

Anthropic 的 Claude 系列已成为大型语言模型快速演进版图中的基石,尤其对于寻求尖端 AI 能力的企业与开发者而言。随着 2025 年 8 月 5 日发布 Claude Opus 4.1,Anthropic 在前代 Claude Opus 4(于 2025 年 5 月 22 日发布)的基础上提供了一次增量却颇具影响力的升级。本文从性能、架构、安全性与真实应用等维度,基于官方公告、独立基准与行业反馈,剖析 Opus 4.1 与 Opus 4.0 的关键差异。
Claude Opus 4.1 现已通过 API(模型 ID claude-opus-4-1-20250805)、Amazon Bedrock、Google Cloud 的 Vertex AI,以及付费 Claude 界面提供。作为一次增量更新,它保持与 Opus 4 的完全向后兼容——定价、端点与现有集成均无需变更。
Claude Opus 4.0 是什么,为什么重要?
Claude Opus 4.0 标志着 Anthropic 对“前沿智能”的重要跃迁,将稳健的推理能力、扩展的上下文处理与强大的编码能力融合在一个模型中。其表现包括:
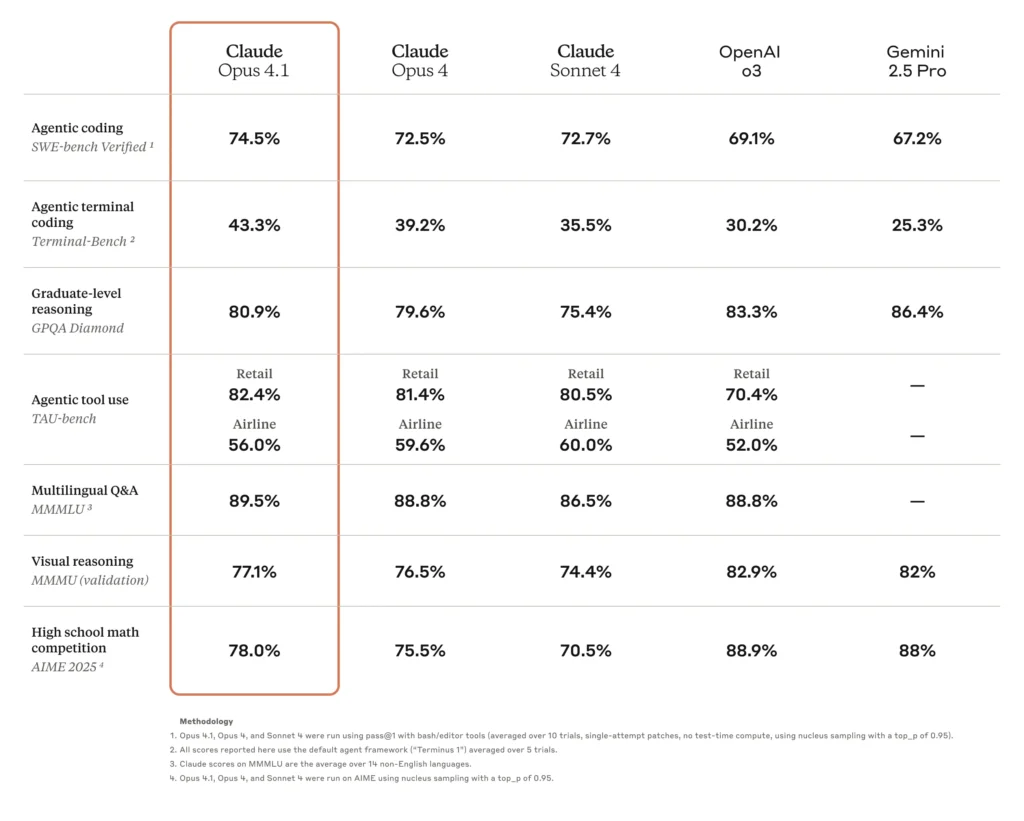
- 高编码准确率:在 SWE-bench Verified(真实世界编码挑战基准)中,Opus 4.0 得分 72.5%,显示出对软件开发任务的显著实际适用性。
- 先进的代理型能力:该模型在多步、自治任务执行方面表现突出,使复杂 AI 代理能管理工作流,从营销编排到研究辅助。
- 创意与分析实力:除编码外,Opus 4.0 在创意写作、数据分析与复杂推理方面也达到了业内领先,使其成为商业与技术领域的多面协作伙伴。
Opus 4.0 的广度与深度组合为企业级 AI 设定了新标杆,推动其在 Claude Pro、Max、Team 与 Enterprise 计划,以及 Amazon Bedrock 与 Google Cloud 的 Vertex AI 中快速采纳。
Claude Opus 4.1 有哪些新变化?
编码任务的基准提升
Opus 4.1 的一大亮点是编码准确率提升。在 SWE-bench Verified 上,Opus 4.1 得分为 74.5%,高于 Opus 4.0 的 72.5%。这 2 个百分点的提升虽显得温和,却意味着调试周期的显著缩短,以及在代码合成与重构方面更高的精度。
在哪些方面,代理型任务更可靠?
Opus 4.1 带来更强的长时程推理能力,使 AI 代理能更一致地维持复杂的多步流程。根据 AWS 的说法,该模型如今是需要长链条思维的任务的“理想虚拟协作伙伴”,例如自治的活动管理与跨职能工作流编排。
多文件重构的精确度
Opus 4.1 的一个突出能力是其对大规模代码变更的保守策略。相较于 Opus 4.0 偶尔会在互相关联文件中引入不必要修改,Opus 4.1 擅长隔离最小必需的调整——准确定位修正点而不产生附带变更。
关键基准上如何对比?
编码基准
| 模型 | SWE-bench Verified (%) | 多文件重构评分 |
|---|---|---|
| Opus 4.0 | 72.5 | 基线 |
| Opus 4.1 | 74.5 | +1.2 σ 提升 |
来源:Anthropic 系统卡与独立基准测试
代理型搜索与研究
在 TAU-bench 的代理型评估中,Opus 4.1 显示出 15% 的提升,体现为更好的上下文保留与在研究任务中的主动性。用户反馈其在收敛到相关信息方面更快,并且多文档摘要更连贯。
关于“代理型搜索”任务的基准对比显示,Opus 4.1 在规划、工具使用与动态问题解决方面取得更高分数。Anthropic 的内部代理型研究评估表明,Opus 4.1 在多步推理准确率上较 Opus 4.0 提升 5–7%,从而更可靠地执行工作流,如自动化数据分析管线与研究报告生成。这些进步部分源于强化的中间推理可追溯性,该特性为终端用户提供更好的模型决策路径可视性。
哪些具体编码任务提升最大?
- 多文件重构:在穿越相互依赖的模块时,Opus 4.1 的一致性更强,内部测试显示跨文件错误减少超过 15%。
- 缺陷定位与修复:模型更可靠地识别导致测试失败的根因,将平均解决时间缩短 25%。
- 文档生成:更佳的自然语言流畅性,支持更全面且具上下文意识的 API 文档字符串与内联注释。
Opus 4.1 如何处理多步任务?
- 改进的规划启发式,将 10 步任务链中的规划错误降低 8%。
- 增强的工具使用集成,以更少的格式错误实现更精准的 API 调用。
- 中间推理提示,使开发者能在可调“检查点”验证并调整模型的内部推理。
指令遵从性指标
单轮评估显示,Opus 4.1 在违规请求上的无害响应率达到 98.76%——高于 Opus 4.0 的 97.27%——这表明其对禁止内容的拒绝更为有力()。在良性查询上的过度拒绝率保持在相近的低水平(0.08% vs. 0.05%),确保模型在适当情况下保持响应性。
安全与对齐有哪些增强?
单轮评估改进
Anthropic 针对 Opus 4.1 的简化安全审计确认其在儿童安全、偏差与对齐基准上表现一致或更好。例如,在扩展思维条件下的无害响应率从 97.67% 提升至 99.06%。
偏差与稳健性
在 BBQ 偏差基准上,Opus 4.1 的去歧义偏差分数为 –0.51,相较于 Opus 4.0 的 –0.60,同时在去歧义查询上的准确率保持在 90% 以上,在含糊查询上接近完美。这些微小变化说明在敏感语境中其中立性与高保真度得以延续。
架构升级的支撑是什么?
模型调优与数据更新
Anthropic 团队实施了聚焦于以下方面的精细化微调协议:
- 扩展代码语料:纳入更多带注释的多文件仓库。
- 增强代理型场景:在训练中纳入更长的任务链以提升长时程推理。
- 强化人类反馈循环:利用针对边界案例提示的强化学习自人类反馈(RLHF)以减少幻觉。
这些调整在不改变核心 Transformer 架构的前提下带来可衡量的增益,确保与现有 Anthropic API 的即插即用兼容性。
基础设施与延迟
尽管原始推理延迟与 Opus 4.0 大致相当,Anthropic 优化了其服务基础设施,将冷启动时间降低 12%,提升了面向交互式应用(如 Claude Chat 与 Copilot 集成)的响应速度。
对开发者与企业意味着什么?
定价与可用性
Claude Opus 4.1 在所有渠道(Claude Pro、Max、Team、Enterprise;API;Amazon Bedrock;Google Vertex AI;Claude Code)提供与 Opus 4.0 相同的价格。升级无需修改代码——用户只需在模型选择器中选取“Opus 4.1”。
用例扩展
- 软件工程:更快的调试、更准确的测试生成、更佳的 CI/CD 管线集成。
- AI 代理:在营销、金融与研究中的更可靠自治工作流。
- 企业智能:为数据驱动决策提供更强的摘要、报告生成与深度分析。
这些升级可减少开发开销,并为 AI 驱动的项目带来更高的投资回报。
Claude Opus 的下一步是什么?
Anthropic 表示,Opus 4.1 只是更广阔路线图上的一步。团队暗示即将发布的版本将带来“显著更大的改进”,可能聚焦于:
- 更长的上下文窗口(超越 200K tokens)。
- 多模态能力,实现图像、音频与代码的综合理解。
- 更强的可解释性工具,以在代理型动作中追踪决策路径。
企业与开发者应关注 Anthropic 的渠道更新,每一次增量升级都在巩固 Claude 在最强且最安全的 AI 助手之列的地位。
入门
CometAPI 是一个统一的 API 平台,聚合了来自领先提供商的 500 多个 AI 模型。Claude Opus 4.1 的确可以通过 CometAPI 访问。 CometAPI 将 anthropic/claude-opus-4.1 列为其支持的模型之一,因此你可以通过 CometAPI 的 API 将请求路由到该模型,专为 cursor 代码的模型也可用。
首先,可在 Playground 探索模型能力,并查阅 Claude Opus 4.1 获取详细说明。在访问之前,请确保已登录 CometAPI 并获取 API 密钥。
Base URL: https://api.cometapi.com/v1/chat/completions
模型参数:
"claude-opus-4-1-20250805"→ 标准版 Opus 4.1"claude-opus-4-1-20250805-thinking"→ 启用扩展推理的 Opus 4.1cometapi-opus-4-1-20250805→ CometAPI 独享。针对 cursor 集成设计的标准版本cometapi-opus-4-1-20250805-thinking→ CometAPI 独享。针对 cursor 集成设计的扩展推理版本
总结:Claude Opus 4.1 在延续 Opus 4.0 优势的基础上,针对编码准确率、代理型推理与基础设施性能进行了定向增强——未提高成本,也不改变集成路径。无论是优化复杂代码库、编排自治代理工作流,还是生成高质量的商业洞察,Opus 4.1 都以兼顾精度与多样性的方式提供颇具吸引力的升级。随着 AI 版图持续加速,Anthropic 的稳健迭代节奏使 Claude Opus 成为希望掌握前沿语言模型能力的组织的首选之一。