

Google DeepMind 今日宣布对其 Gemini 2.5 系列进行重大扩展,发布 Gemini 2.5 Pro 和 Gemini 2.5 Flash 的稳定版本,同时推出全新 Gemini 2.5 Flash‑Lite 模型的预览版。这些更新体现了 Google 持续致力于提供在成本、速度与性能之间取得平衡、适配多样化工作负载的 AI 模型谱系。
稳定版本:Gemini 2.5 Pro 与 Flash
2025 年 6 月 17 日,Google 宣布 Gemini 2.5 Pro 与 Gemini 2.5 Flash 面向公众正式可用。Pro 版本提供最大化的推理能力,面向高级代码生成、科学分析、海量数据综合等高复杂度任务。相比之下,Gemini 2.5 Flash 提供一款面向日常低时延需求的中端选项—非常适用于聊天机器人、摘要生成以及规模化内容创作。
概览:Gemini -2.5 家族的三款模型
| 模型 | 状态 | 优势 | 理想用例 |
|---|---|---|---|
| Gemini 2.5 Flash‑Lite (预览) | 预览 | 最快且最便宜;多模态;可控推理;支持工具 | 高吞吐任务,如聊天机器人、摘要、搜索 |
| Gemini 2.5 Flash | 稳定 | 平衡:低时延、良好推理、多模态 | 实时对话、客户支持 |
| Gemini 2.5 Pro | 稳定 | 最强:深度推理、超大上下文、多模态 | 研究、复杂编码、科学任务 |
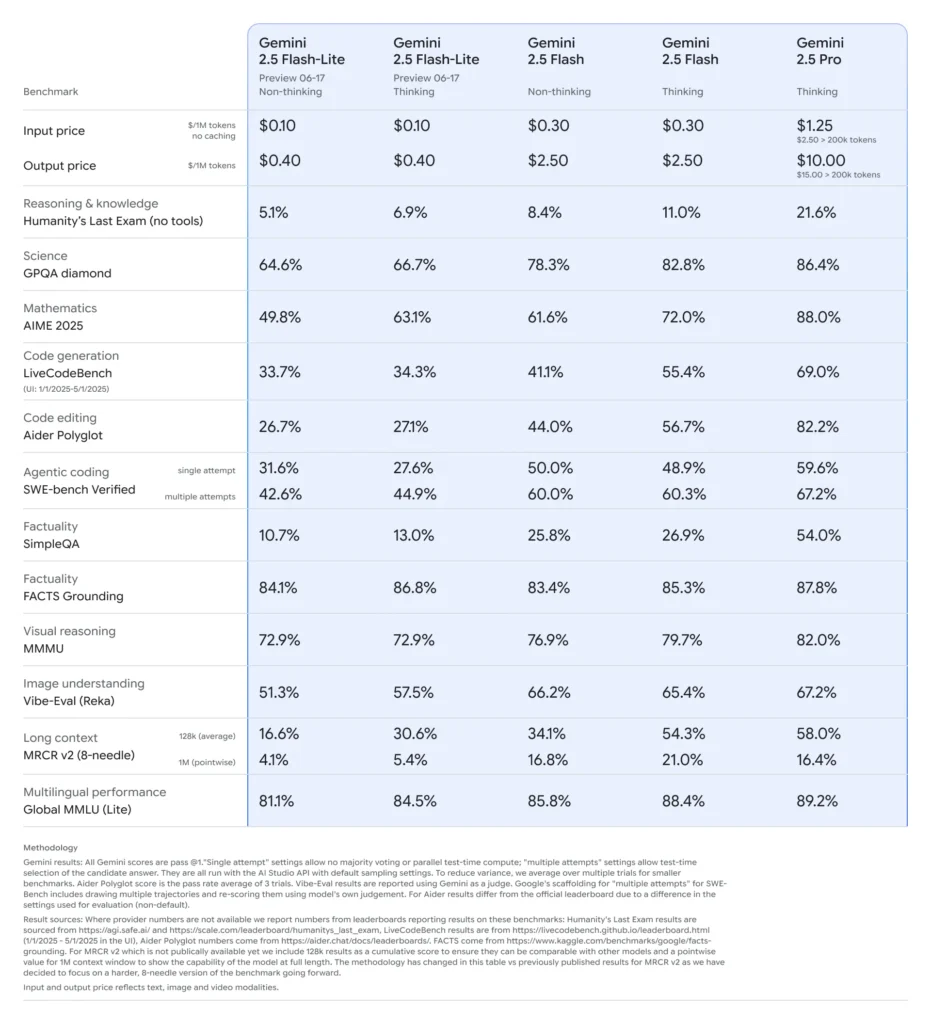
Gemini 2.5 Flash‑Lite:预览亮点
超低时延与成本节省:面向翻译、分类、摘要等高吞吐、实时应用。相较于 2.0 Flash‑Lite 和完整的 Flash 版本,推理更快、单次调用成本更低。
基础性能改进:在代码生成、逻辑、数学、多模态推理与科学等基准上,优于早期的 Flash‑Lite 模型。
成本与效率:Flash‑Lite 定价(预览):每 1M 输入 token 约 $0.10、每 1M 输出 token 约 $0.40—明显低于 Flash($0.30/$2.50)与 Pro($1.25/$10)。
完整的 Gemini -2.5 能力:
- 可控思考:用户可设置“思考预算”(token 限制)以在速度与深度间取舍—Flash‑Lite 可按需启用。
- 多模态输入:支持文本、图像、音频与视频(包括长达一小时的片段),可解析图表、界面、场景与事件摘要。
- 工具集成:包括 Google Search、代码执行与百万 token 的上下文窗口,能力与 Flash 和 Pro 相匹配。
价格‑性能曲线上的定位
Google 将 Flash‑Lite 的高速与低成本定位在帕累托前沿,意味着它是全球范围内兼具能力与成本效率的领先模型之一()。在对比评估中,Flash‑Lite 代表最佳性价比:聪明而又实惠。
关于 Flash 与 Pro
- Gemini 2.5 Flash:稳定、低时延的多模态思考模型。定位低于 Pro,但能力大致与 GPT-4o 相当,且在速度与成本效率上更优()。
- Gemini 2.5 Pro:Google 最先进的模型。以处理数小时的视频/音频、复杂代码与数学,以及超大上下文推理而著称。还引入可选择的“思考预算”和改进的代码质量,作为长期稳定的旗舰 AI。
部署与定价
- 可用性:三款模型均可通过 Google AI Studio、Google Cloud Vertex AI 和 Gemini app 访问。
- 成本结构(Vertex AI 定价截至 2025 年 6 月 16 日):
- Pro:$1.25/1M 输入,$10/1M 输出(超过 200K token 后更高)
- Flash:在“思考”模式下 $0.15/1M 输入,$3.50/1M 输出—且每日包含 1,500 条免费 grounded prompts()
- Flash‑Lite(预览):每 1M token 约 $0.10/$0.40
入门指南
CometAPI 提供统一的 REST 接口,聚合数百种 AI 模型—在一致的端点之下,内置 API 密钥管理、用量配额与计费看板。无需在多个厂商的 URL 与凭据之间来回切换。
开发者可通过 CometAPI 访问 Gemini 2.5 Flash-Lite (preview) API,文中所列最新模型以文章发布之日为准。开始使用前,可在 Playground 体验模型能力,并参阅 API 指南 获取详细说明。访问之前,请确保已登录 CometAPI 并获取 API 密钥。CometAPI 提供远低于官方价格的优惠,帮助您完成集成。