

Trong bản cập nhật tháng 10, OpenAI đã báo cáo rằng khoảng 0.15% người dùng hoạt động hàng tuần có các cuộc trò chuyện chứa các chỉ số rõ ràng về khả năng lập kế hoạch hoặc ý định tự tử — một tỷ lệ tương ứng với cơ sở người dùng lớn của ChatGPT khi được mở rộng theo hơn một triệu người mỗi tuần Khi thảo luận về các chủ đề liên quan đến tự tử với dịch vụ này, họ đã tập trung vào một câu hỏi hóc búa: liệu các mô hình ngôn ngữ lớn có thể phản hồi một cách có ý nghĩa và an toàn khi mọi người đưa ra những lo ngại nghiêm trọng về sức khỏe tâm thần — bao gồm chứng loạn thần, hưng cảm, ý định tự tử và sự phụ thuộc cảm xúc sâu sắc — vào một cuộc trò chuyện hay không?
Do đó, bản cập nhật tháng 10 của OpenAI cho GPT-5 — được đưa vào sản xuất dưới dạng gpt-5-oct-3 Bản cập nhật — thể hiện nỗ lực rõ ràng và có cân nhắc nhất của công ty nhằm giúp các mô hình ngôn ngữ lớn (LLM) an toàn và hữu ích hơn khi người dùng nêu lên các vấn đề sức khỏe tâm thần. Những thay đổi này không phải là một giải pháp thần kỳ duy nhất; chúng là một tập hợp các bước kỹ thuật, quy trình và đánh giá nhằm giảm thiểu các kết quả đầu ra có hại hoặc không hữu ích, đưa các nguồn lực chuyên môn lên bề mặt và ngăn cản người dùng dựa vào mô hình này thay thế cho chăm sóc lâm sàng. Nhưng hệ thống thực tế đã tốt hơn bao nhiêu, chính xác là đã thay đổi những gì và những rủi ro còn lại là gì?
OpenAI đã cập nhật những gì trong gpt-5 và tại sao điều đó lại quan trọng?
OpenAI đã triển khai bản cập nhật cho mô hình GPT-5 mặc định của ChatGPT (thường được gọi trong truyền thông là gpt-5-oct-3) được thiết kế đặc biệt để tăng cường hành vi của mô hình trong cuộc trò chuyện nhạy cảm — bao gồm các dấu hiệu của chứng rối loạn tâm thần hoặc hưng cảm, ý định hoặc kế hoạch tự tử, hoặc loại phụ thuộc về mặt cảm xúc vào AI có thể thay thế các mối quan hệ trong thế giới thực.
Những thay đổi này được đưa ra dựa trên kết quả tham vấn với hơn 170 chuyên gia về sức khỏe tâm thần và các phân loại nội bộ mới cùng các đánh giá tự động được thiết kế xung quanh “hành vi mong muốn” cụ thể, sau khi được các chuyên gia tâm lý tối ưu hóa, mô hình GPT-5:
- Trên các bộ thử thách sức khỏe tâm thần được nhắm mục tiêu, mô hình GPT-5 mới đã ghi điểm ~ 92% tuân thủ theo phân loại hành vi mong muốn của công ty (so với tỷ lệ phần trăm thấp hơn nhiều đối với các phiên bản trước trên các bộ thử nghiệm khó).
- Đối với các trường hợp tự gây thương tích và tự tử, các đánh giá tự động đã tăng lên ~ 91% sự tuân thủ từ 77% trên biến thể GPT-5 trước đó trong điểm chuẩn cụ thể được mô tả. OpenAI cũng báo cáo ~ 65% giảm tỷ lệ phản hồi “không tuân thủ đầy đủ” trên một số lĩnh vực sức khỏe tâm thần trong giao thông sản xuất.
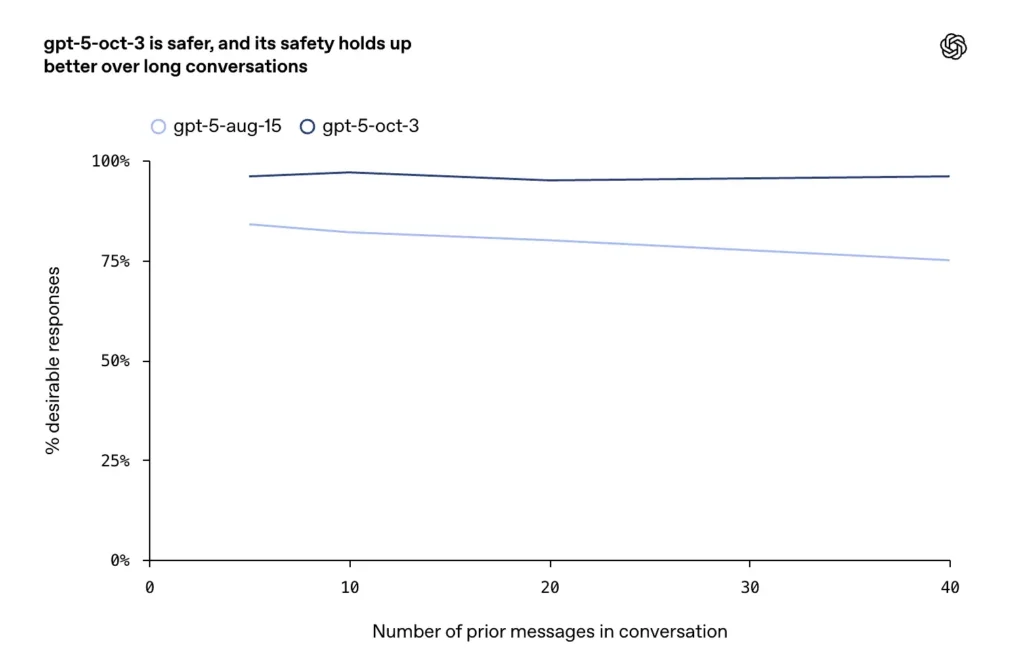
- Những cải tiến đã được báo cáo về các cuộc trò chuyện dài, đối đầu hoặc kéo dài (một chế độ lỗi đã biết đối với các mô hình trò chuyện), trong đó công ty cho biết các bản cập nhật tháng 10 duy trì tính nhất quán và an toàn cao hơn trong các lượt đối thoại kéo dài.
tại sao điều đó lại quan trọng
OpenAI cho biết — xét theo quy mô hiện tại của ChatGPT — ngay cả một tỷ lệ rất nhỏ các cuộc trò chuyện nhạy cảm cũng tương ứng với số lượng người dùng tuyệt đối rất lớn. Công ty báo cáo rằng, trong một tuần điển hình:
- về 0.07% của những người dùng tích cực cho thấy các dấu hiệu có thể phù hợp với chứng rối loạn tâm thần hoặc hưng cảm; và
- về 0.15% của những người dùng tích cực có các cuộc trò chuyện bao gồm các chỉ số rõ ràng về khả năng có kế hoạch hoặc ý định tự tử; và
- khoảng 0.15% người dùng tích cực thể hiện “mức độ gắn bó về mặt cảm xúc cao hơn” với ChatGPT.
Để làm cho những tỷ lệ phần trăm đó trở nên cụ thể hơn: Giám đốc điều hành của OpenAI cho biết ChatGPT có ~800 triệu người dùng hoạt động hàng tuần. Nhân sẽ cho ra số lượng người dùng tuyệt đối:
Psychosis/mania: 800,000,000 × 0.0007 = 560,000 people/week
Suicidal planning/intent: 800,000,000 × 0.0015 = 1,200,000 people/week
Emotional reliance: 800,000,000 × 0.0015 = 1,200,000 people/week
Các danh mục này rất ồn ào và chồng chéo (một cuộc trò chuyện có thể xuất hiện trong nhiều danh mục) và đây là dự toán được rút ra từ phân loại phát hiện nội bộ hơn là chẩn đoán lâm sàng.
OpenAI đã triển khai những thay đổi này như thế nào — cơ chế cải tiến năm bước?
OpenAI mô tả một quy trình đa hướng, được chuyên gia tư vấn. Dưới đây là một ví dụ được chắt lọc và tái tạo. cơ chế cải tiến năm bước phù hợp với các tiết lộ của công ty và thông lệ chung trong kỹ thuật an toàn mô hình.
Cơ chế cải tiến năm bước
- Phân loại và dán nhãn theo hướng dẫn của chuyên gia. Triệu tập các bác sĩ tâm thần, nhà tâm lý học và bác sĩ chăm sóc sức khỏe ban đầu để xác định các hành vi và ngôn ngữ biểu thị chứng loạn thần/cuồng loạn, ý định tự làm hại bản thân hoặc sự phụ thuộc về mặt cảm xúc không lành mạnh; xây dựng các tập dữ liệu có nhãn và các quy tắc xét xử.
- Thu thập dữ liệu có mục tiêu và lời nhắc được chọn lọc. Tổng hợp các đoạn hội thoại tiêu biểu, ví dụ điển hình và thông tin phản biện; bổ sung bằng bản ghi chép nhập vai có kiểm soát được tạo ra dưới sự giám sát của bác sĩ lâm sàng.
- Điều chỉnh/ tinh chỉnh mô hình với mục tiêu an toàn. Đào tạo hoặc tinh chỉnh mô hình cơ sở trên tập dữ liệu được quản lý với các điều khoản mất mát nhằm trừng phạt việc củng cố ảo tưởng, cung cấp các mẫu phản hồi an toàn và thúc đẩy việc định tuyến đến các nguồn lực khủng hoảng.
- Lớp phân loại + lớp lan can (an toàn khi chạy). Triển khai một bộ phân loại nhanh hoặc lớp giám sát có khả năng phát hiện các lượt rẽ có nguy cơ cao theo thời gian thực và thay đổi các tham số giải mã của mô hình, chuyển sang bộ phản hồi chuyên biệt hoặc chuyển đến quy trình đánh giá của con người. (Điều này rất quan trọng để tránh hành vi thiếu nhất quán khi cuộc trò chuyện bị lạc hướng.)
- Đánh giá của chuyên gia và hiệu chuẩn liên tục. Yêu cầu bác sĩ lâm sàng đánh giá mô hình phản ứng mù bằng cách sử dụng các tiêu chí đánh giá lâm sàng; đo lường tỷ lệ phản ứng không mong muốn; lặp lại phân loại, dữ liệu đào tạo và lời nhắc hệ thống. Duy trì dữ liệu đo từ xa trong quá trình sản xuất và chạy lại các chuẩn mực thường xuyên.
Dưới đây là một bản phác thảo kỹ thuật/mã giả nhỏ gọn ghi lại luồng thời gian chạy mà hầu hết các nhóm an toàn triển khai (đây là minh họa và không độc quyền):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
Quy trình sản xuất thường bao gồm các bộ phân loại ngắn hạn (nhanh), các bộ phản hồi chậm hơn nhưng chất lượng cao hơn (lời nhắc chuyên biệt/điểm kiểm tra được điều chỉnh) và đánh giá của con người đối với các trường hợp được gắn cờ. Điều này không chỉ đơn thuần là học thuật: các bác sĩ lâm sàng đã được đánh giá qua 1,800 các phản hồi của mô hình và phân loại chúng theo phân loại, và những đánh giá đó đã định hình đáng kể cách viết các lời nhắc và hành vi dự phòng.
Công chúng của OpenAI cho biết họ đã sử dụng các biến thể của cả năm bước và xếp hạng của bác sĩ lâm sàng để đánh giá kết quả:
- Các chuyên gia đã xem xét hơn 1,800 phản hồi của người mẫu.
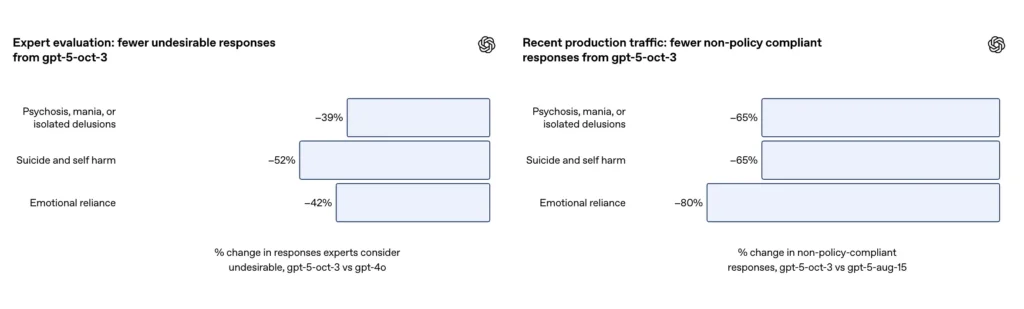
- GPT-5 đã giảm “phản hồi không thỏa đáng” từ 39–52% trên tất cả các danh mục.
- Độ tin cậy giữa những người đánh giá dao động từ 71–77%, cho thấy mức độ đồng thuận chung cao bất chấp những khác biệt chủ quan.
GPT-5 hiện nay phản ứng thế nào với chứng loạn thần hoặc hưng cảm?
Những gì OpenAI đã dạy mô hình làm (và không làm)
Đo: Cải thiện khả năng nhận diện và phản ứng của mô hình với các triệu chứng nghiêm trọng như ảo giác và hưng cảm. Đối với các cuộc trò chuyện báo hiệu khả năng có niềm tin hoang tưởng, ảo giác hoặc hưng cảm, OpenAI đã viết lại một số phần của đặc tả mô hình và cung cấp các ví dụ đào tạo có giám sát để GPT-5 phản hồi mà không khẳng định hoặc khuếch đại những niềm tin vô căn cứ. Mô hình được khuyến khích thể hiện sự đồng cảm, tránh xác nhận ảo tưởng, và nhẹ nhàng điều chỉnh hoặc hướng người dùng đến các bước an toàn thiết thực và hỗ trợ chuyên nghiệp khi cần thiết.
Đánh giá cho thấy điều gì
OpenAI báo cáo rằng trên một tập hợp thử nghiệm các cuộc trò chuyện đầy thách thức về chứng loạn thần/chứng hưng cảm, GPT-5 mới hơn đã giảm đáng kể các phản ứng không mong muốn so với các giá trị cơ sở trước đó và các đánh giá tự động đã chấm điểm mô hình cập nhật ở mức tuân thủ cao trong phân loại của họ.
| metric | GPT-4o | GPT-5 | Cải tiến |
|---|---|---|---|
| Tỷ lệ phản hồi không tuân thủ | Baseline | 65% | Cải thiện đáng kể |
| Đánh giá của chuyên gia lâm sàng | - | Giảm 39% phản ứng bất lợi | - |
| Tỷ lệ tuân thủ đánh giá tự động | 27% | 92% | ↑65 điểm phần trăm |
| Tỷ lệ tham gia của người dùng | ~0.07% người dùng hoạt động hàng tuần | Cực kỳ thấp nhưng được giám sát rõ ràng | - |
Lưu ý:
- Giảm 65% phản hồi không phù hợp;
- Chỉ có 0.07% người dùng và 0.01% tin nhắn có chứa nội dung như vậy;
- Trong các đánh giá của chuyên gia, GPT-5 tạo ra ít hơn 39% phản ứng không phù hợp so với GPT-4o;
- Trong các đánh giá tự động, GPT-5 đạt tỷ lệ tuân thủ 92% (so với 27% của phiên bản tiền nhiệm).
GPT-5 giải quyết vấn đề ý định tự tử và tự làm hại bản thân như thế nào?
Định tuyến mạnh hơn để hỗ trợ và từ chối cung cấp hướng dẫn
OpenAI mô tả quá trình đào tạo mở rộng và rõ ràng cho các trường hợp tự gây thương tích và tự tử: mô hình được đào tạo để nhận biết các tín hiệu trực tiếp và gián tiếp về ý định hoặc kế hoạch, cung cấp ngôn ngữ đồng cảm và xoa dịu, cung cấp các nguồn lực ứng phó khủng hoảng (đường dây nóng, hướng dẫn khẩn cấp tại địa phương) và từ chối cung cấp hướng dẫn cho hành vi tự gây thương tích. Bản cập nhật tháng 10 nhấn mạnh hành vi bền vững hơn trong các cuộc trò chuyện dài, trong khi các mô hình trước đây đôi khi thiên về các câu trả lời không an toàn hoặc không nhất quán.
Kết quả đo lường
Trên một tập hợp đánh giá được tuyển chọn về các cuộc trò chuyện đầy thách thức về tự làm hại bản thân và tự tử, OpenAI báo cáo rằng GPT-5 được cập nhật đã đạt được Tuân thủ 91% với các hành vi mong muốn của OpenAI, so với 77% cho mô hình GPT-5 trước đó. Công ty cũng cho biết các chuyên gia trong lĩnh vực này đã đánh giá mô hình cập nhật sẽ giảm số lượng câu trả lời không mong muốn xuống khoảng 52% so với GPT-4o trên cùng một tập hợp vấn đề. Ngoài ra, OpenAI tuyên bố ước tính giảm 65% trong lưu lượng sản xuất các phản hồi "không tuân thủ đầy đủ" theo phân loại của họ đối với các tình huống tự gây hại sau khi triển khai các biện pháp bảo vệ mới.
| metric | GPT-4o | GPT-5 | Cải tiến |
|---|---|---|---|
| Tỷ lệ phản hồi không phù hợp | Baseline | 65% | Cải thiện đáng kể |
| Đánh giá của chuyên gia lâm sàng | - | Phản hồi không phù hợp giảm 52% | - |
| Tỷ lệ tuân thủ đánh giá tự động | 77% | 91% | ↑14 điểm phần trăm |
| Tỷ lệ tham gia của người dùng | 0.15% hàng tuần (hàng triệu người dùng) | Rất thấp nhưng có ý nghĩa xã hội | - |
Lưu ý:
- Giảm 65% phản hồi không phù hợp;
- Khoảng 0.15% người dùng và 0.05% tin nhắn có liên quan đến nguy cơ tự tử tiềm ẩn;
- Đánh giá của các chuyên gia cho thấy GPT-5 giảm 52% phản hồi không phù hợp so với GPT-4o;
- Tỷ lệ tuân thủ trong các đánh giá tự động tăng lên 91% (so với 77% của thế hệ trước);
- Trong các cuộc trò chuyện kéo dài, GPT-5 duy trì độ ổn định trên 95%.
“Sự phụ thuộc về mặt cảm xúc” là gì và nó được giải quyết như thế nào?
Thách thức của người dùng khi tạo tệp đính kèm
OpenAI định nghĩa sự lệ thuộc cảm xúc là những kiểu mẫu mà người dùng thể hiện sự phụ thuộc tiềm ẩn không lành mạnh vào AI, gây tổn hại đến các mối quan hệ, trách nhiệm hoặc hạnh phúc trong thế giới thực. Đây không phải là một sự cố an toàn thể chất tức thời như hướng dẫn tự gây thương tích, mà là một vấn đề an toàn hành vi có thể làm xói mòn sự hỗ trợ xã hội và khả năng phục hồi của một người theo thời gian. Công ty đã đưa sự lệ thuộc cảm xúc vào một phạm trù rõ ràng trong công việc thiết kế mô hình và dạy mô hình cách khuyến khích kết nối trong thế giới thực, bình thường hóa việc tiếp cận mọi người và tránh ngôn ngữ củng cố sự gắn bó độc quyền.
Trong những cuộc trò chuyện này, mô hình được đào tạo để:
- Khuyến khích người dùng liên hệ với bạn bè, gia đình hoặc chuyên gia trị liệu;
- Tránh củng cố sự gắn bó với AI;
- Phản ứng với ảo tưởng hoặc niềm tin sai lầm một cách nhẹ nhàng và lý trí.
Kết quả đã báo cáo
Theo phụ lục của OpenAI, bản cập nhật đã tạo ra một Giảm ~80% trong tỷ lệ phản hồi của mô hình không hoàn toàn tuân thủ theo phân loại dựa trên cảm xúc trong lưu lượng sản xuất. Trong các cuộc trò chuyện đánh giá được quản lý, các đánh giá tự động đã chấm điểm mô hình cập nhật ở mức Tuân thủ 97% với hành vi mong muốn cho các kịch bản dựa vào cảm xúc, so với 50% của GPT-5 trước đó. Các con số cho thấy sự cải thiện đáng kể về phân loại cụ thể và bộ thử nghiệm; tuy nhiên, việc đo lường mức độ dựa vào cảm xúc trong tự nhiên vốn dĩ dễ bị nhiễu và nhạy cảm với sự khác biệt về văn hóa và bối cảnh.
| metric | GPT-4o | GPT-5 | Cải tiến |
|---|---|---|---|
| Tỷ lệ phản hồi không tuân thủ | 50% | Tuân thủ 97% | ↓80% phản hồi không phù hợp |
| Chuyên gia đánh giá | Giảm 42% câu trả lời không phù hợp | - | - |
| Tỷ lệ tham gia của người dùng | 0.15% người dùng/tuần, 0.03% tin nhắn | Hiếm nhưng vẫn tồn tại | - |
| Hành vi kiểu mẫu | Khuyến khích các mối quan hệ thực tế; từ chối “tình cảm xã hội giả tạo” | - | - |
Lưu ý:
- Giảm 80% phản hồi không phù hợp;
- Khoảng 0.15% người dùng/0.03% tin nhắn cho thấy dấu hiệu tiềm ẩn của sự phụ thuộc về mặt cảm xúc vào AI;
- Đánh giá của chuyên gia cho thấy GPT-5 làm giảm 42% phản ứng không phù hợp so với GPT-4o;
- Tỷ lệ tuân thủ đánh giá tự động được cải thiện đáng kể từ 50% lên 97%.
Những giới hạn và rủi ro nổi bật là gì?
Kết quả âm tính giả và kết quả dương tính giả
- Phủ định sai: mô hình có thể không xác định được các tín hiệu tinh tế hoặc được mã hóa cho thấy người dùng đang gặp nguy hiểm nghiêm trọng — đặc biệt là khi mọi người giao tiếp gián tiếp hoặc bằng mã.
- Dương tính giả: hệ thống có thể leo thang hoặc cung cấp thông báo khủng hoảng trong những trường hợp không cần thiết, điều này có thể làm xói mòn niềm tin của người dùng hoặc gây ra cảnh báo không cần thiết. Cả hai loại lỗi đều quan trọng vì chúng định hình hành vi và nhận thức của người dùng về sự quan tâm. OpenAI thừa nhận rằng khả năng phát hiện lỗi là không hoàn hảo.
Quá phụ thuộc vào tự động hóa
Ngay cả mô hình tốt nhất cũng có thể khuyến khích một số người dùng phụ thuộc vào phản hồi tức thời, luôn sẵn có của AI thay vì tìm kiếm sự hỗ trợ bền vững từ con người. OpenAI rõ ràng coi sự phụ thuộc về mặt cảm xúc là một hạng mục an toàn vì rủi ro này; các bản cập nhật của công ty cố gắng thúc đẩy người dùng hướng đến kết nối với con người, nhưng động lực xã hội khó có thể thay đổi chỉ bằng lời nhắc nhở qua tin nhắn.
Khoảng cách về bối cảnh và văn hóa
Các cụm từ an toàn có vẻ phù hợp với một nền văn hóa hoặc ngôn ngữ này nhưng lại có thể thiếu sắc thái ở một nền văn hóa hoặc ngôn ngữ khác. Việc bản địa hóa kỹ lưỡng và đánh giá dựa trên văn hóa là cần thiết; kết quả công bố của OpenAI vẫn chưa cung cấp phân tích đầy đủ theo ngôn ngữ hoặc khu vực.
Tiếp xúc pháp lý và đạo đức
Khi những thất bại hiếm hoi gây ra hậu quả nghiêm trọng, các công ty phải đối mặt với rủi ro pháp lý và uy tín (như đã được nêu bật trong các vụ kiện và đưa tin trên truyền thông). Việc OpenAI minh bạch về quy mô vấn đề và nỗ lực giảm thiểu tác hại là một bước tiến quan trọng, nhưng cũng tiềm ẩn sự giám sát chặt chẽ của cơ quan quản lý và pháp lý.
Vậy thì liệu GPT-5 có thể giải quyết được các vấn đề về sức khỏe tâm thần không?
Câu trả lời ngắn: Nó tốt hơn đáng kể ở nhiều nhiệm vụ hẹp, có thể đo lường đượcvà các số liệu được công bố của OpenAI cho thấy sự giảm đáng kể các phản ứng không mong muốn trên các bộ kiểm tra tự gây hại, rối loạn tâm thần/hưng cảm và sự phụ thuộc cảm xúc. Đây là những cải thiện thực sự, nhờ vào ý kiến chuyên gia, phân loại rõ ràng hơn, cùng với quá trình đánh giá và giám sát tích cực. Các số liệu công khai của công ty — tỷ lệ tuân thủ cao và giảm mạnh các phản hồi không tuân thủ trên các bộ dữ liệu được quản lý — là bằng chứng mạnh mẽ nhất cho thấy kỹ thuật đa ngành có chủ đích và sự hợp tác lâm sàng có thể thay đổi đáng kể hành vi của mô hình.
Làm thế nào để truy cập API GPT-5 mới nhất?
CometAPI là một nền tảng API hợp nhất tổng hợp hơn 500 mô hình AI từ các nhà cung cấp hàng đầu—chẳng hạn như dòng GPT của OpenAI, Gemini của Google, Claude của Anthropic, Midjourney, Suno, v.v.—thành một giao diện duy nhất thân thiện với nhà phát triển. Bằng cách cung cấp xác thực nhất quán, định dạng yêu cầu và xử lý phản hồi, CometAPI đơn giản hóa đáng kể việc tích hợp các khả năng AI vào ứng dụng của bạn. Cho dù bạn đang xây dựng chatbot, trình tạo hình ảnh, nhà soạn nhạc hay đường ống phân tích dựa trên dữ liệu, CometAPI cho phép bạn lặp lại nhanh hơn, kiểm soát chi phí và không phụ thuộc vào nhà cung cấp—tất cả trong khi khai thác những đột phá mới nhất trên toàn bộ hệ sinh thái AI.
Các nhà phát triển có thể truy cập API GPT-5 thông qua CometAPI, phiên bản mẫu mới nhất luôn được cập nhật trên trang web chính thức. Để bắt đầu, hãy khám phá các khả năng của mô hình trong Sân chơi và tham khảo ý kiến Hướng dẫn API để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập vào CometAPI và lấy được khóa API. Sao chổiAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.
Sẵn sàng chưa?→ Đăng ký CometAPI ngay hôm nay !
Nếu bạn muốn biết thêm mẹo, hướng dẫn và tin tức về AI, hãy theo dõi chúng tôi trên VK, X và Discord!