

Claude Sonnet 4.5(通常简写为Claude 4.5)是 Anthropic 于 2025 年 9 月 29 日发布的前沿版本,聚焦于长周期的代理型工作、编码以及“计算机使用”(跨工具自动化多步任务)。它在自主编码时长、工具使用能力与对齐行为方面实现了大幅跃升,同时保持与上一代 Sonnet 版本相同的每 token 定价。对于构建代理型工作流、开发者生产力栈以及受监管企业应用的团队而言,Claude 4.5 是一个兼具吸引力与成本理性的选择。
什么是 Claude Sonnet 4.5
Claude Sonnet 4.5 是 Anthropic 的下一代重要 Claude 模型迭代(品牌为“Sonnet 4.5”),旨在执行更长、更复杂的多步任务,代表用户操作软件工具,并为企业客户提供生产级的编码与推理能力。该版本强调代理型能力(模型可在多步、多工具中自主行动)、更紧密的对齐/安全,以及更丰富的应用内功能,如代码执行与文件创建(电子表格、幻灯片、文档)。
关键突破与特性
1. 持续、长时运行的代理能力
Anthropic 报告称,Claude Sonnet 4.5 在复杂任务上可保持专注的多步操作,持续超过 30 小时——对于需要 AI 在长时间跨度内编排众多子任务并处理不断变化上下文的工作流,这是一次跨越式提升。这是 Anthropic 所瞄准“代理”用例的核心。
2. 业界领先的编码与计算机使用表现
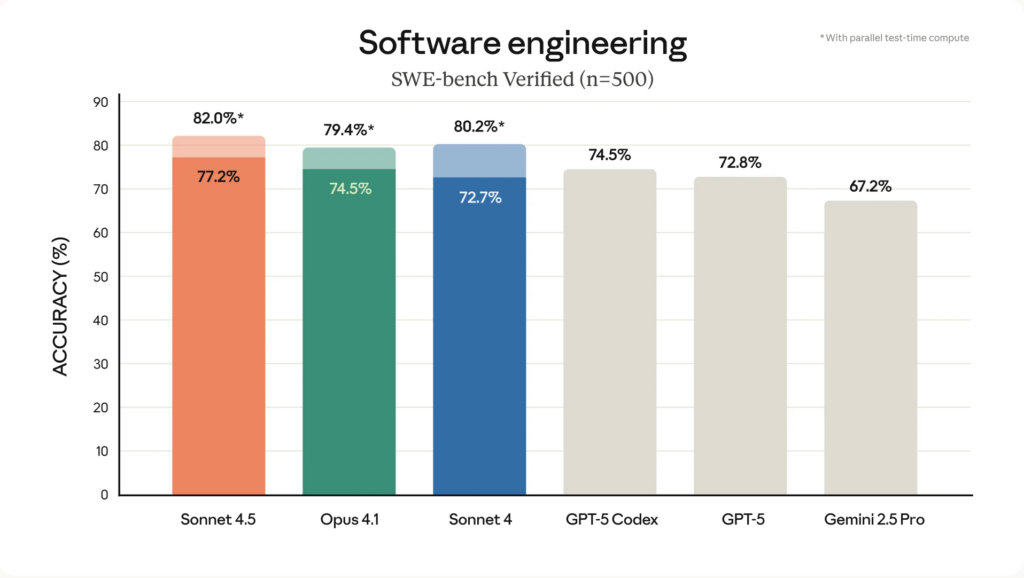
Claude 4.5 在 SWE-Bench Verified(业界编码基准)上取得了顶级成绩,并在实际使用计算机的能力上显著提升(执行工具调用、管理终端/IDE 工作流、构建应用)。Anthropic 与独立媒体将其描述为编码任务的领先模型,并在多项软件工程指标上“世界最佳”。这包括对自主代码生成、调试以及长时代码执行会话的改进。
3. 改进的工具编排、上下文管理与记忆
为支持长时间的代理运行,Claude Sonnet 4.5 引入了更好的上下文管理工具(自动“上下文编辑”以清理陈旧的工具输出),以及一个基于文件的记忆工具,使模型能够在会话之间持久化并检索状态。这些系统特性减少了上下文膨胀,并帮助代理在长工作流中保持“专注于任务”。
4. 更佳的系统/操作系统交互
在 Anthropic 描述并由多方报道的内部测试中,新的 Claude Sonnet 4.5 变体在系统使用基准上取得了显著提升(例如,Anthropic 报告在某操作系统基准任务上的熟练度从约 40% 跃升至约 60%),这意味着该模型在与其他软件交互与控制方面有可量化的改进。当你希望模型可靠地操作工具(编辑文件、运行构建、调用 API)时,这尤为有价值。
5. 开发者工具与集成
Anthropic 随 Claude Sonnet 4.5 一同提供面向开发者的工具:Claude Agent SDK、原生 VS Code 集成、终端/IDE 工作流,以及推送至 GitHub Copilot(Copilot Pro/Enterprise 预览)等产品集成。这些集成为工程团队缩短了从原型到生产的路径。
6. 对齐与安全性改进
Anthropic 称 Claude Sonnet 4.5 为其发布过的“对齐性最高的前沿模型”;它在 AI Safety Level 3 (ASL-3) 防护下部署,并包含改进的分类器与防御机制(例如针对提示注入),Anthropic 报告问题行为有所减少。
性能基准 — 这些数字意味着什么
Anthropic 的公告发布了多项核心数据(SWE-bench、OSWorld、内部终端/代理基准)。Anthropic 公布的关键数据:
- SWE-bench Verified: 77.2%(200K 推理预算,scaffold + tools);在 1M 上下文中为 78.2%;在“高计算”候选选择机制下报告为 82.0%。
- OSWorld(计算机任务): Sonnet 4.5 为 61.4%,对比四个月前的 Sonnet 4 为 42.2%。
- 自主运行时长(内部测试): >30 小时连续自主编码/代理操作(上一代约 ~7 小时)。
- 操作系统/工具基准: Anthropic 报告在某 OS 交互基准上提升至 ~60%,而前代约为 ~40%——显示模型在控制软件时的可靠性提升。
定价(开发者/API)
Anthropic 列出的 Sonnet 4.5 开发者定价与 Sonnet 4 一致:每百万输入 token $3,每百万输出 token $15(可通过提示缓存与批处理获得标准成本节省)。Sonnet 4.5 可通过 Claude API 与 Claude 应用获取。企业与规模折扣/产品层级(Pro/Max/Team/Enterprise)可通过 Anthropic 的商业渠道获得。
为什么选择 Claude Sonnet 4.5?其擅长的用例
代理型自动化与编排
如果你需要模型运行长时间的工作流(数小时/数天)、在多步骤间管理记忆、协调子代理,或自主操作工具(终端、Web UI、电子表格),那么 Sonnet 4.5 对持续一致性的关注与专用的 Agent SDK 将是重大优势。
生产级编码与开发者生产力
Anthropic 的基准与合作伙伴报告(例如 GitHub Copilot 集成)表明,Sonnet 4.5 能够处理多文件代码库编辑、测试与长时间调试会话——适用于开发者希望在更少人工提示下,由助理进行创作、测试与迭代的场景。
受监管与企业场景
更强的对齐性与 ASL-3 部署,使 Sonnet 4.5 对需要更高防护栏与有据可查安全实践的金融、法务、安全与医疗团队更具吸引力。Anthropic 明确将该模型定位于企业客户。
成本敏感的生产用例
由于 Sonnet 4.5 保持了 Sonnet 级别的定价(每百万 token 约 ~$3/$15),与一些更高价的前沿模型相比,其在重代理型工作负载下的性价比更为可观——尤其是在考虑提示缓存与其他平台优化时。
如需考虑替代方案:
- 如果你的优先级是尽可能低的延迟或用于基础问答的最低每 token 推理成本;对于简单工作负载,较轻量的模型或其他供应商的蒸馏模型可能更便宜/更快。(定价与成本结构各异;请比较每 token 输出定价与缓存策略。)
何时选择 Claude Sonnet 4.5 — 实用指南
如果满足以下条件,选择 Claude Sonnet 4.5:
- 你需要一个 LLM 在长序列中可靠地操作工具(代理编排、自动化流水线、自主助理)。
- 你的主要工作负载是大规模软件工程(自动编码、长时间调试会话、持续集成任务)——据报道,Sonnet 4.5 在 SWE-Bench 及相关代码基准上表现出色。
- 你的工作领域受监管或高风险(法务、金融、安全),需要一个在可预测、可审计行为与更安全输出方面经过调优的模型。Anthropic 强调企业级可靠性与安全性。
如需考虑替代方案:
你的优先级是尽可能低的延迟或用于基础问答的最低每 token 推理成本;对于简单工作负载,较轻量的模型或其他供应商的蒸馏模型可能更便宜/更快。(定价与成本结构各异;请比较每 token 输出定价与缓存策略。)
如何访问 Claude Sonnet 4.5
CometAPI 是一个统一的 API 平台,将来自领先提供商的 500 多个 AI 模型——如 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等——聚合到单一且对开发者友好的接口中。通过提供一致的身份验证、请求格式与响应处理,CometAPI 显著简化了将 AI 能力集成到你的应用中的过程。无论你在构建聊天机器人、图像生成器、音乐创作工具,还是数据驱动的分析流水线,CometAPI 都能让你更快迭代、控制成本并保持供应商中立,同时获取 AI 生态中的最新突破。
开发者可通过 CometAPI 访问 Claude Sonnet 4.5 和 Claude Sonnet 4,最新模型版本 始终与官方网站保持同步更新。开始之前,可在 Playground 体验模型能力,并查阅 API 指南 获取详细说明。在访问前,请确保你已登录 CometAPI 并获得 API key。CometAPI 提供远低于官方的价格,助你完成集成。
准备好了吗?→ 立即注册 CometAPI !
结论
Claude Sonnet 4.5 是一次有针对性的进化:它不只是“稍微更会聊天”。Anthropic 将其设计为一个可靠的代理构建器——能够长时间专注于任务、编排工具与代码,并处理领域密集型的工作流(法律、金融、网络安全与工程)。如果你的生产用例需要稳健的工具编排、扩展的上下文稳定性与顶级的编码性能——同时希望保持可预测的每 token 定价——那么 Claude 4.5 值得在你的环境中进行正式的技术试用。