

Z.ai (trước đây là Zhipu AI) của Trung Quốc một lần nữa gây chú ý với việc ra mắt dòng sản phẩm mã nguồn mở GLM 4.5. Được định vị là một giải pháp thay thế hiệu suất cao, tiết kiệm chi phí cho các mô hình ngôn ngữ lớn hiện có, GLM-4.5 hứa hẹn sẽ định hình lại nền kinh tế token và dân chủ hóa quyền truy cập cho các công ty khởi nghiệp, doanh nghiệp và viện nghiên cứu. Bài viết toàn diện này khám phá nguồn gốc, cấu trúc giá và giá trị thực tế của dòng sản phẩm GLM-4.5 - giải quyết hai câu hỏi quan trọng mà mọi bên liên quan đều quan tâm: chi phí là bao nhiêu và liệu nó có xứng đáng không?
Dòng GLM 4.5 là gì?
Dòng sản phẩm GLM 4.5 của Z.ai được xây dựng trên nền tảng AI "agent", nghĩa là mô hình có thể tự động phân tách các tác vụ phức tạp thành các tác vụ con tuần tự nhỏ hơn—nâng cao độ chính xác và giảm thiểu tính toán dư thừa. Điều này trái ngược với các LLM nguyên khối hơn, xử lý lời nhắc chỉ trong một lần chạy. Theo Z.ai, GLM 4.5 tích hợp sẵn khả năng lập luận và lập kế hoạch hành động vào kiến trúc cốt lõi, cho phép thực hiện các quy trình làm việc nhiều bước như tạo trực quan hóa dữ liệu hoặc xử lý tài liệu đầu cuối mà không cần sự điều phối bên ngoài.
Dòng GLM 4.5, do Z.ai phát triển, đại diện cho thế hệ mới nhất của các mô hình ngôn ngữ lớn mã nguồn mở, Hỗn hợp Chuyên gia (MoE), được thiết kế để hợp nhất khả năng lập luận nâng cao, tạo mã và tác nhân trong một kiến trúc duy nhất. Nó có hai phiên bản chính: phiên bản chủ lực GLM 4.5 (tổng cộng 355 B tham số, 32 B hoạt động) và nhẹ hơn GLM 4.5‑Không khí (Tổng cộng 106 B, 12 B đang hoạt động). Cả hai biến thể đều tận dụng cơ chế suy luận kết hợp—“chế độ suy nghĩ” cho lập luận phức tạp, được hỗ trợ bởi công cụ và “chế độ không suy nghĩ” cho việc hoàn thành nhanh chóng, trực tiếp—đáp ứng nhiều trường hợp sử dụng, từ phát triển toàn bộ ngăn xếp đến quy trình làm việc của tác nhân tự động.
thông số kỹ thuật cốt lõi:
- Thông số Kỹ thuật :GLM 4.5 có 355 tỷ tham số, với tập hợp con hoạt động gồm 32 tỷ tham số được sử dụng cho mỗi suy luận để tối ưu hóa việc sử dụng phần cứng và thông lượng.
- Hỗn hợp chuyên gia (MoE): Dòng sản phẩm này tận dụng kiến trúc MoE, định tuyến mã thông báo đến các mạng con chuyên gia một cách linh hoạt để đạt hiệu quả.
- Cửa sổ ngữ cảnh: Mở rộng lên 128 nghìn mã thông báo trên các nền tảng được chọn (ví dụ: SiliconFlow), hỗ trợ các tài liệu và cơ sở mã lớn.
- Tốc độ thế hệ: Các biến thể tốc độ cao vượt quá 100 mã thông báo/giây, phù hợp cho các ứng dụng thời gian thực.
- Chế độ suy luận lai: Người dùng có thể chuyển đổi giữa chế độ "suy nghĩ" (kích hoạt MoE đầy đủ để suy luận sâu sắc) và chế độ "không suy nghĩ" (kích hoạt tối thiểu để phản hồi nhanh chóng, tức thời), giúp các nhà phát triển kiểm soát chặt chẽ hiệu suất so với tốc độ.
Có những biến thể nào trong Series này?
- GLM 4.5 (Tiêu chuẩn): Tổng cộng 355 B / 32 B tham số hoạt động. Được thiết kế chủ yếu để đạt hiệu suất cân bằng giữa các tác vụ lập luận, mã hóa và tác nhân.
- GLM 4.5‑Không khí: Phiên bản tham số hoạt động nhẹ 106 B tổng cộng / 12 B, được thiết kế riêng cho các tình huống có hạn chế nghiêm ngặt về phần cứng hoặc độ trễ—mang lại độ chính xác cạnh tranh trong cùng phân khúc.
Giá của GLM 4.5 Series là bao nhiêu?
Giá token đầu vào và đầu ra là bao nhiêu?
Theo thông báo giá API công khai của Z.ai, GLM 4.5 có giá như sau:
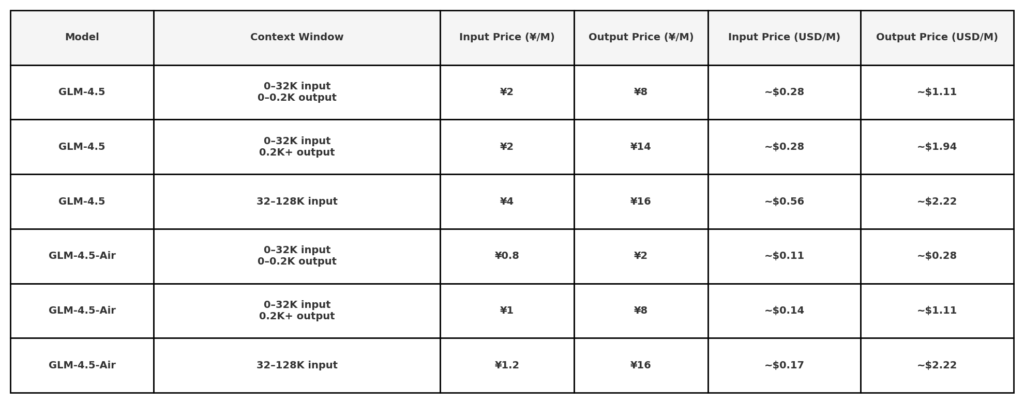
Lưu ý: mức giá rất thấp (0.11 đô la/0.28 đô la) có thể chỉ áp dụng cho các mã thông báo có độ dài nhỏ hoặc các chương trình khuyến mãi cụ thể. Giảm giá 50% cho tất cả các mẫu trong thời gian có hạn, có hiệu lực đến ngày 31 tháng 2025 năm XNUMX. Các mẫu khác tham khảo trang giá văn phòng.
Trên CometAPI, Series được đóng gói với mức giá theo từng tầng hơi khác nhau, hãy tham khảo API GLM‑4.5:
| Mẫu | giới thiệu | Giá |
glm-4.5 | Mô hình lý luận mạnh mẽ nhất của chúng tôi, với 355 tỷ tham số | Mã thông báo đầu vào $0.48 Mã thông báo đầu ra $1.92 |
glm-4.5-air | Hiệu suất mạnh mẽ, nhẹ và tiết kiệm chi phí | Mã thông báo đầu vào $0.16 Mã thông báo đầu ra $1.07 |
glm-4.5-x | Hiệu suất cao, lý luận mạnh mẽ, phản ứng cực nhanh | Mã thông báo đầu vào $1.60 Mã thông báo đầu ra $6.40 |
glm-4.5-airx | Nhẹ, Hiệu suất mạnh mẽ, Phản hồi cực nhanh | Mã thông báo đầu vào $0.02 Mã thông báo đầu ra $0.06 |
glm-4.5-flash | Hiệu suất mạnh mẽ, tuyệt vời cho việc lập trình suy luận và tác nhân | Mã thông báo đầu vào $3.20 Mã thông báo đầu ra $12.80 |
Giá của GLM 4.5 so với DeepSeek và Western LLM như thế nào?
Tại Hội nghị AI thế giới năm 2025, Z.ai đã định vị rõ ràng GLM 4.5 là đối thủ của DeepSeek—công ty dẫn đầu về chi phí trước đây tại Trung Quốc—hứa hẹn “chỉ bằng một phần nhỏ chi phí mã thông báo” và chiếm dụng phần cứng bằng một nửa so với mô hình R1 của DeepSeek.
- DeepSeek R1: Đầu vào khoảng 0.14 USD, đầu ra khoảng 0.60 USD cho mỗi triệu mã thông báo.
- GLM 4.5: Được cho là có thể giảm giá DeepSeek từ 20–30% ở cả đầu vào và đầu ra.
- Tiêu chuẩn phương Tây: GPT‑4 của OpenAI và Gemini của Google có giá dao động từ 3–15 USD cho một triệu token, định vị GLM 4.5 là mức giảm chi phí đáng kể.
Chiến lược định giá này phản ánh mô hình kinh tế AI rộng hơn của Trung Quốc: tính toán tinh gọn hơn, mô hình nhỏ hơn và giảm giá mạnh để chiếm lĩnh thị phần.
Dòng GLM 4.5 có đáng mua không?
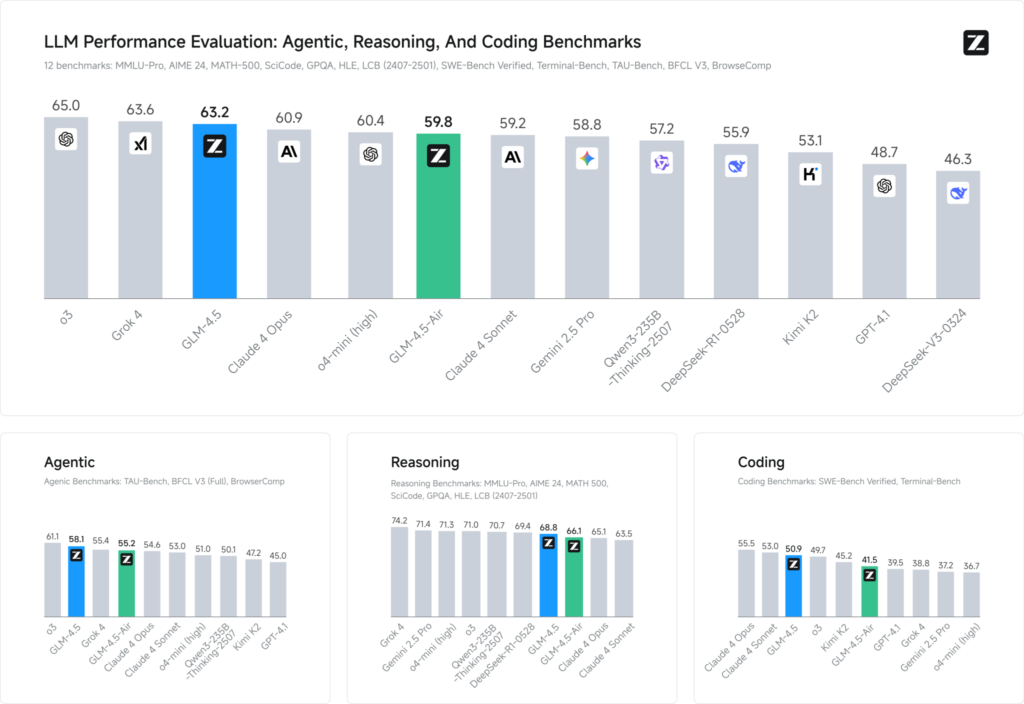
Đánh giá chuẩn trên 12 tập dữ liệu tiêu biểu (bao gồm MMLU Pro, MATH 500, SciCode, Terminal‑Bench và TAU‑Bench) cho thấy GLM 4.5 đạt thứ hạng #3 toàn cầu sau Grok 4 của xAI và o3 của OpenAI—nhưng vẫn xếp hạng #1 trong số các dịch vụ nguồn mở.
Trong các tác vụ mã hóa (LiveCodeBench, SWE‑Bench), thiết kế Mixture-of-Experts của GLM 4.5 góp phần nâng cao chất lượng tạo mã hàng đầu, trong khi về mặt lập luận (AIME 24, MMLU Pro), khả năng lập kế hoạch nhiều bước của nó mang lại độ chính xác mạnh mẽ tương đương với các đối tác mã nguồn đóng. Phiên bản Air nhẹ vẫn duy trì điểm số cạnh tranh trong phạm vi tham số của nó (thang điểm 100 B), khiến nó trở thành một lựa chọn hấp dẫn cho các triển khai biên và hệ thống nhúng.
Điểm chuẩn hiệu suất
- Chỉ số thông minh: Điểm GLM 4.5 66 trên Chỉ số thông minh tổng hợp (MMLU Pro, MATH 500, AIME 24), vượt trội hơn nhiều mô hình thương mại và nguồn mở tầm trung.
- Độ trễ suy luận: Thời gian trung bình đến mã thông báo đầu tiên 0.89 giây, có khả năng cạnh tranh cho các nhiệm vụ suy luận phức tạp, mặc dù thông lượng chậm hơn một chút (≈45.7 mã thông báo/giây) so với một số mô hình nguồn đóng được tối ưu hóa.
- Quy trình làm việc của Agentic: Thể hiện khả năng chỉ huy mạnh mẽ trong việc sử dụng công cụ nhiều bước và tạo mã động, với tỷ lệ chiến thắng trực tiếp là ~54% so với Kimi K2 và 81% so với Qwen3‑Coder trong các đánh giá mã hóa độc lập.
Những trường hợp sử dụng thực tế nào thể hiện ROI?
- Phát triển Full-Stack: GLM‑4.5 có thể xây dựng toàn bộ ứng dụng web—từ bố cục giao diện người dùng trong HTML/CSS/JavaScript đến lược đồ cơ sở dữ liệu phụ trợ—thông qua các lời nhắc nhiều lần, rút ngắn chu kỳ tạo mẫu từ nhiều ngày xuống còn vài giờ.
- Phân tích tài liệu phức tạp: Cửa sổ ngữ cảnh mở rộng 128 K cho phép các công ty luật, tài chính và khoa học phân tích các hợp đồng nhiều trang hoặc báo cáo nghiên cứu chỉ trong một lần, giúp giảm chi phí phân đoạn.
- Quy trình làm việc của tác nhân tự động:Suy luận lai cho phép tạo ra các tập lệnh tự động (ví dụ: bot thu thập dữ liệu web, tác nhân giao dịch) có khả năng suy luận thông qua các quy trình nhiều bước với sự can thiệp tối thiểu của con người.
Các nghiên cứu trường hợp định lượng cho thấy lên đến 60 phần trăm giảm giờ làm việc của nhà phát triển cho các nhiệm vụ tập trung vào mã và 40 phần trăm xử lý nhanh hơn đối với phân tích nội dung dài.
Những nhược điểm tiềm ẩn và những cân nhắc là gì?
Không có công nghệ nào là không có sự đánh đổi. Những người có ý định áp dụng nên lưu ý đến các yếu tố về quy định, vận hành và hệ sinh thái.
Hạn chế
Hỗ trợ & SLA: Các nhà cung cấp nguồn mở có thể không cung cấp SLA cấp doanh nghiệp hoặc hỗ trợ 24/7, không giống như các đối tác thương mại.
Hạn chế thông lượng: Mặc dù cửa sổ ngữ cảnh rất lớn, nhưng tốc độ mã thông báo trên giây lại chậm hơn một số đối tác mã nguồn đóng được tối ưu hóa suy luận, có khả năng ảnh hưởng đến các ứng dụng thời gian thực.
Chi phí hoạt động: Các mô hình MoE tự lưu trữ đòi hỏi phải phối hợp cẩn thận (định tuyến chuyên gia, quản lý bộ nhớ) để tránh tình trạng tắc nghẽn hiệu suất và vượt chi phí.
Cần đầu tư cơ sở hạ tầng như thế nào?
- Tính toán dấu chân: Ngay cả với hiệu quả của MoE, việc lưu trữ biến thể chuẩn của GLM‑4.5 vẫn yêu cầu GPU có bộ nhớ ≥80 GB và kết nối NVLink mạnh mẽ để suy luận có độ trễ thấp.
- Chi phí tinh chỉnh: Việc tùy chỉnh mô hình cho các tác vụ cụ thể của miền có thể yêu cầu các chu kỳ GPU đáng kể, làm tăng chi phí trả trước trước khi tiết kiệm được chi phí thanh toán bằng mã thông báo.
- Bảo trì: Việc triển khai tại chỗ chuyển giao trách nhiệm cập nhật, bản vá bảo mật và mở rộng quy mô từ nhà cung cấp sang các nhóm DevOps nội bộ.
Bạn có thể bắt đầu với GLM‑4.5 như thế nào?
Bắt đầu tích hợp GLM-4.5 bao gồm một vài bước đơn giản—đặc biệt là khi xét đến sổ tay hướng dẫn mã nguồn mở và sự hỗ trợ rộng rãi của bên thứ ba.
API và nền tảng nào hỗ trợ GLM‑4.5?
- Sao chổiAPI API: Điểm cuối hoàn toàn tương thích với OpenAI, có SDK bằng Python, JavaScript và Java.
- Điểm cuối Z.ai trực tiếp: Cung cấp hỗ trợ chính thức và các tính năng truy cập sớm như phối hợp nhiều tác nhân.
- Gương cộng đồng: Máy chủ thời gian chạy nguồn mở đang phát triển nhanh chóng (ví dụ: Ollama, AutoGPT‑CLI) cho phép suy luận cục bộ.
Các nhà phát triển có thể tìm thấy công cụ và tài liệu ở đâu?
- Tài liệu chính thức của Z.ai: Hướng dẫn toàn diện về cài đặt, kỹ thuật nhanh chóng và tối ưu hóa MoE.
- Kho lưu trữ GitHub: Sổ tay mẫu để tạo mã, tạo mã tăng cường truy xuất (RAG) và khung tác nhân tương thích với các công cụ phối hợp chính.
- Diễn đàn cộng đồng: Diễn đàn thảo luận sôi nổi trên các nền tảng như Hugging Face, nơi các học viên chia sẻ công thức tinh chỉnh, thư viện nhắc nhở và chuẩn mực hiệu suất.
Kết luận
Dòng sản phẩm GLM-4.5 khẳng định vị thế vững chắc trong bối cảnh AI cạnh tranh khốc liệt hiện nay: hiệu suất chi phí vượt trội cho cả nhà phát triển, doanh nghiệp và viện nghiên cứu. Với mức giá token chỉ từ 0.11 đô la Mỹ cho mỗi triệu token đầu vào và 0.28 đô la Mỹ cho mỗi triệu token đầu ra—được giảm thêm 50% nhờ chương trình khuyến mãi—và hiệu suất chuẩn mực ngang bằng hoặc vượt trội hơn các mô hình độc quyền lớn hơn, GLM-4.5 mang lại ROI đáng kể cho các ứng dụng tập trung vào mã nguồn, khả năng hiểu dạng dài và quy trình làm việc của agent.
Bắt đầu
CometAPI là một nền tảng API hợp nhất tổng hợp hơn 500 mô hình AI từ các nhà cung cấp hàng đầu—chẳng hạn như dòng GPT của OpenAI, Gemini của Google, Claude của Anthropic, Midjourney, Suno, v.v.—thành một giao diện duy nhất thân thiện với nhà phát triển. Bằng cách cung cấp xác thực nhất quán, định dạng yêu cầu và xử lý phản hồi, CometAPI đơn giản hóa đáng kể việc tích hợp các khả năng AI vào ứng dụng của bạn. Cho dù bạn đang xây dựng chatbot, trình tạo hình ảnh, nhà soạn nhạc hay đường ống phân tích dựa trên dữ liệu, CometAPI cho phép bạn lặp lại nhanh hơn, kiểm soát chi phí và không phụ thuộc vào nhà cung cấp—tất cả trong khi khai thác những đột phá mới nhất trên toàn bộ hệ sinh thái AI.
Các nhà phát triển có thể truy cập API không khí GLM-4.5 và API GLM‑4.5 thông qua Sao chổiAPI, phiên bản mới nhất của các mô hình Claude được liệt kê là tính đến ngày xuất bản bài viết. Để bắt đầu, hãy khám phá các khả năng của mô hình trong Sân chơi và tham khảo ý kiến Hướng dẫn API để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập vào CometAPI và lấy được khóa API. Sao chổiAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.