
Gemini 2.5 Flash API 是 Google 最新的多模态 AI 模型,旨在以高速、低成本完成任务,并具备可控的推理能力,开发者可通过 Gemini API 开启或关闭高级“思考”功能。最新模型为 gemini-2.5-flash。
Gemini 2.5 Flash 概览
Gemini 2.5 Flash 的设计目标是在不牺牲输出质量的前提下提供快速响应。它原生支持文本、图像、音频和视频等多模态输入,适用于多种应用场景。该模型可通过 Google AI Studio 和 Vertex AI 等平台访问,为开发者提供在各类系统中无缝集成所需的工具。
基本信息(功能)
Gemini 2.5 Flash 引入多项突出的功能,在 Gemini 2.5 家族中独具特色:
- 混合推理:开发者可设置 thinking_budget 参数,精细控制模型在输出前用于内部推理的令牌数量。
- 帕累托前沿:定位于最优成本-性能点,Flash 在 2.5 系列中提供最佳的价格-智能比。
- 多模态支持:原生处理文本、图像、视频与音频,实现更丰富的对话与分析能力。
- 100 万令牌上下文:无与伦比的上下文长度,允许在单次请求中进行深度分析与长文档理解。
模型版本
Gemini 2.5 Flash 经历了以下关键版本迭代:
- gemini-2.5-flash-lite-preview-09-2025:增强工具可用性:在复杂、多步任务上性能提升,SWE-Bench Verified 分数提升 5%(从 48.9% 至 54%)。提高效率:启用推理时,以更少令牌实现更高质量输出,降低延迟与成本。
- Preview 04-17:早期访问版本,具备“思考”能力,通过 gemini-2.5-flash-preview-04-17 提供。
- 稳定版 GA(一般可用):自 2025 年 6 月 17 日起,稳定端点 gemini-2.5-flash 取代预览版,确保生产级可靠性,与 5 月 20 日的预览版相比无 API 变更。
- 预览版弃用:预览端点计划于 2025 年 7 月 15 日关闭;用户需在此日期前迁移至 GA 端点。
截至 2025 年 7 月,Gemini 2.5 Flash 已公开可用并稳定(与 gemini-2.5-flash-preview-05-20 无变化)。如果你正在使用 gemini-2.5-flash-preview-04-17,现有预览定价将持续至模型端点计划于 2025 年 7 月 15 日退役并关闭之时。你可以迁移至一般可用的模型“gemini-2.5-flash”。
更快、更便宜、更智能:
- 设计目标:低延迟 + 高吞吐 + 低成本;
- 在推理、多模态处理与长文本任务上整体加速;
- 令牌使用减少 20–30%,显著降低推理成本。
技术规格
输入上下文窗口:最多支持 100 万令牌,允许广泛的上下文保留。
输出令牌:每次响应最多可生成 8,192 令牌。
支持的模态:文本、图像、音频和视频。
集成平台:可通过 Google AI Studio 和 Vertex AI 获取。
定价:具有竞争力的按令牌计费模式,便于成本效益部署。
技术细节
在底层架构上,Gemini 2.5 Flash 是基于Transformer的超大语言模型,训练数据涵盖网页、代码、图像和视频等混合来源。主要技术规格包括:
多模态训练:通过对齐多种模态,Flash 可无缝混合文本与图像、视频或音频,适用于视频摘要或音频描述等任务。
动态思考过程:实现内部推理循环,模型会在最终输出前进行规划与拆解复杂提示。
可配置的思考预算:可将 thinking_budget 设置为 0(无推理)至24,576 令牌,在延迟与答案质量之间进行权衡。
工具集成:支持 Grounding with Google Search、Code Execution、URL Context 与 Function Calling,可直接从自然语言触发真实世界操作。
基准测试表现
在严格评估中,Gemini 2.5 Flash 展现出行业领先的性能:
- LMArena Hard Prompts:在挑战性的 Hard Prompts 基准中得分仅次于 2.5 Pro,体现出强大的多步推理能力。
- MMLU 准确率 0.809:超越平均模型表现,0.809 的 MMLU 准确率反映其广泛的领域知识与推理能力。
- 延迟与吞吐:实现 271.4 tokens/sec 的解码速度与 0.29 s 的首令牌时间,适用于对延迟敏感的工作负载。
- 价格-性能领先:以 $0.26/1 M tokens 的价格,相较多位竞争者更具优势,同时在关键基准上表现匹配或更优。
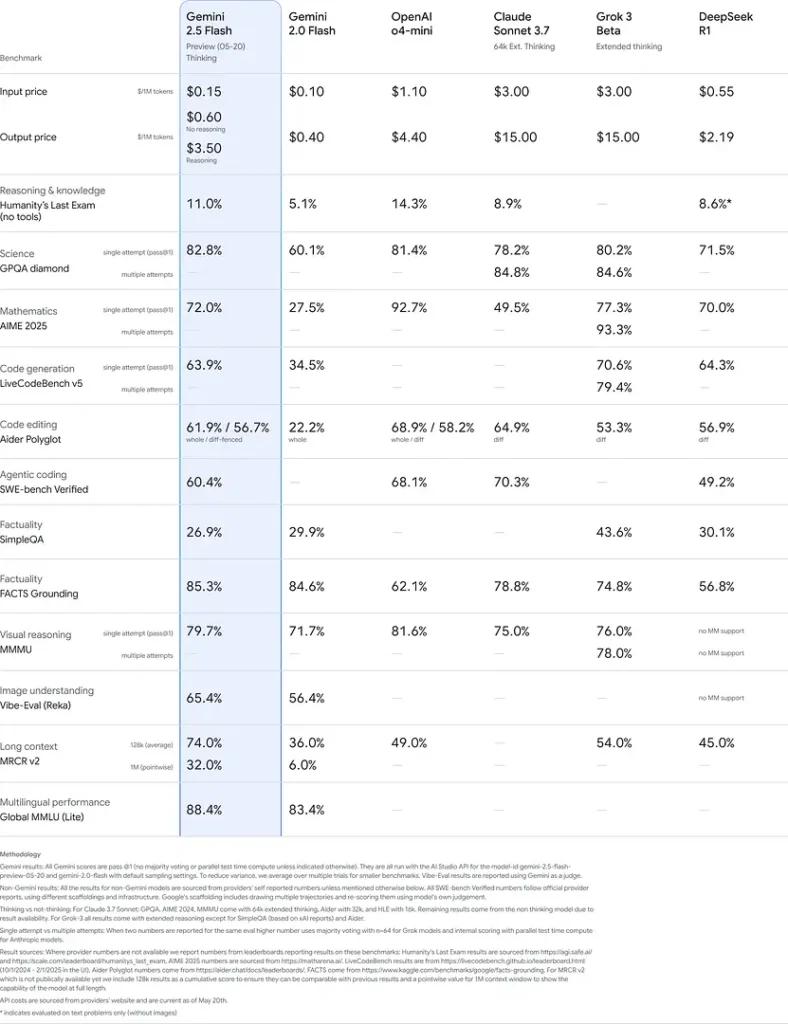
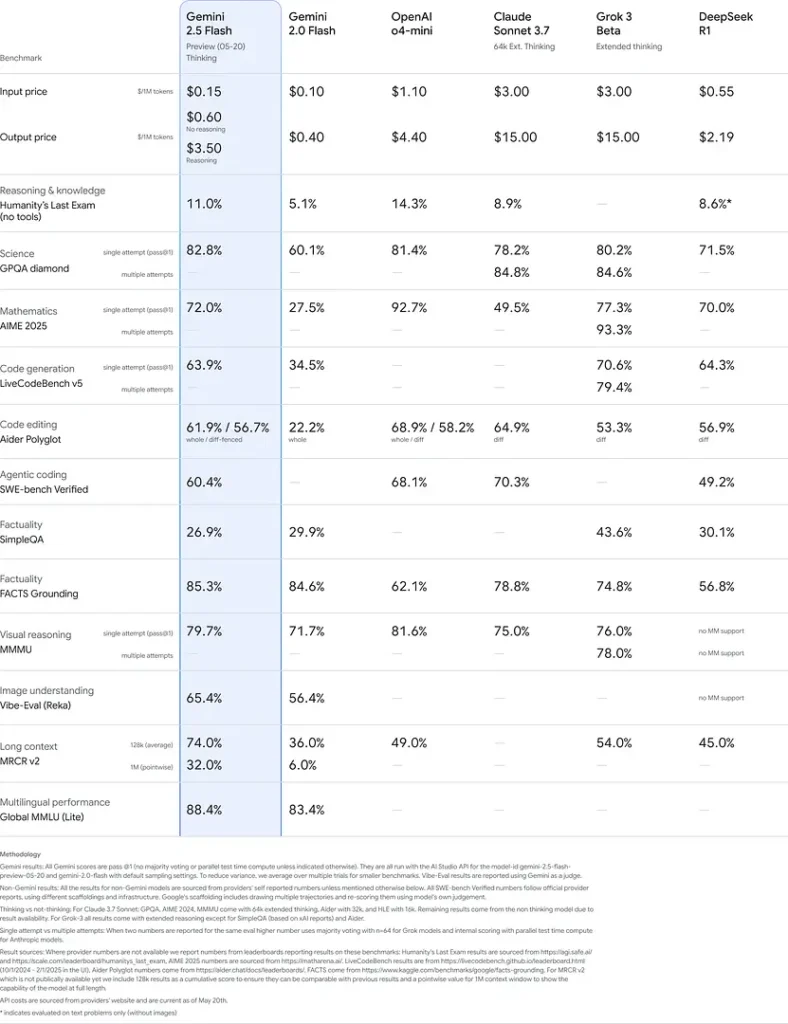
这些结果表明,Gemini 2.5 Flash 在推理、科学理解、数学问题求解、编码、视觉解读与多语言能力方面具备竞争优势:
限制
尽管强大,Gemini 2.5 Flash 仍存在一些限制:
- 安全风险:模型可能呈现**“说教式”语气**,并在边缘案例上生成看似合理但不正确或带偏见的输出(幻觉)。严格的人类监督仍然必要。
- 速率限制:API 使用受到默认层级的速率限制(10 RPM、250,000 TPM、250 RPD),可能影响批处理或高并发应用。
- 智能下限:作为Flash模型,尽管能力出众,但在最苛刻的智能体任务(如高级编码或多智能体协作)上仍不及 2.5 Pro 准确。
- 成本权衡:虽然提供最佳的价格-性能,但广泛使用思考模式会增加总令牌消耗,提高深度推理提示的成本。
结论
Gemini 2.5 Flash 体现了 Google 推动 AI 技术进步的承诺。凭借强劲的性能、多模态能力与高效的资源管理,它为希望在运营中利用人工智能能力的开发者与组织提供了全面解决方案。
如何通过 CometAPI 调用 Gemini 2.5 Flash API
Gemini 2.5 Flash API 在 CometAPI 的定价,较官方价格优惠 20%:
- 输入令牌:$0.24 / M tokens
- 输出令牌:$0.96 / M tokens
必要步骤
- 登录 cometapi.com。如尚未成为我们的用户,请先注册。
- 获取接口的访问凭证 API 密钥。在个人中心的 API token 处点击“Add Token”,获取令牌密钥:sk-xxxxx 并提交。
- 获取本站的 url:https://api.cometapi.com/
使用方法
- 选择 “
gemini-2.5-flash” 端点发送 API 请求并设置请求体。请求方法与请求体可从我们网站的 API 文档获取。我们的网站也提供 Apifox 测试以供便捷使用。 - 将 <YOUR_AIMLAPI_KEY> 替换为你账户中的实际 CometAPI 密钥。
- 将你的问题或请求插入到 content 字段——模型将对此作出响应。
- 处理 API 响应以获取生成的答案。
有关 Comet API 中模型上线信息,请参见 https://api.cometapi.com/new-model.
有关 Comet API 中模型价格信息,请参见 https://api.cometapi.com/pricing。
API 使用示例
开发者可通过 CometAPI 的 API 与 gemini-2.5-flash 交互,支持集成至各类应用。以下为 Python 示例:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
该脚本向 Gemini 2.5 Flash 模型发送一个提示并打印生成的响应,演示如何利用 Gemini 2.5 Flash 进行复杂解释。