

Google 及其研究机构 DeepMind 悄然(随后不那么悄然)推动了 Gemini 路线图的又一重大步骤:Gemini 3.1 Pro。此次发布已在面向消费者的界面和 CometAPI 上推出,定位为 Gemini 3 系列的性能与推理升级——承诺在长篇推理方面显著更强,在多模态理解上有所提升,并在真实世界应用的可扩展性上更好。
Google 的最新模型——Gemini 3.1 Pro 是什么?
Gemini 3.1 Pro 是 Gemini 3 家族中的首个增量更新,定位为“最强能力”的推理模型,针对多步骤、多模态与 agentic(自主代理)任务进行了优化。该模型于 2026 年 2 月中旬向公众预览发布(预览公告日期为 2026 年 2 月 19–20 日),明确面向需要持续思维链、工具调用与长上下文理解的场景——例如:大规模研究综合、可协调工具与系统的工程代理,以及对混合文本、图像、音频和视频的多模态文档分析。
从高层来看,Gemini 3.1 Pro 的开发者对其描述为:
- 天生具备多模态能力——能够同时接收并在同一管线中对文本、图像、音频与视频进行推理。
- 为长上下文而构建——支持极大的上下文窗口,适用于完整代码库、多文档资料夹或长转录内容。
- 针对可靠推理与代理式工作流进行了优化,意味着它被调优以在多步骤任务中进行规划、调用工具并验证输出。
为何此刻重要:组织与开发者正从“出色的对话助手”转向“高风险的决策支持与研究代理”(法律撰写、R&D 综合、多模态文档理解)。Gemini 3.1 Pro 即是为这一通道而生——以降低幻觉、产出可追溯的推理,并与 CometAPI 集成以支持原型与生产。
Gemini 3.1 Pro 的技术亮点与特性有哪些?
原生多模态与极限上下文窗口
Gemini 3.1 Pro 延续了 Gemini 系列对多模态的专注。根据模型卡与产品说明,该模型在同一管线中接收并推理文本、图像、音频与视频——这一能力简化了数据类型混合的工作流(例如同时包含音频+转录+扫描件的法律口供)。值得注意的是,模型支持1,000,000-token的上下文窗口,并可生成长输出(公开说明称输出上限非常大,适合长篇任务)。这一规模使其适用于分析整套代码仓库、多章节文档或长转录而无需分块。
“动态思考”:改进的推理与逐步规划
Google 描述 3.1 Pro 拥有更好的“思考”能力——即更优的内部思维链处理,并能根据任务复杂度动态选择推理策略。模型被调优为在需要时进行显式多步骤规划,同时在此过程中保持 token 效率。实际效果是:对于复杂的、需要步骤推进的问题,幻觉更少,并在多步骤推理基准上展现出更好的事实一致性。
Agentic 工作流与工具使用
3.1 Pro 的主要设计关注点之一是代理式表现:协调工具、调用网页锚定或搜索、编写与执行代码片段,并通过二次检验验证输出。Google 已将 3.1 Pro 集成至以代理为先的产品(例如 Antigravity 开发环境),使模型能够运行涉及编辑器、终端与浏览器的任务——并记录诸如屏幕截图与浏览器录屏等工件以验证进度。这些功能旨在缩小“仅给建议”的模型与能可靠执行多工具工作流的模型之间的差距。
专用子模式(“Deep Research”、“Deep Think”)
Google 将 3.1 Pro 与“Deep Research”配套,并提及即将推出的“Deep Think”变体。这些子模式分别面向高召回的研究任务与最大化推理深度(以更高算力与延迟为代价)。它们旨在服务需要更审慎、更高质量输出的分析师、研究人员与开发者,而非最快、最便宜的响应。
Gemini 3.1 Pro 在基准测试上的表现如何?
Gemini 3.1 Pro 相较于此前的 Gemini 3 Pro 结果取得了显著增益,常在广泛的多步骤推理与多模态指标上领跑——但在某些特定的专门任务(尤其是部分高级编码或专家级题库)上落后于竞争对手。简言之:在专业基准上呈现出广泛提升,同时在狭窄的专项上有竞争对手的优势。
关键基准声明与核心数字
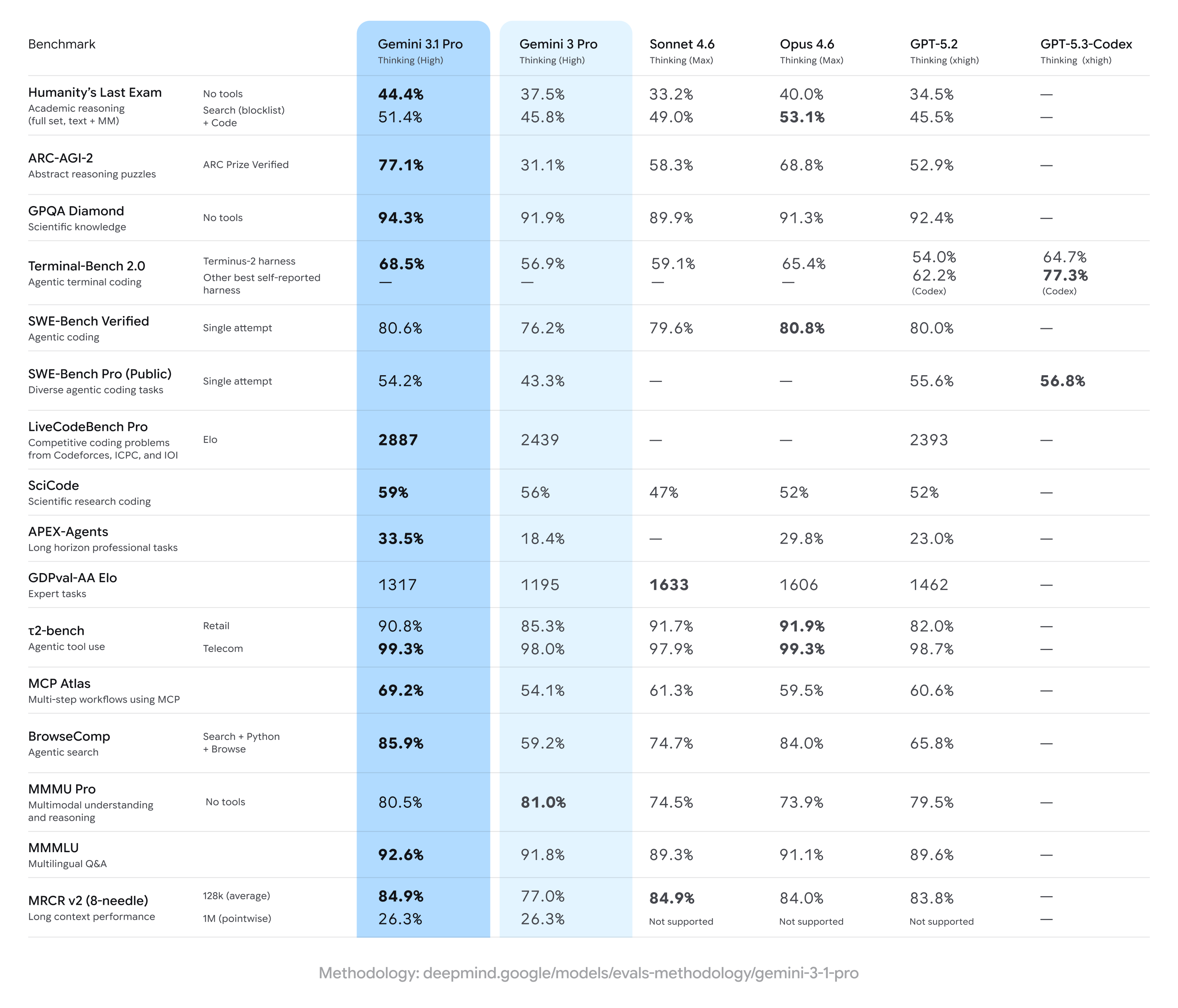
- ARC-AGI-2(抽象推理 / 多步骤科学谜题): 报告显示 Gemini 3.1 Pro 相较于先前的 Gemini 3 Pro 版本有显著提升;某社区测试套件在短而集中的测试中显示相较此前的 Gemini 3 Pro 基线有逾两倍的提升。具体报告分数(社区测试)在部分 ARC 风格聚合上将 Gemini 3.1 Pro 置于 ~77.1%(公开报道)。
- GPQA Diamond 与研究生级科学基准: 数据报告显示 Gemini 3.1 Pro 在 GPQA Diamond(研究生级科学问答基准)上达到了记录高点,超越了早期 Gemini 模型,在独立运行中为该系列设定了新高。这些增益反映了模型在思维链与逐步推理调优方面的改进。
- “Humanity’s Last Exam” 启用工具(多工具、锚定推理): 与 Anthropic 的 Claude Opus 4.6 的正面对比中,Claude 在这一复杂的工具启用基准上取得了53.1%,而 Gemini 3.1 Pro 在同轮测试中达到51.4%——显示 Gemini 紧随其后,但在该特定多工具考试上未能居首。
- 编码与终端基准(Terminal-Bench 2.0、SWE-Bench Pro): 专项编码基准的分化更明显。在配套测试架的 Terminal-Bench 2.0 上,GPT-5.3-Codex 变体约得分77.3%,而 Gemini 3.1 Pro 在同组对比中约为**~68.5%。在 SWE-Bench Pro 的公开结果上,Gemini 3.1 Pro 得分约为54.2%,而 GPT-5.3-Codex 为56.8%**——差距更小,但在这些运行中 OpenAI 的 Codex 家族在专门编程任务上仍有优势。
- GDPval-AA Elo(专家任务评级): 在专家任务的 Elo 式聚合排名中,Claude Sonnet/Opus 变体得分更高(例如**~1606–1633** 分),而某份公开报告在同一数据集中将 Gemini 3.1 Pro 置于**~1317** 分——表明在某些狭窄的专家领域仍有改进空间。
真实世界试用结果与上手测试
分析师的实测文章显示 Gemini 3.1 Pro 尤其擅长:
- 长上下文的总结与多文档综合,1M token 窗口避免了易出工件的分块。
- 多模态理解任务,其中图像+文本锚定提升事实提取。
- 代理式自动化(例如协调简单工具链)——Antigravity 的试验表明,多代理任务的编排可行,并能记录每一步的工件。
Gemini 3.1 Pro 的短板(数字所揭示)
没有模型在所有方面都最佳。独立评论与社区测试突出了具体差距:
- 软件工程与代码维护基准(SWE-Bench Pro 及类似): 在测试实用软件工程能力的任务上(大规模重构、在混乱代码库中进行缺陷分流、某些自动程序修复),Gemini 3.1 Pro 落后于竞争者(Anthropic 的 Claude Opus 4.6)。换言之,就日常工程维护而言,某些测试平台上专门化模型仍保持优势。
- 对延迟敏感的微任务: 由于 Gemini 3.1 Pro 为深度而调优,需要超低延迟与高吞吐的任务(例如轻量级对话 UI 的微型推理)可能更适合 Gemini 家族中的 “Flash” 或其他优化变体。
Gemini 3.1 Pro 的定价是什么?
您可以通过两种方式访问Gemini 3.1 Pro——面向消费者的订阅或开发者 API——且两者定价不同。
- 消费者(Gemini 应用 / Google AI Pro): 访问 Gemini 3.1 Pro 包含在 Google AI Pro 订阅中,在美国为**$19.99 / 月**(Google 也提供更低的“AI Plus”与更高的“AI Ultra”档位)。Google。
- 开发者 / API(token 计费): 如果通过 Gemini/AI 开发者 API 调用 Gemini 模型,定价按 token 计量。对于 Gemini 3.x Pro 预览,公开的开发者价格大致为:标准(≤200k 提示)档位每 1M 输入 token $2.00、每 1M 输出 token $12.00——对于超大上下文的更高档位(例如 $4/$18 每 1M)亦有定价。(详见 Gemini API 定价表以及批量定价。)
- 如果您通过 CometAPI 使用 Gemini 3.1 Pro:
| Comet 价格(USD / M Tokens) | 官方价格(USD / M Tokens) |
|---|---|
| 输入:$1.6/M; 输出:$9.6/M | 输入:$2/M; 输出:$12/M |
面向消费者的订阅定价(Gemini 应用)
在 Gemini 应用的终端用户方案中,Google 以分层结构限定模型变体与附加功能:Google AI Pro 与 Google AI Ultra。价格随市场与货币不同而变化;公开示例显示Google AI Pro 为 $19.99/月(提供促销试用),并在产品页显示分层的本地货币定价(包括试用优惠与短期降价)。AI Ultra 提供更高的访问权限(例如对新技术的优先访问、更多视频生成额度),月费更高。这些消费者方案的价格与其他高端消费者 AI 订阅具有竞争力,旨在为个人高级用户或小团队提供无需 API 集成即可访问 3.1 Pro 功能的途径。
实用提示与使用建议(我会这样做)
用以下方法获得可靠、可复现的结果:
- 显式步骤规划器
提示模式:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.这将利用 3.1 Pro 更强的逐步执行能力,并为您提供检查点。 - 使用模式的结构化输出
请求带有模式的 JSON,并设置strict: true。由于 3.1 Pro 对长、遵循模式的输出更可靠,您会获得更大的单次响应,便于下游解析。 - 工具检查“三明治”
在调用外部工具(API、代码运行器)时,让模型产出:计划 → 精确的工具调用(可复制粘贴) → 验证步骤。然后在模型之外先验证这些步骤,再继续。 - 谨防单步信任
即使模型写出了看似完美的代码或命令,也要进行独立验证(测试、linters、沙箱执行)——尤其针对代理式/自主行为。
上手体验:与 Gemini 3.1 Pro 的实操
试验案例 1:长上下文研究助理(NotebookLM / Deep Research)
目标: 评估模型将 10–50 篇长文档(例如报告、白皮书)综合为多页高管摘要,并包含引文与行动项的能力。
设置: 输入总计 200k–800k token 的语料;要求模型生成 2–4 页摘要,包含明确的引文与“下一步”建议。使用可复用的提示模板,并衡量时间、token 使用量(成本)与事实准确性。
结果: 相较旧模型,端到端总结更快、分块工件更少,摘要中的引文一致性更高,并在大规模上具备更好的连贯性——代价是显著的 token 使用量(因此需规划预算)。基准与上手测试显示,凭借 1M token 窗口,Gemini 3.1 Pro 在多文档综合方面表现出色。
试验案例 2:代理式编码助理(Antigravity + GitHub Copilot)
目标: 衡量在多步骤开发任务中的完成时间缩减(例如在多文件中实现一个特性、运行测试、修复失败测试)。
设置: 在预览中选择 Gemini 3.1 Pro,使用 Antigravity 或 GitHub Copilot。定义可复现的任务(创建 issue → 实现 → 运行测试),记录步骤与代理工件,并与仅人工的基线进行对比。
结果: 在多步骤任务的编排上有所改进(工件记录、自动建议补丁候选),相较此前的 Gemini 3 Pro 具备更好的多文件推理,并在常规特性开发上有可量化的时间节省。对于专门的低层系统调试任务,社区结果显示在某些终端基准上与部分 GPT-Codex 变体相比仍存在差距。
试验案例 3:多模态法律/医疗文档审阅
目标: 使用模型摄入混合语料(扫描 PDF、图像、音频转录),提取关键事实,并生成风险矩阵与优先行动项。
设置: 提供包含扫描图像与 OCR 文本的数据集,并配以音频支持。衡量命名实体抽取的精度、误报率,以及模型引用源工件的能力。
结果: 在跨模态的整合推理上更强,输出更可追溯(能够指向支持论断的图像/页面/音频时间戳)。长上下文窗口减少了手动分块与交叉引用的需求。然而,在受监管领域,输出需由领域专家验证,并应采用锚定/验证管线。
第一印象(有哪些不同)
- 更深的逐步推理。 过去需要多次往返的任务——例如多文档综合、多步骤数学/逻辑——往往能在更少的回合中完成,并以更清晰的思维链式输出呈现(不暴露内部指令文本)。这是 Google 强调的重点。
- 更长、更高质量的结构化输出。 JSON 与长流程自动化更一致,而且往往更长(一些用户报告输出规模远大于 3.0)。这非常适合需要单次生成大负载的任务。请准备好处理更大的输出与流式传输。
- 更高的 token/上下文效率。 在工具使用场景中展现出更“锚定、事实一致”的行为与更高的 token 效率。在短事实检索中表现为更少的幻觉。
最终分析:现在值得采用 Gemini 3.1 Pro 吗?
Gemini 3.1 Pro 是 Gemini 系列的一次有意义的前进,在推理、编码与代理式基准上展现了可验证的改进——背靠 Google 发布的模型卡与引用在精选排行榜上大幅跃升的独立跟踪。对于需要高级推理、代理式工具协调或长上下文多模态能力的团队而言,3.1 Pro 是一个颇具吸引力的候选。
开发者现在即可通过 CometAPI 访问 Gemini 3.1 Pro。入门时,请在 Playground 中探索模型能力,并参考 API 指南 获取详细说明。访问之前,请确保已登录 CometAPI 并获取 API key。CometAPI 提供远低于官方价格的方案,以帮助您集成。
Ready to Go?→ Sign up fo Gemini 3.1 pro today
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!