

GLM-4.6 是 Z.ai(原 Zhipu AI)GLM 家族的最新重大版本:一款面向智能体工作流、长上下文推理与真实世界编码调优的第四代大型语言MoE(专家混合)模型。此次发布强调实用的智能体/工具集成、超大的上下文窗口,以及开放权重以便本地部署。
关键特性
- 长上下文 — 原生 200K token 上下文窗口(由 128K 扩展)。()
- 编码与智能体能力 — 在真实世界编码任务与智能体的工具调用方面宣称有所提升。
- 效率 — 据 Z.ai 的测试,相比 GLM-4.5,token 消耗降低约 ~30%。
- 部署与量化 — 首次宣布在 Cambricon 芯片上实现 FP8 与 Int4 集成;通过 vLLM 在 Moore Threads 上原生支持 FP8。
- 模型规模与张量类型 — 已发布的工件显示在 Hugging Face 上提供 ~357B 参数的模型(BF16 / F32 张量)。
技术细节
模态与格式。 GLM-4.6 是一款纯文本 LLM(输入与输出模态:文本)。上下文长度 = 200K tokens;最大输出 = 128K tokens。
量化与硬件支持。 团队报告在 Cambricon 芯片上实现 FP8/Int4 量化,并通过 vLLM 在 Moore Threads GPU 上实现原生 FP8推理——这对于降低推理成本并支持本地及国内云部署很重要。
工具与集成。 GLM-4.6 通过 Z.ai 的 API、第三方供应商网络(如 CometAPI)分发,并集成到编码智能体(Claude Code、Cline、Roo Code、Kilo Code)中。
技术细节
模态与格式。 GLM-4.6 是一款纯文本 LLM(输入与输出模态:文本)。上下文长度 = 200K tokens;最大输出 = 128K tokens。
量化与硬件支持。 团队报告在 Cambricon 芯片上实现 FP8/Int4 量化,并通过 vLLM 在 Moore Threads GPU 上实现原生 FP8推理——这对于降低推理成本并支持本地及国内云部署很重要。
工具与集成。 GLM-4.6 通过 Z.ai 的 API、第三方供应商网络(如 CometAPI)分发,并集成到编码智能体(Claude Code、Cline、Roo Code、Kilo Code)中。
基准测试表现
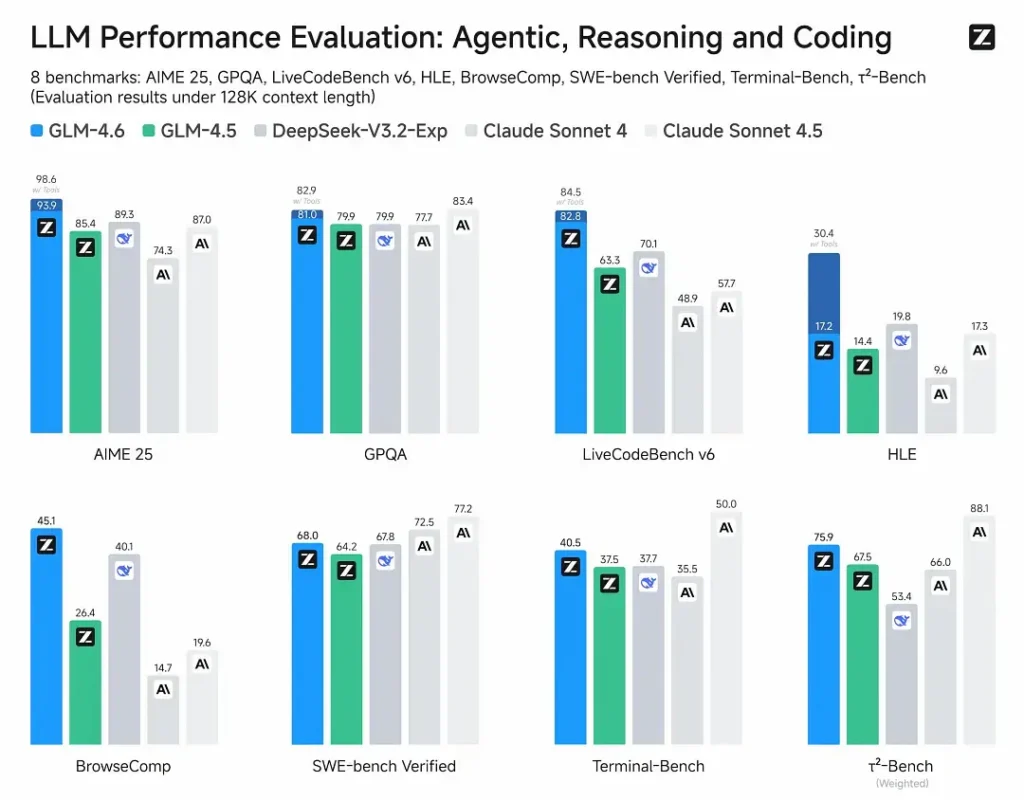
- 公开评测: GLM-4.6 在覆盖智能体、推理与编码的八个公开基准上进行测试,显示出相较 GLM-4.5 的明显提升。在人工评估的真实世界编码测试(扩展版 CC-Bench)中,GLM-4.6 相比 GLM-4.5 使用约少 ~15% 的 tokens,并对 Anthropic 的Claude Sonnet 4 取得约 ~48.6% 的胜率(在许多排行榜上接近持平)。
- 定位: 结果声称 GLM-4.6 与国内外领先模型具有竞争力(示例包括 DeepSeek-V3.1 与 Claude Sonnet 4)。
限制与风险
- 幻觉与错误: 与所有当前 LLM 一样,GLM-4.6 也可能产生事实性错误——Z.ai 的文档明确提示输出可能包含错误。对于关键内容,用户应进行核验并结合检索/RAG。
- 模型复杂度与服务成本: 200K 上下文与超大输出会显著增加内存与时延需求,并可能提高推理成本;需要量化/推理工程来支撑规模化运行。
- 领域差距: 尽管 GLM-4.6 在智能体/编码方面报告强势表现,但有公开报告指出其在某些微基准上仍落后于某些版本的竞品(例如部分编码指标对比 Sonnet 4.5)。在替换生产模型前,应按任务逐项评估。
- 安全与政策: 开放权重提升了可获得性,同时也带来治理问题(缓解措施、防护与红队测试仍由用户负责)。
使用场景
- 智能体系统与工具编排: 支持较长的智能体轨迹、多工具规划与动态工具调用;模型的智能体调优是关键卖点。
- 真实世界编码助手: 多轮代码生成、代码评审与交互式 IDE 助手(据 Z.ai 集成到 Claude Code、Cline、Roo Code)。token 效率提升使其对高频使用的开发者方案更具吸引力。
- 长文档工作流: 利用 200K 窗口进行摘要、多文档综合、长篇法律/技术审阅。
- 内容创作与虚拟角色: 扩展对话、多轮场景中的一致人设维持。
GLM-4.6 与其他模型的比较
- GLM-4.5 → GLM-4.6: 上下文规模跃迁(128K → 200K)与token 效率(在 CC-Bench 上少用约 ~15% 的 tokens);智能体/工具使用能力增强。
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai 报告称在多个排行榜上接近持平,并在 CC-Bench 真实世界编码任务中约 48.6% 胜率(总体接近,但在部分微基准上 Sonnet 仍领先)。对许多工程团队而言,GLM-4.6 被定位为具成本效率的替代方案。
- GLM-4.6 vs 其他长上下文模型(DeepSeek、Gemini 变体、GPT-4 系列): GLM-4.6 强调大上下文与智能体编码工作流;相对优势取决于指标(token 效率/智能体集成 vs 纯代码生成准确率或安全流水线)。应以任务驱动进行经验性选择。
Zhipu AI 的最新旗舰模型 GLM-4.6 发布:355B 总参数,32B 活跃参数。在所有核心能力上超越 GLM-4.5。
- 编码:与 Claude Sonnet 4 对齐,中国最佳。
- 上下文:由 128K 扩展至 200K。
- 推理:提升,支持推理过程中的工具调用。
- 搜索:增强的工具调用与智能体性能。
- 写作:在风格、可读性与角色扮演上更贴合人类偏好。
- 多语种:跨语言翻译能力提升。
如何调用 GLM–**4.**6 API(来自 CometAPI)
GLM‑4.6 在 CometAPI 的 API 定价,较官方价格优惠 20%:
- 输入 Tokens:$0.64 M tokens
- 输出 Tokens:$2.56/ M tokens
必要步骤
- 登录 cometapi.com。如果你还不是我们的用户,请先注册。
- 登录你的 CometAPI console。
- 获取接口的访问凭证 API key。在个人中心的 API token 处点击 “Add Token”,得到令牌密钥:sk-xxxxx 并提交。

使用方法
- 选择 “
glm-4.6” 端点发送 API 请求并设置请求体。请求方法与请求体可从我们的网站 API 文档获得。我们的网站也提供 Apifox 测试以便使用。 - 将 <YOUR_API_KEY> 替换为你账号中的实际 CometAPI key。
- 将你的问题或请求插入到 content 字段——模型将对其进行响应。
- . 处理 API 响应以获取生成的答案。
CometAPI 提供完全兼容的 REST API——实现无缝迁移。关键细节见 API doc:
- Base URL: https://api.cometapi.com/v1/chat/completions
- Model Names: “
glm-4.6“ - Authentication:
Bearer YOUR_CometAPI_API_KEY头 - Content-Type:
application/json。
API 集成与示例
下面是一个通过 CometAPI 调用 GLM‑4.6 的 Python 代码片段。请相应替换 <API_KEY> 与 <PROMPT>:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
关键参数:
- model: 指定 GLM‑4.6 变体
- max_tokens: 控制输出长度
- temperature: 调节创造性与确定性
另请参见 Claude Sonnet 4.5