

GLM-5 là mô hình nền tảng mở trọng số, hướng tác nhân mới của Zhipu AI, được xây dựng cho lập trình tầm nhìn dài hạn và tác nhân đa bước. Mô hình có sẵn qua nhiều API dạng dịch vụ (bao gồm CometAPI và các điểm cuối từ nhà cung cấp) và dưới dạng phát hành nghiên cứu kèm mã nguồn và trọng số; bạn có thể tích hợp bằng các cuộc gọi REST tương thích OpenAI chuẩn, streaming và SDK.
GLM-5 từ Z.ai là gì?
GLM-5 là mô hình nền tảng chủ lực thế hệ thứ năm của Z.ai, được thiết kế cho “kỹ thuật tác nhân”: lập kế hoạch dài hạn, sử dụng công cụ nhiều bước, và thiết kế mã/hệ thống ở quy mô lớn. Phát hành công khai vào tháng 2/2026, GLM-5 là mô hình Mixture-of-Experts (MoE) với tổng ~744 tỷ tham số và ~40B tham số hoạt động cho mỗi lượt suy diễn; kiến trúc và lựa chọn huấn luyện ưu tiên tính mạch lạc ở ngữ cảnh dài, gọi công cụ, và suy luận hiệu quả chi phí cho tải sản xuất. Những lựa chọn này cho phép GLM-5 chạy các quy trình tác nhân kéo dài (ví dụ: duyệt → lập kế hoạch → viết/kiểm thử mã → lặp lại) trong khi vẫn giữ được ngữ cảnh với đầu vào rất dài.
Các điểm kỹ thuật nổi bật:
- Kiến trúc MoE với ~744B tổng tham số / ~40B tham số hoạt động; tiền huấn luyện ở quy mô lớn (~28.5T token được báo cáo) nhằm thu hẹp khoảng cách với các mô hình đóng hàng đầu.
- Hỗ trợ ngữ cảnh dài và tối ưu hóa (deep sparse attention, DSA) giúp giảm chi phí triển khai so với cách mở rộng dày đặc ngây thơ.
- Tính năng tác nhân tích hợp: gọi công cụ/hàm, hỗ trợ phiên trạng thái, và đầu ra tích hợp (có khả năng tạo hiện vật
.docx,.xlsx,.pdfnhư một phần của quy trình tác nhân trong giao diện nhà cung cấp). - Trọng số mở (trọng số được công bố lên các kho mô hình) và tùy chọn truy cập dạng dịch vụ (API của nhà cung cấp, vi dịch vụ suy luận).
Những ưu điểm chính của GLM-5 là gì?
Lập kế hoạch dạng tác nhân và bộ nhớ dài hạn
Kiến trúc và tinh chỉnh của GLM-5 ưu tiên khả năng suy luận đa bước nhất quán và ghi nhớ xuyên suốt quy trình — hữu ích cho:
- tác nhân tự động (pipeline CI, bộ điều phối tác vụ),
- tạo/refactor mã quy mô lớn nhiều tệp, và
- trí tuệ tài liệu cần lưu giữ lịch sử dài.
Cửa sổ ngữ cảnh lớn
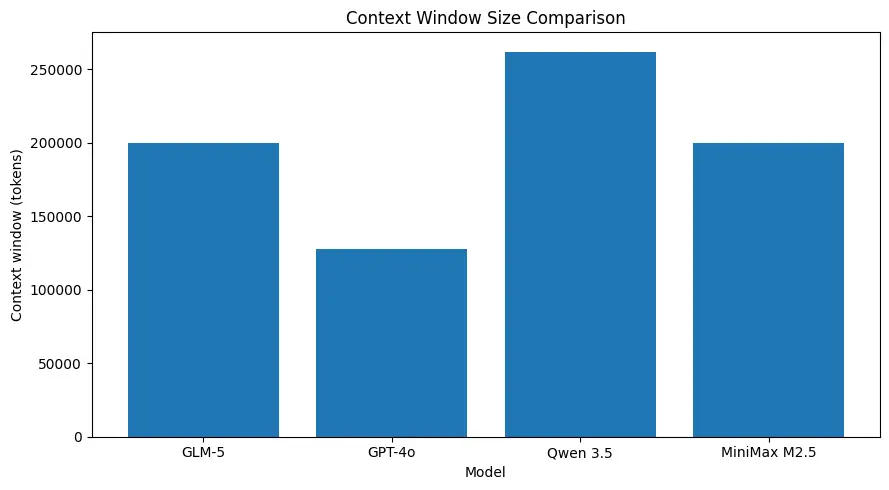
GLM-5 hỗ trợ kích thước ngữ cảnh rất lớn (khoảng ~200k token theo thông số mô hình công bố), cho phép bạn giữ nhiều nội dung phiên trong một yêu cầu và giảm nhu cầu xé nhỏ hoặc dùng bộ nhớ ngoài cho nhiều trường hợp. (Xem biểu đồ so sánh bên dưới.)
Hiệu suất lập trình mạnh cho tác vụ cấp hệ thống
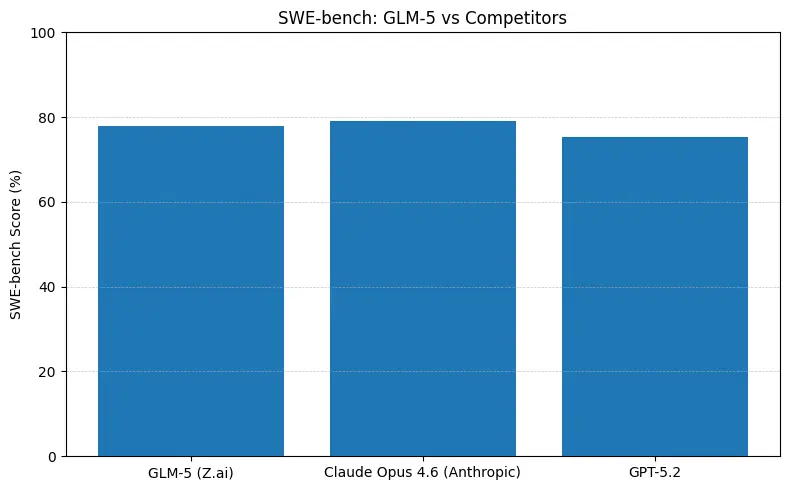
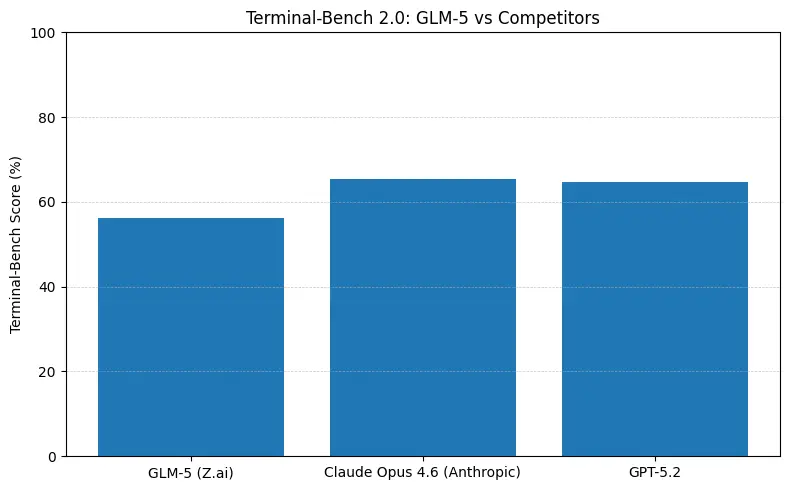
GLM-5 báo cáo hiệu năng mã nguồn mở hàng đầu trên các benchmark kỹ thuật phần mềm (SWE-bench và các bộ bài kiểm tra mã + tác nhân thực tiễn). Trên SWE-bench-Verified đạt ~77,8%; trên các bài kiểm tra tác nhân kiểu mã lệnh/terminal (Terminal-Bench 2.0) điểm ở khoảng giữa 50 — cho thấy khả năng lập trình thực tiễn tiệm cận các mô hình sở hữu hàng đầu. Các chỉ số này nghĩa là GLM-5 phù hợp cho các tác vụ như tạo mã, refactor tự động, suy luận nhiều tệp và trợ lý CI/CD.
Đánh đổi chi phí/hiệu suất
Vì GLM-5 dùng MoE và các đổi mới “chú ý thưa”, mục tiêu là giảm chi phí suy luận cho mỗi đơn vị năng lực so với cách mở rộng dày đặc. CometAPI cung cấp mức giá cạnh tranh khiến GLM-5 hấp dẫn cho tải tác nhân thông lượng lớn.
Tôi dùng API GLM-5 qua CometAPI như thế nào?
Câu ngắn gọn: coi CometAPI như một cổng tương thích OpenAI — thiết lập base URL và API key, chọn glm-5 làm model, rồi gọi endpoint chat/completions. CometAPI cung cấp bề mặt REST kiểu OpenAI (các đường dẫn như /v1/chat/completions) cùng SDK và dự án mẫu giúp việc di chuyển trở nên đơn giản.
Dưới đây là “cookbook” thực tiễn cho sản xuất: xác thực, gọi chat cơ bản, streaming, gọi hàm/công cụ, và xử lý chi phí/response.
Các bước cơ bản để truy cập GLM-5 qua CometAPI:
- Đăng ký trên CometAPI, lấy API key.
- Tìm chính xác model id cho GLM-5 trong danh mục của CometAPI (
"glm-5"tùy theo danh sách). - Gửi yêu cầu POST đã xác thực tới endpoint chat/completions của CometAPI (kiểu OpenAI).
Chi tiết nền tảng (mẫu CometAPI): nền tảng hỗ trợ đường dẫn kiểu OpenAI như https://api.cometapi.com/v1/chat/completions, xác thực Bearer, tham số model, thông điệp system/user, streaming, và ví dụ curl/python trong tài liệu.
Ví dụ: Python (requests) gọi chat completion nhanh với GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Ví dụ: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Phản hồi streaming (mẫu thực tiễn)
CometAPI hỗ trợ streaming kiểu OpenAI (SSE / chunked). Cách đơn giản nhất trong Python là yêu cầu "stream": true và lặp qua dữ liệu phản hồi khi đến. Điều này quan trọng khi bạn cần đầu ra từng phần độ trễ thấp (xây trợ lý dev thời gian thực, UI streaming).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Tham khảo: tài liệu streaming kiểu OpenAI và tương thích CometAPI.
Gọi hàm / công cụ (cách gọi công cụ bên ngoài)
GLM-5 hỗ trợ mẫu gọi hàm hoặc công cụ tương thích với quy ước OpenAI / bộ tổng hợp (gateway truyền lệnh gọi hàm có cấu trúc trong phản hồi của mô hình). Ví dụ: yêu cầu GLM-5 gọi công cụ “run_tests” cục bộ; mô hình trả về hướng dẫn có cấu trúc mà bạn có thể phân tích và thực thi.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Khi mô hình trả về payload function_call, hãy thực thi công cụ ở phía server, sau đó đưa kết quả công cụ trở lại dưới dạng thông điệp với role "tool" và tiếp tục hội thoại. Mẫu này cho phép gọi công cụ an toàn và dòng tác nhân có trạng thái. Xem tài liệu và ví dụ của CometAPI để có helper cụ thể trong SDK.
Tham số & tinh chỉnh thực tiễn
function_call: dùng để bật lệnh gọi công cụ có cấu trúc và luồng thực thi an toàn hơn.
temperature: 0–0.3 cho đầu ra hệ thống có tính quyết định (mã, hạ tầng), cao hơn cho ý tưởng.
max_tokens: đặt theo độ dài đầu ra kỳ vọng; GLM-5 hỗ trợ đầu ra rất dài khi được lưu trữ (giới hạn nhà cung cấp khác nhau).
top_p / nucleus sampling: hữu ích để giới hạn đuôi ít khả năng.
stream: true cho UI tương tác.
So sánh GLM-5 với Claude Opus của Anthropic và các mô hình hàng đầu khác
Câu ngắn gọn: GLM-5 thu hẹp khoảng cách với các mô hình đóng hàng đầu ở benchmark tác nhân và lập trình, đồng thời cung cấp triển khai mở trọng số và thường có chi phí mỗi token tốt hơn khi được lưu trữ bởi các bộ tổng hợp. Sắc thái: trên một số benchmark mã tuyệt đối (SWE-bench, biến thể Terminal-Bench) Claude Opus (4.5/4.6) của Anthropic vẫn dẫn trước vài điểm trong nhiều bảng xếp hạng đã công bố — nhưng GLM-5 rất cạnh tranh và vượt qua nhiều mô hình mở khác.
Ý nghĩa thực tiễn của các con số
- SWE-bench (~độ đúng mã / kỹ thuật): Claude Opus nhỉnh hơn (≈79% so với GLM-5 ≈77,8%) trên bảng xếp hạng công bố; với nhiều tác vụ thực, khoảng cách đó sẽ chuyển thành ít chỉnh sửa thủ công hơn, nhưng không nhất thiết dẫn đến lựa chọn kiến trúc khác cho nguyên mẫu hoặc quy trình tác nhân ở quy mô.
- Terminal-Bench (tác vụ tác nhân dòng lệnh): Opus 4.6 dẫn đầu (≈65,4% so với GLM-5 ≈56,2%) — nếu bạn cần tự động hóa terminal mạnh mẽ và độ tin cậy cao nhất với thao tác shell ngoài phân phối, Opus thường tốt hơn đôi chút.
- Tác nhân và tầm nhìn dài hạn: GLM-5 thể hiện rất tốt trên mô phỏng kinh doanh dài hạn (Vending-Bench 2: số dư $4,432 được báo cáo) và cho thấy tính mạch lạc lập kế hoạch mạnh cho quy trình nhiều bước. Nếu sản phẩm của bạn là tác nhân chạy lâu (tài chính, vận hành), GLM-5 rất mạnh.
Tôi thiết kế prompt và hệ thống thế nào để có đầu ra GLM-5 đáng tin cậy?
Thông điệp hệ thống & ràng buộc rõ ràng
Giao cho GLM-5 vai trò và ràng buộc chặt chẽ, đặc biệt cho tác vụ mã hoặc gọi công cụ. Ví dụ:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Yêu cầu có kiểm thử và lý do ngắn cho mỗi thay đổi không tầm thường.
Phân rã tác vụ phức tạp
Thay vì “viết toàn bộ sản phẩm”, hãy yêu cầu:
- đề cương thiết kế,
- chữ ký giao diện,
- triển khai và kiểm thử,
- script tích hợp cuối cùng.
Phân bước như vậy giảm ảo tưởng và tạo checkpoint quyết định mà bạn có thể xác minh.
Dùng nhiệt độ thấp cho mã có tính quyết định
Khi yêu cầu mã, đặt temperature = 0–0.2 và max_tokens ở ngưỡng an toàn. Với viết sáng tạo hoặc brainstorm thiết kế, tăng nhiệt độ.
Thực tiễn tốt khi tích hợp GLM-5 (qua CometAPI hoặc host trực tiếp)
Kỹ thuật prompt & thông điệp hệ thống
- Dùng hướng dẫn dạng system rõ ràng xác định vai trò tác nhân, chính sách truy cập công cụ và ràng buộc an toàn. Ví dụ: “Bạn là kiến trúc sư hệ thống: chỉ đề xuất thay đổi khi unit test qua tại máy; liệt kê chính xác lệnh CLI cần chạy.”
- Với tác vụ mã, cung cấp ngữ cảnh repository (danh sách tệp, snippet mã chính) và đính kèm đầu ra unit test nếu có. Khả năng xử lý ngữ cảnh dài của GLM-5 hữu ích — nhưng luôn giữ ngữ cảnh thiết yếu lên trước (vai trò, tác vụ) rồi mới đến tài liệu hỗ trợ.
Quản lý phiên & trạng thái
- Dùng session ID cho hội thoại tác nhân dài và giữ “bộ nhớ” đã nén của các bước trước (tóm tắt) để tránh phình ngữ cảnh. CometAPI và gateway tương tự có helper phiên/trạng thái — nhưng nén trạng thái ở tầng ứng dụng là điều cốt yếu cho tác nhân chạy lâu.
Công cụ & gọi hàm (an toàn + tin cậy)
- Phơi bày tập công cụ hẹp, có thể kiểm toán. Không cho phép thực thi shell tùy ý mà không có giám sát. Dùng định nghĩa hàm có cấu trúc và xác thực tham số ở phía server.
- Luôn ghi log các lệnh gọi công cụ và phản hồi mô hình để truy xuất và gỡ lỗi hậu kiểm.
Kiểm soát chi phí & gom batch
- Với tác nhân khối lượng lớn, định tuyến xử lý nền tới biến thể mô hình rẻ hơn khi chấp nhận đánh đổi chất lượng (CometAPI cho phép chuyển mô hình theo tên). Gom batch các yêu cầu tương tự và giảm
max_tokenskhi có thể. Theo dõi tỷ lệ token đầu vào so với đầu ra — token đầu ra thường đắt hơn.
Kỹ thuật độ trễ & thông lượng
- Dùng streaming cho phiên tương tác. Với job tác nhân chạy nền, ưu tiên runtime async, hàng đợi worker và bộ giới hạn tốc độ. Nếu tự host (trọng số mở), tinh chỉnh topo accelerator cho kiến trúc MoE — lựa chọn FPGA / Ascend / silicon chuyên dụng có thể mang lại lợi thế chi phí.
Ghi chú cuối
GLM-5 đại diện cho một bước đi thực tế, mở trọng số hướng tới kỹ thuật tác nhân: cửa sổ ngữ cảnh lớn, khả năng lập kế hoạch, và hiệu suất mã mạnh khiến nó hấp dẫn cho công cụ dev, điều phối tác nhân và tự động hóa cấp hệ thống. Dùng CometAPI để tích hợp nhanh hoặc “vườn” mô hình đám mây cho hosting quản lý; luôn xác thực trên workload của bạn và gắn đo kiểm chặt chẽ cho chi phí và kiểm soát ảo tưởng.
Nhà phát triển có thể truy cập GLM-5 qua CometAPI ngay bây giờ. Để bắt đầu, khám phá khả năng của mô hình trong Playground và tham khảo Hướng dẫn API để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập CometAPI và lấy API key. CometAPI cung cấp mức giá thấp hơn đáng kể so với giá chính thức để hỗ trợ bạn tích hợp.
Sẵn sàng chưa?→ Đăng ký M2.5 ngay hôm nay
Nếu muốn biết thêm mẹo, hướng dẫn và tin tức về AI, hãy theo dõi chúng tôi trên VK, X và Discord!