

Anthropic 的全新 Claude 4 系列 —— Claude Opus 4 与 Claude Sonnet 4 —— 于 2025 年 5 月发布,作为面向高级推理与编码优化的下一代 AI 助手。Opus 4 被 Anthropic 描述为其*“迄今最强大的模型”*,在复杂的多步骤编码与推理任务中表现卓越。Sonnet 4 则是对先前 Sonnet 3.7 的高性能升级,具备强大的通用推理、精确的指令跟随能力,以及具有竞争力的编码水平。
下文将从对开发者重要的关键技术维度比较这些模型:推理与编码表现、延迟与效率、代码生成质量、透明性、工具使用、集成、成本/性能、安全性与部署用例。分析参考了 Anthropic 的发布与文档、独立基准测试以及行业报告,力求提供全面且最新的视角。
Claude Opus 4 和 Claude Sonnet 4 是什么?
Claude Opus 4 和 Claude Sonnet 4 是 Anthropic 的 Claude 4 家族最新成员,被设计为融合内部链式思考与动态工具调用的混合推理语言模型。两款模型具备两项关键创新:
- Thinking Summaries:模型自动生成其推理步骤的概览,提高透明度,帮助开发者理解决策路径。
- Extended Thinking(测试版):一种在内部推理与外部工具调用(如网页搜索或代码执行)之间取得平衡的模式,以在更长、更复杂的工作流程中优化任务表现。
起源与定位
- Claude Opus 4 被定位为 Anthropic 的旗舰推理引擎。它可持续自主执行任务长达七小时,并在经基准评测的编码与工具使用任务上优于其他大型模型(包括 Google 的 Gemini 2.5 Pro、OpenAI 的 o3 reasoning model 和 GPT-4.1)。
- Claude Sonnet 4 作为性价比突出的通用型“主力”,继任 Claude Sonnet 3.7。相较前代,它在指令跟随、工具选择与错误更正方面更为出色,同时保持了面向客户代理与 AI 工作流的高吞吐量。
可用性与定价
- API 与云平台:两款模型均可通过 Anthropic API 使用,并已上架主要云市场 —— Amazon Bedrock、Google Cloud Vertex AI、Databricks、Snowflake Cortex AI 与 GitHub Copilot。
- 免费 vs. 付费层:免费层用户可使用 Claude Sonnet 4,而 Claude Opus 4 与 extended-thinking 功能需要付费订阅。
Opus 4 与 Sonnet 4 的核心能力如何对比?
尽管两者共享底层架构与安全基石,但其调优与性能范围针对不同用例而定制。
编码与开发工作流
Claude Opus 4 为 AI 驱动的软件工程设定了新标杆,在 SWE-bench(72.5%)与 Terminal-bench(43.2%)等行业基准中取得顶级成绩,并可在持续数日的重构流水线中保持自主代码生成。其对 32K+ token 上下文与后台任务执行(“Claude Code”)的支持,让开发者可将复杂的多文件编辑与迭代调试交给模型处理。相比之下,Claude Sonnet 4 虽未达到 Opus 4 的绝对峰值表现,但在面向开发者的工作流中平均较 Sonnet 3.7 提升 20%,并在快速原型、代码评审与交互式聊天式辅助方面表现突出。
推理、记忆与规划
两款模型都引入了扩展记忆窗口,可在长达七小时的会话中保留上下文,对于需要持续对话或长时间自主流程的应用是一次突破。它们的 “thinking summaries” 功能会呈现内部链式思考的简明概览,提升复杂决策路径的透明度。Opus 4 的摘要更为细致,适合研究级分析;而 Sonnet 4 的摘要更精炼,优先保证清晰度与速度,以服务于客服机器人与高并发聊天界面。
安全与伦理考量
鉴于 Claude Opus 4 的强大能力 —— 已展现出引导可能带来生物安全风险的多步骤任务的潜力 —— Anthropic 依据其 Responsible Scaling Policy 将其评定为 AI Safety Level 3(ASL-3),并实施了反越狱分类器、网络安全加固以及面向外部的漏洞悬赏计划。Sonnet 4 虽同样采用了稳健的过滤与红队测试协议,但评级为 ASL-2,反映其更低的风险画像,与其较少自主性的使用场景相匹配。Anthropic 的自愿自我监管旨在表明:严谨的安全实践并不必然阻碍商业落地。
性能基准
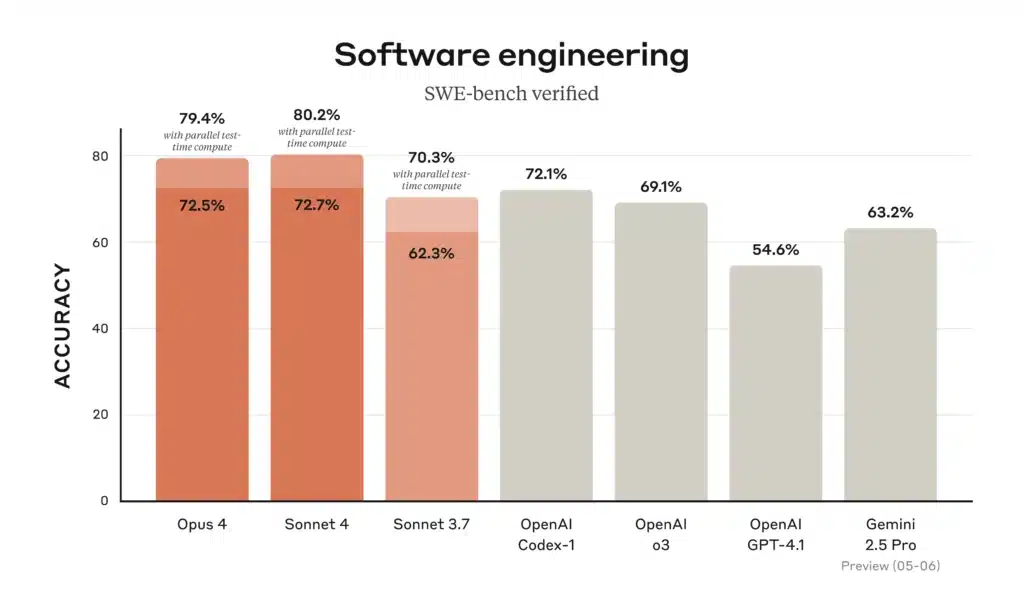
(图:Claude 4 模型相较既有模型的软件工程(SWE-bench Verified)准确率,数值越高越好。)Opus 4 与 Sonnet 4 均名列标准基准前茅。在 Anthropic 的 SWE-bench(软件工程) 测试中,Opus 4 约为 72.5%,Sonnet 4 约为 72.7%(远高于 Claude Sonnet 3.7 的约 62%)。上图(来自 Anthropic)显示,两款新模型(橙色柱)都优于先前的 Claude 版本,甚至在真实编码任务上超过 GPT-4.1。
- 编码(SWE-bench): Opus 4 = 72.5%;Sonnet 4 = 72.7%。二者均显著超越旧模型(Sonnet 3.7 = 62.3%,GPT-4.1 ≈54.6%)。这也印证了 Anthropic 的说法:两款 Claude 4 模型在编码基准上领先。
- 研究生级推理(GPQA Diamond): Anthropic 报告显示,Opus 4 为 74.9%,Sonnet 4 为 70.0%。这是一个面向复杂科学推理的内部基准;Opus 略占优势。
- 知识(MMLU): Opus 4:87.4%;Sonnet 4:85.4%。同样是 Opus 略高,但两者成绩都很强(Anthropic 指出 Sonnet 4 在 MMLU 上“相较 3.7 有显著提升”)。
- 独立编码测试: 在公开评测中,两款模型表现都非常出色。例如,在一次 Next.js 编码任务的第三方测试中,Opus 4 得分 9.5/10,Sonnet 4 得分 9.25/10(在该挑战上与 GPT-4.1 持平或更高)。两者都比其他 LLM 更稳定地产出简洁且正确的代码。
- 其他基准: 在高中数学竞赛(AIME)上,两者得分均偏低(约 33%,这在 LLM 中较为普遍)。对于工具使用与代理任务(TAU-bench 的多个变体),Anthropic 报告两款模型在部分子任务上取得了很强的成绩(>80%)。总之,Opus 4 往往在高难基准上略胜一筹,但 Sonnet 4 仍极为强大;通常两者的权衡在于成本与速度。
总体而言,Claude Opus 4 是顶级型号(适合对性能要求极高的任务),而 Claude Sonnet 4 则以更高的效率提供几乎同等的能力。二者的定价与可用性也体现了这种差异:Sonnet 4 适合规模化应用(亦向免费用户开放),而 Opus 4 则面向需要“榨干每一分性能”的团队。
定价
Token 成本(API): Opus 4 的价格为每百万输入 token 15 美元、每百万输出 token 75 美元;而 Sonnet 4 仅为 3/15 美元(输入/输出)。这些费率与 Anthropic 先前的 Claude v4 定价一致。
折扣: Anthropic 为 Opus 4 提供大幅折扣:提示缓存可将 token 成本最多降低 90%,批处理最多降低 50%。(即使没有这些功能,Sonnet 4 较低的基础成本也更便宜。)
订阅包含: Sonnet 4 在 Claude 的免费计划中即包含,而 Opus 4 需要付费的 Claude Pro/Team/Enterprise 订阅。实践中,这意味着 Sonnet 4(无论在 Claude Chat 还是 API)成本非常低,而 Opus 4 仅对付费客户开放。
在用例中,Sonnet 4 与 Claude Opus 4 有何差异?
虽然 Opus 4 是追求峰值性能的旗舰型号,Sonnet 4 则在实用性与易用性上占据一席之地。
性能与实用性
- 原始能力:在正面对比的基准中,Opus 4 在复杂推理、代码生成准确性与持续的多步骤工作流方面优于 Sonnet 4,体现其“同类最佳”的定位。
- 效率:Sonnet 4 以大约 Opus 4 80% 的性能、约一半的算力成本交付结果,对日常任务与预算敏感项目很有吸引力。
用例场景
| 用例 | Claude Sonnet 4 | Claude Opus 4 |
|---|---|---|
| 日常编码 | ✔️ 速度与准确性均衡 | ✔️ 最高准确性 |
| 研究与科学类 AI | ✔️ 适合摘要与原型 | ✔️ 更强的深度推理 |
| 自主代理型工作流 | ✔️ 入门级代理 | ✔️ 高复杂度、长时程 |
| 成本敏感型部署 | ✔️ 资源效率最优 | ❌ 仅限高端付费层 |
可用性与与开发者工具的集成
Claude Chat & Apps: 两款模型均可在 Anthropic 的 Claude 界面(Web 与应用)中使用。Sonnet 4 向所有用户(含免费层)开放,而 Opus 4 仅在付费计划(Pro/Max/Team/Enterprise)中可用。
Anthropic API 与云平台: 两款 Claude 模型都可以通过 Anthropic 的 REST API 使用,并已上架主要云平台。Anthropic 称这“为开发者即时提供”这些模型及其推理与代理能力的访问。
IDEs 与编辑器插件: Anthropic 将 Claude 4 深度集成进编码工作流。全新的 Claude Code 将 Claude 直接嵌入开发环境。面向 VS Code 与 JetBrains IDE 的测试版扩展,可让模型在你的文件中内联提出代码修改建议。还提供了 GitHub Actions 集成:你可以在 Pull Request 上标记 Claude Code,以自动修复失败的 CI 测试或回复评审意见。Claude Code SDK 允许你在本地机器上将 Claude 作为子进程运行。简而言之,Sonnet 4 与 Opus 4 现在可以在熟悉的工具中作为结对程序员工作。Anthropic 指出,GitHub 将使用 Sonnet 4 作为其新 AI 编码代理背后的模型,同时已为 VS Code、JetBrains 与 GitHub 提供连接器。这个生态使开发者无需离开日常环境即可利用 Claude 的能力。
API 与工作流自动化: 两款模型都完全支持编程化调用。Anthropic 的 API(v1)已更新,允许你切换思考模式、设置安全级别并附加工具连接器。实践中,只需更改模型名称(claude-opus-4-20250514 vs claude-sonnet-4-20250514),Python 客户端调用几乎一致。在 CometAPI 上,API 提供统一接口以调用任一模型。开发者可用偏好的语言或 REST 客户端将其集成进自动化工作流(CI/CD、监控、数据管道)。
对比图表
| 特性 | Claude Opus 4 | Claude Sonnet 4 |
|---|---|---|
| 模型类型 | 最大的 “Opus” 型号 —— 聚焦于最大化推理能力。 | 中型模型 —— 在速度、成本与能力之间取得平衡。 |
| 上下文窗口 | 200K tokens(超大上下文);适合极长文档或多文件代码。 | 200K tokens(同样极大)。 |
| 输出长度 | 每次响应最多 32K tokens(适合复杂代码输出)。 | 每次响应最多 64K tokens(更长输出)。 |
| 性能(SWE-bench) | ~72.5–79%(领先的编码基准)。 | ~72.7–80%(非常接近的编码得分)。 |
| 性能(通用 IQ) | 高级推理强(MMLU ~87%)。在难题上略胜 Sonnet。 | 推理能力强(MMLU ~85%);在硬任务上略低于 Opus。 |
| 用例示例 | 最适合长周期代码项目、深度研究与代理规划(如多文件项目重构、小时级模拟)。 | 最适合高并发任务与交互式代理(如在线聊天机器人、代码评审、CI 自动化)。 |
| Extended Thinking | 支持(64K token 思考模式;擅长深度多步骤推理)。适合需要更长“思考”的任务。 | 支持(64K token 思考模式)。同样支持,并提供面向用户的推理摘要。 |
| 工具支持 | 完整工具使用(并行网页搜索、代码执行、文件 I/O 等)。 | 完整工具使用(同等能力)。 |
| 记忆与 “Files” | 通过 Files API 的先进长期记忆;擅长跟踪项目状态。 | 同样的记忆功能;也可存储与回忆事实。 |
| 多模态输入 | 强大的代码+文本;可通过工具处理图像(视觉分析)。以文本/编码任务为主。 | 包含视觉与 UI 能力;可解析图像/截图,甚至“使用”软件 UI。 |
| 延迟与吞吐 | 延迟更高(计算更重)。适合强调深度的批处理/自动化工作流。 | 延迟更低(响应更快)。为交互与流式使用优化。 |
| 可用性 | Anthropic API(Pro/Enterprise)、AWS Bedrock、GCP Vertex。仅付费层。 | Anthropic API(所有层)、AWS Bedrock、GCP Vertex。Claude 上亦免费。 |
| 定价(tokens) | $15/每百万输入、$75/每百万输出。 | $3/每百万输入、$15/每百万输出。 |
| 安全/对齐 | 最高等级的安全(ASL-3+ 措施),“最不可能”走捷径。 | 同样稳健的安全措施(ASL-3)。效率略高,对齐一致。 |
结论
在 2025 年,Anthropic 的 Claude Opus 4 与 Sonnet 4 为面向开发者的 AI 带来了显著飞跃。它们引入的扩展多模态推理、更深入的工具集成与前所未有的上下文长度,直接解决了现代开发工作流中的难题。通过 API 或云平台将这些模型嵌入流程,团队即可在不牺牲准确性与对齐的前提下,自动化软件生命周期中更多环节 —— 从代码设计到部署。Opus 4 将前沿 AI 推理带入复杂、开放式任务;Sonnet 4 则以高速与高性价比支持日常编码与代理需求。
这些改进 —— extended thinking、memory files、并行工具与精简的 IDE 集成 —— 并非小步快跑,而是重塑了开发者与 AI 的协作方式:从一次性补全转向跨数小时工作的持续协作。结果是日常开发任务更快且更可靠,让工程师将精力集中在创造力与把控上。正如 Anthropic 所言,使用 Claude 4,“你可以用 Opus 4 在整个项目范围内编写与重构代码”,并用 Sonnet 4 支撑“日常开发任务”。
入门
CometAPI 提供统一的 REST 接口,将数百个 AI 模型(包括 Claude 系列)聚合到一致的端点之下,并内置 API 密钥管理、用量配额与账单看板。无需同时应对多个厂商的 URL 与凭据。
开发者可通过 CometAPI 访问 Claude Sonnet 4 API(模型:claude-sonnet-4-20250514;claude-sonnet-4-20250514-thinking)与 Claude Opus 4 API(模型:claude-opus-4-20250514;claude-opus-4-20250514-thinking)等。首先,可在 Playground 中探索模型能力,并查阅 API guide 获取详细说明。访问前,请确保已登录 CometAPI 并获取 API key。CometAPI 还新增了 cometapi-sonnet-4-20250514 与 cometapi-sonnet-4-20250514-thinking,专为在 Cursor 中使用。
New to CometAPI? Start a free 1$ trial,让 Sonnet 4 助你攻克最棘手的任务。
我们迫不及待想看到你的作品。如果哪里不对劲,请点击反馈按钮 —— 告诉我们具体问题是让它变得更好的最快方式。