
Qwen3-Max-Preview est le dernier modèle phare d'Alibaba au sein de la famille Qwen3. Il s'agit d'un modèle de type « Mixture-of-Experts » (MoE) à plus d'un billion de paramètres, avec une fenêtre contextuelle ultra-longue de 262 XNUMX jetons, disponible en préversion pour une utilisation en entreprise et dans le cloud. Il cible :raisonnement approfondi, compréhension de documents longs, codage et flux de travail agentiques.
Informations de base et caractéristiques principales
- Nom / Étiquette :
qwen3-max-preview(Instruire). - Échelle: Plus de 1 XNUMX milliards de paramètres (produit phare à mille milliards de paramètres). Il s'agit de l'étape marketing et statistique clé de la sortie.
- Fenêtre contextuelle : Jetons 262,144 (prend en charge les entrées très longues et les transcriptions multi-fichiers).
- Mode(s) : Variante « Instruct » optimisée pour les instructions avec prise en charge de thinking (chaîne de pensée délibérée) et non-pensée modes rapides dans la famille Qwen3.
- Disponibilité: Accès en avant-première via Chat Qwen, Alibaba Cloud Model Studio (Points de terminaison compatibles OpenAI ou DashScope) et fournisseurs de routage comme API Comet.
Détails techniques (architecture et modes)
- Archi Qwen3-Max suit la lignée de conception Qwen3 qui utilise un mélange de dense + Mélange d'experts (MoE) composants dans des variantes plus grandes, ainsi que des choix d'ingénierie pour optimiser l'efficacité de l'inférence pour un très grand nombre de paramètres.
- Mode de pensée vs mode de non-pensée : La série Qwen3 a introduit un mode de pensée (pour les résultats de type chaîne de pensée à plusieurs étapes) et mode non-pensant pour des réponses plus rapides et concises ; la plateforme expose des paramètres pour basculer ces comportements.
- Fonctionnalités de mise en cache du contexte / performances : Listes de Model Studio cache de contexte prise en charge des requêtes volumineuses pour réduire les coûts d'entrée répétés et améliorer le débit sur les contextes répétés.
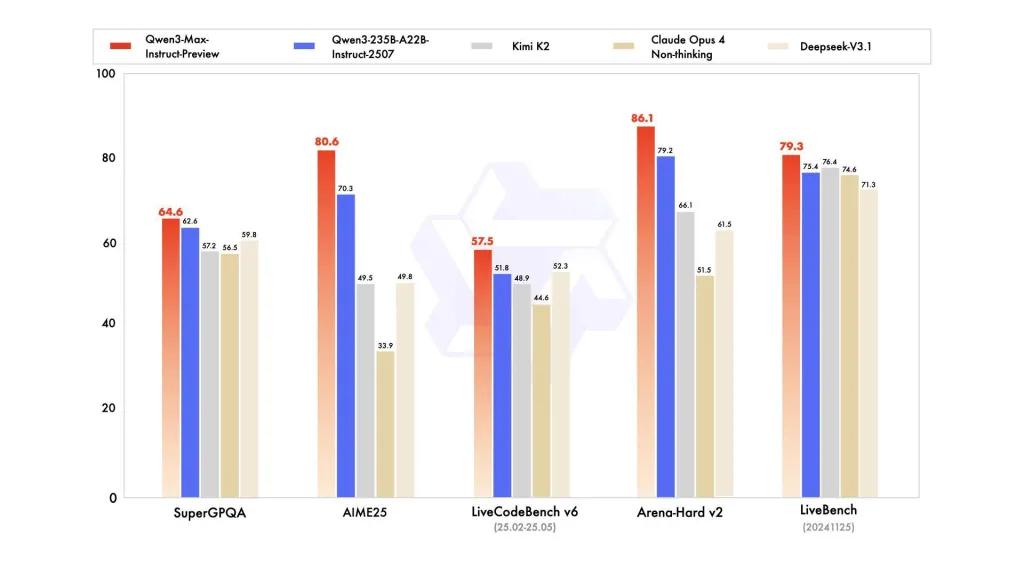
Performances de référence
les rapports font référence à SuperGPQA, aux variantes de LiveCodeBench, à AIME25 et à d'autres suites de concours/benchmark où Qwen3-Max semble compétitif ou leader.
Limites et risques (notes pratiques et de sécurité)
- Opacité pour la recette d'entraînement complète / poids : À titre d'aperçu, les supports d'entraînement, de données et de poids, ainsi que la reproductibilité, peuvent être limités par rapport aux versions précédentes de Qwen3 à poids libre. Certains modèles de la famille Qwen3 ont été publiés à poids libre, mais Qwen3-Max est disponible en version préliminaire contrôlée pour un accès cloud. réduit la reproductibilité pour les chercheurs indépendants.
- Hallucinations et factualité : Les rapports des fournisseurs font état d'une réduction des hallucinations, mais l'utilisation réelle révèlera toujours des erreurs factuelles et des affirmations trop sûres ; les mises en garde habituelles du LLM s'appliquent. Une évaluation indépendante est nécessaire avant tout déploiement à enjeux élevés.
- Coût à grande échelle : Avec une immense fenêtre contextuelle et une grande capacité, coûts symboliques Peut être substantiel pour les messages très longs ou pour un débit de production élevé. Utilisez la mise en cache, le découpage et les contrôles budgétaires.
- Considérations réglementaires et de souveraineté des données : Les utilisateurs professionnels doivent vérifier les régions d'Alibaba Cloud, la résidence des données et les implications en matière de conformité avant de traiter des informations sensibles. (La documentation de Model Studio inclut des points de terminaison et des notes spécifiques à chaque région.)
Cas d'usage
- Compréhension/résumé de documents à grande échelle : notes juridiques, spécifications techniques et bases de connaissances multi-dossiers (avantage : Jeton 262K la fenêtre).
- Raisonnement de code à contexte long et assistance de code à l'échelle du référentiel : compréhension du code multi-fichiers, revues de relations publiques volumineuses, suggestions de refactorisation au niveau du référentiel.
- Tâches complexes de raisonnement et de chaîne de pensée : concours de mathématiques, planification en plusieurs étapes, flux de travail agentiques où les traces « pensantes » aident à la traçabilité.
- Questions-réponses multilingues, d'entreprise et extraction de données structurées : prise en charge de grands corpus multilingues et capacités de sortie structurées (JSON / tableaux).
Comment appeler l'API Qqwen3-max-preview depuis CometAPI
qwen3-max-preview Tarification de l'API dans CometAPI, 20 % de réduction sur le prix officiel :
| Jetons d'entrée | $0.24 |
| Jetons de sortie | $2.42 |
Étapes requises
- Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
- Obtenez la clé API d'accès à l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé : sk-xxxxx et validez.
- Obtenez l'URL de ce site : https://api.cometapi.com/
Utiliser la méthode
- Sélectionnez le point de terminaison « qwen3-max-preview » pour envoyer la requête API et définir le corps de la requête. La méthode et le corps de la requête sont disponibles dans la documentation API de notre site web. Notre site web propose également un test Apifox pour plus de commodité.
- Remplacer avec votre clé CometAPI réelle de votre compte.
- Insérez votre question ou demande dans le champ de contenu : c'est à cela que le modèle répondra.
- Traitez la réponse de l'API pour obtenir la réponse générée.
Appel d'API
CometAPI fournit une API REST entièrement compatible, pour une migration fluide. Informations clés API doc:
- Paramètres de base:
prompt,max_tokens_to_sample,temperature,stop_sequences - Endpoint:
https://api.cometapi.com/v1/chat/completions - Paramètre de modèle: qwen3-max-aperçu
- Authentification:
Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
remplacer
CometAPI_API_KEYavec votre clé ; notez le URL de base.
Python (requêtes) — compatible OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Astuce: utilisé max_input_tokens, max_output_tokenset Model Studio cache de contexte fonctionnalités lors de l'envoi de très grands contextes pour contrôler les coûts et le débit.
Voir aussi Qwen3-Coder