

Gemini Embedding 2 is Google's first natively multimodal embedding model that maps text, images, audio, video, and PDFs into a single 3,072-dimensional semantic vector space (with configurable output sizes). It introduces Matryoshka Representation Learning to provide nested / truncated embeddings, improved multilingual performance (100+ languages), and optimized controls for task-specific embeddings (e.g., task:search, task:code).
What is Gemini Embedding 2?
Gemini Embedding 2 is a unified embedding model from Google that maps multiple input modalities — text, images, audio, video, and documents — into a single semantic vector space. Each embedding is (by default) a 3,072-dimensional floating-point vector that represents the semantic meaning of the input so that semantically similar items (regardless of modality) are close in vector space.The headline capabilities are:
- Wide language and format coverage: a single model that accepts text, images, audio, video and documents and places them in one semantic vector space. Gemini Embedding 2 is documented to capture semantic intent across 100+ languages and to accept common file formats (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), with concrete per-request limits (e.g., up to a handful of images or tens of seconds of audio/video per request—see “How to use” below).
- True multimodality: a single model that accepts text, images, audio, video and documents and places them in one semantic vector space so you can compare or retrieve across modalities (e.g., text → image, audio → text).
- Large default dimensionality with flexible truncation: the model outputs 3072-dimensional vectors by default, but uses Matryoshka Representation Learning (MRL) to concentrate the most important semantic content in the first dimensions so you can truncate to 1536, 768 (or lower) with only modest drops in retrieval quality. This reduces storage and compute cost tradeoffs.
Why this matters. Historically, embeddings were mostly text-only or required separate encoders per modality with complex cross-modal alignment layers. Gemini Embedding 2 removes that barrier by natively supporting multiple formats — so a text query can retrieve an image or a short clip by semantic similarity without intermediate transcription or manual mapping. That simplifies RAG (retrieval-augmented generation), semantic search, and multimodal retrieval pipelines.
Key features & capabilities (what’s new)
1. True native multimodality (one embedding space)
A single model that accepts text, images, audio, video and documents and places them in one semantic vector space. Gemini Embedding 2 maps text, images, audio, video, and documents into the same embedding space so cross-modal retrieval (text→image, audio→text) works directly without cross-model alignment. This reduces pipeline complexity and simplifies RAG (Retrieval-Augmented Generation) stacks.
2. 3,072-dimensional default vectors with adjustable output
Gemini Embedding 2 outputs 3072-dimensional vectors by default, but uses Matryoshka Representation Learning (MRL) to concentrate the most important semantic content in the first dimensions so you can truncate to 1536, 768 (or lower) with only modest drops in retrieval quality. This reduces storage and compute cost tradeoffs.
3. Matryoshka Representation Learning (MRL)
MRL produces "nested" embeddings—like Russian nesting dolls—so lower-dimensional slices preserve higher-level semantics. This lets systems choose an operating point (storage/accuracy tradeoff) without maintaining several separate embedding models. Early blog analysis and documentation describe this technique as a core innovation for flexibility.
4. Task hints / customized embedding objectives
API accepts task hints (e.g., task:search, task:code retrieval, task:semantic-similarity) so the model can optimize the embedding geometry for specific downstream relations—similar to task conditioning used in earlier embedding systems but extended to multimodal inputs.
5. Language and modality breadth
Gemini Embedding 2 is documented to capture semantic intent across 100+ languages and to accept common file formats (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), with concrete per-request limits (e.g., up to a handful of images or tens of seconds of audio/video per request—see “How to use” below).
Performance benchmarks
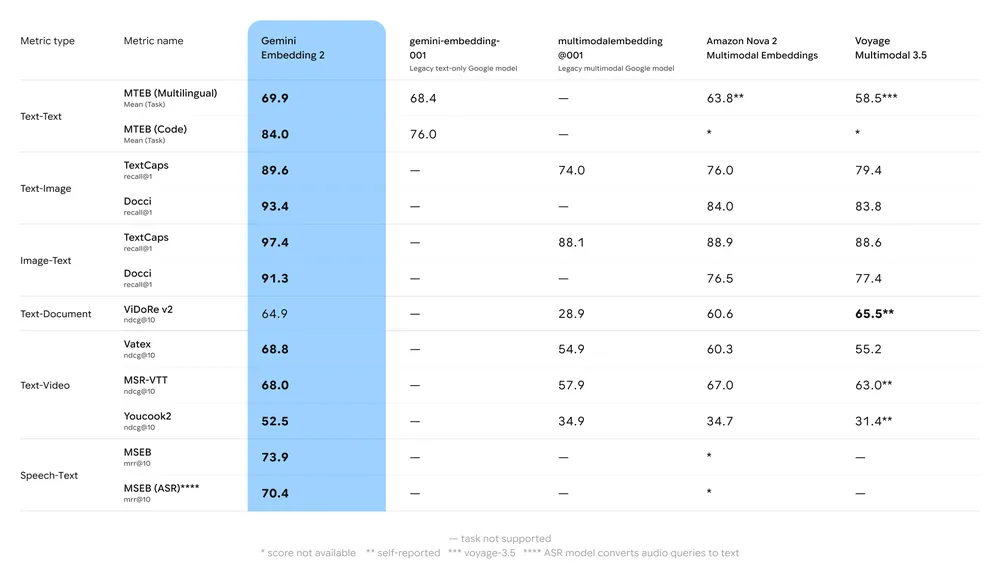
Key benchmark summary:
- MTEB (Massive Text Embedding Benchmark): Reported strong placement on multilingual MTEB leaderboards for English and multilingual tasks; analyses show meaningful uplift vs. Gemini’s previous embedding models and many proprietary alternatives.
- Multimodal retrieval: Outperforms or matches leading single-modal embeddings when used for cross-modal similarity (e.g., text→image retrieval), due to native multimodal training.
- Latency & throughput: Cloud-hosted embedding generation, but latency-sensitive use cases may prefer truncated vectors or alternative lightweight embedding models for on-edge needs.
Gemini Embedding 2 vs gemini-embedding-001 and text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| Modalities supported | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| Default embedding dim. | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| Native audio/video support | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| Typical use cases | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
Technical specs & limits
Default & adjustable embedding size
- Default: 3,072 dimensions.
- Adjustable:
output_dimensionalityparameter allows requesting lower dimensional outputs to save storage / CPU. Use cases with massive vector stores often reduce dims to 512–1,024 for cost reasons but accept some accuracy tradeoffs.
Supported modalities and per-request limits
- Images: PNG, JPEG — up to 6 images per request (vendor-reported limits).
- Video: MP4, MOV — vendor reports up to ~128 seconds per video for single-request embedding.
- Audio: MP3, WAV — vendor reports up to ~80 seconds per audio input.
- Documents: PDFs — up to 6 pages per request (vendor reporting).
- Token limit for textual content: model supports large token inputs; practical per-request token caps exist (check API docs and Vertex AI quotas).
Availability & access
- Public preview: Gemini Embedding 2 was released as a public preview and is available through the Gemini API and Google Cloud's Vertex AI for immediate experimental use
Frequently asked questions (FAQ)
Q1: What modalities does Gemini Embedding 2 support?
A: Text, images (PNG/JPEG), video (MP4/MOV), audio (MP3/WAV) and PDF documents — all mapped into the same semantic vector space.
Q2: What is the default vector size for Gemini Embedding 2?
A: Default is 3,072 dimensions. You can request smaller output dimensionality via the API.
Q3: Is Gemini Embedding 2 available now?
A: Yes — it was announced as a public preview and is available through the Gemini API and Vertex AI (check the model id gemini-embedding-2-preview and current changelog).
Q4: How does it compare to embeddings from other providers?
A: Independent vendor tests report Gemini Embedding 2 ranks among the top proprietary models for multilingual text and shows state-of-the-art performance for several multimodal tasks. Exact rankings vary by task and dataset; test on your own data.
Q5: Will I need to transcribe audio to use Gemini Embedding 2?
A: No — Gemini Embedding 2 can accept audio directly and produce embeddings without first transcribing to text, enabling end-to-end audio semantic retrieval.
Q6: How do I lower storage costs for 3,072-dim vectors?
A: Options include requesting lower output_dimensionality, using float16/quantization/PQ, and storing compressed representations in your vector DB. Vendor posts provide workflows and best practices.
What comes next — should I adopt it now?
Gemini Embedding 2 is a major step in unifying multimodal retrieval and simplifies architectures that previously required separate retrievers for text, vision and speech. The key decision points for adoption:
- Adopt sooner if your product needs robust cross-modal retrieval (text↔image/video/audio), or if maintaining multiple single-modality retrievers is costly and complex.
- Pilot now if you want to evaluate MRL truncation and measure cost vs quality (keep a hybrid deployment: 1536 as primary, 3072 for re-ranking).
- Wait if your workload is extremely cost-sensitive and only text retrieval is required — top text-only models (e.g., OpenAI text-embedding-3-large) remain competitive and sometimes cheaper depending on your pipeline and contract.
Developers can access Gemini Embedding 2 and OpenAI text-embedding-3 API via CometAPI now.To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up for cometapi today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!