GPT-4o Audio API: 一个统一的 /chat/completions 端点扩展,可接受 Opus 编码的音频(以及文本)输入,并返回可配置参数的合成语音或转录(model=gpt-4o-audio-preview-<date>、speed、temperature),适用于批量与流式语音交互。
GPT-4o Audio 的基本信息
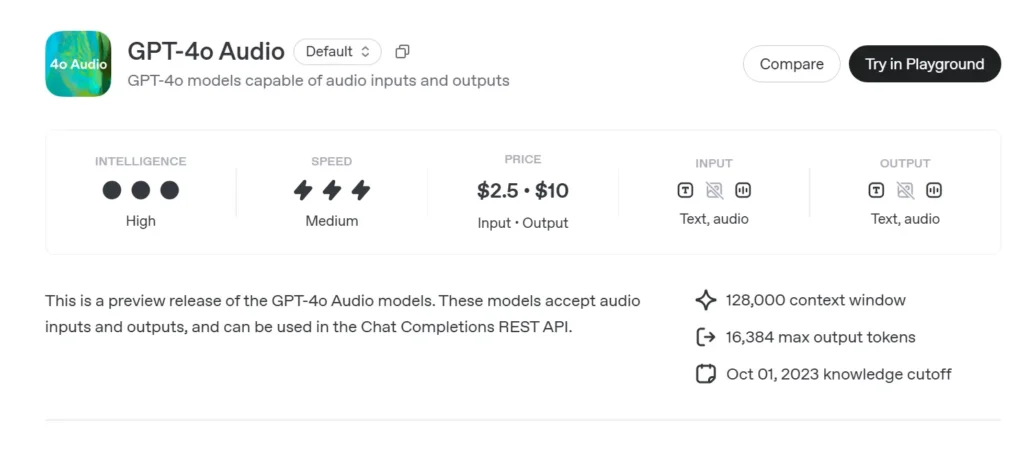
GPT-4o Audio Preview(gpt-4o-audio-preview-2025-06-03)是 OpenAI 最新的以语音为中心的大型语言模型,通过标准的 Chat Completions API 提供,而非超低延迟的 Realtime 通道。基于与 GPT-4o 相同的“omni”基础,这一变体专注于高保真语音输入与输出,适用于不需要毫秒级时序的回合制对话、内容创作、无障碍工具与代理式工作流。它继承了 GPT-4 级模型的文本推理能力,并新增端到端的语音到语音(S2S)管线、确定性的函数调用,以及用于控制语速的新 speed 参数。
GPT-4o Audio 的核心功能集
• 统一的语音到语音处理 – 音频被直接转换为语义丰富的令牌,经推理处理后无需外部 STT/TTS 服务即可重新合成,带来一致的音色、韵律与上下文保留。
• 改进的指令遵从 – 2025 年 6 月的调优在语音指令任务上相较 2024 年 5 月的 GPT-4o 基线实现了**+19 个百分点的 pass-at-1**,降低了在客服与内容撰写等领域的幻觉。
• 稳定的工具调用 – 模型输出符合 OpenAI 函数调用模式的结构化 JSON,使后端 API(搜索、预订、支付)能够以**>95 % 参数准确率被触发。
• speed 参数(0.25–4×) – 开发者可调节语音播放速度,覆盖慢速学习、正常叙述或快速“可听略读”模式,且无需外部重新合成文本。
• 感知中断的轮换对话 – 虽不如 Realtime 变体那样以延迟为核心,但该预览版支持部分流式**:令牌一经计算即开始输出,必要时允许用户提前打断。
GPT-4o 的技术架构
• 单栈 Transformer – 与所有 GPT-4o 衍生模型一致,音频预览采用统一的编码器–解码器,文本与声学令牌通过相同的注意力块处理,促进跨模态对齐。
• 层级化音频令牌化 – 原始 16 kHz PCM → log-mel patches → 粗粒度声学码 → 语义令牌。该多阶段压缩实现40–50× 带宽降低且保持细微差异,使每个上下文窗口可容纳多分钟音频片段。
• NF4 量化权重 – 推理采用4-bit Normal-Float精度,相比 fp16 将 GPU 内存占用减半,并在 A100-80 GB 节点上维持70+ 流式 RTF(实时因子)。
• 流式注意力与 KV 缓存 – 滑动窗旋转嵌入在约 30 s 语音内维持上下文,同时保持O(L) 的内存用量,非常适合播客编辑或辅助阅读工具。
版本与命名 — 带日期戳的预览版本
| Identifier | Channel | Purpose | Release Date | Stability |
|---|---|---|---|---|
| gpt-4o-audio-preview-2025-06-03 | Chat Completions API | 回合制音频交互、代理式任务 | 03 Jun 2025 | 预览(欢迎反馈) |
名称中的关键元素:
- gpt-4o — Omni 多模态家族。
- audio — 为语音用例优化。
- preview — API 合同可能演进;尚未 GA。
- 2025-06-03 — 为可复现性提供训练与部署快照。
如何通过 CometAPI 调用 GPT-4o Audio API
GPT-4o Audio API 在 CometAPI 的定价:
- 输入令牌:$2 / 每百万令牌
- 输出令牌:$8 / 每百万令牌
必要步骤
- 登录 cometapi.com。如果您尚未成为我们的用户,请先注册。
- 获取接口的访问凭证 API Key。在个人中心的 API token 处点击“Add Token”,获取令牌密钥:sk-xxxxx 并提交。
- 获取本站点的 url:https://api.cometapi.com/
使用方法
- 选择 “
gpt-4o-audio-preview-2025-06-03” 端点发送请求并设置请求体。请求方法与请求体可从我们的网站 API 文档获取。我们的网站也提供 Apifox 测试以便您使用。 - 将 <YOUR_API_KEY> 替换为您账户中的实际 CometAPI Key。
- 将您的问题或请求插入到 content 字段——模型会对此作出响应。
- . 处理 API 响应以获取生成的答案。
有关模型访问的信息请参见 API doc。
有关模型价格的信息请参见 https://api.cometapi.com/pricing。
API 工作流 — 带音频部件与函数钩子的 Chat Completions
- 输入格式 — 在
messages[].content中嵌入audio/*MIME 或base64WAV 分片。 - 输出选项 —
•mode: "text"→ 用于字幕的纯文本。
•mode: "audio"→ 返回带时间戳的流式 Opus 或 µ-law 负载。 - 函数调用 — 添加
functions:模式;模型以role: "function"输出带 JSON 参数;开发者执行工具调用,并可选择将结果回传。 - 速率控制 — 设置
voice.speed=1.25以加速播放;安全范围 0.25–4.0。 - 令牌/音频限制 — 初始为 128 k 上下文(约 ~4 分钟语音);4096 audio tokens / 8192 text tokens,以先达到者为准。
示例代码与 API 集成
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- 亮点:
- model:
"gpt-4o-audio-preview-2025-06-03" - 在 user 消息中使用 audio 键发送二进制流
- speed:控制语速,介于慢速(0.5)与快速(2.0)之间
- temperature:在创造性与一致性之间取得平衡
技术指标 — 延迟、质量、准确性
| Metric | Audio Preview | GPT-4o (仅文本) | Delta |
|---|---|---|---|
| First Token Latency (1-shot) | 1.2 s 平均 | 0.35 s | +0.85 s |
| MOS (Speech Naturalness, 5-pt) | 4.43 | — | — |
| Instruction Compliance (Voice) | 92 % | 73 % | +19 pp |
| Function Call Arg Accuracy | 95.8 % | 87 % | +8.8 pp |
| Word Error Rate (Implicit STT) | 5.2 % | n/a | — |
| GPU Memory / Stream (A100-80GB) | 7.1 GB | 14 GB (fp16) | −49 % |
基准通过 Chat Completions 流式执行,批大小 = 1。