

Agentic coding——使用自主 AI 智能体来规划、编写、测试并迭代软件的实践——在 2024–2025 年间从研究演示走入了开发者的实际工作流。随着 2025 年 10 月 Claude Haiku 4.5 的发布,Anthropic 带来了一个专为“智能体式”工作负载优化的模型:快速、具成本效益,并针对子智能体编排与“计算机使用”任务(即驱动工具、编辑器、CLI)进行了调优。本指南整合了最新动态、能力说明、实用配方与治理最佳实践,帮助开发者与工程领导者在 2025 年负责任且高效地采用智能体式编码。
什么是“智能体式编码”(编排、子智能体)?
智能体式编码指的是一种 LLM 使用模式:模型不仅写代码,还会在更大的工作流中自主协调动作、调用工具、处理中间结果并管理子任务。实践中,这意味着模型可以充当“程序员智能体”,规划步骤序列、将工作委派给子智能体/工具,并消费它们的输出生成最终成果。Anthropic 与其他厂商正在明确构建模型与工具框架来支持这种风格。
编排 vs 子智能体
- 编排器(Orchestrator):一个控制器(可以是人类、像 Sonnet 4.5 这样的专用智能体模型,或一个轻薄程序),将复杂任务拆解为离散子任务,分派给子智能体,并将结果拼接起来。编排器维护全局状态并执行策略(安全、预算)。
- 子智能体(Subagents):小而专注的工作者(通常是像 Haiku 4.5 这样的轻量模型,或甚至是确定性的代码模块),负责单个子任务——例如摘要、实体抽取、编码、API 调用或输出校验。
将 Claude Haiku 4.5 作为子智能体(编码器),并以更强的推理模型作为编排器,是一种常见且具成本效益的设计:编排器负责规划,而 Haiku 负责快速且低成本地实现许多小而易并行的操作。
为什么现在重要
多个因素汇聚使智能体式编码在 2025 年变得切实可行:
- 为“计算机使用”调优的模型,在工具调用、测试与编排方面更可靠。
- 延迟与成本的改善,使得并行运行许多智能体实例成为可能。
- 工具生态(API、沙盒、CI/CD 集成)让智能体在可控、可观测的环境中运行。
Claude Haiku 4.5 明确定位于利用这些趋势,提供适合子智能体编排的速度、成本与编码能力平衡。
心智模型(常见模式): 规划者 → 工作者 → 评估者。规划者将目标拆分为任务;工作者子智能体执行任务(通常并行);评估者核验并接受或提出改进意见。
Claude Haiku 4.5 —— 开发者关注的更新
Anthropic 于 2025 年 10 月发布了 Claude Haiku 4.5,这是一款面向编码、计算机使用与智能体任务的高吞吐、具成本效益的模型。该版本重点提升速度与每 token 成本,同时保留强健的编码与多步推理表现——这是在包含大量短工具调用与循环的实际智能体工作流中至关重要的属性。Haiku 4.5 定位为 Anthropic 的 Haiku 阶梯中最经济的选项,同时在代码与智能体任务上匹配重要的任务级表现。模型已通过 API 提供,使开发者可以将其集成到 CI 系统、IDE 内工具与服务端编排器中。
基准与实际表现
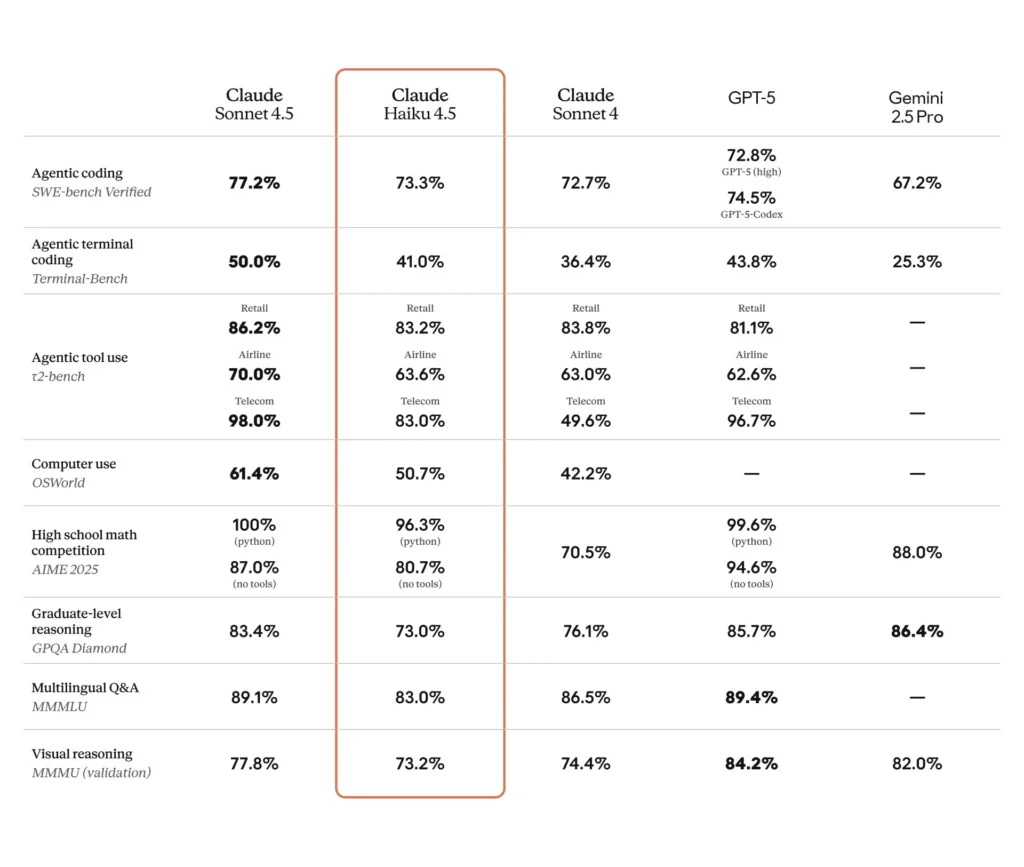
亮点指标包括:Claude Haiku 4.5 在诸如 SWE-bench Verified 的编码基准上取得了强劲成绩(据 Anthropic 材料报道约为 ~73.3%),并且在相较此前 Haiku 版本的“计算机使用”(工具驱动任务)上有明显提升。Claude Haiku 4.5 在许多开发者任务上可与 Sonnet 4 匹敌,同时提供吸引人且适合规模化智能体系统的成本/性能权衡。
支持智能体式编码的关键特性(Haiku 4.5)
为循环与工具调用调优的速度与成本画像:智能体循环通常包含大量短模型调用(规划 → 工具调用 → 评估 → 重新规划)。Haiku 4.5 强调吞吐与更低的 token 成本,让你可以更实惠地运行更多迭代。当你的编排器为测试、代码规范检查或构建实验分支而生成子智能体时,这一点尤为关键。
更强的短形式编码与“计算机使用”:Haiku 4.5 针对编码基准与模拟使用计算机的任务(运行 shell 命令、编辑文件、解释日志)进行了调优。这使其在自动化脚本中更可靠,LLM 可以读取输出、决定下一步并发出后续命令。利用这一能力来自动化分诊、脚手架与测试-修复循环。
API 与生态可用性:Haiku 4.5 可通过 API(例如 CometAPI)以及云合作伙伴(如 Vertex AI 与 Bedrock 上架)访问,从而简化与现有 CI/CD 流水线、容器化编排器与云服务的集成。稳定的编程接口减少脆弱的胶水代码,并允许一致的限流、重试与可观测性。
适配 Haiku 4.5 的多智能体编排模式
当 Haiku 4.5 是你的廉价且快速的工作者时,几个被验证的编排模式值得采用。
1)层级式编排(主/从)
如何工作: 高阶规划者(Sonnet) → 中层分发者(Haiku 编排器) → 工作者池(Haiku + 确定性代码)。一个能力更强的编排器(如 Sonnet 4.5)产出计划并将步骤分配给多个 Haiku 4.5 工作者。主控汇总结果并执行最终推理或验收检查。
适用场景: 复杂任务,需要偶尔的前沿推理(设计、策略决策),但包含大量常规执行。Anthropic 明确推荐这是高效模式。
2)任务农场 / 工作者池
如何工作: 一组同质的 Haiku 工作者从队列中拉取任务,独立运行。编排器监控进度并重分配失败的任务。
适用场景: 高吞吐工作负载,如批量文档摘要、数据集标注或在许多代码路径上运行单元测试。该模式利用 Haiku 的速度和低成本。
3)流水线(分段变换)
如何工作: 数据按顺序阶段流动——例如,摄取 → 归一化(Haiku) → 增强(外部工具) → 综合(Sonnet)。每一阶段都小且专门化。
适用场景: 多步 ETL 或内容生产,且不同阶段需要不同模型/工具最为理想。
4)MapReduce / MapMerge
如何工作: Map:许多 Haiku 工作者处理不同分片的输入。Reduce:编排器(或更强模型)进行合并与冲突解决。
适用场景: 大型语料分析、大规模问答或多文档综合。当你希望保留本地编码以供溯源,同时仅偶尔由更昂贵的模型计算全局摘要或排序时,这很有用。
5)评估循环(QA + 修订)
如何工作: Haiku 生成输出;另一个 Haiku 工作者或 Sonnet 评估者按检查清单进行核验。如果输出不达标则循环返工。
适用场景: 质量敏感任务,迭代式改进比仅使用前沿模型更划算。
系统架构:使用 Haiku 的务实“代理编码”设置
紧凑的参考架构(组件):
- API 网关 / 边缘层: 接收用户请求;执行鉴权/限流。
- 预处理器(Haiku): 清洗、规范化、提取结构化字段,并返回编码后的任务对象(JSON)——“代理编码”。
- 编排器(Sonnet / 更高模型或轻量规则引擎): 消费编码任务并决定生成哪些子任务,或是否由自身处理请求。
- 工作者池(Haiku 实例): 并行的 Haiku 智能体执行分配的子任务(搜索、摘要、代码生成、简单工具调用)。
- 评估者 / 质量门(Sonnet 或 Haiku): 验证输出并在必要时请求改进。
- 工具层: 到数据库、搜索、代码执行沙盒或外部 API 的连接器。
Haiku 4.5 改进的“子智能体编排”行为让其非常适合这种组合:其响应速度与成本画像允许并发运行多个工作者以并行探索多样实现。此设置将 Haiku 作为快速的代理编码器与执行工作者,在降低延迟与成本的同时,保留 Sonnet 用于重量级的规划/评估。
工具与计算考虑
- 沙盒化的计算机使用:为智能体提供受控的 shell 或容器化环境来运行测试和构建产物。限制网络访问,仅挂载必要的仓库。
- 溯源:每一个智能体动作都应产出带签名的日志与差异,以保持可解释性并支持回滚。
- 并行度:启动多个工作者可以增加覆盖率(不同实现),但需要编排器来调和相互冲突的补丁。
- 资源预算:将 Haiku 4.5 用于“内环”(快速迭代),如有必要,将更重的模型保留给最终代码评审或架构分析。
工具包装器与能力适配器
切勿将原始系统 API 直接暴露给模型提示。将工具封装成窄而明确的适配器,验证输入并净化输出。适配器职责示例:
- 验证命令是否属于允许的操作
- 强制资源/时间限制
- 将底层错误转换为结构化 JSON 供评估者使用
最小可运行示例 —— Python(异步)
下面是一个最小且实用的 Python 示例,展示层级式模式:Sonnet 作为规划者,Haiku 工作者作为执行者。它使用官方的 Anthropic Python SDK 进行消息调用(参见 SDK 文档)。将 ANTHROPIC_API_KEY 替换为你的环境变量。你也可以使用 CometAPI 的 API:Claude Haiku 4.5 API 与 Claude Sonnet 4.5 API。通过 CometAPI 调用 API 的价格比官方价格低 20%。通过 CometAPI 调用 API 的价格比官方价格低 20%。你只需将 Key 替换为你获取的 CometAPI KEY 即可调用。
注意:该示例为清晰起见有意使用小型且同步/异步混合的写法。在生产环境中你将添加健壮的错误处理、重试、机密管理以及任务队列(例如 Redis/RQ、Celery 或 AWS SQS)。
# minimal_haiku_orchestrator.py
# 依赖:pip install anthropic aiohttp asyncio
import os
import asyncio
from anthropic import AsyncAnthropic
ANTHROPIC_KEY = os.environ.get("ANTHROPIC_API_KEY")
if not ANTHROPIC_KEY:
raise RuntimeError("在环境变量中设置 ANTHROPIC_API_KEY")
# 模型名称(如果 Anthropic 更改具体 ID,请调整)
PLANNER_MODEL = "claude-sonnet-4-5-20250929" # 高能力规划者
WORKER_MODEL = "claude-haiku-4-5" # 快速、低成本的工作者
client = AsyncAnthropic(api_key=ANTHROPIC_KEY)
async def plan(user_request: str) -> list:
prompt = f"""You are a planner. 将用户请求拆分为一个有序的小型可执行步骤列表。
User request: \"\"\"{user_request}\"\"\"
返回包含步骤对象的 JSON 数组,字段为 "id" 与 "instruction"。"""
resp = await client.messages.create(
model=PLANNER_MODEL,
messages=,
max_tokens=800,
)
text = resp.content.strip()
# 朴素解析:规划者预期返回 JSON
import json
try:
steps = json.loads(text)
except Exception:
# 回退:如果规划者返回文本,则让 Haiku 重格式化
steps = [{"id": i+1, "instruction": line.strip()}
for i, line in enumerate(text.splitlines()) if line.strip()]
return steps
async def worker_execute(step):
# Haiku 高速工作者;返回包含结果与元数据的字典
system = f"You are a fast worker. 执行这条单一指令,并返回包含字段 id, output, status 的 JSON。"
prompt = f"指令:{step}\n返回包含字段:id, output, status 的 JSON"
resp = await client.messages.create(
model=WORKER_MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": prompt},
],
max_tokens=512,
)
# 解析单行 JSON,否则回退为原始文本
import json
txt = resp.content.strip()
try:
data = json.loads(txt)
except Exception:
data = {"id": step, "output": txt, "status": "ok"}
return data
async def evaluate_and_merge(results):
# 再次使用 Sonnet 进行最终综合/质量评估
combined = "\n\n".join(} -> {r.get('output','')}" for r in results])
prompt = f"给定如下部分结果,请产出简洁的最终答案,并在任一步骤失败时标注通过/失败。\n\n{combined}"
resp = await client.messages.create(
model=PLANNER_MODEL,
messages=,
max_tokens=600,
)
return resp.content.strip()
async def orchestrate(user_request: str):
steps = await plan(user_request)
# 并行运行工作者(建议限制并行度)
sem = asyncio.Semaphore(8) # 同时最多 8 个 Haiku 工作者
async def guarded(step):
async with sem:
return await worker_execute(step)
results = await asyncio.gather(*)
final = await evaluate_and_merge(results)
return final
if __name__ == "__main__":
import sys
req = " ".join(sys.argv) or "总结最新的设计文档并列出 5 个后续事项。"
out = asyncio.run(orchestrate(req))
print("最终输出:\n", out)
简要说明:
Sonnet 规划工作(JSON 步骤)。Haiku 并发执行各步骤。Sonnet 随后综合/验证结果。这是典型的“规划者→工作者→评估者”循环。代码使用 Anthropic 的 Python SDK(anthropic),其示例与异步客户端展示了相同的 messages.create 接口。
如何访问 Claude Haiku 4.5 API
CometAPI 是一个统一的 API 平台,将来自领先提供商的 500+ AI 模型——包括 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等——整合到单一、对开发者友好的接口中。通过提供一致的认证、请求格式与响应处理,CometAPI 大幅简化了将 AI 能力集成到你的应用中。无论你是在构建聊天机器人、图像生成器、音乐创作工具,还是数据驱动的分析流水线,CometAPI 都能让你更快迭代、控制成本并保持供应商无关性,同时利用整个 AI 生态的最新突破。
开发者可以通过 CometAPI 访问 Claude Haiku 4.5 API,最新模型版本 会与官网保持同步。开始之前,可在 Playground 探索模型能力,并查阅 API 指南 获取详细说明。访问前,请确保已登录 CometAPI 并获取 API Key。CometAPI 提供远低于官方价格的费用,帮助你完成集成。
准备好了吗?→ 立即注册 CometAPI!
如果你想了解更多提示、指南与 AI 新闻,关注我们的 VK、X 和 Discord!
结论
将 Claude Haiku 4.5 作为快速的代理编码器/工作者,可以解锁低延迟、具成本效益的多智能体系统。实用模式是让更高能力的模型进行编排与评估,而成千上万的 Haiku 工作者并行承担常规的重体力活。上面的最小 Python 示例可助你快速上手——将其适配到你的生产队列、监控与工具集,以构建稳健、安全、可扩展的智能体式流水线。