Gemini 2.5 Flash được thiết kế để cung cấp phản hồi nhanh mà không làm giảm chất lượng đầu ra. Nó hỗ trợ đầu vào đa phương thức, bao gồm văn bản, hình ảnh, âm thanh và video, phù hợp với nhiều ứng dụng đa dạng. Mô hình có thể truy cập qua các nền tảng như Google AI Studio và Vertex AI, cung cấp cho nhà phát triển các công cụ cần thiết để tích hợp liền mạch vào nhiều hệ thống.
Thông tin cơ bản (Tính năng)
Gemini 2.5 Flash giới thiệu một số tính năng nổi bật giúp nó khác biệt trong dòng Gemini 2.5:
- Lập luận lai: Nhà phát triển có thể đặt tham số thinking_budget để kiểm soát chi tiết số lượng token mà mô hình dành cho lập luận nội bộ trước khi xuất đầu ra.
- Biên Pareto: Ở điểm tối ưu giữa chi phí và hiệu năng, Flash mang lại tỷ lệ giá thành trên mức độ thông minh tốt nhất trong các mô hình 2.5.
- Hỗ trợ đa phương thức: Xử lý nguyên bản văn bản, hình ảnh, video và âm thanh, cho phép khả năng đối thoại và phân tích phong phú hơn.
- Ngữ cảnh 1 triệu token: Độ dài ngữ cảnh vượt trội cho phép phân tích sâu và hiểu tài liệu dài chỉ trong một yêu cầu.
Phiên bản mô hình
Gemini 2.5 Flash đã trải qua các phiên bản chính sau:
- gemini-2.5-flash-lite-preview-09-2025: Tăng khả dụng của công cụ: Cải thiện hiệu năng trên các tác vụ phức tạp, nhiều bước, với mức tăng 5% điểm SWE-Bench Verified (từ 48.9% lên 54%). Nâng cao hiệu suất: Khi bật lập luận, đầu ra chất lượng cao hơn đạt được với ít token hơn, giảm độ trễ và chi phí.
- Preview 04-17: Bản phát hành truy cập sớm với khả năng “thinking”, có sẵn qua gemini-2.5-flash-preview-04-17.
- Stable General Availability (GA): Kể từ 17 tháng 6, 2025, endpoint ổn định gemini-2.5-flash thay thế bản preview, đảm bảo độ tin cậy cấp sản xuất mà không có thay đổi API so với bản preview ngày 20 tháng 5.
- Ngừng hỗ trợ Preview: Các endpoint preview được lên lịch tắt vào ngày 15 tháng 7, 2025; người dùng phải chuyển sang endpoint GA trước ngày này.
Tính đến tháng 7 năm 2025, Gemini 2.5 Flash hiện đã công khai và ổn định (không có thay đổi so với gemini-2.5-flash-preview-05-20). Nếu bạn đang sử dụng gemini-2.5-flash-preview-04-17, mức giá preview hiện tại sẽ tiếp tục cho đến khi endpoint của mô hình dự kiến ngừng hoạt động vào ngày 15 tháng 7, 2025. Bạn có thể di chuyển sang mô hình phát hành chung "gemini-2.5-flash".
Nhanh hơn, rẻ hơn, thông minh hơn:
- Mục tiêu thiết kế: độ trễ thấp + thông lượng cao + chi phí thấp;
- Tăng tốc tổng thể trong lập luận, xử lý đa phương thức và các tác vụ văn bản dài;
- Mức sử dụng token giảm 20–30%, cắt giảm đáng kể chi phí lập luận.
Thông số kỹ thuật
Cửa sổ ngữ cảnh đầu vào: Tối đa 1 triệu token, cho phép giữ ngữ cảnh rộng.
Token đầu ra: Có thể tạo tối đa 8,192 token cho mỗi phản hồi.
Các phương thức được hỗ trợ: Văn bản, hình ảnh, âm thanh và video.
Nền tảng tích hợp: Có sẵn qua Google AI Studio và Vertex AI.
Giá: Mô hình định giá theo token mang tính cạnh tranh, giúp triển khai tiết kiệm chi phí.
Chi tiết kỹ thuật
Ở bên trong, Gemini 2.5 Flash là một mô hình ngôn ngữ lớn dựa trên transformer được huấn luyện trên hỗn hợp dữ liệu web, mã, hình ảnh và video. Các thông số kỹ thuật chính bao gồm:
Huấn luyện đa phương thức: Được huấn luyện để căn chỉnh nhiều phương thức, Flash có thể kết hợp mượt mà văn bản với hình ảnh, video hoặc âm thanh, hữu ích cho các tác vụ như tóm tắt video hoặc tạo chú thích âm thanh.
Quy trình suy nghĩ động: Triển khai một vòng lặp lập luận nội bộ, trong đó mô hình lập kế hoạch và phân rã các lời nhắc phức tạp trước khi xuất đầu ra cuối cùng.
Ngân sách suy nghĩ có thể cấu hình: thinking_budget có thể được đặt từ 0 (không lập luận) đến 24,576 token, cho phép cân bằng giữa độ trễ và chất lượng câu trả lời.
Tích hợp công cụ: Hỗ trợ Grounding với Google Search, Thực thi mã, Ngữ cảnh URL và Gọi hàm, cho phép thực hiện hành động trong thế giới thực trực tiếp từ lời nhắc ngôn ngữ tự nhiên.
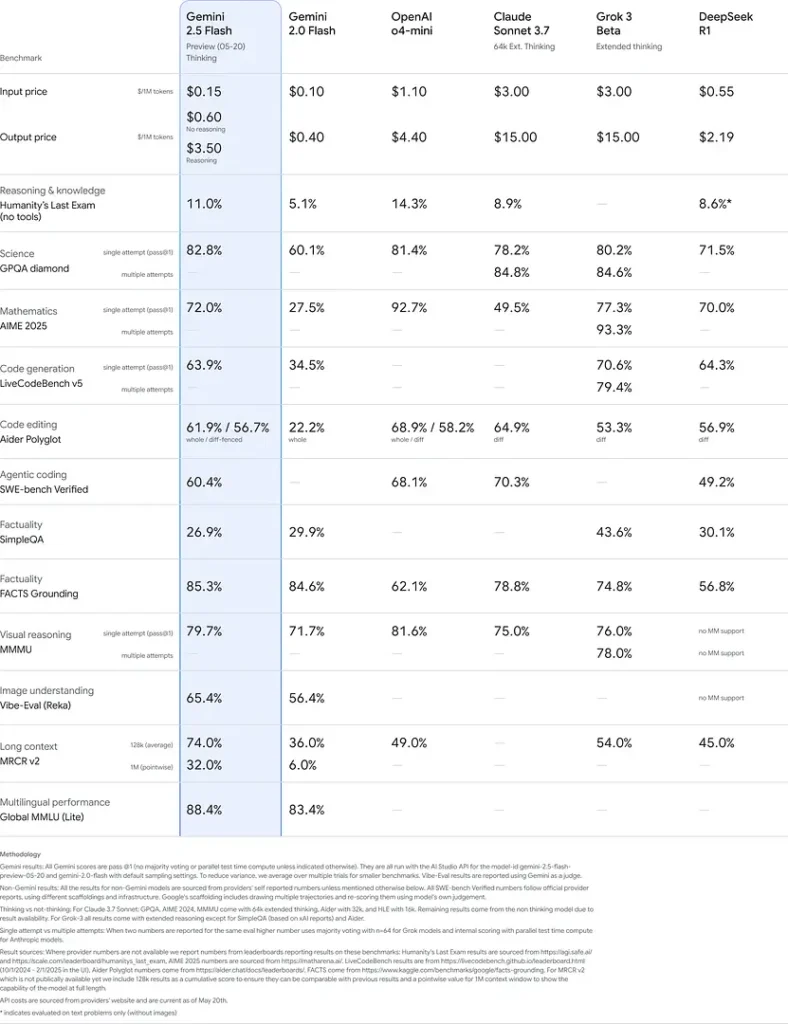
Hiệu năng trên benchmark
Trong các đánh giá nghiêm ngặt, Gemini 2.5 Flash thể hiện hiệu năng dẫn đầu ngành:
- LMArena Hard Prompts: Đạt vị trí thứ hai chỉ sau 2.5 Pro trên benchmark Hard Prompts đầy thách thức, cho thấy khả năng lập luận nhiều bước mạnh mẽ.
- Điểm MMLU 0.809: Vượt hiệu năng trung bình của các mô hình với độ chính xác MMLU 0.809, phản ánh kiến thức đa lĩnh vực và năng lực lập luận mạnh mẽ.
- Độ trễ và thông lượng: Đạt tốc độ giải mã 271.4 tokens/sec với 0.29 s Time-to-First-Token, lý tưởng cho các khối lượng công việc nhạy cảm với độ trễ.
- Dẫn đầu về tỷ lệ giá/hiệu năng: Ở mức $0.26/1 M tokens, Flash rẻ hơn nhiều đối thủ trong khi vẫn ngang bằng hoặc vượt trội trên các benchmark chính.
Những kết quả này cho thấy lợi thế cạnh tranh của Gemini 2.5 Flash trong lập luận, hiểu biết khoa học, giải quyết bài toán, lập trình, diễn giải hình ảnh và khả năng đa ngôn ngữ:
Hạn chế
Mặc dù mạnh mẽ, Gemini 2.5 Flash vẫn có một số hạn chế:
- Rủi ro an toàn: Mô hình có thể thể hiện giọng điệu “lên lớp” và đôi khi tạo ra đầu ra nghe có vẻ hợp lý nhưng sai hoặc thiên lệch (ảo giác), đặc biệt với các truy vấn biên. Sự giám sát chặt chẽ của con người vẫn là điều cần thiết.
- Giới hạn tốc độ: Việc sử dụng API bị ràng buộc bởi giới hạn tốc độ (10 RPM, 250,000 TPM, 250 RPD ở tầng mặc định), có thể ảnh hưởng đến xử lý theo lô hoặc các ứng dụng lưu lượng lớn.
- Ngưỡng trí tuệ: Dù rất mạnh đối với một mô hình flash, nó vẫn kém chính xác hơn 2.5 Pro ở các tác vụ tác tử đòi hỏi cao như lập trình nâng cao hoặc phối hợp đa tác tử.
- Đánh đổi chi phí: Mặc dù cung cấp tỷ lệ giá/hiệu năng tốt nhất, việc sử dụng rộng rãi chế độ thinking làm tăng tổng mức tiêu thụ token, đẩy chi phí lên đối với các lời nhắc cần lập luận sâu.