

xAI 于 2025 年 11 月 17–18 日低调发布了 Grok 4.1 ——这是对 Grok 4 的一次聚焦升级,优先强化“情商、创意表达与降低幻觉”,同时保留早期 Grok 版本的锋利推理能力。它以两种模式(Thinking / Non-Thinking)推出,已在 11 月上旬静默上线,在 LMArena 展现顶级榜单成绩,并可通过 grok.com、Grok 应用与 API 使用。
什么是 Grok 4.1?
Grok 4.1 是面向生产的、增量式的 Grok 4 后继者:它是同一家族成员,基于相同的大规模强化学习基础,但通过微调与再训练,并进行大量后训练优化,集中针对风格、人格、对齐与真实世界可靠性。其定位是务实、可用的前进一步:在人类盲测偏好中更聪明、更具情感智能、更擅长创意写作,并且显著减少困扰早期高性能 LLM 的那类“自信但错误”的幻觉。
Grok 4.1 在以下四个维度实现质的变化:
- 创造力:在写作、叙事与社交语境中展现更强的语言风格与想象力;
- 情商:识别语气与情感变化,以更贴近人类的情感逻辑回应,生成安慰与理解的回复;
- 人格一致性:在长对话中保持一致的语气与人格,不再表现出早期模型的不一致行为;
- 协作性:在多轮对话或任务协作中保持连贯与目标意识。
xAI 用一句话概括其特性:“它更敏锐、更具同理心,更像一个连贯的人。”
Grok 4.1 底层如何工作?
最佳理解为:与 Grok 4 家族共享同一预训练骨干,再叠加聚焦于奖励建模、风格对齐与代理型评估器的分层后训练流水线。
训练与对齐阶段有哪些?
Grok 4.1 采用现代前沿 LLM 常见的多阶段流水线,并针对 4.1 做了两点重要调整:
- 预训练 + 中期训练:大型语料的网络数据预训练 + 针对性中期训练以提升领域知识与多模态能力。
- 监督式微调(SFT):用于期望行为(回复、拒绝策略)的人工示范。
- 奖励建模(新颖应用):xAI 训练奖励模型不仅基于人类偏好标签,还使用前沿代理型推理模型作为奖励评分者——实质上让高能力、基于模型的评估器在规模上为候选输出打分。这使得无需不可能庞大的人类标注预算,就能优化诸如风格、人格一致性、同理心与有用性等不可验证属性。
- 策略优化(RLHF / 基于模型奖励的 RL):使用学习到的奖励信号进行标准策略优化,产出部署策略(即用户交互的模型)。
奖励建模方法有哪些新变化?
传统 RLHF 的流程是收集人类偏好标签(A/B)、训练奖励模型去预测这些标签,再用 RL(或拒绝采样)对基座模型进行针对该奖励的优化。但 xAI 强调了两项务实创新:
- 代理型奖励模型:而不是纯粹由人类评审,xAI 使用有能力的“代理型”推理模型作为评分者,评估更微妙的属性(语气、情感细腻度、创造力)。评分器可快速运行成千上万的成对比较,使工程师更快迭代。这是风格与情商显著改进的机制。
- 面向不可验证信号的后训练对齐:对于无法用确定性度量衡量的属性(如“温暖”或“连贯人格”),他们引入了特化的奖励目标与尺度化课程,让模型学习输出的风格而不牺牲核心事实准确性。
“Thinking” 与 “Non-Thinking” 在技术上如何运作?
- Grok 4.1 Thinking(代号
quasarflux)——在生成最终答案前公开明确的推理步骤(思考 token);针对复杂任务与 LMArena 更高 Elo 进行优化。额外的 token 增加推理时间,但有助于多步推理任务、调试与可解释性。 - Grok 4.1 Non-Thinking(代号
tensor)绕过显式中间 token,直接给出单次的即时最终响应。这样降低延迟与 token 成本,同时仍受益于同样精炼的策略权重。非思考模式被优化为极低延迟且仍具高能力。
情感与风格的对齐优化
超越简单“真实性”信号,Grok 4.1 包含针对情感、语气与人际风格的定向对齐优化。这意味着训练流水线包含显式惩罚不匹配语气的奖励或损失组件(例如在需要同理时不必要地简短),并奖励符合期望风格或情感剖面的回应。在 Grok 4.1 中,首次引入了“人格对齐”(Personality Alignment)的优化目标。
其目标是帮助模型保持一致且稳定的自我身份感。与 Grok 4 相比,4.1 在训练目标中新增:
- 对情感表达维度给予正向奖励(情感对齐奖励);
- 人格一致性度量。
Grok 4.1 是如何评估的——表现如何?
盲测人类偏好结果如何?
在静默上线期间,Grok 4.1 在实时流量中相对于此前生产模型被偏好 64.78% 的次数——这是强有力的人类偏好信号,表明在真实场景中的对话结果更好。
Grok 4.1 是否登顶排行榜?
xAI 报告称 Grok 4.1 的 Thinking 模式位居 LMArena 的 Text Arena 第 1 名,Elo 为 1483,而其非推理(快速)模式以 1465 Elo 排名第 2——在准确性与呈现上均有强势表现(风格控制有所贡献)。
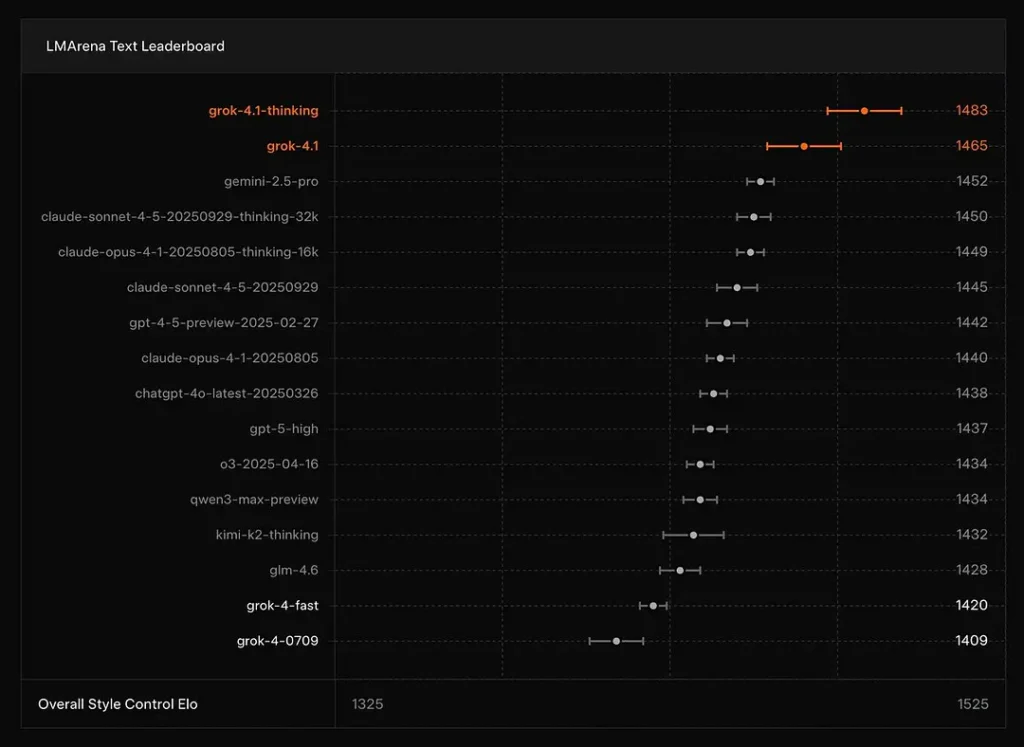
结论:Grok 4.1 在文本理解、生成与整体质量上优于主流 GPT-4.5 与 Claude 系列,仅次于 GPT-5 Advanced Preview 版本。
情商
xAI 运行了 EQ-Bench3,这是一项覆盖 45 个具有挑战性的角色扮演场景的情商专项测试,并报告 Grok 4.1 在同理心、节奏与人际洞察方面取得显著提升。Grok 4.1 在理解悲伤、同理与安慰的语境中得分最高。

创意写作——它真的更有想象力吗?
Grok 4.1 在 Creative Writing v3(32 个提示,跨 3 次迭代,采用评分细则 + Elo 评分)上进行了评估。xAI 表示 4.1 的写作风格、声音一致性与叙事创造性显著提升,位居近期创意任务排行榜前列(发布中包含示例提示)。独立报道也印证了这些发现:评测者看到更“独特的声音”和更好的长篇连贯性。在写作质量方面,Grok 4.1 仅次于 GPT-5 系列模型,且超越 Claude、Gemini 和 Kimi 的整条产品线。

降低幻觉 / 诚实性
xAI 声称幻觉率显著降低:他们在公告与社交帖子中报告,与早期 Grok 模型相比,Grok 4.1 发生幻觉的可能性约低 3×,并引用了生产流量分析与 FActScore 风格评估(例如传记/人物问答集,越低越好)。尤其是在“非推理模式”中,当可用外部搜索工具时,事实一致性更为稳定。

为何说 Grok 4.1“碾压”其他模型——这是夸张吗?
“Crushes” 带有营销色彩,但该说法背后有客观主张:
- 榜单:Grok 4.1 在公共 LMArena 文本生成榜上占据顶尖位置(Thinking 模式 1483 Elo),并在创意与 EQ 基准上表现强劲,见 xAI 的发布。这些是社区通用的、可比的竞争指标。
- 真实流量的偏好胜出:xAI 报告静默上线实时流量中的盲比结果(相对于先前生产模型约 65% 的人类偏好胜出)。这反映了真实用户改进,而不仅是论文基准。
- 务实的新能力:将模型评分者、针对不可验证信号的 RL,以及更严格的输入过滤结合,是直接改善对话、同理与创意任务用户体验的工程举措,而这些领域竞争对手历史上表现欠佳。
因此,尽管“碾压”是以更生动的方式表达“在多项公共与内部评测中领先”,xAI 发布的公开指标为这一结论提供了支撑。
如何获取 Grok 4.1
消费者/应用访问
xAI 会周期性地在 “Auto” 模式下免费或以促销窗口形式开放 Grok 4.1,但高级层级(SuperGrok、SuperGrok Heavy)以及更高配额的 API 访问仍作为付费方案提供。
Grok 4.1 对所有用户可用,在 grok.com、X(原 Twitter) 以及 iOS 与 Android 的 Grok 应用中,立即以 Auto 模式推出,同时也可在模型选择器中明确选择 “Grok 4.1”。
API 访问与开发者计划
Grok 4.1 端点可通过 xAI API 使用。截止本文发布日期,官方 GPT 4.1 API 尚未发布。
CometAPI 承诺持续追踪最新的模型动态,包括 Grok 4.1 API,该接口将与正式发布同步上线。敬请期待并持续关注 CometAPI。在等待期间,你可以关注 Grok 的其他模型,如 Grok-code-fast-1 和 Grok 4,在 Playground 中探索它们的能力,并查阅 API 指南以获得详细调用说明。访问前,请确保你已登录 CometAPI 并获取 API key。
在生产中使用 Grok 4.1 的实用建议
如何降低幻觉风险
- 启用实时搜索或经过验证的工具链处理信息检索查询。
- 提供验证步骤:要求模型为事实声明返回来源与证据;如可用,使用
response元数据检查引用。 - 运行确定性检查(事实核查 LLM、结构化数据验证器)作为高风险输出的后处理步骤。
如何控制语气与风格
- 使用明确的系统提示固定语气(“你是正式且富有同理心的。”)。
- 使用监督式提示与本地小模板,以在应用中统一语气。
- 在可用的情况下,利用 xAI 的风格控制选项与基于奖励的调节旋钮。
最终结论:Grok 4.1 是一次巨变吗?
Grok 4.1 并非全新架构;它是一版精密而深思熟虑的后训练/对齐发布,聚焦于人们在聊天中真正关心的内容:人格、情商、创造力与更少的事实错误。在排行榜上的可测提升、大规模真实流量的偏好结果,以及更完善的安全工具。对于依赖高质量对话、创意协作或语气敏感辅助的应用而言,Grok 4.1 是一次重大进步,并在多个社区基准中,于发布时位居前列。
CometAPI 是一个商业化的 API 聚合平台,为开发者提供统一的、OpenAI 风格的 REST 接口来访问数百个来自多家供应商的 AI 模型——文本 LLM、图像/视频生成、嵌入等——通过单一、一致的接口。开发者无需为 OpenAI、Anthropic、Google、Meta 或其他小型专业模型提供商分别接入不同 SDK 或自定义端点;在 CometAPI 中只需更改模型字符串与少量参数即可调用不同模型。
准备好试用了吗?→ 立即注册 CometAPI!