

Trong bối cảnh bị chi phối bởi triết lý “mở rộng bằng mọi giá”—nơi các mô hình như Flux.2 và Hunyuan-Image-3.0 đẩy số lượng tham số lên mức khổng lồ 30B đến 80B—một đối thủ mới đã xuất hiện để phá vỡ hiện trạng. Z-Image, do Tongyi Lab của Alibaba phát triển, đã chính thức ra mắt, phá vỡ kỳ vọng với kiến trúc gọn nhẹ 6 tỷ tham số, mang lại chất lượng đầu ra sánh ngang các ông lớn trong ngành trong khi vẫn chạy được trên phần cứng tiêu dùng.
Ra mắt vào cuối năm 2025, Z-Image (và biến thể tốc độ cao Z-Image-Turbo) đã ngay lập tức thu hút cộng đồng AI, vượt mốc 500.000 lượt tải trong vòng 24 giờ kể từ khi ra mắt. Với việc tạo ra hình ảnh chân thực chỉ trong 8 bước suy luận, Z-Image không chỉ là một mô hình nữa; đó là lực lượng dân chủ hóa trong AI sinh tạo, cho phép tạo nội dung độ trung thực cao trên các laptop mà đối thủ của nó khó có thể chạy nổi.
Z-Image là gì?
Z-Image là một mô hình nền tảng sinh ảnh nguồn mở mới được phát triển bởi nhóm nghiên cứu Tongyi-MAI / Alibaba Tongyi Lab. Đây là mô hình sinh tạo 6 tỷ tham số, xây dựng trên kiến trúc mới Scalable Single-Stream Diffusion Transformer (S3-DiT), kết hợp các token văn bản, token ngữ nghĩa trực quan và token VAE vào một luồng xử lý duy nhất. Mục tiêu thiết kế rất rõ ràng: mang lại mức độ chân thực hàng đầu và khả năng tuân thủ hướng dẫn, đồng thời giảm mạnh chi phí suy luận và cho phép sử dụng thực tế trên phần cứng tiêu dùng. Dự án Z-Image công bố mã nguồn, trọng số mô hình và bản demo trực tuyến theo giấy phép Apache-2.0.
Z-Image phát hành nhiều biến thể. Bản phát hành được đề cập nhiều nhất là Z-Image-Turbo — phiên bản chưng cất, ít bước, tối ưu cho triển khai — cùng với bản Z-Image-Base (checkpoint nền tảng, phù hợp hơn cho tinh chỉnh) và Z-Image-Edit (được tinh chỉnh theo hướng dẫn cho chỉnh sửa ảnh).
Lợi thế “Turbo”: Suy luận 8 bước
Biến thể chủ lực, Z-Image-Turbo, sử dụng kỹ thuật chưng cất tiến trình gọi là Decoupled-DMD (Chưng cất khớp phân phối tách rời). Điều này cho phép mô hình nén quy trình tạo từ mức tiêu chuẩn 30–50 bước xuống chỉ còn 8 bước.
Kết quả: Thời gian tạo dưới 1 giây trên GPU doanh nghiệp (H800) và gần như thời gian thực trên card tiêu dùng (RTX 4090), không gặp hiện tượng “nhựa” hoặc “bị bạc màu” như các mô hình turbo/lightning khác.
4 tính năng chính của Z-Image
Z-Image tích hợp các tính năng phục vụ cả nhà phát triển kỹ thuật lẫn chuyên gia sáng tạo.
1. Mức độ chân thực & thẩm mỹ vượt trội
Dù chỉ có 6 tỷ tham số, Z-Image tạo ra hình ảnh với độ nét gây kinh ngạc. Mô hình vượt trội ở:
- Kết cấu da: Tái hiện lỗ chân lông, khuyết điểm và ánh sáng tự nhiên trên chủ thể con người.
- Vật lý vật liệu: Kết xuất chính xác chất liệu kính, kim loại và vải.
- Ánh sáng: Xử lý ánh sáng điện ảnh và ánh sáng thể tích tốt hơn so với SDXL.
2. Kết xuất văn bản song ngữ bản địa
Một trong những điểm đau lớn của sinh ảnh AI là kết xuất văn bản. Z-Image giải quyết vấn đề này với hỗ trợ bản địa cho cả tiếng Anh và tiếng Trung.
- Mô hình có thể tạo poster, logo và biển hiệu phức tạp với chính tả và thư pháp chính xác ở cả hai ngôn ngữ, tính năng thường thiếu ở các mô hình thiên về phương Tây.
3. Z-Image-Edit: Chỉnh sửa dựa trên hướng dẫn
Song song với mô hình nền tảng, nhóm đã phát hành Z-Image-Edit. Biến thể này được tinh chỉnh cho tác vụ image-to-image, cho phép người dùng chỉnh sửa ảnh hiện có bằng các hướng dẫn ngôn ngữ tự nhiên (ví dụ: “Hãy làm cho người đó mỉm cười”, “Đổi nền thành núi tuyết”). Mô hình duy trì mức độ nhất quán cao về danh tính và ánh sáng trong quá trình biến đổi.
4. Khả năng tiếp cận phần cứng tiêu dùng
- Hiệu quả VRAM: Chạy ổn định trên 6GB VRAM (với lượng tử hóa) đến 16GB VRAM (độ chính xác đầy đủ).
- Chạy cục bộ: Hỗ trợ đầy đủ triển khai cục bộ qua ComfyUI và
diffusers, giúp người dùng thoát khỏi phụ thuộc đám mây.
Z-Image hoạt động như thế nào?
Single-stream diffusion transformer (S3-DiT)
Z-Image khác biệt so với thiết kế hai luồng cổ điển (encoder/dòng riêng cho văn bản và hình ảnh), thay vào đó nối các token văn bản, token VAE hình ảnh và token ngữ nghĩa trực quan thành một đầu vào transformer duy nhất. Cách tiếp cận một luồng này cải thiện mức sử dụng tham số và đơn giản hóa căn chỉnh đa mô thức bên trong backbone transformer, theo tác giả, đem lại tỷ lệ đánh đổi hiệu quả/chất lượng thuận lợi cho một mô hình 6B.
Decoupled-DMD và DMDR (chưng cất + RL)
Để cho phép tạo ít bước (8 bước) mà không chịu phạt chất lượng như thường thấy, nhóm đã phát triển phương pháp chưng cất Decoupled-DMD. Kỹ thuật này tách rời tăng cường CFG (classifier-free guidance) khỏi quá trình khớp phân phối, cho phép tối ưu hóa độc lập từng phần. Sau đó họ áp dụng bước học tăng cường hậu huấn luyện (DMDR) để tinh chỉnh căn chỉnh ngữ nghĩa và thẩm mỹ. Kết hợp lại, chúng tạo ra Z-Image-Turbo với số NFEs ít hơn so với các mô hình khuếch tán điển hình, đồng thời giữ được độ chân thực cao.
Tối ưu thông lượng huấn luyện và chi phí
Z-Image được huấn luyện theo cách tối ưu vòng đời: pipeline dữ liệu được tuyển chọn, giáo trình tinh gọn, và các lựa chọn triển khai chú trọng hiệu năng. Tác giả báo cáo hoàn tất toàn bộ quy trình huấn luyện trong khoảng 314K giờ GPU H800 (≈ USD $630K) — một chỉ số kỹ thuật rõ ràng, có thể tái lập, cho thấy mô hình hiệu quả về chi phí so với các lựa chọn rất lớn (>20B).
Kết quả đánh giá của mô hình Z-Image
Z-Image-Turbo xếp hạng cao trên nhiều bảng xếp hạng đương đại, bao gồm vị trí nguồn mở hàng đầu trên bảng xếp hạng Artificial Analysis Text-to-Image và hiệu năng mạnh trong các đánh giá ưu tiên của con người tại Alibaba AI Arena.
Tuy nhiên, chất lượng trong thực tế còn phụ thuộc vào cách viết prompt, độ phân giải, pipeline upscaling và xử lý hậu kỳ bổ sung.
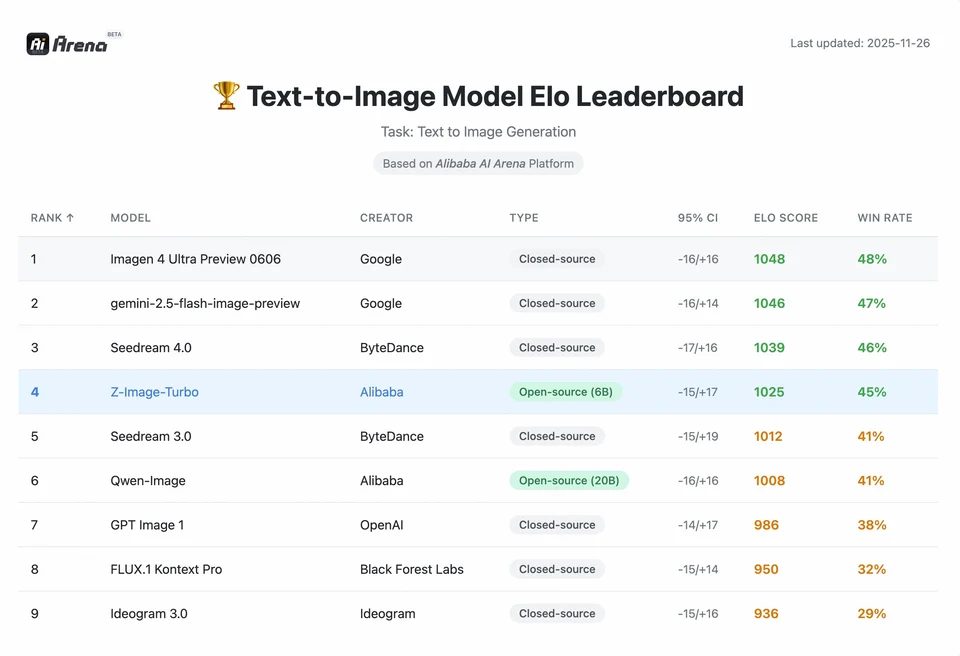
Để hiểu được quy mô thành tựu của Z-Image, chúng ta cần nhìn vào dữ liệu. Dưới đây là phân tích so sánh Z-Image với các mô hình nguồn mở và mô hình thương mại hàng đầu.
Tóm tắt benchmark so sánh
| Tính năng / Chỉ số | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Kiến trúc | S3-DiT (Luồng đơn) | MM-DiT (Luồng kép) | U-Net | Transformer khuếch tán |
| Tham số | 6 tỷ | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Số bước suy luận | 8 bước | 25 - 50 bước | 1 - 4 bước | 30 - 50 bước |
| VRAM yêu cầu | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Kết xuất văn bản | Cao (EN + CN) | Cao (EN) | Vừa (EN) | Cao (CN + EN) |
| Tốc độ tạo (4090) | ~1.5 - 3.0 giây | ~15 - 30 giây | ~0.5 giây | ~20 giây |
| Điểm chân thực | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| Giấy phép | Apache 2.0 | Phi thương mại (Dev) | OpenRAIL | Tùy chỉnh |
Phân tích dữ liệu & hiểu biết về hiệu năng
- Tốc độ so với chất lượng: Dù SDXL Turbo nhanh hơn (1 bước), chất lượng của nó suy giảm đáng kể với các prompt phức tạp. Z-Image-Turbo đạt “điểm ngọt” ở 8 bước, tương đương chất lượng của Flux.2 trong khi nhanh hơn 5x đến 10x.
- Dân chủ hóa phần cứng: Flux.2, dù mạnh mẽ, trên thực tế bị giới hạn bởi các card 24GB VRAM (RTX 3090/4090) để đạt hiệu năng hợp lý. Z-Image cho phép người dùng với card tầm trung (RTX 3060/4060) tạo ảnh chất lượng chuyên nghiệp 1024x1024 tại chỗ.
Nhà phát triển có thể truy cập và sử dụng Z-Image như thế nào?
Có ba cách tiếp cận điển hình:
- Hosted / SaaS (web UI hoặc API): Sử dụng các dịch vụ như z-image.ai hoặc nhà cung cấp khác triển khai mô hình và cung cấp giao diện web hoặc API trả phí để sinh ảnh. Đây là con đường nhanh nhất để thử nghiệm mà không cần thiết lập cục bộ.
- Hugging Face + diffusers pipelines: Thư viện
diffuserstrên Hugging Face bao gồmZImagePipelinevàZImageImg2ImgPipelinevà cung cấp quy trìnhfrom_pretrained(...).to("cuda")điển hình. Đây là cách khuyến nghị cho nhà phát triển Python muốn tích hợp đơn giản và ví dụ có thể tái lập. - Suy luận bản địa tại chỗ từ repo GitHub: Repo Tongyi-MAI bao gồm script suy luận bản địa, các tùy chọn tối ưu (FlashAttention, biên dịch, offload CPU), và hướng dẫn cài đặt
diffuserstừ nguồn để có tích hợp mới nhất. Cách này hữu ích cho nhà nghiên cứu và đội ngũ muốn toàn quyền kiểm soát hoặc chạy huấn luyện/tinh chỉnh tùy biến.
Ví dụ Python tối thiểu trông như thế nào?
Dưới đây là đoạn mã Python ngắn gọn sử dụng diffusers của Hugging Face minh họa sinh ảnh từ văn bản với Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Ghi chú: giá trị mặc định và thiết lập khuyến nghị cho guidance_scale khác với các mô hình Turbo; tài liệu cho thấy guidance có thể đặt thấp hoặc bằng 0 đối với Turbo tùy vào hành vi mong muốn.
Làm thế nào để chạy image-to-image (chỉnh sửa) với Z-Image?
ZImageImg2ImgPipeline hỗ trợ chỉnh sửa ảnh. Ví dụ:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Cách này phản chiếu mô thức sử dụng chính thức và phù hợp cho các tác vụ chỉnh sửa sáng tạo và inpainting.
Nên tiếp cận prompt và guidance như thế nào?
- Hãy rõ ràng về cấu trúc: Với cảnh phức tạp, hãy cấu trúc prompt để bao gồm bố cục cảnh, đối tượng trọng tâm, camera/ống kính, ánh sáng, tâm trạng và các yếu tố văn bản. Z-Image hưởng lợi từ prompt chi tiết và xử lý tốt các tín hiệu vị trí/câu chuyện.
- Tinh chỉnh
guidance_scalecẩn thận: Các mô hình Turbo có thể khuyến nghị giá trị guidance thấp; cần thử nghiệm. Trong nhiều quy trình Turbo,guidance_scale=0.0–1.0với seed và số bước cố định sẽ cho kết quả ổn định. - Dùng image-to-image cho chỉnh sửa có kiểm soát: Khi cần giữ bố cục nhưng thay đổi phong cách/màu sắc/đối tượng, bắt đầu từ ảnh khởi tạo và dùng
strengthđể kiểm soát mức độ thay đổi.
Trường hợp sử dụng tốt nhất và thực hành khuyến nghị
1. Lập mẫu nhanh & vẽ storyboard
Trường hợp sử dụng: Đạo diễn phim và nhà thiết kế game cần hình dung cảnh trong tức thì.
Vì sao Z-Image? Với thời gian tạo dưới 3 giây, người sáng tạo có thể lặp qua hàng trăm ý tưởng trong một phiên, tinh chỉnh ánh sáng và bố cục theo thời gian thực mà không phải chờ đợi hàng phút cho một lần render.
2. Thương mại điện tử & Quảng cáo
Trường hợp sử dụng: Tạo nền sản phẩm hoặc ảnh phong cách sống cho hàng hóa.
Thực hành tốt nhất: Dùng Z-Image-Edit.
Tải lên ảnh sản phẩm thô và sử dụng prompt hướng dẫn như "Đặt chai nước hoa này trên bàn gỗ trong khu vườn ngập nắng." Mô hình giữ nguyên tính toàn vẹn của sản phẩm trong khi “tưởng tượng” nền chân thực.
3. Tạo nội dung song ngữ
Trường hợp sử dụng: Chiến dịch marketing toàn cầu cần tài sản cho cả thị trường phương Tây và châu Á.
Thực hành tốt nhất: Tận dụng khả năng kết xuất văn bản.
- Prompt: "Một biển hiệu neon ghi 'OPEN' và '营业中' phát sáng trong con hẻm tối."
- Z-Image sẽ kết xuất chính xác cả ký tự tiếng Anh và tiếng Trung, điều mà hầu hết mô hình khác không làm được.
4. Môi trường ít tài nguyên
Trường hợp sử dụng: Chạy sinh tạo AI trên thiết bị biên hoặc laptop văn phòng tiêu chuẩn.
Mẹo tối ưu: Dùng phiên bản INT8 đã lượng tử hóa. Điều này giảm sử dụng VRAM xuống dưới 6GB với tổn thất chất lượng không đáng kể, giúp khả thi cho ứng dụng cục bộ trên laptop không dành cho game.
Kết luận: ai nên dùng Z-Image?
Z-Image được thiết kế cho tổ chức và nhà phát triển muốn mức độ chân thực cao với độ trễ và chi phí thực tế, và ưu tiên giấy phép mở cùng triển khai tại chỗ hoặc lưu trữ tùy biến. Mô hình đặc biệt hấp dẫn với các nhóm cần lặp nhanh (công cụ sáng tạo, mockup sản phẩm, dịch vụ thời gian thực) và với nhà nghiên cứu/cộng đồng quan tâm đến tinh chỉnh một mô hình ảnh gọn nhưng mạnh.
CometAPI cung cấp các mô hình Grok Image ít hạn chế tương tự, cũng như các mô hình như Nano Banana Pro, GPT- image 1.5, Sora 2(Sora 2 có tạo được nội dung NSFW không? Làm sao để thử?) v.v.—miễn là bạn có các mẹo và thủ thuật NSFW phù hợp để vượt qua hạn chế và bắt đầu tạo tự do. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập CometAPI và lấy API key. CometAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.
Sẵn sàng bắt đầu?→ Dùng thử miễn phí để tạo !