Chi tiết kỹ thuật
- Suy luận thích ứng:
Gemini 2.5 Flash-Litehỗ trợ chế độ suy nghĩ theo yêu cầu, cho phép nhà phát triển chỉ phân bổ tài nguyên tính toán khi cần suy luận sâu hơn. - Tích hợp công cụ: Tương thích hoàn toàn với các công cụ gốc của Gemini 2.5, bao gồm Grounding with Google Search, Code Execution, URL Context và Function Calling để tạo quy trình làm việc đa phương thức liền mạch.
- Model Context Protocol (MCP): Tận dụng MCP của Google để lấy dữ liệu web theo thời gian thực, đảm bảo phản hồi luôn cập nhật và phù hợp với ngữ cảnh.
- Tùy chọn triển khai: Có sẵn thông qua CometAPI, Gemini API, Vertex AI và Google AI Studio, kèm kênh bản xem trước dành cho nhóm dùng sớm để thử nghiệm và cung cấp phản hồi.
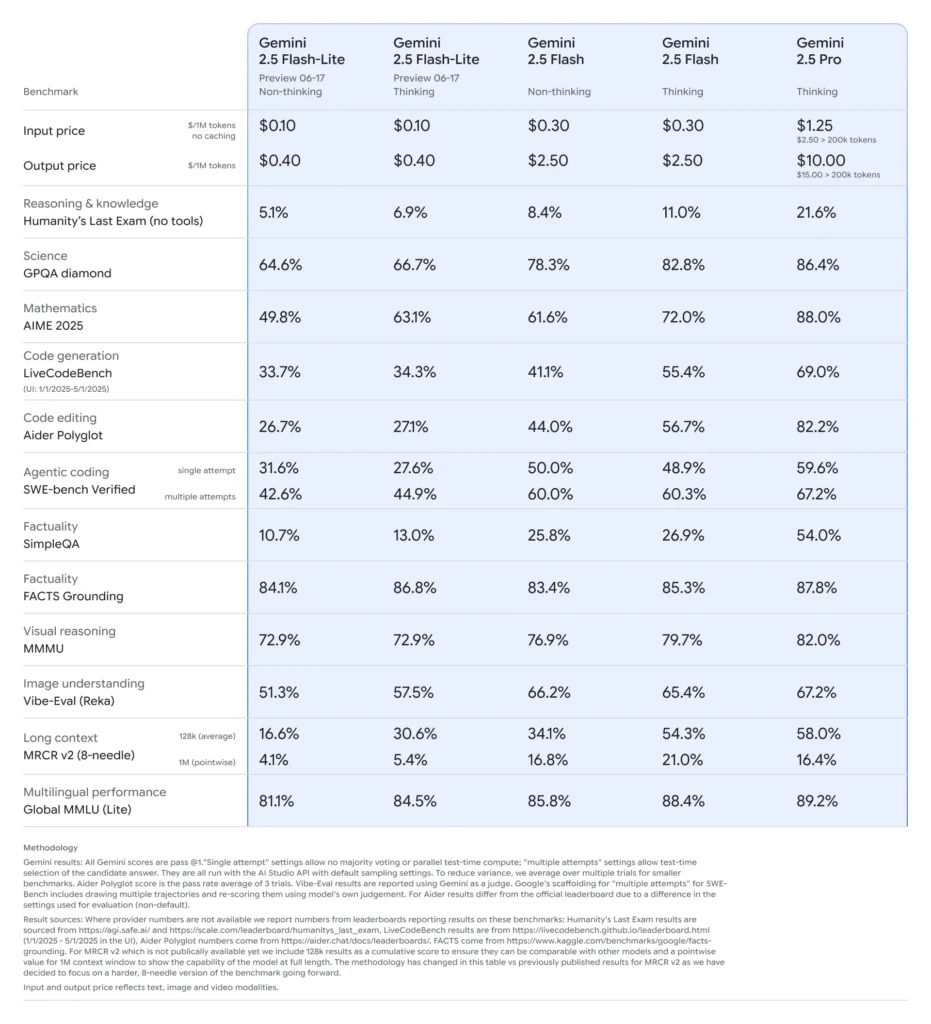
Hiệu năng đo chuẩn của Gemini 2.5 Flash-Lite
- Độ trễ: Đạt thời gian phản hồi trung vị thấp hơn đến 50% so với Gemini 2.5 Flash, với độ trễ điển hình dưới 100 ms trên các bài đo chuẩn phân loại và tóm tắt tiêu chuẩn.
- Thông lượng: Tối ưu cho khối lượng công việc cao, duy trì hàng chục nghìn yêu cầu mỗi phút mà không suy giảm hiệu năng.
- Giá thành-hiệu năng: Cho thấy mức giảm 25% chi phí trên mỗi 1.000 token so với bản Flash tương ứng, trở thành lựa chọn tối ưu theo Pareto cho các triển khai nhạy về chi phí.
- Mức độ áp dụng trong ngành: Người dùng sớm báo cáo tích hợp trơn tru vào các pipeline sản xuất, với các chỉ số hiệu năng phù hợp hoặc vượt dự báo ban đầu.
Trường hợp sử dụng lý tưởng
- Nhiệm vụ tần suất cao, độ phức tạp thấp: Gắn thẻ tự động, phân tích cảm xúc và dịch hàng loạt
- Pipeline nhạy về chi phí: Trích xuất dữ liệu từ tập tài liệu lớn, tóm tắt theo lô định kỳ
- Kịch bản edge và di động: Khi độ trễ là yếu tố then chốt nhưng ngân sách tài nguyên hạn chế
Hạn chế của Gemini 2.5 Flash-Lite
- Trạng thái bản xem trước: Có thể thay đổi API trước khi GA; các tích hợp nên dự trù khả năng tăng phiên bản.
- Không tinh chỉnh trực tiếp: Không thể tải lên trọng số tùy chỉnh; dựa vào thiết kế prompt và thông điệp hệ thống.
- Giảm tính sáng tạo: Được tinh chỉnh cho các tác vụ mang tính xác định, thông lượng cao; ít phù hợp với tạo nội dung mở hoặc viết “sáng tạo”.
- Giới hạn tài nguyên: Chỉ tuyến tính đến ~16 vCPUs; vượt mức này, mức tăng thông lượng giảm dần.
- Hạn chế đa phương thức: Hỗ trợ đầu vào hình ảnh/âm thanh nhưng độ trung thực hạn chế; không lý tưởng cho các tác vụ thị giác chuyên sâu hoặc chuyển âm thanh thành văn bản.
- Đánh đổi về cửa sổ ngữ cảnh: Mặc dù chấp nhận tới 1 M tokens, suy luận thực tế ở quy mô đó có thể giảm thông lượng.