

作为一名 AI 创作者,我很高兴向你介绍 Nano Banana —— Gemini 2.5 Flash Image 的俏皮昵称 —— 这是 Google 最新的高保真图像生成与图像编辑模型。在这篇深度解析中,我将说明它是什么、如何在应用与 API 中使用、如何有效编写提示、提供具体示例、包含可直接运行的代码,并带你走过七个富有创意、切实可用的场景,你今天就可以开始实践。
什么是 Gemini 2.5 Flash Image(Nano Banana)?
Gemini 2.5 Flash Image 是 Gemini 系列中的一款全新图像生成与图像编辑模型。它将 Gemini 2.5 Flash 家族扩展到图像生成与编辑(不仅是文本),结合 Gemini 的多模态推理、世界知识以及基于提示的控制,从文本和/或图像输入创建或修改图像。团队与开发者文档明确称其为“Gemini 2.5 Flash Image”,并注明内部昵称为 nano-banana。
在发布时,Gemini 2.5 Flash Image 层的公布价格为每 100 万输出 token $30,并给出每张图像的示例成本为1290 个输出 token ≈ $0.039/张。该模型以预览形式提供(开发/预览 ID 如 gemini-2.5-flash-image-preview),并已通过部分合作伙伴(CometAPI)以及 Google 自有开发平台上线。
Gemini 2.5 Flash Image 的亮点功能有哪些?
跨编辑的角色与风格一致性
核心改进之一是“角色一致性”:模型明确调优以在多次编辑与不同场景中保持主体(人物、宠物或产品)视觉上的一致性——这一直是早期图像模型的弱项。这对需要统一品牌资产、连续叙事中的重复角色,或自动生成的多镜头产品摄影等流程有显著提升。
基于提示的局部化编辑
你可以提供一张图像加上一句自然语言指令,如“去除衬衫上的污渍”、“将服装改为蓝色夹克”,或“虚化背景并提升主体亮度”,模型会在很多情况下无需手动掩膜就执行目标、局部编辑。这让迭代式、对话式编辑变得实用。
多图融合与风格迁移
Gemini 2.5 Flash Image 可以接收多张图像并将它们“合成”到同一场景,或将某张图像的风格/质感迁移到另一张图像。这支持产品情景化(将产品置入场景)、家具摆设,或用于营销与电商的组合影像。
原生世界知识
由于构建于 Gemini 家族之上,模型能够利用世界知识——例如理解道具、环境或上下文合理的物体关系——这有助于构建更真实的场景与语义上连贯的编辑(不仅是美学上可行的输出)。
低延迟与成本效率
Gemini 的 “Flash” 家族面向低延迟与成本效率,相较更大的推理阶层更适合速度与价格/质量平衡的真实用例。开发者公告强调了其速度与有利的价格与质量权衡。
内置来源标识:SynthID 水印
用该模型创建/编辑的所有图像都包含不可见的 SynthID 数字水印,从而可以在后续验证图像是否由 AI 生成或编辑。这是 Google 在产品层面的来源追踪与滥用缓解措施之一。
1) 我如何为连载漫画或品牌活动创建一个一致的角色?
为什么有效
Nano Banana 明确经过训练,以在多次编辑与新场景中保持同一角色外观一致——当你需要在多个剧集、缩略图或主视觉中呈现相同的面孔、服装或吉祥物时,这非常有用。开发者称之为“角色一致性”。
如何编写提示
- 以一个描述性段落开场,捕捉身份特征(年龄范围、面部特征、可识别标记、服装元素)。
- 添加“一致性令牌”式的指令,例如“在所有输出中使用相同角色——不要改变可识别标记。”
- 对于多图输出,提供一张或多张参考图来锁定相貌。
如何为一致性编辑编写提示
- 先描述需要保持不变的核心身份属性:年龄、发色、明显特征(例如“左脸颊有一颗小痣”)与服装风格。
- 编辑时使用两段式提示:先描述必须保持一致的部分,再描述希望改变的部分。示例:“保持:28 岁东亚女性,黑色短波波头,左脸颊小痣。改变:置于 1970 年代风格的餐馆,穿红色皮夹克,微笑,暖色钨丝灯光。”
- 进行多步编辑时,在提示中加入一个小型参考符号,例如“(KEEP_ID: A)”,并在后续提示中重用它以指示同一主体。
示例提示
“创建一幅Amina的写实肖像:她是一位 28 岁的图像小说家,短不对称发型,左脸颊有月牙形胎记,温暖的棕色眼睛,穿绿色皮夹克。请在以下 6 个场景提示中保持 Amina 的可识别特征:‘Amina 在清晨咖啡店’,‘Amina 在公园素描’,……。在每个场景中使用相同的角色相貌。”
代码片段(Python,生成多张图像)
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
base_description = (
"Photorealistic portrait of Amina: 28yo graphic novelist, short asymmetrical haircut, "
"crescent mole on left cheek, warm brown eyes, green leather jacket. Keep likeness identical across scenes."
)
scenes = [
"Amina at a morning coffee shop, reading a sketchbook, warm golden hour light.",
"Amina sketching in the park, windy afternoon, soft bokeh background.",
# add more scenes...
]
for i, scene in enumerate(scenes, start=1):
prompt = f"{base_description} Scene: {scene}"
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=,
)
parts = response.candidates.content.parts
for part in parts:
if part.inline_data:
img = Image.open(BytesIO(part.inline_data.data))
img.save(f"amina_scene_{i}.png")
2) Nano Banana 如何加速电商产品摄影与 A/B 图像?
为什么富有创意且实用
产品团队在多镜头、布光与多变体(颜色、背景)上投入巨大。Nano Banana 的多图融合与精准的提示编辑让你快速生成一致的产品变体与生活化合成图——用于目录、生活场景与社交素材——显著减少迭代时间与制作成本。
如何为产品变体编写提示
- 提供简短的产品规格(尺寸、材质、色彩方案)与摄影风格(例如“工作室白底、45° 角度、柔和阴影”)。
- 针对变体:““为这款蓝牙耳机制作 4 个变体:黑色、粉色、灰色配橙色耳罩,以及灰色带蓝色高光——全部保持相同的灯光、相同的机位角度,并在白色房间中。”。”
- 使用多图融合将产品放入不同场景:“将这款背包置于野餐毯上,黄金时段,浅景深。”
示例提示(产品)
“图像 A(产品参考):高级皮革背包。创建三个白底目录变体——森林绿、棕褐、炭灰——以 45° 角拍摄,自然柔和阴影,ISO 感觉为 100。”
代码片段:Python 快速生成(目录变体)
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client(api_key="YOUR_API_KEY")
product_image = open("backpack_ref.png","rb").read()
prompt = ("Make 4 variations of this Bluetooth headset: black, pink, gray with orange ear caps, and gray with blue glint – all with the same lighting, same camera angle, and in a white room.")
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=,
)
# Save images from response parts (example)
for i, part in enumerate(response.candidates.content.parts):
if part.inline_data:
img = Image.open(BytesIO(part.inline_data.data))
img.save(f"backpack_variant_{i}.png")
该代码片段反映了 Google 文档中的使用模式,是将产品变体自动化的良好起点。
输出图像:

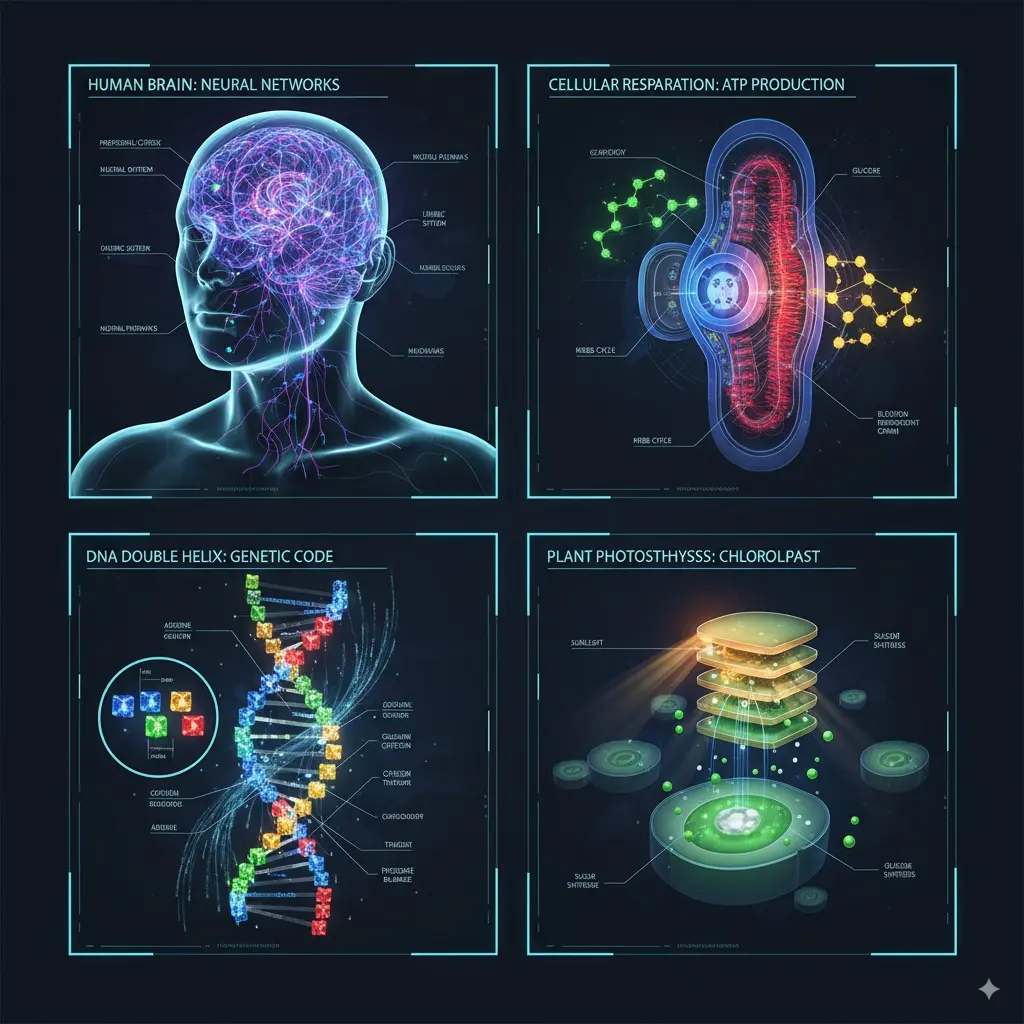
3) 我如何创建结合照片与示意图的教育插图?
为什么有效
Nano Banana 融合了 世界知识(Gemini 的多模态推理),可以解读手绘图、为图像加注释,或根据照片与文本指令生成解释性视觉——适用于在线教育、技术文档与交互式辅导。
如何编写提示
- 提供图像(例如某个物理实验的照片)以及类似“给该图添加标签与箭头解释关键组成部分,并创建第二张图展示系统的剖面”的提示。
示例提示
生成四组知识性图解说明:人脑的神经网络、细胞呼吸的 ATP 生成、DNA 双螺旋的遗传密码、叶绿体的植物光合作用
输出图像:
4) 我如何把真实照片转换为符合品牌的营销变体(服装、灯光、背景)?
为什么有效
该模型支持通过自然语言表达的目标化转换与局部编辑:更换服装、调整灯光、替换背景或移除物体——并尽量保持主体身份与整体真实感。这使快速生成营销变体(季节性服装、本地化场景)成为可能。
如何编写提示
- 将原始照片作为输入提供。
- 使用明确的目标编辑指令,例如:“将夹克替换为红色羊毛短呢大衣,将背景设置为黄昏时分的城市街景,并为主体增加暖色轮廓光。”
示例提示
“从上传的照片开始,将蓝色牛仔夹克替换为剪裁合体的红色羊毛短呢大衣,背景设置为傍晚城市街道并带有轻微散景,为主体加入柔和的轮廓光以与背景分离。”
提示
- 如果需要迭代控制,进行多轮编辑:先请求第一步编辑,再细化(“移除帽子”,“现在提升色温”)。
5) 动画创作与前期预览团队如何快速原型化场景与分镜?
为什么有用
导演与摄影指导可以快速原型化布光、服装与机位构图。Nano Banana 能输出角色一致的分镜,有助于规划与预览(pre-vis. ())。
H3:示例提示
There is a tree house in the forest at night with colorful lights hanging on the trees
输出图像:

6) Nano Banana 如何用于概念艺术、游戏资产与一致的游戏内角色?
为什么游戏工作室与独立开发者应关注
创建美术资产与迭代角色外观通常要求艺术家反复重绘。Nano Banana 的角色一致性让你能够生成大量姿势、服装与布光设置,同时忠实保持单一角色身份——在前期制作与快速原型阶段极大节省时间。
如何为游戏资产编写提示
- 用文本定义“规范”角色设定:身高、体型、关键特征、服装基配。
- 请求多输出:“生成三种战甲变体并保持相同面部特征,每种分别展示正面、侧面与四分之三视角。”
- 对于环境美术,使用多图融合:提供一张角色图与一张环境图,并提示进行融合。
示例提示(游戏资产)
“为‘Kael, the wind ranger’创建三种装甲变体:保持面部特征(窄下颌、右眉上方疤痕)。装甲 A:皮革 + 青色布料;装甲 B:鱼鳞甲 + 黄铜;装甲 C:隐蔽的哑黑。输出整身正面、侧面、四分之三视角。”

装甲 C:隐蔽哑黑

装甲 B:鱼鳞甲 + 黄铜

装甲 A:皮革 + 青色布料
7) 我如何用对话式多轮编辑来自动化照片修饰流程?
为什么有效
Nano Banana 支持对话式多轮图像编辑:你可以先提出一个编辑请求,查看结果,再用自然语言给出更多指令。这非常适合构建人机协同的修图流水线,让编辑者在多次处理过程中逐步引导模型。
如何实现该工作流
- 上传初始照片并请求基线修图(灯光、瑕疵去除)。
- 每一轮都将新编辑的图像与下一步指令一起发送回模型(“降低高光、提升阴影、裁剪为 4:5”)。
- 记录每一步,以便回退或将同样的处理批量应用。
迷你工作流片段(Python)
# 1) Initial retouch
prompt1 = "Remove small blemishes, even skin tone, slightly warm color grade"
response1 = client.models.generate_content(model="gemini-2.5-flash-image-preview", contents=)
# save response1 -> edited_v1.png
# 2) Follow-up tweak
prompt2 = "Crop to 4:5, increase local contrast on eyes, desaturate background slightly"
response2 = client.models.generate_content(model="gemini-2.5-flash-image-preview", contents=)
# save response2 -> edited_v2.png
我如何编写提示以获得 Nano Banana 的最佳效果?
应遵循哪些提示原则?
Nano Banana 对描述性、叙述风格的提示反应最佳,这类提示会解释场景、视角、灯光与氛围——而不仅是一串关键词。官方建议为写实风格提供相机、镜头、布光与风格线索;为插画提供风格与配色线索。同时明确给出约束(长宽比、背景、文字要求等)。
我如何构建一个强有力的提示?
以下是简短、可复用的模板:
- 写实模板:
A photorealistic of , , in , illuminated by , captured with , emphasizing . Aspect ratio: . - 风格迁移/合成模板:
Combine Image A (style) with Image B (subject). Transfer the color palette of A, keep subject proportions of B. Final style:.
提示工程技巧(速览)
- 使用一条清晰的叙述句,而不是许多零散标签。
- 为写实风格添加相机细节(例如“85mm,浅景深”)。
- 想在多次编辑中保持角色一致性,引用先前图像并指明希望保留的属性(例如“保留主体的雀斑与蓝色围巾,更改发型为……”)。
- 进行编辑时,上传源图像,并清楚描述需要更改的区域或元素。
- 使用迭代式、多轮编辑来微调细小视觉细节(Nano Banana 支持对话式细化)。
结语
Nano Banana(Gemini 2.5 Flash Image)是一次创意飞跃:它让创作者在保持角色与产品连续性的同时,实现大胆的新编辑、多图融合与快速迭代。用它来加速叙事、减少制作摩擦、并以速度原型化视觉——但也要以严格的审查与伦理边界相配套。
快速上手
CometAPI 是一个统一的 API 平台,聚合了 500+ 来自主流提供商的 AI 模型——例如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等——在一个对开发者友好的接口之下。通过提供一致的认证、请求格式与响应处理,CometAPI 大大简化了将 AI 能力集成到应用中的过程。无论你在构建聊天机器人、图像生成器、音乐创作,或数据驱动的分析管线,CometAPI 都能让你更快迭代、控制成本,并保持供应商无关性——同时紧跟 AI 生态的最新突破。
开发者可以通过 CometAPI 访问 Gemini 2.5 Flash Image(Nano Banana 在 CometAPI 列表中以 gemini-2.5-flash-image-preview/gemini-2.5-flash-image 形式列出)。最新模型版本以文章发布时为准。开始前,请在 Playground 中探索模型能力,并参考 API guide 获取详细说明。访问前请确保已登录 CometAPI 并获得 API key。CometAPI 提供远低于官方的价格,助你更快完成集成。