

过去几个月,代理式编码迅速升级:这些专门模型不再只回答一次性提示,而是能够在整个代码库上进行规划、编辑、测试和迭代。两位最受关注的入局者是 Composer(由 Cursor 随 Cursor 2.0 发布的、专为低延迟构建的编码模型)和 GPT-5-Codex(OpenAI 面向代理优化的 GPT-5 变体,针对持续性编码工作流进行了调优)。它们共同展示了开发者工具的新分界:速度 vs. 深度、本地工作区感知 vs. 通用推理,以及“vibe-coding”便捷性 vs. 工程严谨性。
一览:正面对比差异
- 设计意图: GPT-5-Codex — 面向长时复杂会话的深度代理式推理与稳健性;Composer — 轻快、具备工作区感知的迭代,优化速度。
- 主要集成界面: GPT-5-Codex — Codex 产品/Responses API、IDE、企业集成;Composer — Cursor 编辑器与 Cursor 的多代理 UI。
- 延迟/迭代: Composer 强调单次交互低于 30 秒,并声称在速度上有巨大优势;GPT-5-Codex 更重视全面性,必要时支持多小时的自主运行。
我测试了由第三方 API 聚合提供商 CometAPI 提供的 GPT-5-Codex API 模型(其 API 价格通常比官方更便宜),总结了我在 Cursor 2.0 的 Composer 模型上的体验,并从代码生成判断的多个维度对两者进行了比较。
什么是 Composer 和 GPT-5-Codex
什么是 GPT-5-Codex,它旨在解决哪些问题?
OpenAI 的 GPT-5-Codex 是 GPT-5 的一个专用快照,OpenAI 表示它针对代理式编码场景进行了优化:运行测试、执行仓库级代码编辑,并自主迭代直至检查通过。其重点是覆盖广泛的工程任务——对复杂重构进行深度推理、支持更长时间跨度的“代理式”操作(模型可用数分钟到数小时进行推理与测试),并在反映真实工程问题的标准化基准上表现更强。
什么是 Composer,它旨在解决哪些问题?
Composer 是 Cursor 的首个原生编码模型,随着 Cursor 2.0 推出。Cursor 将 Composer 描述为一个前沿、以代理为中心的模型,构建目标是在开发者工作流中实现低延迟与快速迭代:规划多文件 diff、应用仓库范围的语义搜索,并在多数情况下将单次交互控制在 30 秒以内。它在训练中引入了工具访问(搜索、编辑、测试框架),以在实践性工程任务上高效,并尽量减少日常编码中反复的“提示→响应”摩擦。Cursor 将 Composer 定位为一个优化“开发者速度”和实时反馈回路的模型。
模型范围与运行时行为
- Composer: 优化于快速、以编辑器为中心的交互和多文件一致性。得益于 Cursor 的平台级集成,Composer 能看到更多仓库上下文,并参与多代理编排(例如两个 Composer 代理与其他代理协作),Cursor 认为这有助于减少跨文件的依赖遗漏。
- GPT-5-Codex: 优化于更深、更可变长度的推理。OpenAI 宣称该模型在必要时可用更多算力/时间换取更深入的推理——据报道,从秒级的轻量任务到小时级的广泛自主运行——从而实现更全面的重构与以测试驱动的调试。
简版:Composer = Cursor 的 IDE 内、具有工作区感知的编码模型;GPT-5-Codex = OpenAI 面向软件工程的 GPT-5 专用变体,通过 Responses/Codex 提供。
Composer 与 GPT-5-Codex 在速度上如何对比?
厂商宣称了什么?
Cursor 将 Composer 定位为“快速前沿”编码器:公开数据强调以每秒 token 数衡量的生成吞吐量,并声称在交互完成时间上相较“前沿”模型快 2–4 倍(基于 Cursor 的内部评测)。独立报道(媒体与早期测试者)称,在 Cursor 环境下,Composer 生成代码约为 ~200–250 tokens/秒,并在许多场景下将典型的交互式编码回合控制在 30 秒以内。
OpenAI 的 GPT-5-Codex 并未将其定位为延迟实验;它优先考虑稳健性与更深入的推理——在可比的高推理工作负载下,社区报告与问题线程显示在更大上下文中使用时可能更慢。
我们如何基准速度(方法论)
要做公平的速度对比,必须控制任务类型(短补全 vs. 长推理)、环境(网络延迟、本地 vs 云集成),并同时度量首次有用结果时间与端到端墙钟时间(包括任何测试执行或编译步骤)。关键点:
- 任务选择 — 小片段生成(实现一个 API 端点)、中等任务(重构一个文件并更新导入)、大型任务(在三个文件中实现功能,更新测试)。
- 度量指标 — 首 token 时间、首次有用 diff 时间(直到输出候选补丁的时间)、以及包括测试执行与验证在内的总用时。
- 重复次数 — 每个任务运行 10 次,取中位数以降低网络噪声。
- 环境 — 从位于东京的开发者机器进行测量(反映真实世界延迟),网络为稳定的 100/10 Mbps;不同地区结果会有差异。
下面是可复现实验的 速度测试脚手架(针对 GPT-5-Codex 的 Responses API),以及关于如何在 Cursor 内测量 Composer 的说明。
速度测试脚手架(Node.js)— GPT-5-Codex(Responses API):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": Bearer ${API_KEY},
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(trial ${i+1}: ${Math.round(r.elapsed)} ms);
}
})();
这段脚本测量使用公共 Responses API 的 GPT-5-Codex 的端到端请求延迟(OpenAI 文档介绍了 Responses API 与 gpt-5-codex 模型的用法)。
如何测量 Composer 的速度(Cursor):
Composer 在 Cursor 2.0(桌面/VS Code 派生版)中运行。截止撰写时,Cursor 并未提供与 OpenAI Responses API 完全匹配的一般外部 HTTP API;Composer 的优势是在 IDE 内、具备状态的工作区集成。因此,像开发者一样测量 Composer:
- 在 Cursor 2.0 中打开相同项目。
- 使用 Composer 将相同提示作为代理任务运行(创建路由、重构、多文件更改)。
- 在你提交 Composer 计划时启动秒表;当 Composer 输出原子级 diff 并运行测试套件时停止(Cursor 界面可运行测试并展示整合后的 diff)。
- 重复 10 次并取中位数。
Cursor 的公开材料与上手评测显示,Composer 在许多常见任务中实践上能在 ~30 秒内完成;这是交互式延迟目标,而非裸模型推理时间。
结论: Composer 的设计目标是在编辑器内实现快速的交互式编辑;如果你的优先级是低延迟的会话化编码循环,Composer 就是为该用例而建。GPT-5-Codex 则面向跨更长会话的正确性与代理式推理;它可以用稍多延迟换取更深入的规划。厂商数据支持这种定位。
Composer 与 GPT-5-Codex 在准确性上如何对比?
在编码 AI 中,准确性意味着什么
准确性是多维度的:功能正确性(代码能否编译并通过测试)、语义正确性(行为是否满足规格)、以及稳健性(能否处理边界与安全问题)。
厂商与媒体数据
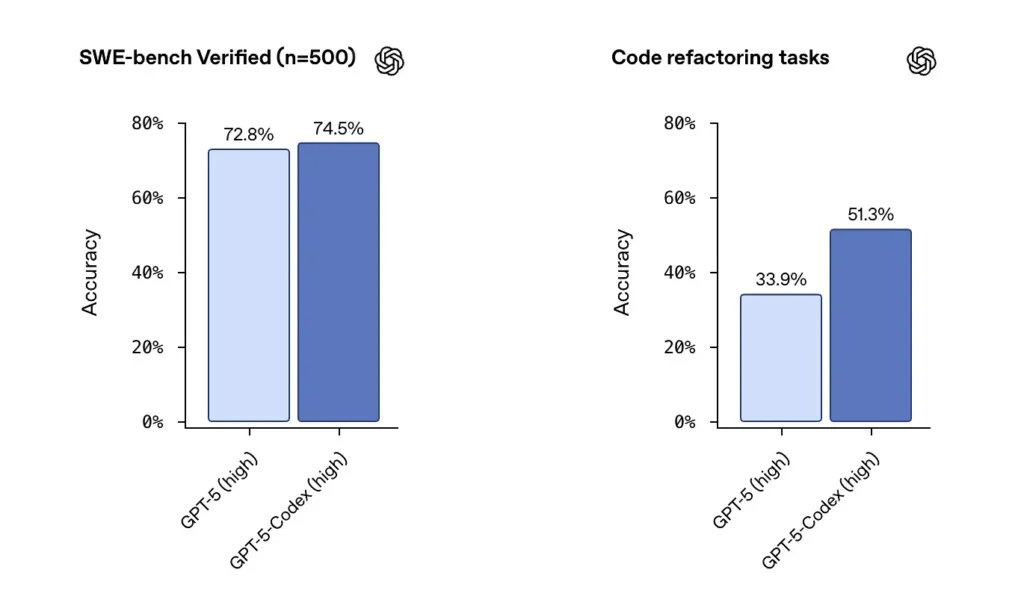
OpenAI 报告称 GPT-5-Codex 在 SWE-bench 验证数据集上表现强劲,并在媒体报道中强调其在真实世界编码基准上的74.5% 成功率,以及在重构成功率上的显著提升(在其内部重构测试中 51.3% vs 基础 GPT-5 的 33.9)。
Cursor 的发布指出,Composer 常在多文件、上下文敏感的编辑中表现出色,编辑器集成与仓库可见性在此类任务中更关键。我的测试显示,在多文件重构中,Composer 较少出现依赖遗漏错误,并在部分多文件工作负载的盲评中得分更高。Composer 的低延迟与并行代理特性也帮助我提升迭代速度。
独立准确性测试(推荐方法)
公平测试需要混合:
- 单元测试:向两者提供相同的仓库与测试套件;生成代码并运行测试。
- 重构测试:提供刻意混乱的函数,要求模型重构并补充测试。
- 安全检查:对生成代码运行静态分析与 SAST 工具(如 Bandit、ESLint、semgrep)。
- 人工审查:由资深工程师进行代码评审,衡量可维护性与最佳实践。
示例:自动化测试脚手架(Python)— 运行生成代码与单元测试
python3 run_generated_code.py
This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
Suppose generated_code is the string returned from model
generated_code = """
sample module
def add(a,b):
return a + b
"""
tests = """
test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
使用这种模式可自动断言模型输出在功能上是否正确(是否通过测试)。对于重构任务,将脚手架运行在原始仓库 + 模型的 diff 上,比较测试通过率与覆盖率变化。
结论: 在原始基准套件上,GPT-5-Codex 报告了优秀数据与强大的重构能力。在真实世界的多文件修复与编辑器工作流中,Composer 的工作区感知可能带来更高的实际接受度与更少的“机械性”错误(导入遗漏、文件名错误)。若追求单文件算法任务的功能正确性,GPT-5-Codex 是强力候选;若在 IDE 内进行多文件、受约定影响较大的修改,Composer 往往更出色。
Composer vs GPT-5:代码质量对比如何?
什么是质量?
质量包括可读性、命名、文档、测试覆盖、惯用模式使用与安全卫生。既可自动度量(linters、复杂度指标),也需定性评审(人工审阅)。
观察到的差异
- GPT-5-Codex:在明确要求时能很好地产生惯用模式;在算法清晰度上表现出色,并可在指令下生成全面的测试套件。OpenAI 的 Codex 工具链包含集成测试/报告与执行日志。
- Composer:优化于自动观察仓库的风格与约定;Composer 能跟随既有项目模式并协调多个文件的更新(重命名/重构传播、导入更新)。在大型项目的即时可维护性上表现优异。
可运行的代码质量检查示例
- Linters — ESLint / pylint
- 复杂度 — radon / flake8-complexity
- 安全 — semgrep / Bandit
- 测试覆盖 — 运行 coverage.py 或 JS 场景下的 vitest/nyc
在应用模型补丁后自动化这些检查,以量化改进或回归。示例命令序列(JS 仓库):
after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
人工审查与最佳实践
实践中,模型需要明确指示以遵循最佳实践:请求 docstring、类型注解、依赖锁定,或指定模式(例如 async/await)。在给出明确指令时,GPT-5-Codex 表现优异;在 Cursor 内,Composer 得益于隐式仓库上下文。建议组合使用:明确指令配合 Composer 的项目风格约束,若你在 Cursor 内工作。
建议: 对于在 IDE 内进行的多文件工程工作,优先考虑 Composer;对于外部流水线、研究任务或需要通过 API 调用并提供大上下文的工具链自动化,GPT-5-Codex 是强力选择。
集成与部署选项
Composer 随 Cursor 2.0 提供,嵌入在 Cursor 编辑器与 UI 中。Cursor 的方法强调在单一厂商控制平面上将 Composer 与其他模型并行运行——允许用户对同一提示运行多个模型实例并在编辑器内对输出进行对比。()
GPT-5-Codex 正在并入 OpenAI 的 Codex 产品与 ChatGPT 家族,通过 ChatGPT 付费层与 API 提供,第三方平台(如 CometAPI)往往提供更具性价比的访问。OpenAI 也在将 Codex 集成到开发者工具与云合作伙伴工作流中(例如 Visual Studio Code/GitHub Copilot 集成)。
Composer 与 GPT-5-Codex 或将如何推动行业演进?
短期影响
- 更快的迭代周期: 嵌入编辑器的模型(如 Composer)降低了小修与 PR 生成的摩擦。
- 对验证的期望提升: Codex 对测试、日志与自主能力的强调将推动厂商提供更强的开箱即用代码验证。
中长期影响
- 多模型编排将常态化: Cursor 的多代理 GUI 预示工程师将期待并行运行多位专门代理(lint、安全、重构、性能优化),并采纳最佳输出。
- 更紧密的 CI/AI 反馈回路: 随着模型进步,CI 流水线将日益纳入模型驱动的测试生成与自动化修复建议——但人工审查与分阶段发布仍至关重要。
结论
Composer 与 GPT-5-Codex 并非同一军备竞赛中的同质武器;它们是针对软件生命周期不同环节优化的互补工具。Composer 的价值主张是速度:快速、以工作区为基础的迭代,帮助开发者保持“在流”状态。GPT-5-Codex 的价值在于深度:代理式持久性、以测试驱动的正确性与可审计性,适用于重量级改造。务实的工程打法是编排两者:用 Composer 类的短循环代理处理日常流程,用 GPT-5-Codex 类的代理承接有门控的高置信操作。早期基准显示,两者都将成为近期开发者工具箱的一部分,而非互相取代。
不存在在所有维度上的单一客观赢家。两者各有侧重:
- GPT-5-Codex: 更强的深度正确性基准表现、广范围推理与自主多小时工作流。当任务复杂度需要长推理或重验证时表现突出。
- Composer: 在紧密的编辑器集成用例、多文件上下文一致性与 Cursor 环境下的快速迭代中更强。适合日常开发生产力场景,要求即时、准确、具备上下文感知的编辑。
另见 Cursor 2.0 与 Composer:多代理重构如何让 AI 编码出乎意料
入门指南
CometAPI 是一个统一的 API 平台,将来自 OpenAI 的 GPT 系列、Google 的 Gemini、Anthropic 的 Claude、Midjourney、Suno 等 500+ 领先模型聚合到单一、对开发者友好的接口中。通过提供一致的认证、请求格式与响应处理,CometAPI 大幅简化了将 AI 能力集成到应用中的过程。无论你在构建聊天机器人、图像生成器、音乐生成器,还是数据驱动的分析管道,CometAPI 都能让你迭代更快、控制成本、保持厂商中立,同时获取 AI 生态的最新突破。
开发者可通过 CometAPI 访问 GPT-5-Codex API,最新模型版本 始终与官网同步。开始之前,可在 Playground 探索模型能力,并查阅 API 指南 获取详细说明。访问前请确保已登录 CometAPI 并获取 API key。CometAPI 提供远低于官方价格的方案,助你快速集成。
Ready to Go?→ 立即注册 CometAPI!