

DeepSeek has released DeepSeek V3.2 as the successor to its V3.x line and an accompanying DeepSeek-V3.2-Speciale variant that the company positions as a high-performance, reasoning-first edition for agent/tool use. V3.2 builds on experimental work (V3.2-Exp) and introduces higher reasoning capability, a Speciale edition optimized for “gold-level” math/competitive programming performance, and what DeepSeek describes as a first-of-its-kind dual-mode “thinking + tool” system that tightly integrates internal step-by-step reasoning with external tool invocation and agent workflows.
What is DeepSeek V3.2 — and how does V3.2-Speciale differ?
DeepSeek-V3.2 is the official successor to DeepSeek’s experimental V3.2-Exp branch. It is described by DeepSeek as a “reasoning-first” model family built for agents, i.e., models tuned not only for natural conversational quality but specifically for multi-step inference, tool invocation, and reliable chain-of-thought style reasoning when operating in environments that include external tools (APIs, code execution, data connectors).
What is DeepSeek-V3.2 (base)
- Positioned as the mainstream production successor to the V3.2-Exp experimental line; intended for broad availability via DeepSeek’s app/web/API.
- Keeps a balance between compute efficiency and robust reasoning for agentic tasks.
What is DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale is a variant that DeepSeek markets as a higher-capability “Special Edition” tuned for contest-level reasoning, advanced mathematics, and agent performance. Marketed as a higher-capability variant that “pushes the boundaries of reasoning capabilities.” DeepSeek currently exposes Speciale as an API-only model with temporary access routing; early benchmarks suggest it is positioned to compete with high-end closed models in reasoning and coding benchmarks.
What lineage and engineering choices led to V3.2?
V3.2 inherits a lineage of iterative engineering DeepSeek publicized across 2025: V3 → V3.1 (Terminus) → V3.2-Exp (an experimental step) → V3.2 → V3.2-Speciale. The experimental V3.2-Exp introduced DeepSeek Sparse Attention (DSA) — a fine-grained sparse attention mechanism aimed at lowering memory and compute costs for very long context lengths while preserving output quality. That DSA research and the cost-reduction work served as a technical stepping stone for the official V3.2 family.
What’s new in official DeepSeek 3.2?
1) Enhanced reasoning ability — how is reasoning improved?
DeepSeek markets V3.2 as “reasoning-first.” That means the architecture and fine-tuning focus on reliably performing multi-step inference, maintaining internal chains of thought, and supporting the kinds of structured deliberation agents need to use external tools correctly.
Concretely, improvements include:
- Training and RLHF (or similar alignment procedures) tuned to encourage explicit stepwise problem solving and stable intermediate states (useful for math reasoning, multi-step code generation, and logic tasks).
- Architectural and loss-function choices that preserve longer context windows and allow the model to reference earlier reasoning steps with fidelity.
- Practical modes (see “dual-mode” below) that let the same model operate either in faster “chat” style mode or in a deliberative “thinking” mode where it intentionally works through intermediate steps before acting.
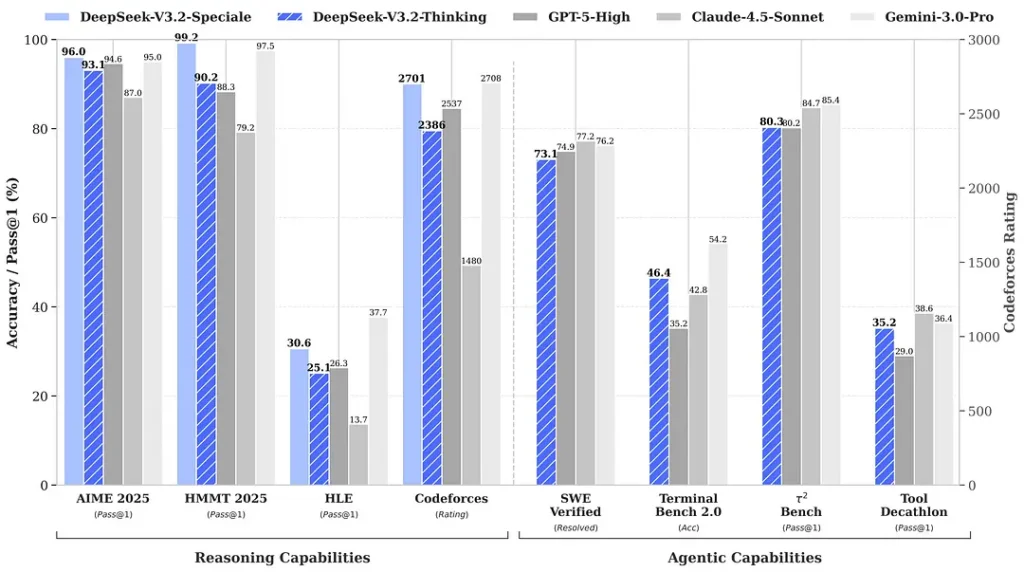
Benchmarks cited around the release claim notable gains in math and reasoning suites; independent early community benchmarks also report impressive scores on competitive evaluation sets:
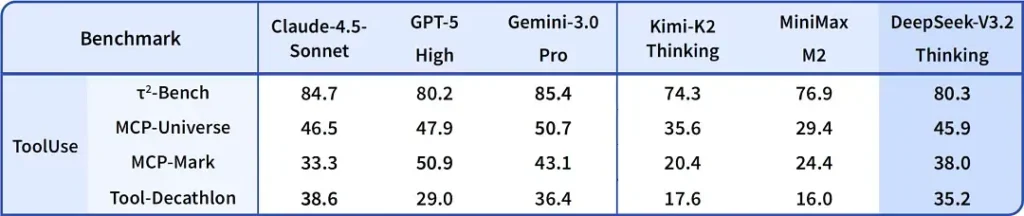
2) Breakthrough performance in the Special Edition — how much better?
DeepSeek-V3.2-Speciale is claimed to deliver a step up in reasoning accuracy and agent orchestration compared to the standard V3.2. The provider frames Speciale as a performance tier targeted at heavy reasoning workloads and challenging agent tasks; it’s currently API-only and offered as a temporary, higher-capability endpoint (DeepSeek indicated Speciale availability will be limited initially). The Speciale version integrates the previous mathematical model DeepSeek-Math-V2; It can prove mathematical theorems and verify logical reasoning on its own; It has achieved remarkable results in multiple world-class competitions:
- 🥇 IMO (International Mathematical Olympiad) Gold Medal
- 🥇 CMO (Chinese Mathematical Olympiad) Gold Medal
- 🥈 ICPC (International Computer Programming Contest) Second Place (Human Contest)
- 🥉 IOI (International Olympiad in Informatics) Tenth Place (Human Contest)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) First-ever implementation of a dual-mode “thinking + tool” system
One of the most practically interesting claims in V3.2 is a dual-mode workflow that separates (and lets you choose between) fast conversational operation and a slower, deliberative “thinking” mode that integrates tightly with tool use.
- “Chat / fast” mode: Designed for low-latency, user-facing chat with concise answers and fewer internal reasoning traces — good for casual help, short Q&A, and speed-sensitive applications.
- “Thinking / reasoner” mode: Optimized for rigorous chain-of-thought, stepwise planning, and orchestrating external tools (APIs, database queries, code execution). When operating in thinking mode the model produces more explicit intermediate steps, which can be inspected or used to drive safe, correct tool calls in agentic systems.
This pattern (a two-mode design) was present in earlier experimental branches, and DeepSeek has integrated it more deeply in V3.2 and Speciale — Speciale currently supports the thinking mode exclusively (hence its API gating). The ability to flip between speed and deliberation is valuable for engineering because it lets developers pick the right trade-off for latency vs. reliability when building agents that must interact with real-world systems.
Why it’s notable: Many modern systems offer either a strong chain-of-thought model (to explain reasoning) or a separate agent/tool orchestration layer. DeepSeek’s framing suggests a tighter coupling — the model can “think” and then deterministically call tools, using tool responses to inform subsequent thinking — which is more seamless for developers building autonomous agents.
Where to get DeepSeek v3.2
Short answer — you can get DeepSeek v3.2 in several ways depending on what you need:
- Official web/app (use online) — try the DeepSeek web interface or mobile app to use V3.2 interactively.
- API access — DeepSeek exposes V3.2 through their API (docs include model names / base_url and pricing). Sign up for an API key and call the v3.2 endpoint.
- Downloadable/open weights (Hugging Face) — the model (V3.2 / V3.2-Exp variants) is published on Hugging Face and can be downloaded (open-weight). Use
huggingface-hubortransformersto pull the files. - CometAPI — An AI API aggregation platform provide hosted endpoints V3.2-Exp. The price is cheaper than the official price.
A couple of practical notes:
- If you want weights to run locally, go to the Hugging Face model page (accept any license / access conditions there) and use
huggingface-cliortransformersto download; the GitHub repo usually shows the exact commands. - If you want production usage via API, follow you want platform such as cometapi API docs for endpoint names and the correct
base_urlfor the V3.2 variant.
DeepSeek-V3.2-Speciale:
- Open for research use only, supports “Thinking Mode” dialogue, but does not support tool calls.
- Maximum output can reach 128K tokens (ultra-long Thinking Chain).
- Currently free to test until December 15, 2025.
Final thoughts
DeepSeek-V3.2 represents a meaningful step in the maturing of reasoning-centric models. Its combination of improved multi-step reasoning, specialized high-performance editions (Speciale), and a productionized “thinking + tool” integration is noteworthy for anyone building advanced agents, coding assistants, or research workflows that must interleave deliberation with external actions.
Developers can access DeepSeek V3.2 through CometAPI. To begin, explore the model capabilities of CometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for CometAPI today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!