

GPT-5.2، OpenAI کے GPT-5 خاندان میں دسمبر 2025 کی پوائنٹ ریلیز ہے: ایک فلیگ شپ ملٹی موڈل ماڈل فیملی (متن + وژن + ٹولز) جو پیشہ ورانہ علمی کام، طویل سیاق و سباق میں استدلال، ایجینٹک ٹول کے استعمال، اور سافٹ ویئر انجینئرنگ کے لیے خاص طور پر ٹیون کی گئی ہے۔ OpenAI، GPT-5.2 کو اب تک کے سب سے زیادہ قابل GPT-5 سیریز ماڈل کے طور پر پیش کرتا ہے اور کہتا ہے کہ اسے قابلِ اعتماد کثیر مرحلہ استدلال، بہت بڑے دستاویزات کی ہینڈلنگ، اور بہتر حفاظتی/پالیسی کمپلائنس پر زور دیتے ہوئے تیار کیا گیا؛ اس ریلیز میں تین صارفین کے لیے سامنے آنے والے متغیرات — Instant، Thinking، اور Pro — شامل ہیں اور اسے پہلے ادائیگی والے ChatGPT سبسکرائبرز اور API کسٹمرز کے لیے رول آؤٹ کیا جا رہا ہے۔
GPT-5.2 کیا ہے اور یہ کیوں اہم ہے؟
GPT-5.2، OpenAI کے GPT-5 خاندان کا تازہ ترین رکن ہے — ایک نیا “فرنٹیئر” ماڈل سیریز جو خاص طور پر واحد-ٹرن مکالماتی معاونین اور ان نظاموں کے درمیان خلا پُر کرنے کے لیے ڈیزائن کی گئی ہے جنہیں طویل دستاویزات پر استدلال، ٹولز کو کال کرنا، تصاویر کی تشریح کرنا، اور کثیر مرحلہ ورک فلو کو قابل اعتماد طریقے سے انجام دینا ہوتا ہے۔ OpenAI، 5.2 کو پیشہ ورانہ علمی کام کے لیے اپنا سب سے زیادہ قابل ریلیز قرار دیتا ہے: یہ اندرونی بینچ مارکس پر جدید ترین نتائج مرتب کرتا ہے (خاص طور پر علمِ کار کے لیے نئے GDPval بینچ مارک پر)، سافٹ ویئر انجینئرنگ بینچ مارکس پر زیادہ مضبوط کوڈنگ کارکردگی دکھاتا ہے، اور طویل سیاق و سباق اور وژن صلاحیتوں میں نمایاں بہتری فراہم کرتا ہے۔
عملی طور پر، GPT-5.2 محض “ایک بڑا چیٹ ماڈل” نہیں ہے۔ یہ تین ٹیونڈ متغیرات (Instant، Thinking، Pro) کا خاندان ہے جو لیٹنسی، استدلال کی گہرائی، اور لاگت کے درمیان توازن قائم کرتے ہیں — اور جو OpenAI کے API اور ChatGPT روٹنگ کے ساتھ مل کر، طویل تحقیقی کام چلانے، بیرونی ٹولز کو کال کرنے والے ایجنٹس بنانے، پیچیدہ تصاویر اور چارٹس کی تشریح کرنے، اور سابقہ ریلیزز کے مقابلے میں زیادہ وفاداری کے ساتھ پروڈکشن-گریڈ کوڈ تیار کرنے کے لیے استعمال کیے جا سکتے ہیں۔ یہ ماڈل بہت بڑے کانٹیکسٹ ونڈوز کو سپورٹ کرتا ہے (OpenAI دستاویزات فلیگ شپ ماڈلز کے لیے 400,000 ٹوکن کانٹیکسٹ ونڈو اور 128,000 میکس-آؤٹ پٹ حد درج کرتی ہیں)، واضح استدلالی کوشش کی سطحوں کے لیے نئے API فیچرز، اور “ایجینٹک” ٹول کالنگ برتاؤ۔
GPT-5.2 میں اپ گریڈ کی گئی 5 بنیادی صلاحیتیں
1) کیا GPT-5.2 کثیر مرحلہ منطق اور ریاضی میں بہتر ہے؟
GPT-5.2 زیادہ تیز کثیر مرحلہ استدلال اور ریاضی و ساختہ مسئلہ حل کرنے میں واضح طور پر مضبوط کارکردگی لاتا ہے۔ OpenAI کے مطابق انہوں نے استدلالی کوشش پر مزید باریک سطح کا کنٹرول شامل کیا ہے (نئی سطحیں جیسے xhigh)، “reasoning token” سپورٹ انجینئر کی ہے، اور ماڈل کو اس طرح ٹیون کیا ہے کہ وہ طویل داخلی استدلالی ٹریسز کے دوران chain-of-thought برقرار رکھے۔ FrontierMath اور ARC-AGI طرز کے ٹیسٹس جیسے بینچ مارکس GPT-5.1 کے مقابلے میں معنی خیز اضافے دکھاتے ہیں؛ یہ سائنسی اور مالیاتی ورک فلو میں استعمال ہونے والے ڈومین-خصوصی بینچ مارکس پر بڑے مارجن دکھاتا ہے۔ خلاصہ یہ کہ: جب اسے سوچنے کو کہا جائے تو GPT-5.2 “زیادہ دیر تک سوچتا” ہے، اور زیادہ پیچیدہ علامتی/ریاضیاتی کام زیادہ مستقل مزاجی کے ساتھ کر سکتا ہے۔

| RC-AGI-1 (Verified) Abstract reasoning | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) Abstract reasoning | 52.9% | 17.6% |
GPT-5.2 Thinking نے متعدد اعلیٰ درجے کے سائنس اور ریاضی استدلالی ٹیسٹس میں ریکارڈ قائم کیے:
- GPQA Diamond Science Quiz: 92.4% (Pro ورژن 93.2%)
- ARC-AGI-1 Abstract Reasoning: 86.2% (پہلا ماڈل جو 90% کی حد عبور کرتا ہے)
- ARC-AGI-2 Higher Order Reasoning: 52.9%، Thinking Chain ماڈل کے لیے نیا ریکارڈ
- FrontierMath Advanced Mathematics Test: 40.3%، اپنے پیش رو سے کہیں آگے؛
- HMMT Math Competition Problems: 99.4%
- AIME Math Test: 100% Complete Solution
مزید برآں، GPT-5.2 Pro (High) ARC-AGI-2 پر جدید ترین سطح پر ہے، فی ٹاسک $15.72 کی لاگت پر 54.2% اسکور حاصل کرتے ہوئے! دیگر تمام ماڈلز سے بہتر کارکردگی۔
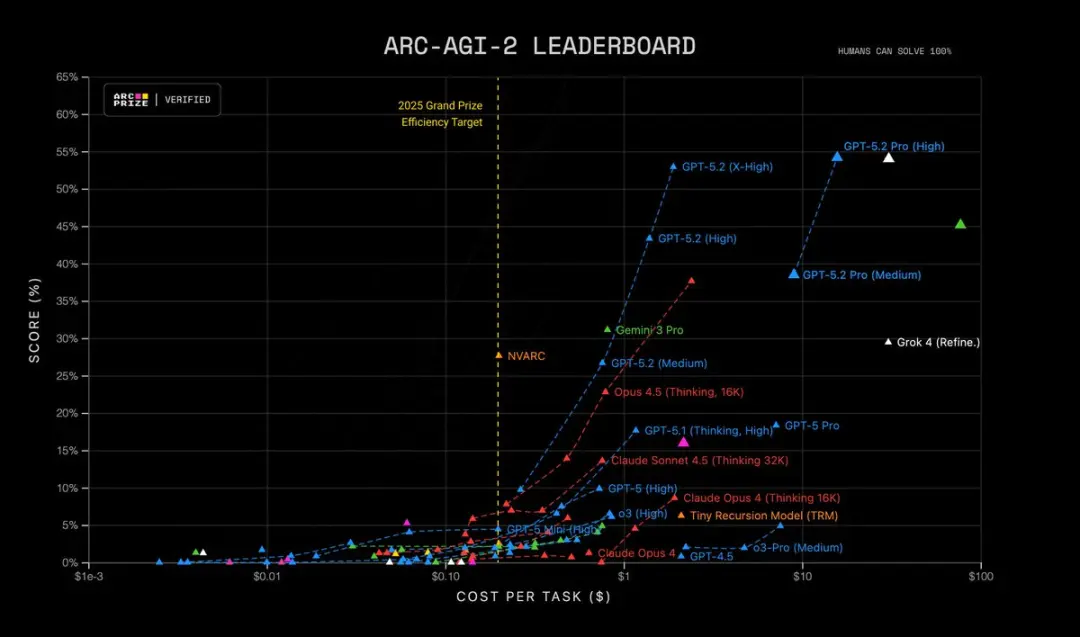
یہ کیوں اہم ہے: بہت سے حقیقی دنیا کے کام — مالیاتی ماڈلنگ، تجربہ ڈیزائن، رسمی استدلال درکار پروگرام سنتھیسز — ایک ماڈل کی اس صلاحیت سے بندھے ہوتے ہیں کہ وہ کئی درست مراحل کو زنجیر کی صورت میں جوڑ سکے۔ GPT-5.2 “خیالی مراحل” کو کم کرتا ہے اور جب آپ اسے اپنا کام دکھانے کے لیے کہتے ہیں تو زیادہ مستحکم درمیانی استدلالی ٹریسز پیدا کرتا ہے۔
2) طویل متن کی فہم اور بین-دستاویزی استدلال کیسے بہتر ہوا ہے؟
طویل سیاق و سباق کی سمجھ نمایاں بہتریوں میں سے ایک ہے۔ GPT-5.2 کا بنیادی ماڈل 400k-ٹوکن کانٹیکسٹ ونڈو کو سپورٹ کرتا ہے اور — اہم بات — جیسے جیسے متعلقہ مواد سیاق کے اندر مزید گہرائی میں جاتا ہے، یہ زیادہ درستگی برقرار رکھتا ہے۔ GDPval، “خوب وضاحت شدہ علمی کام” کے لیے ایک ٹاسک سوئٹ جو 44 پیشوں پر محیط ہے، وہاں GPT-5.2 Thinking بہت سے کاموں پر ماہر انسانی ججوں کے برابر یا بہتر سطح تک پہنچتا ہے۔ آزاد رپورٹس کی تصدیق ہے کہ ماڈل کئی دستاویزات میں معلومات کو پہلے کے ماڈلز کی نسبت زیادہ بہتر طریقے سے تھامتا اور یکجا کرتا ہے۔ یہ کاموں جیسے ڈیو ڈیلیجنس، قانونی خلاصہ سازی، لٹریچر ریویوز، اور کوڈ بیس کی فہم کے لیے حقیقی طور پر عملی پیش رفت ہے۔
GPT-5.2 256,000 ٹوکن تک کے کانٹیکسٹس کو ہینڈل کر سکتا ہے (تقریباً 200+ صفحات کی دستاویزات)۔ مزید یہ کہ، "OpenAI MRCRv2" طویل-متن فہم ٹیسٹ میں، GPT-5.2 Thinking نے درستگی کی شرح تقریباً 100% کے قریب حاصل کی۔
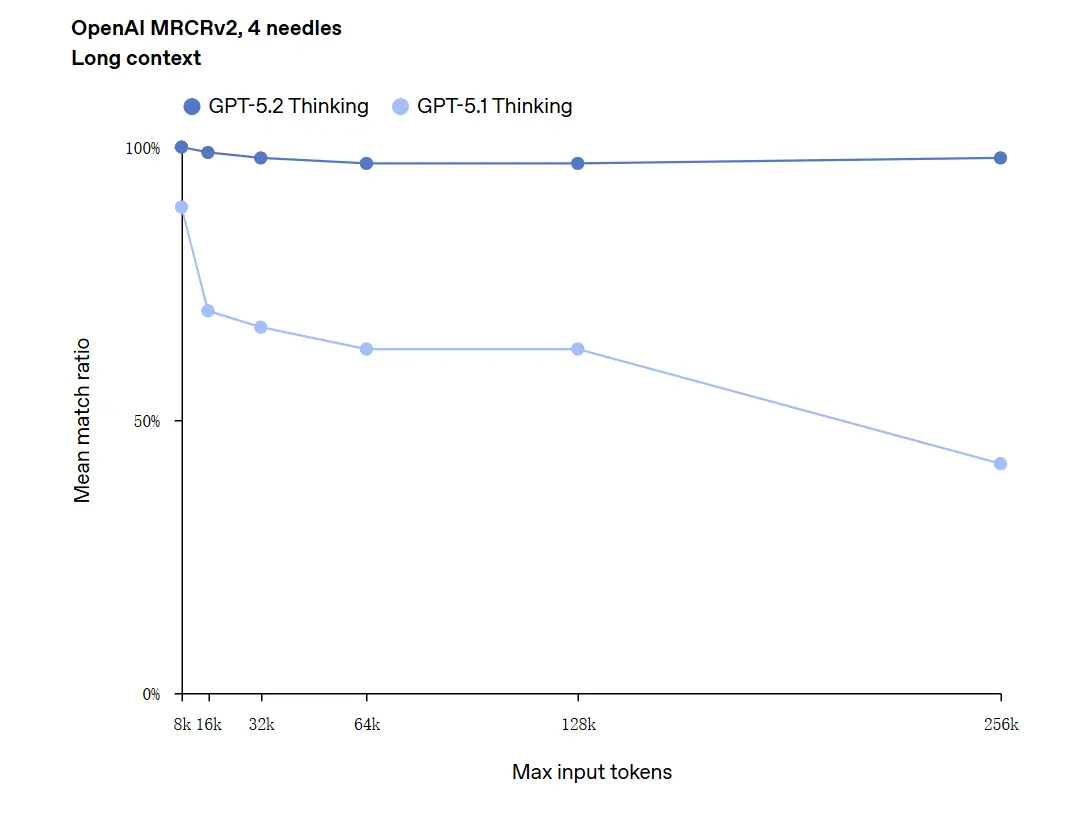
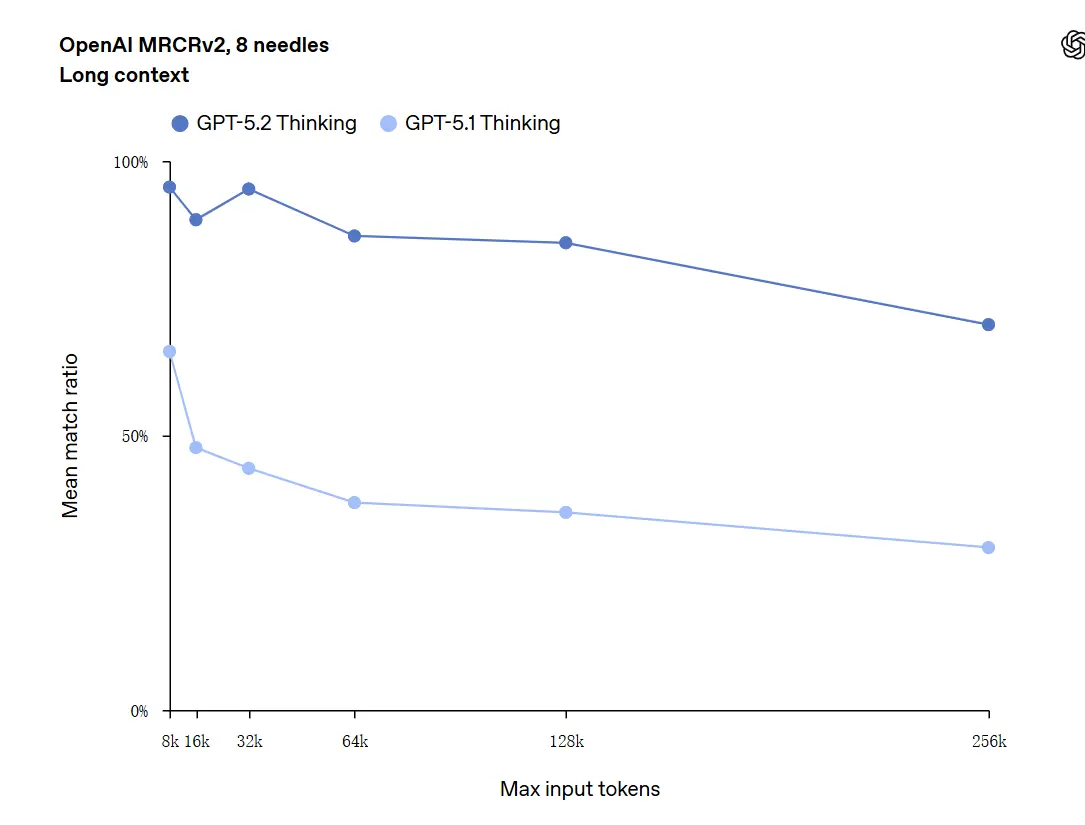
“100% درستگی” کے بارے میں نوٹ: ان بہتریوں کو مخصوص باریک مائیکرو-ٹاسکس کے لیے “100% کے قریب” بیان کیا گیا؛ OpenAI کے ڈیٹا کو بہتر طور پر “جدید ترین اور بہت سے معاملات میں جانچے گئے کاموں پر انسانی ماہر سطح سے برابر یا بلند” کہا جا سکتا ہے، نہ کہ تمام استعمالات میں لفظی طور پر بے عیب۔ بینچ مارکس بڑے اضافے دکھاتے ہیں لیکن عالمگیر کمال نہیں۔
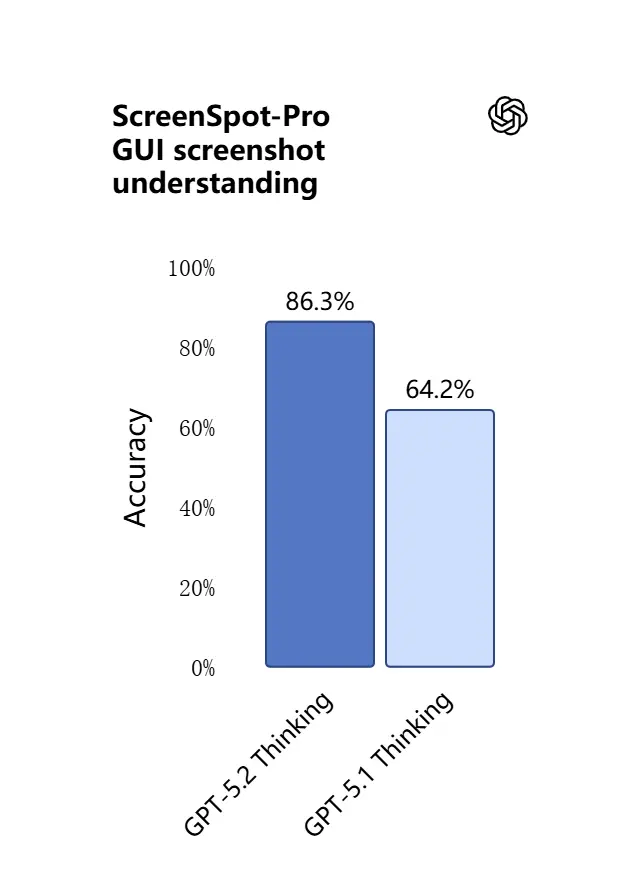
3) بصری فہم اور ملٹی موڈل استدلال میں کیا نیا ہے؟
GPT-5.2 میں وژن صلاحیتیں زیادہ باریک اور عملی ہیں۔ ماڈل اسکرین شاٹس کی بہتر تشریح کرتا ہے، چارٹس اور جدولیں پڑھتا ہے، UI عناصر کو شناخت کرتا ہے، اور بصری اِن پٹس کو طویل متنی سیاق کے ساتھ ملاتا ہے۔ یہ صرف کیپشننگ نہیں: GPT-5.2 تصاویر سے ساختہ ڈیٹا اخذ کر سکتا ہے (مثلاً کسی PDF میں جدولیں)، گراف کی وضاحت کر سکتا ہے، اور ڈایاگرامز پر یوں استدلال کرتا ہے کہ جو بعد ازاں ٹول کارروائیوں کو سہارا دے (مثلاً فوٹوگرافتہ رپورٹ سے اسپریڈشیٹ تیار کرنا)۔
.webp)
عملی اثر: ٹیمیں مکمل سلائیڈ ڈیکس، اسکین شدہ تحقیقی رپورٹس، یا تصاویر سے بھرپور دستاویزات براہ راست ماڈل میں فیڈ کر سکتی ہیں اور بین-دستاویزی خلاصوں کی درخواست کر سکتی ہیں — دستی استخراجی کام میں بہت کمی واقع ہوتی ہے۔
4) ٹول کالنگ اور ٹاسک ایگزیکیوشن میں کیا تبدیلی آئی ہے؟
GPT-5.2 ایجینٹک برتاؤ میں مزید آگے بڑھتا ہے: یہ کثیر مرحلہ کاموں کی منصوبہ بندی میں بہتر ہے، فیصلہ کرتا ہے کہ کب بیرونی ٹولز کو کال کرنا ہے، اور کسی کام کو ابتدا سے انجام تک مکمل کرنے کے لیے API/ٹول کالز کی تسلسل کے ساتھ ایگزیکیوشن کرتا ہے۔ “ایجینٹک ٹول-کالنگ” میں بہتریاں — ماڈل ایک منصوبہ تجویز کرے گا، ٹولز (ڈیٹابیسز، کمپیوٹ، فائل سسٹمز، براؤزر، کوڈ رنرز) کو کال کرے گا، اور پہلے سے زیادہ قابلِ اعتماد طریقے سے نتائج کو آخری ڈِلیوریبل میں سنسِتھسائز کرے گا۔ API روٹنگ اور حفاظتی کنٹرولز متعارف کراتا ہے (allowed tools فہرستیں، ٹول اسکیفولڈنگ) اور ChatGPT UI درخواستوں کو مناسب 5.2 متغیر (Instant بمقابلہ Thinking) کی جانب خودکار طور پر روٹ کر سکتا ہے۔
GPT-5.2 نے Tau2-Bench Telecom بینچ مارک میں 98.7% اسکور کیا، جس سے پیچیدہ کثیر-ٹرن کاموں میں اس کی پختہ ٹول-کالنگ صلاحیتوں کا اظہار ہوتا ہے۔
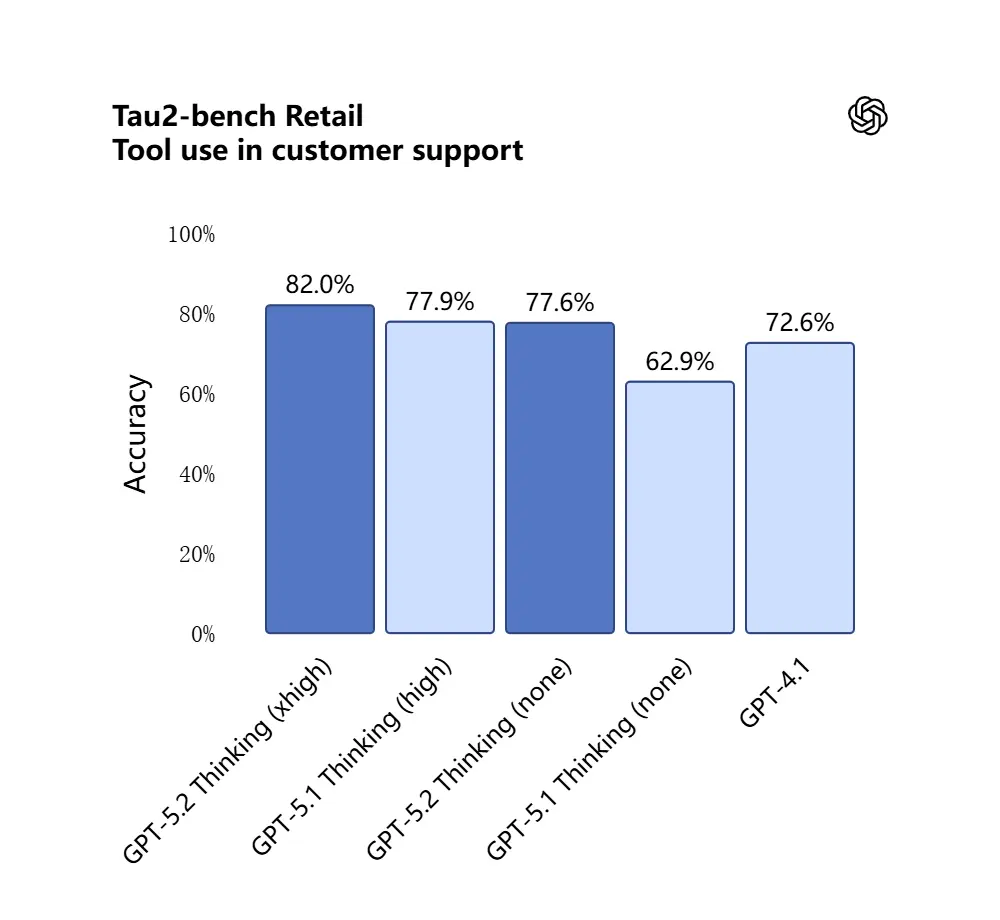
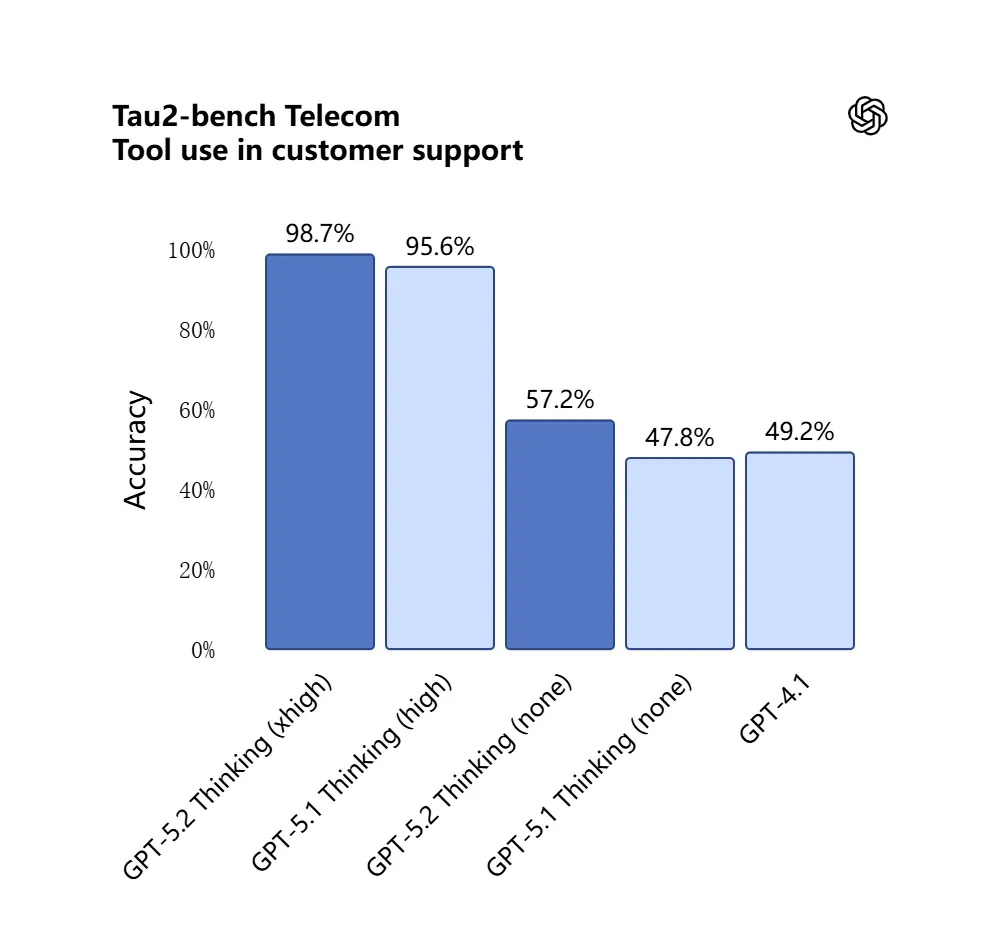
یہ کیوں اہم ہے: اس سے GPT-5.2 ایسے خودکار معاون کے طور پر زیادہ مفید بن جاتا ہے جن کاموں کے لیے “ان کنٹریکٹس کو اِن جیسٹ کرو، کلازز نکالو، اسپریڈشیٹ اپ ڈیٹ کرو، اور خلاصہ ای میل لکھو” — وہ ورک فلو جنہیں پہلے محتاط آرکیسٹریشن درکار ہوتی تھی۔
5) پروگرامنگ صلاحیت میں ارتقا
GPT-5.2 سافٹ ویئر انجینئرنگ کے کاموں میں نمایاں طور پر بہتر ہے: یہ زیادہ مکمل ماڈیولز لکھتا ہے، ٹیسٹس زیادہ قابل اعتماد طریقے سے جنریٹ اور رن کرتا ہے، پیچیدہ پروجیکٹ ڈپنڈینسی گرافس کو سمجھتا ہے، اور “سست کوڈنگ” (بوائلر پلیٹ چھوڑ دینا یا ماڈیولز کو آپس میں جوڑنے میں ناکامی) کی جانب کم مائل ہے۔ انڈسٹری-گریڈ کوڈنگ بینچ مارکس (SWE-bench Pro، وغیرہ) پر GPT-5.2 نئے ریکارڈز قائم کرتا ہے۔ وہ ٹیمیں جو LLMs کو پیئر-پروگرامرز کے طور پر استعمال کرتی ہیں، اس بہتری سے جنریشن کے بعد درکار دستی توثیق اور ری ورک کم ہو سکتا ہے۔
SWE-Bench Pro ٹیسٹ (حقیقی دنیا کے صنعتی سافٹ ویئر انجینئرنگ کام) میں، GPT-5.2 Thinking کا اسکور 55.6% تک بہتر ہوا، جبکہ SWE-Bench Verified ٹیسٹ میں اس نے 80% کی نئی بلند سطح بھی حاصل کی۔
_Software%20engineering.webp)
عملی اطلاقات میں، اس کا مطلب ہے:
- پروڈکشن ماحول کے کوڈ کی خودکار ڈیبگنگ زیادہ استحکام کی طرف لے جاتی ہے؛
- ملٹی-لینگویج پروگرامنگ کی سپورٹ (صرف Python تک محدود نہیں)؛
- اختتام تک مرمت کے کاموں کو خودمختار طور پر مکمل کرنے کی قابلیت۔
GPT-5.2 اور GPT-5.1 میں کیا فرق ہیں؟
مختصر جواب: GPT-5.2 ایک تکراری لیکن معنی خیز بہتری ہے۔ یہ GPT-5 خاندان کی آرکیٹیکچر اور ملٹی موڈل بنیادوں کو برقرار رکھتا ہے، لیکن چار عملی جہتوں میں پیش رفت کرتا ہے:
- استدلال کی گہرائی اور مستقل مزاجی۔ 5.2 کثیر مرحلہ مسائل کے لیے اعلیٰ تر استدلالی کوشش کی سطحیں متعارف کراتا ہے اور بہتر چیننگ فراہم کرتا ہے؛ 5.1 نے پہلے استدلال بہتر کیا تھا، مگر 5.2 پیچیدہ ریاضی اور کثیر مرحلہ منطق کے لیے چھت بلند کرتا ہے۔
- طویل سیاق و سباق پر قابلِ اعتماد کارکردگی۔ دونوں ورژنز نے کانٹیکسٹ کو وسعت دی، مگر 5.2 کو اس طرح ٹیون کیا گیا ہے کہ وہ بہت طویل ان پٹس کے اندر گہرائی تک درستگی برقرار رکھے (OpenAI سیکڑوں ہزار ٹوکن تک بہتر برقرار رکھنے کا دعویٰ کرتا ہے)۔
- وژن + ملٹی موڈل وفاداری۔ 5.2 تصاویر اور متن کے مابین کراس-ریفرنسنگ کو بہتر بناتا ہے — مثلاً کسی چارٹ کو پڑھنا اور اس ڈیٹا کو اسپریڈشیٹ میں ضم کرنا — کام کی سطح پر زیادہ درستگی دکھاتا ہے۔
- ایجینٹک ٹول برتاؤ اور API فیچرز۔ 5.2 API میں نئی استدلالی کوشش کی پیرامیٹرز (
xhigh) اور کانٹیکسٹ کمپیکشن فیچرز ظاہر کرتا ہے، اور OpenAI نے ChatGPT میں روٹنگ لاجک کو بہتر کیا ہے تاکہ UI خودکار طور پر بہترین متغیر منتخب کر سکے۔ - کم غلطیاں، زیادہ استحکام: GPT-5.2 اپنی "وہم کی شرح" (غلط جواب کی شرح) کو 38% تک کم کرتا ہے۔ یہ تحقیق، تحریر، اور تجزیاتی سوالات کے جواب زیادہ قابل اعتماد طریقے سے دیتا ہے، “من گھڑت حقائق” کے واقعات کو کم کرتا ہے۔ پیچیدہ کاموں میں، اس کا ساختہ آؤٹ پٹ زیادہ واضح اور اس کی منطق زیادہ مستحکم ہوتی ہے۔ اسی دوران، ذہنی صحت سے متعلق کاموں میں ماڈل کی جوابی حفاظت نمایاں طور پر بہتر ہوئی ہے۔ ذہنی صحت، خود کو نقصان پہنچانے، خودکشی، اور جذباتی انحصار جیسے حساس منظرناموں میں یہ زیادہ مضبوط کارکردگی دکھاتا ہے۔
سسٹم ایویلیوشنز میں، GPT-5.2 Instant نے "Mental Health Support" ٹاسک پر 0.995 (1.0 میں سے) اسکور کیا، جو GPT-5.1 (0.883) سے نمایاں طور پر بلند ہے۔
مقداری طور پر، OpenAI کے شائع شدہ بینچ مارکس GDPval، ریاضی بینچ مارکس (FrontierMath)، اور سافٹ ویئر انجینئرنگ ایویلیوشنز پر قابل پیمائش اضافے دکھاتے ہیں۔ GPT-5.2 جونیئر انویسٹمنٹ بینکنگ اسپرڈ شیٹ کے کاموں میں GPT-5.1 سے چند فیصد پوائنٹس بہتر کارکردگی دکھاتا ہے۔
کیا GPT-5.2 مفت ہے — اس کی قیمت کتنی ہے؟
کیا میں GPT-5.2 مفت استعمال کر سکتے ہیں؟
OpenAI نے GPT-5.2 کو ادائیگی والے ChatGPT منصوبوں اور API رسائی سے شروع کرتے ہوئے رول آؤٹ کیا۔ تاریخی طور پر OpenAI نے سب سے تیز/گہرے ماڈلز کو ادائیگی والے ٹئیرز کے پیچھے رکھا ہے جبکہ ہلکے متغیرات بعد میں زیادہ وسیع پیمانے پر دستیاب کیے ہیں؛ 5.2 کے ساتھ کمپنی نے کہا کہ رول آؤٹ ادائیگی والے منصوبوں (Plus، Pro، Business، Enterprise) پر شروع ہو گا اور API ڈویلپرز کے لیے دستیاب ہے۔ اس کا مطلب ہے کہ فوری مفت رسائی محدود ہے: مفت ٹئیر کو بعد میں جیسے جیسے OpenAI رول آؤٹ کو وسعت دے، کمزور یا روٹڈ رسائی (مثلاً ہلکے سب-متغیرات کی جانب) مل سکتی ہے۔
اچھی خبر یہ ہے کہ CometAPI اب GPT-5.2 کے ساتھ انٹیگریٹڈ ہے، اور فی الحال کرسمس سیل جاری ہے۔ آپ اب CometAPI کے ذریعے GPT-5.2 کا استعمال کر سکتے ہیں؛ playground آپ کو GPT-5.2 کے ساتھ آزادانہ طور پر انٹریکٹ کرنے کی اجازت دیتا ہے، اور ڈویلپرز GPT-5.2 API (CometAPI کی قیمت OpenAI کی 20% ہے) استعمال کر کے ورک فلو بنا سکتے ہیں۔
API کے ذریعے (ڈویلپر/پروڈکشن استعمال) اس کی قیمت کیا ہے؟
API استعمال فی ٹوکن بل کیا جاتا ہے۔ لانچ کے وقت OpenAI کے شائع شدہ پلیٹ فارم پرائسنگ دکھاتی ہے (CometAPI کی قیمت OpenAI کی 20% ہے):
- GPT-5.2 (standard chat) — $1.75 فی 1M ان پٹ ٹوکن اور $14 فی 1M آؤٹ پٹ ٹوکن (کیچڈ اِن پٹ پر رعایتیں لاگو ہوتی ہیں)۔
- GPT-5.2 Pro (flagship) — $21 فی 1M ان پٹ ٹوکن اور $168 فی 1M آؤٹ پٹ ٹوکن (نمایاں طور پر زیادہ مہنگا کیونکہ اسے اعلیٰ درستگی، کمپیوٹ-ہیوی ورک لوڈز کے لیے بنایا گیا ہے)۔
- موازنہ کے طور پر، GPT-5.1 سستا تھا (مثلاً $1.25 اِن / $10 آؤٹ فی 1M ٹوکن)۔
تشریح: API لاگتیں سابقہ نسلوں کے مقابلے میں بڑھ گئی ہیں؛ قیمت سے اشارہ ملتا ہے کہ 5.2 کی پریمیم استدلال اور طویل سیاق کارکردگی کو ایک الگ پروڈکٹ ٹئیر کے طور پر قیمت دی گئی ہے۔ پروڈکشن سسٹمز میں، منصوبہ لاگتیں اس بات پر بہت منحصر ہوتی ہیں کہ آپ کتنے ٹوکن اِن پٹ/آؤٹ پٹ کرتے ہیں اور کتنی بار کیچڈ اِن پٹس کو دوبارہ استعمال کرتے ہیں (کیچڈ اِن پٹس پر بھاری رعایتیں ملتی ہیں)۔
عملاً اس کا کیا مطلب ہے
- ChatGPT کے UI کے ذریعے عام استعمال کے لیے، ماہانہ سبسکرپشن منصوبے (Plus، Pro، Business، Enterprise) مرکزی راستہ ہیں۔ GPT-5.2 ریلیز کے ساتھ ChatGPT سبسکرپشن ٹئیرز کی قیمتیں تبدیل نہیں ہوئیں (OpenAI عام طور پر منصوبہ قیمتیں مستحکم رکھتا ہے چاہے ماڈل آفرنگز بدل جائیں)۔
- پروڈکشن اور ڈویلپر استعمال کے لیے، ٹوکن لاگت کا بجٹ رکھیں۔ اگر آپ کی ایپ طویل جوابات اسٹریم کرتی ہے یا طویل دستاویزات پر کارروائی کرتی ہے، تو آؤٹ پٹ ٹوکن پرائسنگ ($14 / 1M ٹوکن Thinking کے لیے) لاگت پر غالب رہے گی، جب تک کہ آپ اِن پٹس کو احتیاط سے کیچ نہ کریں اور آؤٹ پٹس کو دوبارہ استعمال نہ کریں۔
GPT-5.2 Instant بالمقابل GPT-5.2 Thinking بالمقابل GPT-5.2 Pro
OpenAI نے GPT-5.2 کو تین مقصدی-ٹئیرڈ متغیرات کے ساتھ لانچ کیا تاکہ استعمال کے کیسز سے مماثلت ہو سکے: Instant، Thinking، اور Pro:
- GPT-5.2 Instant: تیز، لاگت-موثر، روزمرہ کام کے لیے ٹیونڈ — FAQs، ہاؤ-ٹوز، ترجمہ، تیز ڈرافٹنگ۔ کم لیٹنسی؛ اچھے ابتدائی ڈرافٹس اور سادہ ورک فلو۔
- GPT-5.2 Thinking: پائیدار کام کے لیے گہرے، اعلیٰ معیار کے جوابات — طویل دستاویزات کا خلاصہ، کثیر مرحلہ منصوبہ بندی، تفصیلی کوڈ ریویوز۔ لیٹنسی اور معیار میں توازن؛ پیشہ ورانہ کاموں کے لیے ڈیفالٹ ‘ورک ہارس’۔
- GPT-5.2 Pro: اعلیٰ ترین معیار اور قابلِ اعتماد۔ سست اور مہنگا؛ مشکل، اعلیٰ-اسٹیکس کاموں (پیچیدہ انجینئرنگ، قانونی سنتھیسز، اعلیٰ قدر فیصلے) اور جہاں ‘xhigh’ استدلالی کوشش درکار ہو، کے لیے بہترین۔
تقابلی جدول
| Feature / Metric | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Intended use | روزمرہ کام، تیز ڈرافٹس | گہرا تجزیہ، طویل دستاویزات | اعلیٰ معیار، پیچیدہ مسائل |
| Latency | سب سے کم | معتدل | سب سے زیادہ |
| Reasoning effort | معیاری | High | xHigh دستیاب |
| Best for | FAQ، ٹیوٹوریلز، ترجمہ، مختصر پرامپٹس | خلاصے، منصوبہ بندی، اسپریڈشیٹس، کوڈنگ کام | پیچیدہ انجینئرنگ، قانونی سنتھیسز، تحقیق |
| API name examples | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Input token price (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Output token price (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Availability (ChatGPT) | رول آؤٹ جاری؛ پہلے ادائیگی والے منصوبے | ادائیگی والے منصوبوں کو رول آؤٹ | Pro صارفین / Enterprise (ادائیگی والے) |
| Typical use case example | ای میل ڈرافٹنگ، معمولی کوڈ اسنیپٹس | ملٹی-شیٹ مالیاتی ماڈل بنانا، طویل رپورٹ Q&A | کوڈ بیس کا آڈٹ، پروڈکشن-گریڈ سسٹم ڈیزائن جنریٹ کرنا |
کن لوگوں کے لیے GPT-5.2 موزوں ہے؟
GPT-5.2 کو وسیع ہدفی صارفین کو ذہن میں رکھ کر ڈیزائن کیا گیا ہے۔ ذیل میں کردار-بنیاد سفارشات ہیں:
انٹرپرائزز اور پروڈکٹ ٹیمیں
اگر آپ علمی کام کی پروڈکٹس بناتے ہیں (ریسرچ اسسٹنٹس، کنٹریکٹ ریویو، اینالیٹکس پائپ لائنز، یا ڈیویلپر ٹولنگ)، تو GPT-5.2 کی طویل-کانٹیکسٹ اور ایجینٹک صلاحیتیں انٹیگریشن پیچیدگی کو نمایاں طور پر کم کر سکتی ہیں۔ وہ انٹرپرائزز جنہیں مضبوط دستاویزی فہم، خودکار رپورٹنگ، یا ذہین کوپائلٹس درکار ہیں، Thinking/Pro مفید پائیں گے۔ Microsoft اور دیگر پلیٹ فارم پارٹنرز پہلے ہی 5.2 کو پروڈکٹیوٹی اسٹیکس (مثلاً Microsoft 365 Copilot) میں ضم کر رہے ہیں۔
ڈیویلپرز اور انجینئرنگ ٹیمیں
وہ ٹیمیں جو LLMs کو پیئر-پروگرامرز کے طور پر استعمال کرنا چاہتی ہیں یا کوڈ جنریشن/ٹیسٹنگ کو خودکار بنانا چاہتی ہیں، 5.2 میں بہتر پروگرامنگ وفاداری سے فائدہ اٹھائیں گی۔ API رسائی (thinking یا pro موڈز کے ساتھ) 400k ٹوکن کانٹیکسٹ ونڈو کی بدولت بڑے کوڈ بیسز کی گہری سنتھیسز کو فعال کرتی ہے۔ Pro استعمال کرنے پر API پر زیادہ ادائیگی کی توقع رکھیں، مگر پیچیدہ سسٹمز کے لیے دستی ڈیبگنگ اور ریویو میں کمی اس لاگت کو جواز بخش سکتی ہے۔
محققین اور ڈیٹا-مرکوز تجزیہ کار
اگر آپ باقاعدگی سے لٹریچر کو سنتھیسائز کرتے ہیں، طویل تکنیکی رپورٹس پارس کرتے ہیں، یا ماڈل-معاون تجربہ ڈیزائن چاہتے ہیں، تو GPT-5.2 کی طویل-کانٹیکسٹ اور ریاضی بہتریاں ورک فلو کو تیز کرنے میں مدد دیتی ہیں۔ قابلِ تکرار تحقیق کے لیے، ماڈل کو محتاط پرامپٹ انجینئرنگ اور توثیقی مراحل کے ساتھ جوڑیں۔
چھوٹے کاروبار اور پاور صارفین
ChatGPT Plus (اور پاور صارفین کے لیے Pro) کو 5.2 متغیرات کی جانب روٹڈ رسائی ملے گی؛ یہ چھوٹی ٹیموں کے لیے، بغیر API انٹیگریشن بنائے، اعلیٰ درجے کی آٹومیشن اور اعلیٰ معیار کے آؤٹ پٹس کو قابلِ رسائی بناتا ہے۔ غیر تکنیکی صارفین جنہیں بہتر دستاویزی خلاصہ سازی یا سلائیڈ بلڈنگ درکار ہو، GPT-5.2 عملی قدر میں نمایاں اضافہ کرتا ہے۔
ڈیویلپرز اور آپریٹرز کے لیے عملی نوٹس
API فیچرز جن پر توجہ دیں
reasoning.effortلیولز (مثلاًmedium,high,xhigh) آپ کو بتانے دیتی ہیں کہ ماڈل داخلی استدلال پر کتنی کمپیوٹ خرچ کرے؛ اس کو فی-ریکویسٹ بنیاد پر لیٹنسی بمقابلہ درستگی کے لیے استعمال کریں۔- Context compaction: API میں ہسٹری کو کمپریس اور کمپیکٹ کرنے کے ٹولز شامل ہیں تاکہ واقعی متعلقہ مواد طویل سلسلوں کے لیے محفوظ رہے۔ جب آپ کو مؤثر ٹوکن استعمال قابلِ انتظام رکھنا ہو، یہ نہایت اہم ہے۔
- Tool scaffolding اور allowed-tools کنٹرولز: پروڈکشن سسٹمز صراحت کے ساتھ اس بات کی وائٹ لسٹنگ کریں کہ ماڈل کیا انوک کر سکتا ہے اور آڈٹنگ کے لیے ٹول کالز کو لاگ کریں۔
لاگت کنٹرول کے مشورے
- اکثر استعمال ہونے والی دستاویزی ایمبیڈنگز کو کیچ کریں اور کیچڈ اِن پٹس (جنہیں نمایاں رعایتیں ملتی ہیں) کو ایک ہی کارپس کے خلاف دہرائے گئے سوالات کے لیے استعمال کریں۔ OpenAI کے پلیٹ فارم پرائسنگ میں کیچڈ اِن پٹس کے لیے قابل ذکر رعایتیں شامل ہیں۔
- دریافت/کم-قدر سوالات کو Instant کی جانب روٹ کریں اور Thinking/Pro کو بیچ جابز یا آخری پاسز کے لیے محفوظ رکھیں۔
- API لاگت کا اندازہ لگاتے وقت ٹوکن استعمال (اِن پٹ + آؤٹ پٹ) احتیاط سے تخمینہ کریں کیونکہ طویل آؤٹ پٹس لاگت کو ضرب دے دیتے ہیں۔
خلاصہ — کیا آپ کو GPT-5.2 پر اپ گریڈ کرنا چاہیے؟
اگر آپ کا کام طویل-دستاویزی استدلال، بین-دستاویزی سنتھیسز، ملٹی موڈل تشریح (تصاویر + متن)، یا ٹولز کو کال کرنے والے ایجنٹس بنانے پر منحصر ہے، تو GPT-5.2 واضح اپ گریڈ ہے: یہ عملی درستگی بلند کرتا ہے اور دستی انٹیگریشن کام کم کرتا ہے۔ اگر آپ بنیادی طور پر ہائی-والیوم، کم-لیٹنسی چیٹ بوٹس چلاتے ہیں یا سخت بجٹ پابندیوں والے ایپلی کیشنز ہیں، تو Instant (یا پہلے ماڈلز) اب بھی مناسب انتخاب ہو سکتے ہیں۔
GPT-5.2 “بہتر چیٹ” سے “بہتر پیشہ ورانہ معاون” کی جانب ایک سوچا-سمجھا قدم ہے: زیادہ کمپیوٹ، زیادہ قابلیت، اور بلند لاگت ٹئیرز — لیکن ساتھ ہی حقیقی پیداواری فائدے ان ٹیموں کے لیے جو قابلِ اعتماد طویل-کانٹیکسٹ، بہتر ریاضی/استدلال، تصویر فہم، اور ایجینٹک ٹول ایگزیکیوشن سے فائدہ اٹھا سکتے ہیں۔
شروع کرنے کے لیے، GPT-5.2 ماڈلز(GPT-5.2;GPT-5.2 pro, GPT-5.2 chat ) کی صلاحیتوں کو Playground میں دریافت کریں اور تفصیلی ہدایات کے لیے API guide سے رجوع کریں۔ رسائی سے پہلے، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ اِن کر لیا ہے اور API کلید حاصل کر لی ہے۔ CometAPI انٹیگریشن میں مدد کے لیے سرکاری قیمت سے کہیں کم قیمت پیش کرتی ہے۔
تیار ہیں؟→ GPT-5.2 ماڈلز کا مفت ٹرائل !