ، بینچ مارکنگ، ڈیبگنگ، اور تکرار کر سکتا ہے—صلاحیتیں جو اسے Anthropic اور OpenAI کے خصوصی کوڈنگ ایجنٹس کا براہِ راست حریف بناتی ہیں۔
اس ریلیز کے ساتھ تقریباً ~10% API قیمت میں اضافہ ہوا (ان پٹ ٹوکنز ~$0.54/M، آؤٹ پٹ ~$4.40/M)، تاہم یہ پھر بھی Anthropic کے Opus 4.6 جیسے مساوی ماڈلز سے نمایاں طور پر سستا ہے (250–470% تک زیادہ مہنگے)۔
GLM-5.1 بینچ مارک کارکردگی
Z.ai، GLM-5.1 کو دنیا کا طاقتور ترین اوپن سورس ماڈل اور ایجنٹک کوڈنگ میں عالمی سطح پر ٹاپ-3 پرفارمر کے طور پر پوزیشن کرتا ہے۔ کارکردگی کا ڈیٹا SWE-Bench Pro، NL2Repo، Terminal-Bench 2.0، اور کسٹم طویل افق منظرناموں پر مبنی سرکاری جائزوں سے آتا ہے۔
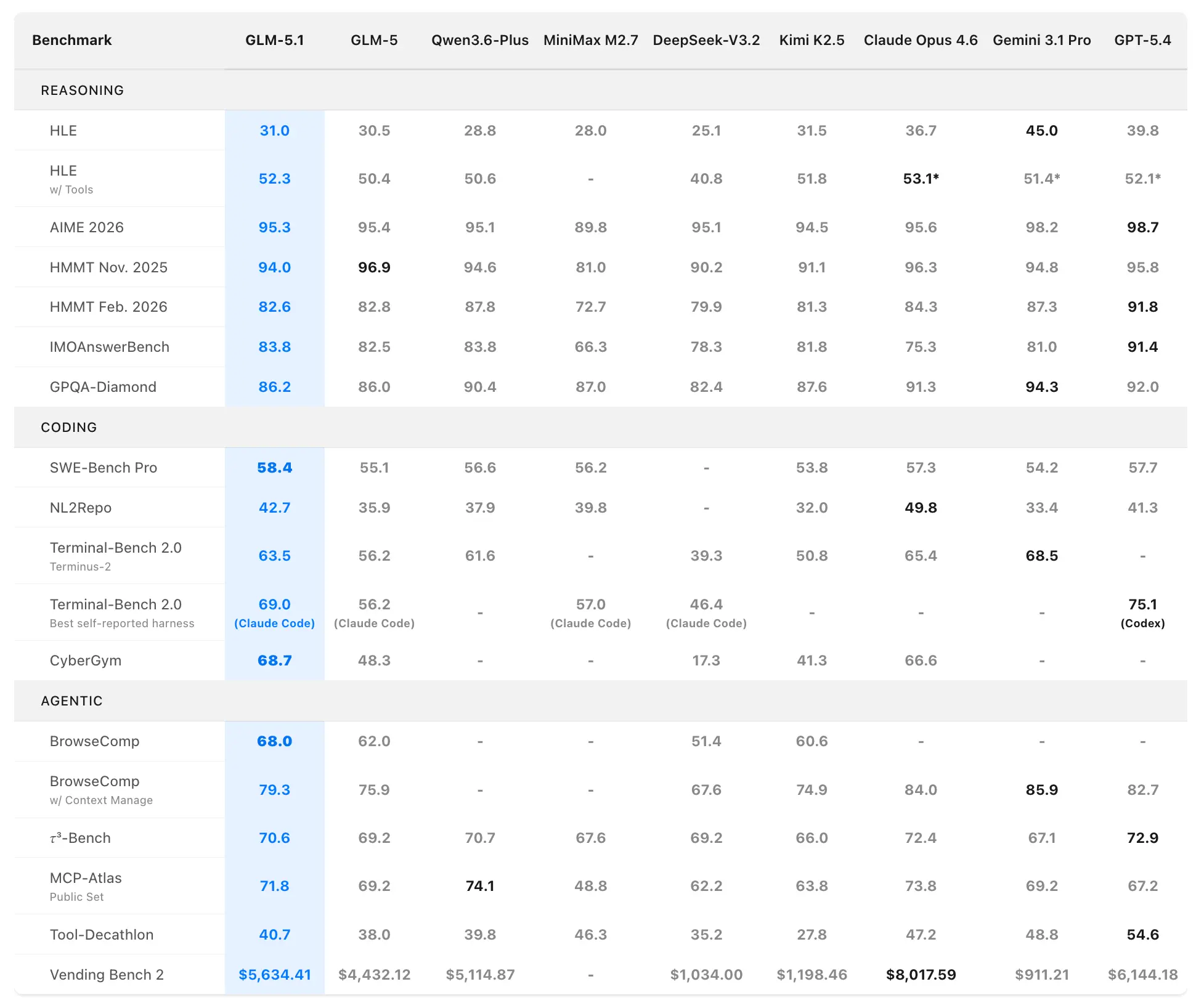
کوڈنگ اور ایجنٹک بینچ مارکس
SWE-Bench Pro (حقیقی سافٹ ویئر انجینئرنگ کام جو ریپوزٹری نیویگیشن، کوڈ ایڈٹنگ، اور فنکشنل ویریفکیشن درکار کرتے ہیں):
- GLM-5.1: 58.4 (نیا SOTA)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 اس سخت بینچ مارک پر پہلی گھریلو (چینی) اور اوپن سورس ماڈل ہے جس نے سرفہرست پوزیشن حاصل کی، جو پیشہ ور ڈویلپر ورک فلو سے قریب تر مماثلت رکھتا ہے۔
NL2Repo (قدرتی زبان سے مکمل ریپوزٹری جنریشن):
- GLM-5.1: 42.7 (GLM-5 کے 35.9 پر نمایاں سبقت)
- مقابل ماڈلز 32.0–49.8 کی رینج میں (لیڈر ہارنس کے لحاظ سے مختلف ہیں)۔
Terminal-Bench 2.0 (حقیقی دنیا کے ٹرمینل اور سسٹمز کے کام):
- Terminus-2 ہارنس: GLM-5.1 63.5 (بنام GLM-5 56.2)
- بہترین خود رپورٹڈ (Claude Code): زیادہ سے زیادہ 69.0۔
ایک علیحدہ کوڈنگ ہارنس جائزے (Claude Code طرز) میں، GLM-5.1 نے 45.3 اسکور کیا—Claude Opus 4.6 کے 47.9 کا 94.6% اور GLM-5 کے 35.4 پر 28% بہتری۔
مرکب درجہ بندی: #1 اوپن سورس، #1 چینی ماڈل، #3 عالمی سطح پر SWE-Bench Pro + NL2Repo + Terminal-Bench کے مجموعے میں۔
طویل افق کاموں کی کارکردگی: اصل فرق
معیاری بینچ مارکس ایک وقتی یا مختصر سیشن کارکردگی ناپتے ہیں۔ GLM-5.1 طویل خودکار رنز میں چمکتا ہے:
- VectorDBBench آپٹیمائزیشن (600+ تکرار، 6,000+ ٹول کالز): Rust اسکیلیٹن سے شروع کرتے ہوئے، GLM-5.1 نے مرحلہ وار انڈیکسنگ، کمپریشن، روٹنگ، اور پروننگ کو نئے سرے سے ڈیزائن کیا، اور 21.5k QPS حاصل کیے (Claude Opus 4.6 کی 50-ٹرن بہترین 3,547 QPS کے مقابلے 6×)، جبکہ SIFT-1M پر ≥95% ریکال برقرار رکھی۔ اس نے ہر 100–200 تکرار پر ساختی بریک تھروز کے ساتھ “سیڑھی نما” پیش رفت دکھائی۔
- KernelBench لیول 3 (مکمل ML ماڈل آپٹیمائزیشن، 1,000+ ٹرنز): 50 پیچیدہ مسائل میں جیومیٹرک مین اسپیڈ اپ 3.6× (torch.compile max-autotune کے 1.49× سے بہتر)۔ GLM-5.1 اس وقت بھی بہتری جاری رکھتا رہا جب GLM-5 پلیٹو ہو گیا؛ صرف Claude Opus 4.6 نے 4.2× پر اسے پیچھے چھوڑا۔
- Linux ڈیسک ٹاپ ویب ایپ بلڈ (8+ گھنٹے، اوپن اینڈڈ): صرف قدرتی زبان کے پرامپٹ اور بغیر کسی اسٹارٹر کوڈ کے، GLM-5.1 نے خودمختاری سے ایک فعّال لینکس طرز ڈیسک ٹاپ ماحول بنایا—ٹاسک بار، ونڈوز، انٹریکشنز، اور پالش کے ساتھ—جہاں پچھلے ماڈلز صرف بنیادی اسکیلیٹن تک محدود رہے تھے۔
یہ نتائج GLM-5.1 کی وہ صلاحیتیں دکھاتے ہیں جن سے یہ انتہائی طویل افق پر بھی ربط قائم رکھتا ہے، خود جائزہ لیتا ہے، حکمتِ عملی تبدیل کرتا ہے، اور مقامی آپٹِما سے باہر نکل آتا ہے—وہ صلاحیتیں جنہیں Z.ai نے واضح طور پر حقیقی دنیا کے ایجنٹک سسٹمز کے لیے انجینئر کیا ہے۔
GLM-5.1، GLM-5 سے کیسے مختلف ہے؟
GLM-5 اور GLM-5.1 ایک دوسرے سے قریبی تعلق رکھتے ہیں، لیکن ان کی پوزیشننگ ایک جیسی نہیں۔ GLM-5، Z.AI کا ابتدائی فاؤنڈیشن ماڈل ہے برائے Agentic Engineering۔ اسے پیچیدہ سسٹم انجینئرنگ اور طویل فاصلے کے ایجنٹ کاموں کے لیے ڈیزائن کیا گیا، اوپن ویٹ SOTA کوڈنگ اور ایجنٹ صلاحیت کے ساتھ، اور حقیقی پروگرامنگ منظرناموں میں جس کی کوڈنگ کارکردگی Claude Opus 4.5 کے قریب پہنچتی ہے۔ یہ SWE-bench Verified پر 77.8 اور Terminal Bench 2.0 پر 56.2 اسکور کرتا ہے۔
اس کے برعکس، GLM-5.1 کو طویل افق کاموں اور زیادہ قابلِ اعتماد مسلسل نفاذ کی اگلی منزل کے طور پر پیش کیا گیا ہے، جو طویل کاموں میں استحکام، مطابقت، اور ٹول کے استعمال کو بہتر بناتا ہے، اور مجموعی طور پر Claude Opus 4.6 کے ساتھ بہتر ہم آہنگی دکھاتا ہے۔ دوسرے لفظوں میں، GLM-5 ایک پہلے کا انجینئرنگ مرکز فاؤنڈیشن ماڈل ہے، جبکہ GLM-5.1 زیادہ ٹاسک برداشت پر مبنی فلیگ شپ ہے۔
GLM-5 جنریشن میں معماری اور تربیتی فرق بھی ہیں جو اس چھلانگ کی وضاحت میں مدد دیتے ہیں۔ GLM-5 نے 355B پیرامیٹرز (32B ایکٹیویٹڈ) سے 744B پیرامیٹرز (40B ایکٹیویٹڈ) تک توسیع کی، پری ٹریننگ ڈیٹا کو 23T سے 28.5T تک بڑھایا، غیر ہم وقت ساز ری انفورسمنٹ لرننگ فریم ورک شامل کیا، اور DeepSeek Sparse Attention کو ضم کیا تاکہ طویل متن کے معیار کو برقرار رکھتے ہوئے کارکردگی بہتر بنائی جا سکے۔ یہ تفصیلات GLM-5 سے جڑی ہیں، لیکن یہی بنیاد ہے جس پر GLM-5.1 واضح طور پر کھڑا ہے۔
GLM-5.1 بمقابلہ دیگر فرنٹیئر ماڈلز
GLM-5.1 بطور طاقتور ترین اوپن سورس امیدوار نمایاں ہے جبکہ قیمت/کارکردگی میں بھی پرکشش ہے۔
موازنہ جدول: بڑے کوڈنگ اور ایجنٹک بینچ مارکس (اپریل 2026)
| ماڈل | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness اسکور | طویل مدت میں تسلسل؟ | اوپن سورس؟ | تقریباً API قیمت (Input/Output فی M ٹوکن) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | ہاں (600+ تکرار، 8 گھنٹے) | ہاں | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | محدود | ہاں | کم (pre-hike سے پہلے) |
| GPT-5.4 | 57.7 | — | — | — | مضبوط | نہیں | زیادہ |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | سب سے مضبوط | نہیں | ~250–470% زیادہ مہنگا |
| Gemini 3.1 Pro | 54.2 | — | — | — | اچھا | نہیں | زیادہ |
فیصلہ: GLM-5.1 اوپن سورس دستیابی، لاگت، اور مخصوص طویل افق کوڈنگ میٹرکس پر جیتتا ہے۔ یہ ایجنٹک منظرناموں میں کلوڈ سورس لیڈرز کے ساتھ برابری کی ٹکر دیتا ہے جبکہ سرحدی صلاحیتوں کو جمہوری بھی بناتا ہے۔
GLM-5.1 کے اطلاقی منظرنامے
1) خودمختار سافٹ ویئر انجینئرنگ
GLM-5.1 سب سے زیادہ متاثر کن تب ہے جب کام ایک حقیقی انجینئرنگ اسپرنٹ جیسا ہو: کوڈ بیس پڑھیں، تبدیلی کی منصوبہ بندی کریں، اسے نافذ کریں، ٹیسٹ کریں، ریگریشن ٹھیک کریں، اور نتیجہ مستحکم ہونے تک تکرار جاری رکھیں۔ Z.ai کے ریلیز نوٹس خودمختار منصوبہ بندی، مسلسل نفاذ، بگ فکسنگ، اور حکمتِ عملی کی تکرار پر واضح زور دیتے ہیں، جو اس ماڈل کو کوڈنگ ایجنٹس اور سافٹ ویئر ڈلیوری پائپ لائنز کے لیے خاص مقصدی محسوس کراتے ہیں۔
2) طویل چلنے والے ایجنٹ ورک فلو
اگر آپ کا استعمال کیس کئی ٹول کالز، طویل ملٹی اسٹیپ ورک فلو، یا بار بار خود اصلاح پر مشتمل ہے، تو GLM-5.1 کا ڈیزائن ایک مضبوط میچ ہے۔ دستاویزات ٹول انووکیشن، اسٹرکچرڈ آؤٹ پٹ، MCP انٹیگریشن، اور ٹول-اسٹریمنگ سپورٹ کو نمایاں کرتی ہیں—جو اس وقت کارآمد ہیں جب ماڈل صرف جواب نہیں دے رہا بلکہ ایک بڑے نظام کے اندر عمل کر رہا ہو۔
3) انٹرپرائز نالج ورک اور رپورٹنگ
GLM-5.1 کو دفتری پیداواری کاموں کے لیے بھی پوزیشن کیا گیا ہے جیسے PowerPoint، Word، PDF، اور Excel ورک فلو۔ Z.ai کہتا ہے کہ یہ پیچیدہ مواد کی تنظیم، لے آؤٹ ڈیزائن، اسٹرکچرڈ آؤٹ پٹ، اور بصری چمک میں بہتری لاتا ہے، جو اسے رپورٹ جنریشن، تدریسی مواد، تحقیقی خلاصوں، اور دیگر دستاویزاتی کاموں کے لیے موزوں بناتا ہے۔
4) فرنٹ اینڈ پروٹوٹائپنگ اور آؤٹ پٹس
Z.ai کے مطابق GLM-5.1 ویب سائٹ جنریشن، انٹرایکٹو صفحات، اور فرنٹ اینڈ پروٹوٹائپنگ کے لیے موزوں ہے، کم ٹیمپلیٹڈ ساخت کے ساتھ اور ٹاسک کمپلیشن کے معیار میں بہتری کے ساتھ۔ اس سے یہ ان پروڈکٹ ٹیموں کے لیے اچھا فٹ بنتا ہے جنہیں بریف سے پروٹوٹائپ تک تیز رفتاری چاہیے—خاص طور پر جب پروٹوٹائپ محض خوبصورت نہیں بلکہ قابلِ استعمال بھی ہونا چاہیے۔
5) پیچیدہ گفتگو اور ہدایات پر عمل
اگرچہ سرخی کوڈنگ ہے، GLM-5.1 کو اوپن اینڈڈ سوال و جواب، پیچیدہ ہدایات، اور ملٹی ٹرن تعامل میں بھی مضبوط بتایا گیا ہے۔ یہ اسے اسسٹنٹ طرز ورک فلو کے لیے مفید بناتا ہے جہاں ماڈل کو پابندیوں کا حساب رکھنا، آؤٹ پٹ کو درست کرنا، اور طویل گفتگو میں سیاق برقرار رکھنا ہو۔
نتیجہ: 2026 میں GLM-5.1 کیوں اہم ہے
GLM-5.1 محض ایک تدریجی ریلیز نہیں—یہ واقعی قابلِ عمل اوپن سورس ایجنٹک AI کی آمد کا اشارہ ہے۔ سب سے مشکل حقیقی دنیا کی انجینئرنگ بینچ مارکس میں کمال دکھاتے ہوئے، اور پھر بھی قابلِ برداشت اور اوپن رہتے ہوئے، Z.ai نے پوری صنعت کے لیے معیار بلند کر دیا ہے۔ چاہے آپ سولو ڈویلپر ہوں، انٹرپرائز ٹیم، یا محقق، GLM-5.1 طویل افق کوڈنگ کاموں کے لیے بے مثال خودمختاری پیش کرتا ہے—اور وہ بھی ملکیتی لاگت کے ایک حصے پر۔
آزما کر دیکھنا چاہتے ہیں؟ فوری رسائی کے لیے CometAPI GLM-5.1 ماڈل، Hugging Face ریپو، یا GLM Coding Plan چیک کریں۔