

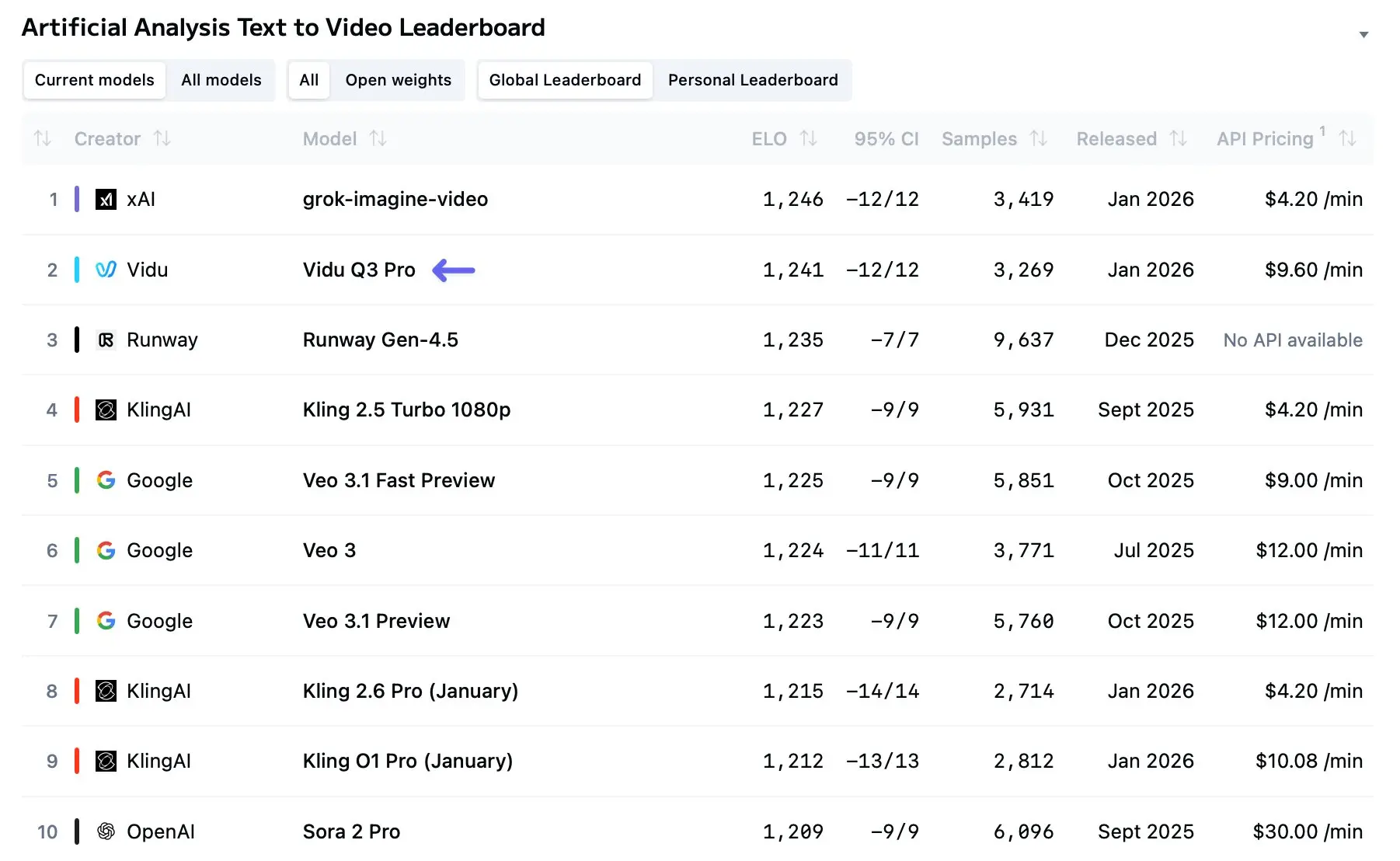
Vidu Q3 entered the conversation in early 2026 as one of the clearest signals yet that AI-driven video generation is moving from short, novelty clips toward genuinely narrative, multi-shot storytelling. In the months since its wide release Vidu Q3 has become a staple in creator workflows, research pilots, and commercial pilots — and for good reason: it pushes duration, audiovisual integration, and multi-shot coherence farther than most earlier models while offering a developer-facing API for programmatic use.
What is Vidu Q3?
Vidu Q3 is the latest flagship iteration of ShengShu Technology’s large video model (LVM) architecture. Unlike its predecessors (Vidu 1.0 and 1.5) which required separate workflows for visual generation and audio post-production, Vidu Q3 is an "all-in-one" generative engine.
The core breakthrough of Vidu Q3 is its ability to generate high-definition visuals and high-fidelity audio simultaneously.[ By understanding the physics of sound and light together, the model eliminates the "uncanny valley" of desynchronized audio often seen in competitor models. It supports up to 16 seconds of continuous generation in native 1080p resolution, positioning it as a production-ready tool for short films, commercials, and narrative storytelling.
How Does Vidu Q3 Work Under the Hood?
While core architecture details are proprietary, Vidu builds on U-ViT fusion of diffusion models and transformers — a design known for balancing coherence, temporal continuity, and expressiveness in video generation.
This hybrid architecture enables the model to reason about motion, sound, and narrative context over extended sequences.
6 Vidu Q3’s standout features
1. Extended-duration generation — how long can it go?
One of Vidu Q3’s headline features is longer single-generation duration. Many earlier generation models focused on micro-clips; Q3 intentionally extends the clip length to permit simple story arcs and multi-shot sequences without forcing creators to splice many tiny clips together. Platform documentation and partner portals advertise up to ~16 seconds of native generation in one pass (format and quality options may vary by provider and API plan). This matters because moving from 4–8 seconds to 16 seconds changes how creators plan scenes, write beats, and pace audio cues.
2. Visual fidelity and temporal coherence
Independent evaluations and early benchmarks show that Vidu Q3 produces clearer imagery and fewer frame-level distortions than earlier consumer-grade models. Improvements in architecture and data augmentation appear to reduce flicker and improve motion continuity for clips under 10–16 seconds. However, the model can still struggle with dense, multi-subject scenes (crowds, complicated physical interactions) where occlusion and fine motion need strong physics reasoning. Comparative ranking sites and model leaderboards have already placed Vidu Q3 high in T2V (text-to-video) lists, though rankings vary by benchmark and dataset.
3. Native audio + video generation
Unlike systems that produce silent visuals and leave audio to postproduction, Vidu Q3 integrates audio generation within the model. The result is lip-synced dialogue, timed SFX, and optional background music produced alongside frames. Integrating sound at the model level reduces alignment errors (lip sync drift, off-beat cues) and shortens the production loop for demos, previews, and many finished-format short pieces.
4. Smart camera control & multi-shot narratives
Q3’s “smart camera” features interpret prompts for camera movements (pans, dolly, tracking) and multi-shot sequences. Instead of producing a single static viewpoint, the model can generate planned cuts and transitions so the resulting clip reads like a directed scene. For creators this changes output from ‘a single composed image that moves’ into ‘a short scene with multiple shots.’ That improves watchability and enables richer visual storytelling in a single generation.
5. Multi-reference consistency and character fidelity
Vidu (as a platform) has invested in “reference to video” and multi-reference consistency systems that allow creators to upload several reference images to lock character identity across frames. Q3 extends those ideas to keep character appearance and props consistent across multiple camera angles and cuts — a basic but essential requirement for coherent narrative output. This is especially useful for anime or stylized projects where maintaining consistent character art is critical.
6. Developer readiness: APIs and workflow
Vidu’s model suite—Q3 included—is available through web UIs and a programmatic REST API. Developers can submit text-to-video or image-plus-text jobs to an inference endpoint, receive a task ID, and poll for results (typical async job pattern). The API offers parameters such as resolution, aspect ratio, duration, movement amplitude, and a toggle for audio generation. That makes Q3 accessible for automation, batch workflows, and integration with editorial pipelines.
How Does Vidu Q3 Compare to Sora 2 and Veo 3.1?
Short answer: Vidu Q3 competes strongly on longer narrative outputs and integrated audio/video for 10–20s scenes, Sora 2 excels at physically plausible single-shot realism and social integration, and Veo 3.1 leads on pixel-level polish, multi-frame continuity tools, and enterprise API integration. Below we unpack the differences across practical axes.
Which model is stronger for realism and physics: Sora 2 or Vidu Q3?
Sora 2 (OpenAI) was explicitly trained for physical plausibility and world simulation — its public notes call out advanced physics behavior, accurate object interactions, and highly realistic motion trajectories. Sora 2 also provides synchronized audio and social app integrations (including cameos and a mobile app), making it exceptionally strong for lifelike, physically coherent scenes. If your brief demands accurate collision, realistic dynamics, or photorealistic human motion in short, self-contained shots, Sora 2 is often superior.
Vidu Q3, by contrast, is positioned more as a storytelling engine: longer clips, multi-shot sequencing, and director-style camera control. That doesn’t mean Vidu sacrifices realism, but its primary gains are narrative continuity and combined audiovisual output rather than raw physics simulation. For cinematic short storytelling (e.g., a 16s product demo with cuts and VO), Q3’s workflow is often faster and simpler.
Which model is better for cinematic polish and high fidelity: Veo 3.1 vs Vidu Q3?
Veo 3.1 (Google / DeepMind / Gemini) has been marketed as a high-fidelity, enterprise-grade option with strong continuity controls, native audio generation, and support inside Google’s cloud/Vertex/Gemini stacks. Veo 3.1 introduced advanced “ingredients to video” features, vertical (9:16) native support, and upscaling to high resolutions (including 4K capabilities in some flows). For projects that require the highest pixel quality, precise color harmony, and tight enterprise APIs, Veo 3.1 is often the go-to.
Vidu Q3 holds its own by focusing on extended duration + multi-shot story coherence and a creator-centric productization (fast web playgrounds, multi-reference orchestration). If your priority is producing a human-directed short scene with multiple camera moves and integrated audio cues (and you prize length above raw pixel polish), Vidu Q3 is compelling. For raw photoreal fidelity, Veo 3.1 typically has the edge.
As of early 2026, the AI video triumvirate consists of OpenAI’s Sora 2, Google’s Veo 3.1, and Vidu Q3. Here is how they stack up in a direct comparison:
| Feature | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Max Single Clip Duration | ~16 s | Up to ~25 s (Pro) | 8 s (with narrative stitching features) |
| Native Audio Generation | Yes (integrated) | Yes (experimental) | Yes (advanced) |
| Cinematic Camera Control | Yes (shot aware) | Limited presets | Yes (multi-shot consistency) |
| Multi-shot Narrative | Yes | Yes | Yes |
| Text Rendering in Frames | Yes | Varies | Varies |
| Resolution | 1080p | 1080p | 1080p / 4K in special cases |
| Primary Use Case | Narrative Storytelling, Animation | High-Budget Concept/Film | Youtube Shorts / TikTok |
Analysis:
- Vs. Sora 2: Sora 2 remains the heavyweight for pure visual fidelity and surrealist imagination ("Hollywood quality"). However, Vidu Q3 edges it out in workflow efficiency due to the 16-second limit and superior audio integration. For creators who need a "done-in-one" clip, Q3 is faster.
- Vs. Veo 3.1: Google's Veo 3.1 excels at speed for shorter, social-media-focused clips (4-8s) and integrates deeply with YouTube. Vidu Q3 aims higher up the value chain, targeting professional animators and filmmakers who need longer, continuous cuts that Veo struggles to maintain consistently.
What practical applications does Vidu Q3 enable?
Advertising and short-form marketing
Brands can prototype ad concepts end-to-end much faster: write a script, generate a 16-second visual with synchronized VO and SFX, iterate on wording and shot composition, and produce multiple language dubs by prompting language variants. For A/B testing social creatives, the reduced turnaround is a clear business win. Case studies released by platforms show marketers using Vidu Q3 for micro-ads and product teasers.
Storyboarding and previsualization for film and TV
Directors and editors are using short AI clips as previsualizations (previz) to block scenes, test camera moves, and pitch treatments. Vidu Q3’s multi-shot sequencing and smart camera controls are particularly useful here: creative teams can iterate on blocking and dialogue without the expense of location shoots. While AI previz doesn’t replace on-set direction, it shortens early-stage decision cycles.
E-learning and explainer videos
Education and corporate learning departments can generate concise animated explainer segments with synchronized narration and annotated SFX. For standardized content (product training, onboarding), this reduces dependency on expensive production houses and accelerates localized versions. The speed-to-publish and native audio capabilities make Vidu Q3 attractive for these use cases.
Gaming, concept art, and indie production
Indie developers and game teams use short AI cinematic clips for trailers, NPC dialog mockups, or style exploration. Vidu Q3’s support for reference images and character consistency helps keep a game IP’s visual identity coherent in prototype trailers. The model is also used for pitch materials to secure funding or publisher interest.
Accessibility and rapid localization
Because audio is generated natively, Vidu Q3 simplifies multi-language versions: generate the same shot with different language prompts, or ask for varied voice timbres. This enables quick localization of marketing content or training assets while maintaining lip-sync approximations good enough for many short-form contexts (though top-tier lip-match for broadcast may still require human adjustment).
Is Vidu Q3 the best AI video model in 2026?
Declaring a single “best” model misses nuance: the winner depends on the use case.
- For photorealistic, physically grounded output and conservative safety handling, OpenAI’s Sora 2 is frequently seen as the top choice. It emphasizes realism and robust moderation, making it attractive for high-end production and risk-averse enterprises.
- For platform-integrated, format-optimized short-form content, Veo 3.1’s native vertical outputs and Google’s app integrations (YouTube Shorts, Google Photos) make it uniquely convenient.
- For rapid audio-video prototyping, multi-shot narrative control, and a strong balance of storytelling features, Vidu Q3 is a standout—especially when iteration speed and integrated audio matter more than absolute photorealism. Early benchmarks and vendor reporting place Vidu Q3 high in T2V rankings, and its features make it a practical choice for marketers, independent creators, and studios prototyping new ideas.
Limitations and Considerations?
While Vidu Q3 marks a breakthrough, it has trade-offs:
- Clip duration is still capped (~16 s), so longer narratives need stitching or multiple prompts.
- Resource cost can scale with HD generation and complex audio.
- AI tools still require editorial judgment to refine and edit outputs into finished products.
So: Vidu Q3 is a top-tier contender in 2026, particularly for creators who prioritize native audio workflows and multi-shot storytelling. Whether it is the best depends on the precise production brief, regulatory constraints, and distribution pipeline of the user.
Conclusion
Vidu Q3 stands out in 2026 as a leading AI video model capable of producing narrative-ready, integrated audio-video clips that bridge creativity and production demands. Compared to Sora 2’s strong narrative cohesion and Veo 3.1’s cinematic realism, Vidu Q3 offers a balanced toolkit ideal for storytellers, content creators, and commercial workflows.
As benchmarks show its high performance and integrated features, Vidu Q3 represents a turning point in generative video AI — making complex audiovisual production more accessible and efficient.
Developers can access Vidu Q3, Veo 3.1 and Sora 2 via CometAPI, the latest models listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up fo Video generation today !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!