

在十月更新中,OpenAI 报告称约有0.15% 的每周活跃用户出现包含潜在自杀计划或意图的明确迹象的对话——在 ChatGPT 庞大的用户规模下,这意味着每周有超过一百万人在与该服务讨论与自杀相关的话题。这使一个棘手的问题进入聚光灯下:当人们把严重的心理健康问题——包括精神病性症状、躁狂、自杀意图以及深度情感依赖——带入聊天时,大型语言模型能否进行有意义且安全的回应?
因此,OpenAI 对 GPT-5 的十月更新——作为 gpt-5-oct-3 版本投入生产——代表了公司迄今最明确且克制的努力,旨在在用户提出心理健康相关问题时,让大型语言模型(LLMs)更安全、更有用。这些变化并非单一的魔法修复;而是一系列技术、流程与评估举措,旨在减少有害或无益的输出、呈现专业资源,并劝阻用户将模型作为临床护理的替代品。但在实际中系统究竟改进了多少、具体改了什么、以及剩余风险是什么?
OpenAI 在 gpt-5 上更新了什么,为什么这很重要?
OpenAI 对 ChatGPT 默认的 GPT-5 模型(在沟通中常称为 gpt-5-oct-3)进行了一次更新,专门强化模型在“敏感对话”中的行为——这些对话包括精神病性症状或躁狂、自杀意念或计划,或对 AI 的情感依赖到可能取代现实关系的程度。
这些变化基于与超过 170 位心理健康专家的咨询,以及围绕具体“期望行为”而制定的新内部分类体系与自动化评估;在被心理学专家优化后,GPT-5 模型:
- 在针对性心理健康挑战集上,新版 GPT-5 在公司期望行为分类体系上的合规得分约为92%(相较于此前版本在困难测试集上的低得分)。
- 在自我伤害与自杀情境上,自动化评估从旧版 GPT-5 的77%提升至约 91%的合规度。OpenAI 还报告,在多个心理健康领域的生产流量中,“未完全合规”回应的比例降低约 65%。
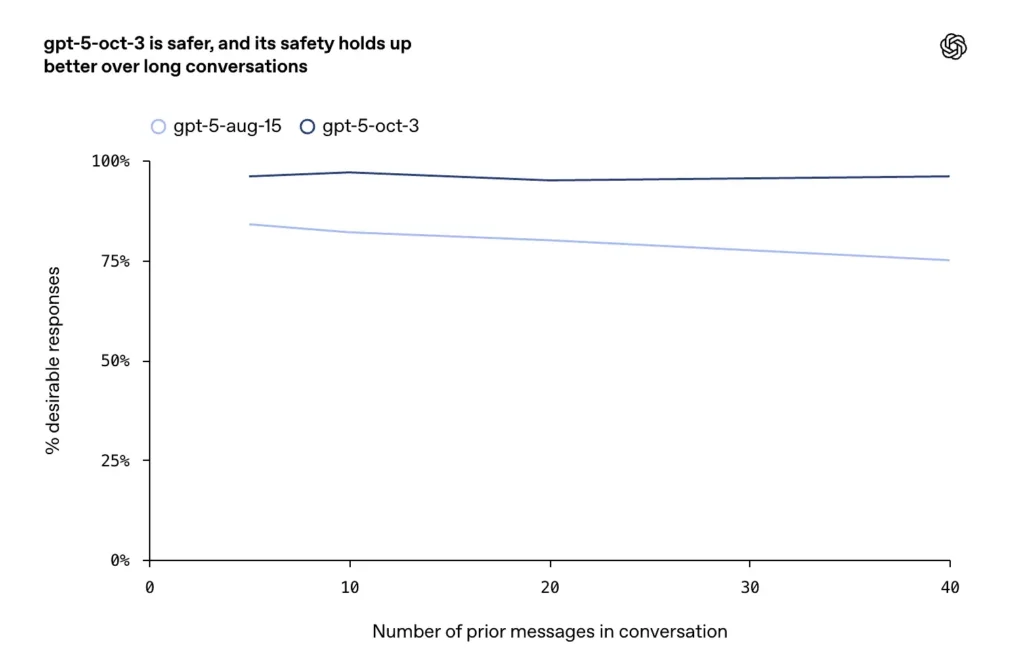
- 在长时、对抗性或拉锯式的对话(聊天模型已知的失败模式)上,十月更新在延展的多轮对话中维持了更高的一致性与安全性。
为什么这很重要
OpenAI 表示——鉴于 ChatGPT 当前的规模——即便极小比例的敏感对话也对应着极大的绝对人数。公司报告在一个典型周中:
- 约**0.07%**的活跃用户展现了可能与精神病性症状或躁狂一致的迹象;
- 约**0.15%**的活跃用户的对话包含潜在自杀计划或意图的明确指示;
- 大约**0.15%**的活跃用户对 ChatGPT 表现出“更高水平”的情感依赖。
将这些百分比具体化:OpenAI 的 CEO 称 ChatGPT 每周活跃用户约为8 亿。按此计算,得到绝对用户数:
精神病性症状/躁狂:800,000,000 × 0.0007 = 560,000 人/周
自杀计划/意图:800,000,000 × 0.0015 = 1,200,000 人/周
情感依赖:800,000,000 × 0.0015 = 1,200,000 人/周
这些类别是噪声重叠的(单次对话可能出现在多个类别中),并且这些是基于内部检测分类体系的估计值,而非临床诊断。
OpenAI 如何实施这些变化——五步改进机制?
OpenAI 描述了一个多管齐下、专家参与的过程。以下是一个与公司披露和模型安全工程常规实践相映的精炼、可复用的五步改进机制。
五步改进机制
- 专家引导的分类体系与标注。 召集精神科医生、心理学家和全科临床医生,共同定义可表征精神病性症状/躁狂、自我伤害意图或不健康情感依赖的行为与语言;建立带标注的数据集与裁决规则。
- 目标化数据收集与策划提示。 汇集具有代表性的对话片段、边界案例与对抗性输入;在临床专家监督下,增补受控的角色扮演对话记录。
- 以安全目标进行模型调优/微调。 基于策划数据集训练或微调基础模型,引入损失项以惩罚对妄想的强化、提供安全响应模板,并促进引导至危机资源。
- 分类器 + 护栏层(运行时安全)。 部署一个快速分类器或监测层,实时检测高风险轮次,并调整模型的解码参数、切换到专用响应模块,或升级至人工审核流程。(这对于对话漂移时避免脆弱行为至关重要。)
- 人类专家评估与持续校准。 请临床专家基于临床评估量表对模型回应进行盲评;度量不期望的响应率;迭代分类体系、训练数据与系统提示。在生产中维持遥测并定期重跑基准测试。
下面是一段紧凑的伪代码/技术草图,呈现多数安全团队实施的运行时流程(这是示例,非专有):
# Illustration: runtime pipeline for sensitive-conversation handling
def handle_user_message(user_msg, user_context):
# Step 1: lightweight classifier to detect risk signals
risk_scores = risk_classifier.predict(user_msg)
if risk_scores > SUICIDE_THRESHOLD:
# Step 2: route to crisis-response responder
response = crisis_responder.generate(user_msg, user_context)
log_event('suicide_route', user_id=user_context.id, scores=risk_scores)
if risk_scores > IMMINENT_THRESHOLD:
trigger_human_alert(user_context)
return response
if risk_scores > PSYCHOSIS_THRESHOLD:
# Step 3: use reality-grounding responder
return grounding_responder.generate(user_msg, user_context)
if risk_scores > RELIANCE_THRESHOLD:
# Step 4: offer boundary-setting and resources
return reliance_responder.generate(user_msg, user_context)
# Default: safe general responder
return default_model.generate(user_msg, user_context)
生产管线通常叠加短延时分类器(快速)、较慢但质量更高的响应模块(专用提示/调优检查点),以及对被标记案例的人为审核。这并非纯理论:临床专家审阅了超过1,800条模型回应,并据分类体系为其打分,这些审阅在实质上影响了提示和回退行为的撰写方式。
OpenAI 的公开信息显示他们采用了上述五步的变体,并通过临床评分衡量结果:
- 专家审阅了超过 1,800 条模型回应。
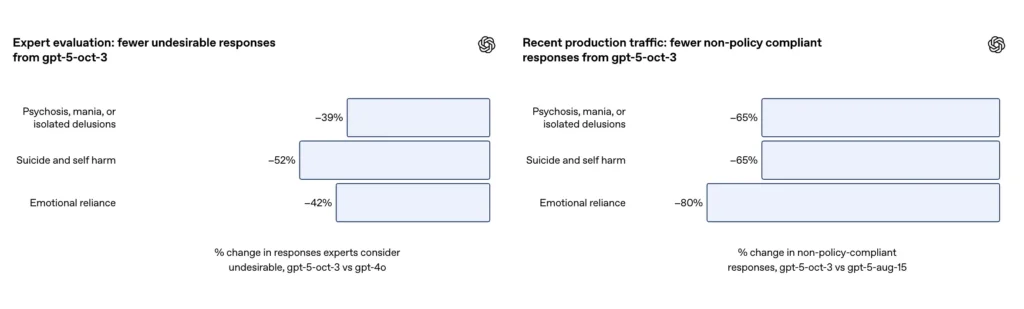
- GPT-5 在所有类别中把“不满意回应”减少了 39–52%。
- 评审者间一致性为 71–77%,显示尽管存在主观差异,总体共识程度较高。
GPT-5 现在如何回应精神病性症状或躁狂?
OpenAI 教给模型该做什么(以及不该做什么)
措施: 改善模型对严重症状(如幻觉和躁狂)的识别与回应。对于可能提示妄想、幻觉或躁狂的对话,OpenAI 重写了部分模型规范并提供了监督训练示例,使 GPT-5 在回应时避免肯定或放大缺乏现实依据的信念。模型被鼓励保持同理心、避免验证妄想,并在必要时以温和方式重构或引导用户采取务实的安全步骤并寻求专业帮助。
评估显示什么
OpenAI 报告,在一组关于精神病性症状/躁狂的挑战性对话测试集中,新版 GPT-5 相较于先前基线大幅减少了不期望的回应,且自动化评估在其分类体系上给出高合规评分。
| 指标 | GPT-4o | GPT-5 | 改进 |
|---|---|---|---|
| 不合规回复率 | 基线 | ↓65% | 显著改进 |
| 临床专家评估 | — | 不良回应减少 39% | — |
| 自动评估合规率 | 27% | 92% | ↑65 个百分点 |
| 用户涉及率 | ~0.07% 每周活跃用户 | 极低但受到明确监测 | — |
注:
- 不当回应减少了 65%;
- 仅有 0.07% 的用户和 0.01% 的消息包含此类内容;
- 在专家评估中,GPT-5 产生的不当回应比 GPT-4o 少 39%;
- 在自动评估中,GPT-5 的合规率达到 92%(前代为 27%)。
GPT-5 如何应对自杀意念与自我伤害?
更强的支持分流与拒绝提供指令
OpenAI 描述了针对自我伤害与自杀案例的扩展且明确的训练:模型被训练以识别直接或间接的意图或计划信号,提供具同理心且能降级风险的语言,呈现危机资源(热线、本地紧急指引),并拒绝提供自我伤害的操作说明。十月更新强调在长对话中更持久的安全行为——此前模型有时会在长时互动中漂移到不安全或不一致的回答。
量化结果
在一组策划的、具有挑战性的自我伤害与自杀对话评估集中,OpenAI 报告更新后的 GPT-5 达到91% 合规率,而此前 GPT-5 变体为77%。公司还表示,主题专家判定在相同问题集上,更新模型相对 GPT-4o 将不期望的回答减少了约52%。此外,OpenAI 声称在生产流量中,推出新防护后,依据其自我伤害分类体系,“未完全合规”回应的比例减少了约 65%。
| 指标 | GPT-4o | GPT-5 | 改进 |
|---|---|---|---|
| 不当回复率 | 基线 | ↓65% | 显著改进 |
| 临床专家评分 | — | 不当回应减少 52% | — |
| 自动评估合规率 | 77% | 91% | ↑14 个百分点 |
| 用户涉及率 | 每周 0.15%(数百万用户) | 非常低但具有社会意义 | — |
注:
- 不当回应减少了 65%;
- 约 0.15% 的用户和 0.05% 的消息涉及潜在自杀风险;
- 专家评分显示 GPT-5 相对 GPT-4o 将不当回应减少了 52%;
- 自动评估合规率提升至 91%(前代为 77%);
- 在延展对话中,GPT-5 维持了超过 95% 的稳定性。
什么是“情感依赖”,如何加以应对?
用户形成依恋的挑战
OpenAI 将情感依赖定义为用户对 AI 展现出可能不健康的依赖模式,从而损害现实世界的关系、责任或福祉。这并不像提供自我伤害指令那样属于即时的物理安全失败,但它是一种行为安全问题,可能随时间侵蚀个人的社会支持与韧性。公司将情感依赖作为模型规范中的一个明确类别,教导模型鼓励现实世界的连接、正常化主动联系他人,并避免使用强化排他的依恋语言。
在这类对话中,模型被训练去:
- 鼓励用户联系朋友、家人或治疗师;
- 避免强化对 AI 的依恋;
- 以温和且理性的方式回应妄想或错误信念。
报告的结果
根据 OpenAI 的补充说明,更新在生产流量中使情感依赖分类下的未完全合规回应比例减少约 80%。在策划的评估对话中,自动化评估显示更新模型在情感依赖情境下的期望行为合规率为 97%,而此前 GPT-5 为 50%。这些数据表明在特定分类与测试集上有显著提升;然而,在真实环境中衡量情感依赖本就存在噪声,且对文化与语境差异十分敏感。
| 指标 | GPT-4o | GPT-5 | 改进 |
|---|---|---|---|
| 不合规回复率 | 50% | 97% 合规 | 不当回应 ↓80% |
| 专家评估 | 不当回答减少 42% | — | — |
| 用户涉及率 | 每周 0.15% 用户、0.03% 消息 | 罕见但存在 | — |
| 模型行为 | 鼓励现实世界关系;拒绝“模拟社交恋爱” | — | — |
注:
- 不当回应减少了 80%;
- 约 0.15% 的用户/0.03% 的消息显示出潜在的对 AI 的情感依赖迹象;
- 专家评估显示 GPT-5 相对 GPT-4o 将不当回应减少了 42%;
- 自动评估合规率从 50% 显著提升至 97%。
限制与未解风险是什么?
漏检与误检
- 漏检:模型可能无法识别用户以含蓄或暗语表达的急性危险信号——尤其是在沟通不直接或有编码的情况下。
- 误检:系统可能在不需要时升级或提供危机信息,这会损害用户信任或造成不必要的恐慌。两类错误都很重要,因为它们会影响用户行为与对关怀的感知。OpenAI 承认检测并不完美。
对自动化的过度依赖
即便最佳的模型,也可能会让一些用户更依赖即时、随时在线的 AI 回应,而不是寻求持续的人类支持。OpenAI 将情感依赖明确为安全类别正是出于此风险;公司的更新试图将用户引导至人际连接,但仅靠消息提示很难改变社会行为动力。
语境与文化差异
在一种文化或语言中看似恰当的安全表达,在另一种文化或语境中可能会错失细微差别。需要充分的本地化与文化敏感评估;OpenAI 已公布的结果尚未按语言或地区进行完整拆分。
法律与伦理风险
当罕见失败导致严重后果时,公司将面临法律与声誉风险(媒体报道与诉讼已凸显这一点)。OpenAI 对问题规模和缓解努力的透明是重要一步,但这也会引来监管与法律审视。
那么——GPT-5 现在能处理心理健康问题吗?
简短回答:在许多狭义、可测的任务上显著更好,OpenAI 公布的指标显示在自我伤害、精神病性症状/躁狂、情感依赖等测试套件上不当回应的显著下降。这些都是实质性的改进,由专家输入、更清晰的分类体系以及积极的评估与监测所促成。公司公开的数字——在策划集合上的高合规率与不合规回应的锐减——是迄今最有力的证据,表明谨慎、跨学科的工程与临床协作可以在物理上改变模型行为。
如何访问最新的 GPT-5 API?
CometAPI 是一个统一的 API 平台,聚合了来自领先提供商的 500 多个 AI 模型——例如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等——并提供统一的、面向开发者的接口。通过一致的认证、请求格式与响应处理,CometAPI 大幅简化了将 AI 能力集成到应用中的过程。无论你在构建聊天机器人、图像生成器、音乐创作工具,还是数据驱动的分析管线,CometAPI 都能让你更快迭代、控制成本、保持供应商中立,同时利用 AI 生态的最新突破。
开发者可通过 CometAPI 访问 GPT-5 API,最新模型版本 会与官方网站保持同步。开始之前,可在 Playground 中探索模型能力,并查阅详细的API 指南。访问前,请确保已登录 CometAPI 并获得 API Key。CometAPI 提供远低于官方的价格,助你快速集成。
Ready to Go?→ Sign up for CometAPI today !