
.webp&w=3840&q=75)
GLM-5.1 represents a pivotal shift in the AI landscape. As Chinese AI companies accelerate commercialization while open-sourcing frontier capabilities, this model narrows the gap with proprietary leaders like OpenAI’s GPT-5.4, Anthropic’s Claude Opus 4.6, and Google’s Gemini 3.1 Pro—particularly in real-world software engineering. Trained on the same 744B-parameter MoE architecture as GLM-5 but heavily optimized for agentic workflows, it excels where most LLMs falter: long, ambiguous, iterative tasks that require planning, experimentation, debugging, and self-correction over thousands of tool calls.
Now, CometAPI integrates GLM-5.1 and GLM-5, and developers can also see other top Western models and access them at a very low API price (which is also an advantage of CometAPI compared to other competitors).
What is GLM-5.1?
GLM-5.1 is Z.ai’s newest flagship language model and the company’s latest push into long-horizon, agent-style software work. In Z.ai’s own words, it is designed for tasks that need continuous execution rather than one-shot responses, and it is positioned as a model that can plan, execute, refine, and deliver within a single extended run. Z.ai’s release notes say GLM-5.1 is built with multi-turn supervised fine-tuning, reinforcement learning, and a process-quality evaluation framework, and that it improves stability, consistency, and tool use over extended tasks.
That positioning matters because GLM-5.1 is not being sold as just “another chat model.” It is aimed at engineering workflows where models need to keep a goal in mind, handle intermediate steps, and recover from mistakes without losing the thread,it as a model for autonomous planning, sustained execution, bug fixing, and strategy iteration, which is a very different product story from a casual assistant or a short-context coding copilot.
A useful practical detail: GLM-5.1 is text-only, it is supported in the GLM Coding Plan and can be used in popular coding agents such as Claude Code and OpenClaw, which makes it especially relevant for teams that want a model to sit inside an existing developer workflow rather than replace it.
Core Technical Specifications (Inherited and Refined from GLM-5):
- Architecture: Mixture-of-Experts (MoE) with 744 billion total parameters and approximately 40 billion active parameters per inference.
- Context Window: 203K–204.8K tokens (with support for up to 131K output tokens).
- Key Enhancements: DeepSeek Sparse Attention (DSA) for efficient long-context handling and reduced deployment costs; advanced asynchronous reinforcement learning infrastructure (via Z.ai’s “slime” framework) for more effective post-training.
- Availability: Open-weights (MIT license on Hugging Face via zai-org/GLM-5.1), API access through Z.ai’s platform and aggregators like CometAPI, and integrated into GLM Coding Plan tools (Claude Code / OpenClaw compatible).
Unlike earlier GLM models focused on general intelligence or short “vibe coding,” GLM-5.1 targets production-grade autonomous agents. It can independently plan, execute, benchmark, debug, and iterate on complex engineering projects for hours without human intervention—capabilities that position it as a direct competitor to specialized coding agents from Anthropic and OpenAI.
The release coincided with a ~10% API price increase (input tokens ~$0.54/M, output ~$4.40/M), yet remains dramatically cheaper than equivalents like Anthropic’s Opus 4.6 (250–470% more expensive).
GLM-5.1 Benchmark Performance
Z.ai positions GLM-5.1 as the world’s strongest open-source model and a global top-3 performer in agentic coding. Performance data comes from official evaluations on SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0, and custom long-horizon scenarios.
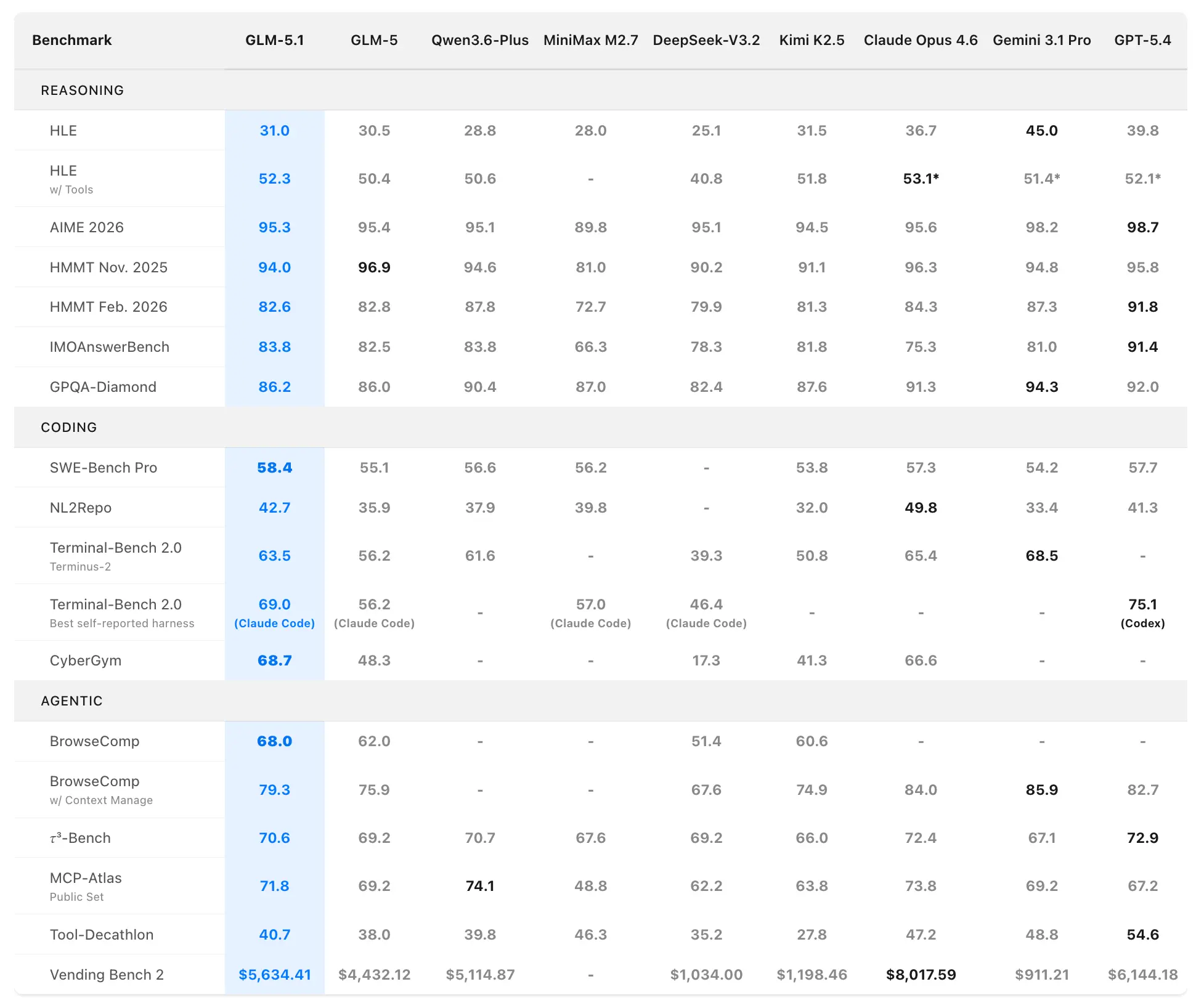
Coding and Agentic Benchmarks
SWE-Bench Pro (realistic software engineering tasks requiring repository navigation, code editing, and functional verification):
- GLM-5.1: 58.4 (new state-of-the-art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 is the first domestic (Chinese) and open-source model to claim the top spot on this rigorous benchmark, which closely mirrors professional developer workflows.
NL2Repo (natural language to full repository generation):
- GLM-5.1: 42.7 (wide lead over GLM-5’s 35.9)
- Competitive models range 32.0–49.8 (specific leaders vary by harness).
Terminal-Bench 2.0 (real-world terminal and systems tasks):
- Terminus-2 harness: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Best self-reported (Claude Code): Up to 69.0.
In a separate coding harness evaluation (Claude Code-style), GLM-5.1 scored 45.3—reaching 94.6% of Claude Opus 4.6’s 47.9 and a 28% improvement over GLM-5’s 35.4.
Composite Ranking: #1 open-source, #1 Chinese model, #3 globally across SWE-Bench Pro + NL2Repo + Terminal-Bench.
Long-Horizon Task Performance: The Real Differentiator
Standard benchmarks measure one-shot or short-session performance. GLM-5.1 shines in extended autonomous runs:
- VectorDBBench Optimization (600+ iterations, 6,000+ tool calls): Starting from a Rust skeleton, GLM-5.1 iteratively redesigned indexing, compression, routing, and pruning, achieving 21.5k QPS (6× the prior 50-turn best of 3,547 QPS by Claude Opus 4.6) while maintaining ≥95% recall on SIFT-1M. It exhibited “staircase” progress with structural breakthroughs every 100–200 iterations.
- KernelBench Level 3 (full ML model optimization, 1,000+ turns): Geometric mean speedup of 3.6× across 50 complex problems (outperforming torch.compile max-autotune’s 1.49×). GLM-5.1 continued improving long after GLM-5 plateaued; only Claude Opus 4.6 edged it at 4.2×.
- Linux Desktop Web App Build (8+ hours, open-ended): Given only a natural-language prompt and no starter code, GLM-5.1 autonomously built a functional Linux-style desktop environment—complete with taskbar, windows, interactions, and polish—where prior models produced only basic skeletons.
These results demonstrate GLM-5.1’s ability to maintain coherence, self-evaluate, revise strategies, and escape local optima over extremely long horizons—capabilities Z.ai explicitly engineered for real-world agentic systems.
How is GLM-5.1 different from GLM-5?
GLM-5 and GLM-5.1 are closely related, but they are not positioned the same way. GLM-5 is Z.AI’s earlier foundation model for Agentic Engineering. It is designed for complex system engineering and long-range agent tasks, with open-weight SOTA coding and agent capability, and coding performance that approaches Claude Opus 4.5 in real programming scenarios. It scores 77.8 on SWE-bench Verified and 56.2 on Terminal Bench 2.0.
GLM-5.1, by contrast, is framed as the next step toward long-horizon tasks and more reliable sustained execution, improves stability, consistency, and tool use over extended tasks, and that it is better aligned with Claude Opus 4.6 overall. In other words, GLM-5 is the earlier engineering-centric foundation model, while GLM-5.1 is the more task-endurance-oriented flagship.
There are also architectural and training differences in the GLM-5 generation that help explain the jump. GLM-5 expanded from 355B parameters (32B activated) to 744B parameters (40B activated), increased pre-training data from 23T to 28.5T, added an asynchronous reinforcement-learning framework, and integrated DeepSeek Sparse Attention to preserve long-text quality while improving efficiency. Those details are tied to GLM-5, but they form the base that GLM-5.1 appears to build on.
GLM-5.1 vs Other Frontier Models
GLM-5.1 stands out as the strongest open-source contender while offering compelling price/performance.
Comparison Table: Major Coding & Agentic Benchmarks (April 2026)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Long-Horizon Sustained? | Open-Source? | Approx. API Price (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | Yes (600+ iter, 8 hrs) | Yes | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limited | Yes | Lower (pre-hike) |
| GPT-5.4 | 57.7 | — | — | — | Strong | No | Higher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Strongest | No | ~250–470% more expensive |
| Gemini 3.1 Pro | 54.2 | — | — | — | Good | No | Higher |
Verdict: GLM-5.1 wins on open-source accessibility, cost, and specific long-horizon coding metrics. It trades blows with closed-source leaders in agentic scenarios while democratizing frontier capabilities.
Application scenarios of GLM-5.1
1) Autonomous software engineering
GLM-5.1 is most compelling when the task resembles a real engineering sprint: read the codebase, plan the change, implement it, test it, fix the regressions, and keep iterating until the result is stable. Z.ai’s release notes explicitly emphasize autonomous planning, sustained execution, bug fixing, and strategy iteration, which makes this model feel purpose-built for coding agents and software delivery pipelines.
2) Long-running agent workflows
If your use case involves many tool calls, long multi-step workflows, or repeated self-correction, GLM-5.1’s design is a strong match. The documentation highlights tool invocation, structured output, MCP integration, and tool-streaming support, all of which are useful when a model is not just answering, but operating inside a larger system.
3) Enterprise knowledge work and reporting
GLM-5.1 is also positioned for office productivity tasks such as PowerPoint, Word, PDF, and Excel workflows. Z.ai says it improves complex content organization, layout design, structured output, and visual polish, which makes it a plausible fit for report generation, teaching materials, research summaries, and other document-heavy work.
4) Front-end prototyping and artifacts
Z.ai says GLM-5.1 is well suited to website generation, interactive pages, and front-end prototyping, with less templated structure and better task completion quality. That suggests a good fit for product teams who need a fast bridge from brief to prototype, especially when the prototype must be usable rather than just pretty.
5) Complex conversation and instruction-following
Although the headline story is coding, GLM-5.1 is also described as stronger in open-ended Q&A, complex instructions, and multi-turn interaction. That makes it useful for assistant-style workflows where the model must keep track of constraints, revise outputs, and preserve context across longer conversations.
Conclusion: Why GLM-5.1 Matters in 2026
GLM-5.1 isn’t just another incremental release—it signals the arrival of truly capable open-source agentic AI. By excelling in the hardest real-world engineering benchmarks while remaining affordable and open, Z.ai has raised the bar for the entire industry. Whether you’re a solo developer, enterprise team, or researcher, GLM-5.1 offers unmatched autonomy for long-horizon coding tasks at a fraction of proprietary costs.
Ready to try it? Check CometAPI GLM-5.1 model, Hugging Face repo, or GLM Coding Plan for immediate access.