

Trong bối cảnh trí tuệ nhân tạo đang phát triển nhanh chóng, năm 2025 đã chứng kiến những tiến bộ đáng kể trong các mô hình ngôn ngữ lớn (LLM). Trong số những người đi đầu là Qwen2.5 của Alibaba, các mô hình V3 và R1 của DeepSeek và ChatGPT của OpenAI. Mỗi mô hình này đều mang đến những khả năng và cải tiến độc đáo. Bài viết này đi sâu vào những phát triển mới nhất xung quanh Qwen2.5, so sánh các tính năng và hiệu suất của nó với DeepSeek và ChatGPT để xác định mô hình nào hiện đang dẫn đầu cuộc đua AI.
Qwen2.5 là gì?
Giới thiệu chung
Qwen 2.5 là mô hình ngôn ngữ lớn chỉ dành cho bộ giải mã mới nhất của Alibaba Cloud, có nhiều kích cỡ khác nhau, từ 0.5B đến 72B tham số. Nó được tối ưu hóa cho các đầu ra có cấu trúc, tuân theo hướng dẫn (ví dụ: JSON, bảng), mã hóa và giải quyết vấn đề toán học. Với hỗ trợ cho hơn 29 ngôn ngữ và độ dài ngữ cảnh lên tới 128K mã thông báo, Qwen2.5 được thiết kế cho các ứng dụng đa ngôn ngữ và dành riêng cho từng miền.
Các tính năng chính
- Hỗ trợ đa ngôn ngữ: Hỗ trợ hơn 29 ngôn ngữ, phục vụ cho lượng người dùng toàn cầu.
- Độ dài ngữ cảnh mở rộng: Xử lý tới 128K token, cho phép xử lý các tài liệu và cuộc hội thoại dài.
- Các biến thể chuyên biệt: Bao gồm các mô hình như Qwen2.5-Coder để lập trình các tác vụ và Qwen2.5-Math để giải quyết các vấn đề toán học.
- Khả Năng Tiếp Cận: Có sẵn thông qua các nền tảng như Hugging Face, GitHub và giao diện web mới ra mắt tại chat.qwenlm.ai.
Làm thế nào để sử dụng Qwen 2.5 cục bộ?
Dưới đây là hướng dẫn từng bước cho 7 B Trò chuyện điểm kiểm tra; kích thước lớn hơn chỉ khác nhau về yêu cầu của GPU.
1. Điều kiện tiên quyết về phần cứng
| Mẫu | vRAM cho 8 bit | vRAM cho 4 bit (QLoRA) | Kích thước đĩa |
|---|---|---|---|
| Qwen 2.5‑7B | 14GB | 10GB | 13GB |
| Qwen 2.5‑14B | 26GB | 18GB | 25GB |
Một RTX 4090 (24 GB) duy nhất đủ cho suy luận 7 B ở độ chính xác 16 bit đầy đủ; hai card như vậy hoặc CPU off-load cộng với lượng tử hóa có thể xử lý 14 B.
2. Cài đặt
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Kịch bản suy luận nhanh
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
trust_remote_code=True cờ là bắt buộc vì Qwen vận chuyển một tùy chỉnh Nhúng vị trí quay vỏ bánh.
4. Tinh chỉnh với LoRA
Nhờ bộ điều hợp LoRA hiệu quả về tham số, bạn có thể đào tạo chuyên biệt Qwen trên ~50 cặp miền (ví dụ như y tế) trong vòng chưa đầy bốn giờ trên một GPU 24 GB duy nhất:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Tệp bộ điều hợp kết quả (~120 MB) có thể được hợp nhất lại hoặc tải theo yêu cầu.
Tùy chọn: Chạy Qwen 2.5 dưới dạng API
CometAPI hoạt động như một trung tâm tập trung cho các API của một số mô hình AI hàng đầu, loại bỏ nhu cầu phải hợp tác riêng với nhiều nhà cung cấp API. Sao chổiAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp Qwen API và bạn sẽ nhận được 1 đô la trong tài khoản của mình sau khi đăng ký và đăng nhập! Chào mừng bạn đến đăng ký và trải nghiệm CometAPI. Dành cho các nhà phát triển muốn tích hợp Qwen 2.5 vào các ứng dụng:
Bước 1: Cài đặt các thư viện cần thiết:
bash
pip install requests
Bước 2: lấy API Key
- Hướng đến Sao chổiAPI.
- Đăng nhập bằng tài khoản CometAPI của bạn.
- Chọn hình ba gạch Menu chính.
- Nhấp vào “Lấy khóa API” và làm theo lời nhắc để tạo khóa.
Bước 3: Triển khai các cuộc gọi API
Sử dụng thông tin xác thực API để thực hiện yêu cầu tới Qwen 2.5.Thay thế bằng khóa CometAPI thực tế từ tài khoản của bạn.
Ví dụ, trong Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Sự tích hợp này cho phép kết hợp liền mạch các khả năng của Qwen 2.5 vào nhiều ứng dụng khác nhau, nâng cao chức năng và trải nghiệm của người dùng. Chọn “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” điểm cuối để gửi yêu cầu API và thiết lập nội dung yêu cầu. Phương thức yêu cầu và nội dung yêu cầu được lấy từ tài liệu API của trang web của chúng tôi. Trang web của chúng tôi cũng cung cấp thử nghiệm Apifox để thuận tiện cho bạn.
Vui lòng tham khảo trước Qwen 2.5 API tối đa để biết chi tiết về tích hợp. CometAPI đã cập nhật phiên bản mới nhất API QwQ-32B.Để biết thêm thông tin về Model trong Comet API, vui lòng xem Tài liệu API.
Lời khuyên và phương pháp hay nhất
| Kịch bản | Khuyến nghị |
|---|---|
| Hỏi & Đáp tài liệu dài | Chia nhỏ các đoạn văn thành ≤16 K mã thông báo và sử dụng lời nhắc tăng cường truy xuất thay vì ngữ cảnh 100 K đơn giản để giảm độ trễ. |
| Kết quả đầu ra có cấu trúc | Thêm tiền tố vào thông báo hệ thống: You are an AI that strictly outputs JSON. Quá trình huấn luyện căn chỉnh của Qwen 2.5 rất hiệu quả ở chế độ tạo thế hệ bị hạn chế. |
| Hoàn thành mã | Thiết lập temperature=0.0 và top_p=1.0 để tối đa hóa tính xác định, sau đó lấy mẫu nhiều chùm tia (num_return_sequences=4) để xếp hạng. |
| Lọc an toàn | Sử dụng gói biểu thức chính quy “Qwen‑Guardrails” nguồn mở của Alibaba hoặc text‑moderation‑004 của OpenAI làm bước đầu tiên. |
Những hạn chế đã biết của Qwen 2.5
- Dễ bị tiêm ngay. Các cuộc kiểm toán bên ngoài cho thấy tỷ lệ bẻ khóa thành công là 18% trên Qwen 2.5‑VL—một lời nhắc nhở rằng quy mô mô hình không bảo vệ khỏi các lệnh tấn công.
- Tiếng ồn OCR không phải tiếng Latin. Khi được tinh chỉnh cho các tác vụ ngôn ngữ thị giác, đường truyền đầu cuối của mô hình đôi khi gây nhầm lẫn giữa ký tự tượng hình tiếng Trung giản thể và tiếng Trung phồn thể, đòi hỏi các lớp hiệu chỉnh dành riêng cho từng miền.
- Bộ nhớ GPU đạt ngưỡng 128 K. FlashAttention‑2 bù đắp RAM, nhưng quá trình truyền dữ liệu dày đặc 72 B qua 128 K mã thông báo vẫn yêu cầu >120 GB vRAM; người thực hành nên sử dụng window-attend hoặc KV-cache.
Lộ trình & hệ sinh thái cộng đồng
Nhóm Qwen đã ám chỉ Qwen 3.0, nhắm mục tiêu vào xương sống định tuyến lai (Dense + MoE) và tiền huấn luyện giọng nói-hình ảnh-văn bản thống nhất. Trong khi đó, hệ sinh thái đã lưu trữ:
- Q-Đặc vụ – một tác nhân chuỗi suy nghĩ theo kiểu ReAct sử dụng Qwen 2.5‑14B làm chính sách.
- Alpaca tài chính Trung Quốc – một LoRA trên Qwen2.5‑7B được đào tạo với 1 M hồ sơ quản lý.
- Mở plug-in thông dịch – hoán đổi GPT‑4 cho điểm kiểm tra Qwen cục bộ trong VS Code.
Kiểm tra trang “Bộ sưu tập Qwen2.5” của Hugging Face để biết danh sách các điểm kiểm tra, bộ điều hợp và dây nịt đánh giá được cập nhật liên tục.
Phân tích so sánh: Qwen2.5 so với DeepSeek và ChatGPT
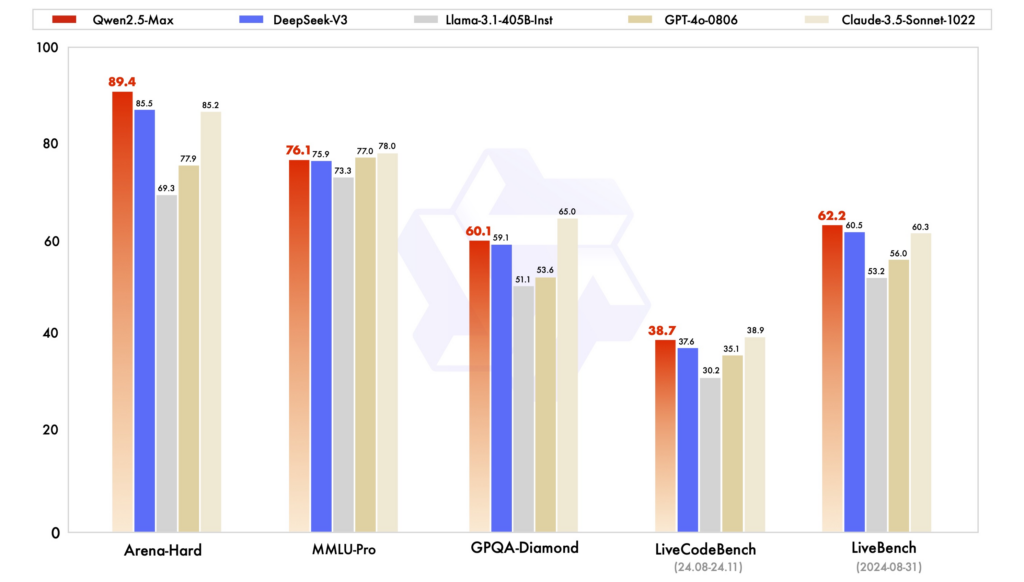
Điểm chuẩn hiệu suất: Trong nhiều đánh giá khác nhau, Qwen2.5 đã chứng minh hiệu suất mạnh mẽ trong các tác vụ đòi hỏi lý luận, mã hóa và hiểu biết đa ngôn ngữ. DeepSeek-V3, với kiến trúc MoE, vượt trội về hiệu quả và khả năng mở rộng, mang lại hiệu suất cao với ít tài nguyên tính toán hơn. ChatGPT vẫn là một mô hình mạnh mẽ, đặc biệt là trong các tác vụ ngôn ngữ mục đích chung.
Hiệu quả và chi phí: Các mô hình của DeepSeek đáng chú ý vì khả năng đào tạo và suy luận tiết kiệm chi phí, tận dụng kiến trúc MoE để chỉ kích hoạt các tham số cần thiết cho mỗi mã thông báo. Qwen2.5, mặc dù dày đặc, cung cấp các biến thể chuyên biệt để tối ưu hóa hiệu suất cho các tác vụ cụ thể. Quá trình đào tạo của ChatGPT liên quan đến các nguồn lực tính toán đáng kể, phản ánh trong chi phí vận hành của nó.
Khả năng truy cập và tính khả dụng của mã nguồn mở: Qwen2.5 và DeepSeek đã áp dụng các nguyên tắc mã nguồn mở ở nhiều mức độ khác nhau, với các mô hình có sẵn trên các nền tảng như GitHub và Hugging Face. Việc Qwen2.5 ra mắt giao diện web gần đây giúp tăng cường khả năng truy cập của nó. ChatGPT, mặc dù không phải là mã nguồn mở, nhưng có thể truy cập rộng rãi thông qua nền tảng và tích hợp của OpenAI.
Kết luận
Qwen 2.5 nằm ở vị trí lý tưởng giữa dịch vụ cao cấp đóng trọng lượng và mô hình sở thích mở hoàn toànSự kết hợp giữa giấy phép cho phép, sức mạnh đa ngôn ngữ, năng lực ngữ cảnh dài và phạm vi rộng các thang đo tham số khiến nó trở thành nền tảng hấp dẫn cho cả nghiên cứu và sản xuất.
Khi bối cảnh LLM nguồn mở tiến triển, dự án Qwen chứng minh rằng tính minh bạch và hiệu suất có thể cùng tồn tạiĐối với các nhà phát triển, nhà khoa học dữ liệu và nhà hoạch định chính sách, việc thành thạo Qwen 2.5 ngay hôm nay là khoản đầu tư cho tương lai AI đa dạng hơn, thân thiện với sự đổi mới hơn.